活体检测 Single-Side Domain Generalization for Face Anti-Spoofing 论文学习记录
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Jia_Single-Side_Domain_Generalization_for_Face_Anti-Spoofing_CVPR_2020_paper.pdf
动机
尽管现有的 SOTA 方法在数据集内测试场景下取得了不错的结果,但在跨数据集测试下,它们不能很好地泛化。这是因为这些方法没有考虑不同域之间的内在分布关系,因此提取了具有偏向性的判别特征,从而对未知域的泛化性差。为了解决这个问题,最近的 FAS 方法采用域自适应技术,通过利用未标记的目标数据来最小化源域和目标域之间的分布差异。然而,在许多现实场景中,收集大量未标记的目标数据进行训练的代价很大。
因此,一些研究人员开始从域泛化 (DG) 的角度来解决 FAS 问题。传统的 DG 方法旨在通过对齐多个源域之间的分布来学习通用特征空间,假设提取的人脸特征可以映射到共享特征空间附近,这样模型就可以很好地泛化到未知域。由于来自源域和目标域的真实人脸都是通过对真人的成像来收集的,因此它们的分布差异很小,比较容易学习紧凑的特征空间。相比之下,由于攻击类型和收集方式的多样性,将来自不同域的假人脸特征聚合在一起比较困难。因此,为假人脸寻找一个通用的特征空间很难优化,也可能影响目标域的分类精度。如下图左侧所示,尽管学习了真假人脸紧凑的特征空间,但仍无法获得判别类边界。考虑以上情况,除了将真人脸和假人脸尽可能区分之外,作者还建议将所有真实人脸拉到一起,同时将不同域的假人脸推开。如下图右侧所示,作者的方法迫使假人脸的特征在特征空间中更加分散,而真实人脸的特征更加紧凑,从而产生类边界,更好地泛化到目标域。

