C++项目:基于boost在线文档实现的搜索引擎(二)
C++项目:基于boost在线文档实现的搜索引擎(二)
- 索引模块
- 索引模块的描述
- 正排索引与倒排索引的建立
-
- 正排索引
- 倒排索引
- jieba分词,正排查找,倒排查找
-
- jieba分词
- 索引查找
- 索引的测试
上一篇:C++项目:基于boost在线文档实现的搜索引擎(一)
下一篇:C++项目:基于boost在线文档实现的搜索引擎(三)
github: https://github.com/duchenlong/boost-search-engine
通过之前的预处理的过程,我们将boost在线文档都进行了分解,得到了每一个html在线文档分词后的结果(title,url,content)
之后我们就需要将正文进行拆分,为正文的每一个关键字建立一个索引,方便我们之后的搜索过程,这里可以使用C++STL中的哈希表,也就是unordered_map
这里我们需要完成
倒排索引的建立,倒排索引与正排索引进行搜索文本的查找
索引模块
对于索引模块,也就是我们需要构建倒排索引
也就是需要提取关键字对指定文本进行分词,这一过程叫做倒排索引。他的核心就是根据一个词,映射到这个词所属的文档中(哈希表)
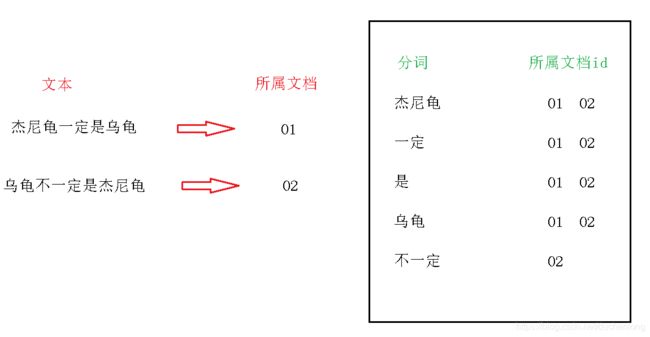
正排索引:根据文档id,得到文档的内容倒排索引:根据文档的内容,得到文档的id
为了对每一个倒排索引与正排索引的关键字进行描述,我们给他们各自封装一个结构体:
/*
* 正排索引的存储结构体
* 根据文档 id 定位到文档的内容
* 防止文档过多,直接使用64位的 int 来存储
*/
struct frontIdx{
int64_t _docId;
string _title;
string _url;
string _content;
};
/*
* 倒排索引存储的结构体
* 根据文本的关键字 定位到 所属的文档Id
* 为了后面根据权值排序,再加一个关键字的权值
*/
struct backwardIdx{
int64_t _docId;
int _weight;
string _word;
};
索引模块的描述
我们的索引模块会有两次使用的地方:
- 第一次就是我们启动服务器的时候,自动对指定目录下的所有 html文档进行分词,建立索引
- 第二次就是我们进行查找的时候,这时进行分词的就是我们的搜索内容,并对这个内容进行分词,正排索引与倒排索引。
这其中会有一些公共的代码块,所以我们可以对索引的地方进行封装,构建一个类Index来进行这一模块的描述:

class Index{
public:
Index();
//查找正排索引
const frontIdx* GetFrontIdx(const int64_t doc_id);
//查倒排索引
const vector<backwardIdx>* GetBackwardIdx(const string& key);
// 建立倒排索引 与 正排索引
bool Build(const string& input_path);
// jieba分词 对语句进行分词
void CutWord(const string& input,vector<string>* output);
private:
//根据一行 预处理 解析的文件,得到一个正排索引的节点
frontIdx* BuildForward(const string& line);
//根据正排索引节点,构造倒排索引节点
void BuildInverted(const frontIdx& doc_info);
private:
//正排索引
vector<frontIdx> forward_index;
//倒排索引 哈希表
unordered_map<string,vector<backwardIdx> > inverted_index;
// jieba分词
cppjieba::Jieba jieba;
};
正排索引与倒排索引的建立
首先,我们在建立索引的时候,所传的参数是预处理中存储文档进行解析后数据的文件的路径,这个路径中,一行即是一组数据,他的排列为 title\3url\3content\n。

所以在建立索引之前,我们需要进入这个文件中,然后一行一行的将所有html文档中的数据都读取了
在得到一个文档解析的数据后,我们需要得到单独的 title,url,content。因为他们中间被我们用特殊的符号\3分割开,我们可以使用split函数进行分割,而C++的STL中并没有实现这个函数,就借助与Boost中的split函数来实现一些。
boost::split(type, select_list, boost::is_any_of(","), boost::token_compress_on);
-
type类型是std::vectorstd::string,用于存放切割之后的字符串 -
select_list:传入的字符串,可以为空。 -
boost::is_any_of(","):设定切割符为,(逗号) -
boost::token_compress_on:将连续多个分隔符当一个,默认没有打开,当用的时候一般是要打开的。
boost:: token_compress_off:不会压缩分割结果,连续的分隔符时会返回""字符串
因为可能存在有些html文档中没有标题的情况,所有我们采用boost:: token_compress_off风格来分割字符串,遇到没有标题或者正文时,会直接返回""空字符串。并且,split函数进行封装时,因为这是一个公共的代码,所以我们防止公共代码出,common文件下
因为涉及到对文档进行编号的问题,所以应该建立正排索引(得到文档id),再根据正排索引的数据建立倒排索引。
// 建立索引
bool Index::Build(const string& input_path){
// 按行读取 存放预处理中解析出来的数据的文件
cout<<input_path<<" build index begin "<<endl;
std::ifstream file(input_path.c_str());
if(file.is_open() == false){
cout<<input_path<< " file open error " <<endl;
return false;
}
string line;
int idx = 0;
static string progess("|/-\\");
while(std::getline(file,line)){
// 针对当前行数据,进行正排索引
frontIdx* doc_info = BuildForward(line);
if(doc_info == nullptr){
cout<< " forward build error "<<endl;
continue;
}
//根据正排索引的节点,构建倒排索引
BuildInverted(*doc_info);
// 打印部分构建结果 防止过多cout影响时间复杂度
if(doc_info->_docId % 100 == 0){
//cout<< doc_info->_docId << " sucessed "<
//进度条
cout<<"\r"<<progess[idx % 4]<< doc_info->_docId << " sucessed " <<std::flush;
idx++;
}
}
cout<<"index build sucessed "<<endl;
file.close();
return true;
}
进度条显示结果




正排索引
//根据一行 预处理 解析的文件,得到一个正排索引的节点
frontIdx* BuildForward(const string& line);
正排索引的参数就是一个文档需要处理的一行数据,所以需要先进行分词,获取单独的 title,url,content,然后再操作
因为正排索引建立的时机就是服务器启动的同时,然后根据所有文档操作一下。所以一开始的文档id完全凭我们自己的取值,那何不简单一点,就不用哈希表了(因为哈希表存在冲突的问题),我们可以用一个vector数组,那么数组的下标即为文档id的时候,我们可以真正做到O(1)的查找复杂度
这样,我们文档Id的一开始的取值就是0,每次新增的文档Id即为当前数组的大小
//根据一行 预处理 解析的文件,得到一个正排索引的节点,并插入到正排数组中
frontIdx* Index::BuildForward(const string& line){
// 对一行数据进行拆分 \3 为分割点,依次为 title url content
vector<string> nums;
common::Util::Split(line,"\3",&nums);
if(nums.size() != 3){
cout<<" file num error "<< nums.size()<<endl;
return nullptr;
}
frontIdx doc_info;
doc_info._docId = forward_index.size();
doc_info._title = nums[0];
doc_info._url = nums[1];
doc_info._content = nums[2];
forward_index.push_back(std::move(doc_info));
return &forward_index.back();
}
我们在正排索引中添加文档正文的时候,因为这里的文档正文可能非常多,并且这个变量也是一个临时变量,出了这个函数就被析构了,我们何不利用一些C++中的move与右值引用呢?把这个临时变量变成一个右值,直接使用vector中的右值拷贝,省事又省时。
那么作为返回值,我们需要返回这个新的文档的节点,这个时候不能直接返回&doc_info,因为我们已经通过move操作将doc_info变成nullptr了,再说这也是一个临时变量,不能作为地址去返回。

倒排索引
//根据正排索引节点,构造倒排索引节点
void BuildInverted(const frontIdx& doc_info);
这里我们需要做的就是分别对title和content进行关键字拆分(jieba分词),然后再分别统计分词后的关键字作为title和content出现的次数
struct backwardIdx{
int64_t _docId;
int _weight;
string _word;
};
这时候,文档的id和关键字_word我们就知道了,还需要我们定义一个计算权值的公式来,因为title的长度一般都远远少于content的长度,所以让title中关键字的出现次数的比重大一点
_weight = 10 * _titleCnt + _contentCnt;(不存在特殊性,完全自定义)
//根据正排索引节点,构造倒排索引节点
void Index::BuildInverted(const frontIdx& doc_info){
//统计关键字作为 标题 和正文的出现次数
struct WordCnt {
int _titleCnt;
int _contentCnt;
WordCnt()
:_titleCnt(0),_contentCnt(0)
{}
};
unordered_map<string,WordCnt> wordMap;
//针对标题进行分词
vector<string> titleWord;
CutWord(doc_info._title,&titleWord);
for(string word : titleWord){
//全部转为小写
boost::to_lower(word);
wordMap[word]._titleCnt++;
}
//针对正文进行分词
vector<string> contentWord;
CutWord(doc_info._content,&contentWord);
for(string word : contentWord){
boost::to_lower(word);
wordMap[word]._contentCnt++;
}
//统计结果,插入到倒排索引中
for(const auto& word_pair : wordMap){
backwardIdx backIdx;
backIdx._docId = doc_info._docId;
//自定义 权值 = 10 * titleCnt + contentCnt
backIdx._weight = 10 * word_pair.second._titleCnt + word_pair.second._contentCnt;
backIdx._word = word_pair.first;
vector<backwardIdx>& back_vector = inverted_index[word_pair.first];
back_vector.push_back(std::move(backIdx));
}
}
同理,在添加到倒排索引的数组中的时候,又是一个临时变量,那为了减少不必要的拷贝,我们还是使用move进行右值拷贝
jieba分词,正排查找,倒排查找
jieba分词
//jieba分词词典的路径
const char* const DICT_PATH = "../jieba_dict/jieba.dict.utf8";
const char* const HMM_PATH = "../jieba_dict/hmm_model.utf8";
const char* const USER_DICT_PATH = "../jieba_dict/user.dict.utf8";
const char* const IDF_PATH = "../jieba_dict/idf.utf8";
const char* const STOP_WORD_PATH = "../jieba_dict/stop_words.utf8";
Index::Index()
:jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH)
{
forward_index.clear();
inverted_index.clear();
}
jieba分词的使用,就是看了github上下载之后,大佬们写的测试程序,然后修改一下,做一个接口就可以了
// jieba分词 对语句进行分词
void Index::CutWord(const string& input,vector<string>* output){
jieba.CutForSearch(input,*output);
索引查找
没有什么特殊的,没有找到就返回nullptr,找到了就返回找到数据的指针
//查找正排索引
const frontIdx* Index::GetFrontIdx(const int64_t doc_id){
if(doc_id < 0 || doc_id >= forward_index.size()){
return nullptr;
}
return &forward_index[doc_id];
}
//查倒排索引
const vector<backwardIdx>* Index::GetBackwardIdx(const string& key){
auto it = inverted_index.find(key);
if(it == inverted_index.end()){
return nullptr;
}
return &(it->second);
}
索引的测试
#include "searcher.hpp"
#include 
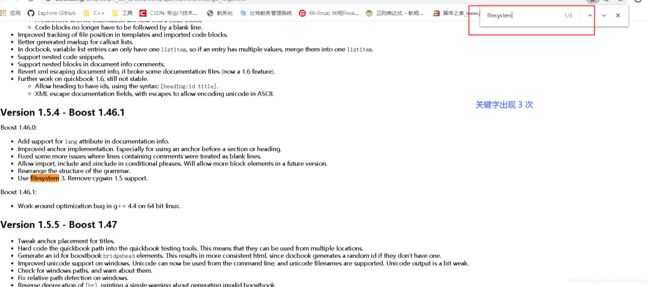
所搜索的关键字出现了三次,都是在正文中出现,权值为3