创新点
(1)基于假人脸比真人脸更多样化的分析,提出了一种端到端单边域泛化框架
(2)设计了单边对抗学习和非对称的三元组损失来实现真假人脸不同的优化目标,并进行特征和权重归一化以进一步提高性能
相关工作
FAS
1)基于纹理特征的方法
这类方法通过各种纹理线索来区分真假人脸。提取纹理特征的传统方法有:LBP、HOG、SURF 等。近年来,随着深度学习在计算机视觉领域的发展,研究人员开始转向使用 CNN 来提取判别性更强特征。
2)基于时间的方法
这类方法利用连续帧中的时间线索进行 FAS。CNN-LSTM 架构将多个帧作为输入来提取时间特征以进行 FAS。
DG
域适应方法的目标是提高模型的泛化能力,它在不访问任何目标数据的情况下显式挖掘多个源域之间的关系,从而更好地泛化到未知域。大多数以前的 DG 方法都专注于最小化多个源域之间的分布差异以提取域不变特征。然而,由于攻击类型和收集方式的多样性,很难为假人脸寻找一个通用的特征空间。
方法论
由于假人脸的数据分布的差异性远大于真人脸数据分布的差异性,因此,很难去为真人脸和假人脸寻找一个紧凑和通用的特征空间。在这篇文章中,作者为属于不同域的真假人脸寻找不对称的优化目标,通过这种方法学到的特征空间在未知域中的泛化性更强。SSDG 框架如下图所示,具体来说,作者通过与域判别器竞争的方式来训练特征生成器,使得模型无法区分真人脸的特征。此外,还提出了非对称三元组损失来明确分离不同域的假人脸,同时聚合真人脸。特征和权重的归一化 (L2 Norm)也被进一步结合来提高训练过程中的泛化能力。因此,SSDG 方法迫使假人脸在特征空间中更加分散,而真人脸更加紧凑,这使得模型学到的分类边界的通用性更强。
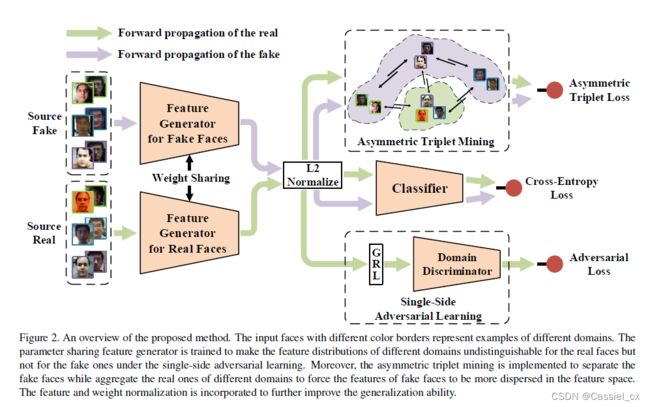
单边对抗学习
假设有 N 个源域,每个源域都有真假人脸两种类别。由于所有真人脸都是通过对真人进行成像收集的,作者推测它们之间的分布差异比假人脸的小。因此,为真人脸寻找一个通用的特征空间相对来说比较容易,这有助于捕捉更多常见的判别线索。具体来说,提出了单边对抗学习来学习通用特征空间,该学习仅对提取的真人脸特征进行。作者首先将所有源域的真人脸与假人脸分离,然后将它们输入相应的特征生成器,将输入的人脸转换为潜在特征空间,公式如下:
![]()
其中,G 表示生成器,Z 表示生成器提取的特征,下标 r、f 分别表示真假人脸。作者采用了参数共享策略,因此两个生成器的参数是一致的。域判别器 D 用于判断 ![]() 属于哪个源域,而特征生成器则用于欺骗域判别器,尽可能让它误判。在学习过程中,特征生成器的参数通过最大化域判别器的损失来优化,而域判别器的参数则以相反的目标进行优化。由于数据包含多个源域,因此作者利用标准的交叉熵损失来优化单边对抗学习下的网络,公式如下:
属于哪个源域,而特征生成器则用于欺骗域判别器,尽可能让它误判。在学习过程中,特征生成器的参数通过最大化域判别器的损失来优化,而域判别器的参数则以相反的目标进行优化。由于数据包含多个源域,因此作者利用标准的交叉熵损失来优化单边对抗学习下的网络,公式如下:
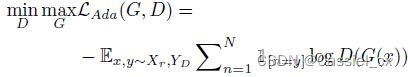
其中,![]() 表示域标签。 为了同时优化生成器和判别器,作者在生成器后添加了梯度反向层 (GRL),它在反向传播期间将对抗性损失的梯度乘以
表示域标签。 为了同时优化生成器和判别器,作者在生成器后添加了梯度反向层 (GRL),它在反向传播期间将对抗性损失的梯度乘以 ![]() 。
。 和
和  的定义如下:
的定义如下:
![]()
![]()
它们的作用是在训练早期阶段抑制噪声信号的影响。
非对称三元组损失
由于攻击类型以及数据收集方式的多样性,假人脸数据分布的差异性远大于真人脸的差异性,因此为假人脸寻找一个分散的特征空间比寻找一个紧凑的特征空间简单。作者明确地分离了来自不同域的假人脸,以迫使它们在特征空间中更加分散。为了实现真假人脸的非对称优化目标,作者提出了非对称三元组损失来根据类别进行非对称三元组挖掘,这有助于为未知域学习更好的类边界。具体来说,假设有3个源域,将来自三个不领域的真假人脸重组并分成四类,如下图左边所示,三个不同域的假人脸被视为不同的类别 (分别为圆形、正方形和三角形),而所有真人脸被归为一个类别(叉)。接着,对真假人脸进行四类非对称三元组挖掘,达到以下优化目标:1)分离不同域的假人脸; 2)聚合所有源域的真人脸; 3)将真假人脸分开。之后,如下图右边所示,提取的假人脸特征在特征空间中比以前更加分散,而真人脸的特征则更加聚合,从而为未知域提供了更好的泛化类边界。特征生成器优化如下:
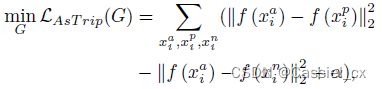
其中, 为预定义的裕值 margin。
为预定义的裕值 margin。

特征和权重归一化
特征范数与图像质量密切相关。由于数据采集条件的多样性 (如:光照、相机质量等),不同人脸图像在源域和目标域中的特征范数存在较大的差异。因此,作者对特征生成器的输出进行 L2 归一化。
此外,作者参考人脸识别算法中的做法,将权重也进行归一化,使得:![]()
损失函数
由于所有源域数据都包含标签,因此在特征生成器之后进行真假人脸分类,分类器和特征生成器的损失均是交叉熵损失。整体损失函数公式如下:
![]()
其中,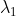 和
和 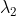 为损失平衡参数。
为损失平衡参数。
实验结果
消融实验以及与 baseline 模型的对比实验结果如下:

不同特征生成器的对比实验结果如下:

在有限源域数据下与其他 DG 方法进行对比,结果如下:

SSDG 方法的 Grad-CAM 可视化结果如下,图中第一行是真人脸,第二行是假人脸:
