CDH优化(收藏篇)
目录
1 测试环境参考方案
1.0 资源:集群服务安排
1.1 优化:Cloudera Management
1.2 优化:Zookeeper
1.3 优化:HDFS
1.4 优化:YARN + MapReduce
1.5 优化:Kafka
1.6 优化:HBase
1.7 优化:Hive
1.8 优化:Oozie、Hue、Solr、Spark
2 线上集群参考方案
2.0 资源:集群服务安排
2.1 优化:Cloudera Management
2.2 优化:Zookeeper
2.3 优化:HDFS
2.4 优化:YARN + MapReduce
2.5 优化:Kafka
2.6 优化:HBase
2.7 优化:Hive
2.8 优化:Oozie、Hue、solr、spark
1 测试环境参考方案
1.0 资源:集群服务安排
- 表格方便大家复制修改
| 服务名称 | 子服务 | CM-24G | ZK-Kafka(3台)-12G | DataNode(3台)-64G | NameNode1-16G | NameNode2-16G | Resourcemanager1-16G | Resourcemanager2-16G | hive-hbase-24G | hive-hbase-24G |
|---|---|---|---|---|---|---|---|---|---|---|
| MySQL | MySQL | √ | ||||||||
| CM | Activity Monitor Alert Publisher Event Server Host Monitor Service Monitor |
√ √ √ √ √ |
||||||||
| HDFS | NameNode DataNode Failover Controller JournalNode |
X X X √ |
X √ X X |
√ X √ X |
√ X √ X |
|||||
| Yarn | NodeManager Resourcemanager JobHisoryServer |
√ X X |
X √ √ |
X √ √ |
||||||
| Zookeeper | Zookeeper Server | √ | ||||||||
| Kafka | Kafka Broker | √ | ||||||||
| Hive | Hive Metastore Server HiveServer2 Gateway(安装对应应用服务器) |
X √ √ |
X X √ |
X X √ |
√ X X |
√ X X |
||||
| Hbase | HMaster HRegionServer Thrift Server |
X √ √ |
√ X X |
√ X X |
||||||
| Oozie | Oozie Server | √ | ||||||||
| Hue | Hue Server Load Balancer |
X √ |
√ X |
|||||||
| Spark | History Server Gateway(安装对应应用服务器) |
X √ |
X √ |
√ X |
||||||
| Flume | Flume Agent (安装对应应用服务器) | |||||||||
| Sqoop | Sqoop(安装对应应用服务器) | |||||||||
| sorl | √ |
- 图


1.1 优化:Cloudera Management
这些服务主要是提供监控功能,目前的调整主要集中在内存放,以便有足够的资源 完成集群管理。
| 服务 | 选项 | 配置值 |
|---|---|---|
| Activity Monitor | Java Heap Size | 2G |
| Alert Publisher | Java Heap Size | 2G |
| Event Server | Java Heap Size | 2G |
| Host Monitor | Java Heap Size | 4G |
| Service Monitor | Java Heap Size | 4G |
1.2 优化:Zookeeper
| 服务 | 选项 | 配置值 |
|---|---|---|
| Zookeeper | Java Heap Size (堆栈大小) | 2G |
| Zookeeper | maxClientCnxns (最大客户端连接数) | 1024 |
| Zookeeper | dataDir (数据文件目录+数据持久化路径) | /hadoop/zookeeper (建议独立目录) |
| Zookeeper | dataLogDir (事务日志目录) | /hadoop/zookeeper_log (建议独立目录) |
| Zookeeper | maxSessionTimeout | 180000 |
1.3 优化:HDFS
| 服务 | 选项 | 配置值 |
|---|---|---|
| NameNode | Java Heap Size (堆栈大小)10 | 10G |
| NameNode | dfs.namenode.handler.count (详见3.3.2) | 30 |
| NameNode | dfs.namenode.service.handler.count (详见3.3.2) | 30 |
| NameNode | fs.permissions.umask-mode (使用默认值022) | 027(使用默认值022) |
| DataNode | Java Heap Size (堆栈大小) | 8G |
| DataNode | dfs.datanode.failed.volumes.tolerated (详见3.3.3) | 0 |
| DataNode | dfs.datanode.balance.bandwidthPerSec (DataNode 平衡带宽) | 100M |
| DataNode | dfs.datanode.handler.count (服务器线程数) | 64 |
| DataNode | dfs.datanode.max.transfer.threads (最大传输线程数) | 20480 |
| JournalNode | Java Heap Size (堆栈大小) | 512M |
1.3.1 数据块优化
dfs.blocksize = 128M
- 文件以块为单位进行切分存储,块通常设置的比较大(最小6M,默认128M),根据网络带宽计算最佳值。
- 块越大,寻址越快,读取效率越高,但同时由于MapReduce任务也是以块为最小单位来处理,所以太大的块不利于于对数据的并行处理。
- 一个文件至少占用一个块(如果一个1KB文件,占用一个块,但是占用空间还是1KB)
- 我们在读取HDFS上文件的时候,NameNode会去寻找block地址,寻址时间为传输时间的1%时,则为最佳状态。
- 目前磁盘的传输速度普遍为100MB/S
- 如果寻址时间约为10ms,则传输时间=10ms/0.01=1000ms=1s
- 如果传输时间为1S,传输速度为100MB/S,那么一秒钟我们就可以向HDFS传送100MB文件,设置块大小128M比较合适。
- 如果带宽为200MB/S,那么可以将block块大小设置为256M比较合适。
1.3.2 NameNode 的服务器线程的数量
- dfs.namenode.handler.count=20*log2(Cluster Size),比如集群规模为16 ,8以2为底的对数是4,故此参数设置为80
- dfs.namenode.service.handler.count=20*log2(Cluster Size),比如集群规模为16 ,8以2为底的对数是4,故此参数设置为80
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。该值需要设置为集群大小的自然对数乘以20,。
1.3.3 DataNode 停止提供服务前允许失败的卷的数量
DN多少块盘损坏后停止服务,默认为0,即一旦任何磁盘故障DN即关闭。 对盘较多的集群(例如DN有超过2块盘),磁盘故障是常态,通常可以将该值设置为1或2,避免频繁有DN下线。
1.4 优化:YARN + MapReduce
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| ResourceManager | Java Heap Size (堆栈大小) | 4G | |
| ResourceManager | yarn.scheduler.minimum-allocation-mb (最小容器内存) | 2G | 给应用程序 Container 分配的最小内存 |
| ResourceManager | yarn.scheduler.increment-allocation-mb (容器内存增量) | 512M | 如果使用 Fair Scheduler,容器内存允许增量 |
| ResourceManager | yarn.scheduler.maximum-allocation-mb (最大容器内存) | 32G | 给应用程序 Container 分配的最大内存 |
| ResourceManager | yarn.scheduler.minimum-allocation-vcores (最小容器虚拟 CPU 内核数量) | 1 | 每个 Container 申请的最小 CPU 核数 |
| ResourceManager | yarn.scheduler.increment-allocation-vcores (容器虚拟 CPU 内核增量) | 1 | 如果使用 Fair Scheduler,虚拟 CPU 内核允许增量 |
| ResourceManager | yarn.scheduler.maximum-allocation-vcores (最大容器虚拟 CPU 内核数量) | 16 | 每个 Container 申请的最大 CPU 核数 |
| ResourceManager | yarn.resourcemanager.recovery.enabled | true | 启用后,ResourceManager 中止时在群集上运行的任何应用程序将在 ResourceManager 下次启动时恢复,备注:如果启用 RM-HA,则始终启用该配置。 |
| NodeManager | Java Heap Size (堆栈大小) | 4G | |
| NodeManager | yarn.nodemanager.resource.memory-mb | 10G | 可分配给容器的物理内存数量,参照资源池内存90%左右 |
| NodeManager | yarn.nodemanager.resource.cpu-vcores | 20 | 可以为容器分配的虚拟 CPU 内核的数量,参照资源池内存90%左右 |
| ApplicationMaster | yarn.app.mapreduce.am.command-opts | 右红 | 传递到 MapReduce ApplicationMaster 的 Java 命令行参数 "-Djava.net.preferIPv4Stack=true " |
| ApplicationMaster | yarn.app.mapreduce.am.resource.mb (ApplicationMaster 内存) | 4G | |
| JobHistory | Java Heap Size (堆栈大小) | 1G | |
| MapReduce | mapreduce.map.memory.mb (Map 任务内存) | 4G | 一个MapTask可使用的资源上限。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| MapReduce | mapreduce.reduce.memory.mb (Reduce 任务内存) | 8G | 一个 ReduceTask 可使用的资源上限。如果 ReduceTask 实际使用的资源量超过该值,则会被强制杀死 |
| MapReduce | mapreduce.map.cpu.vcores | 2 | 每个 MapTask 可使用的最多 cpu core 数目 |
| MapReduce | mapreduce.reduce.cpu.vcores | 4 | 每个 ReduceTask 可使用的最多 cpu core 数目 |
| MapReduce | mapreduce.reduce.shuffle.parallelcopies | 20 | 每个 Reduce 去 Map 中取数据的并行数。 |
| MapReduce | mapreduce.task.io.sort.mb(Shuffle 的环形缓冲区大小) | 512M | 当排序文件时要使用的内存缓冲总量。注意:此内存由 JVM 堆栈大小产生(也就是:总用户 JVM 堆栈 - 这些内存 = 总用户可用堆栈空间) |
| MapReduce | mapreduce.map.sort.spill.percent | 80% | 环形缓冲区溢出的阈值 |
| MapReduce | mapreduce.task.timeout | 10分钟 | Task 超时时间,经常需要设置的一个参数,该参数表 达的意思为:如果一个 Task 在一定时间内没有任何进 入,即不会读取新的数据,也没有输出数据,则认为 该 Task 处于 Block 状态,可能是卡住了,也许永远会 卡住,为了防止因为用户程序永远 Block 住不退出, 则强制设置了一个该超时时间。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是 :AttemptID:attempt_12267239451721_123456_m_00 0335_0 Timed out after 600 secsContainer killed by the ApplicationMaster。 |
1.5 优化:Kafka
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| Kafka Broker | Java Heap Size of Broker | 2G | Broker堆栈大小 |
| Kafka Broker | Data Directories | 多块独立磁盘 | |
| Kafka 服务 | Maximum Message Size | 10M | 服务器可以接收的消息的最大大小。此属性必须与使用者使用的最大提取大小同步。否则,不守规矩的生产者可能会发布太大而无法消费的消息 |
| Kafka 服务 | Replica Maximum Fetch Size | 20M | 副本发送给leader的获取请求中每个分区要获取的最大字节数。此值应大于message.max.bytes。 |
| Kafka 服务 | Number of Replica Fetchers | 6 | 用于复制来自领导者的消息的线程数。增大此值将增加跟随者代理中I / O并行度。 |
1.6 优化:HBase
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| HBase | Java Heap Size | 18G | 客户端 Java 堆大小(字节)主要作用来缓存Table数据,但是flush时会GC,不要太大,根据集群资源,一般分配整个Hbase集群内存的70%,16->48G就可以了 |
| HBase | hbase.client.write.buffer | 512M | 写入缓冲区大小,调高该值,可以减少RPC调用次数,单数会消耗更多内存,较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。 |
| HBase Master | Java Heap Size | 8G | HBase Master 的 Java 堆栈大小 |
| HBase Master | hbase.master.handler.count | 300 | HBase Master 中启动的 RPC 服务器实例数量。 |
| HBase RegionServer | Java Heap Size | 15G | HBase RegionServer 的 Java 堆栈大小 |
| HBase RegionServer | hbase.regionserver.handler.count | 50 | RegionServer 中启动的 RPC 服务器实例数量,根据集群情况,可以适当增加该值,主要决定是客户端的请求数 |
| HBase RegionServer | hbase.regionserver.metahandler.count | 30 | 用于处理 RegionServer 中的优先级请求的处理程序的数量 |
| HBase RegionServer | zookeeper.session.timeout | 180000ms | ZooKeeper 会话延迟(以毫秒为单位)。HBase 将此作为建议的最长会话时间传递给 ZooKeeper 仲裁 |
| HBase RegionServer | hbase.hregion.memstore.flush.size | 1G | 如 memstore 大小超过此值,Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。 |
| HBase RegionServer | hbase.hregion.majorcompaction | 7 | 合并周期,在合格节点下,Region下所有的HFile会进行合并,非常消耗资源,在空闲时手动触发 |
| HBase RegionServer | hbase.hregion.majorcompaction.jitter | 0.5 | 抖动比率,根据上面的合并周期,有一个抖动比率,也不靠谱,还是手动好 |
| HBase RegionServer | hbase.hstore.compactionThreshold | 6 | 如在任意一个 HStore 中有超过此数量的 HStoreFiles,则将运行压缩以将所有 HStoreFiles 文件作为一个 HStoreFile 重新写入。(每次 memstore 刷新写入一个 HStoreFile)您可通过指定更大数量延长压缩,但压缩将运行更长时间。在压缩期间,更新无法刷新到磁盘。长时间压缩需要足够的内存,以在压缩的持续时间内记录所有更新。如太大,压缩期间客户端会超时。 |
| HBase RegionServer | hbase.client.scanner.caching | 1000 | 内存未提供数据的情况下扫描仪下次调用时所提取的行数。较高缓存值需启用较快速度的扫描仪,但这需要更多的内存且当缓存为空时某些下一次调用会运行较长时间 |
| HBase RegionServer | hbase.hregion.max.filesize | 50G | HStoreFile 最大大小。如果列组的任意一个 HStoreFile 超过此值,则托管 HRegion 将分割成两个 |
| HBase Master | hbase.master.logcleaner.plugins | 日志清除器插件 | org.apache.hadoop.hbase.master.cleaner.TimeToLiveLogCleaner |
| HBase | hbase.replication | false | 禁用复制 |
| HBase | hbase.master.logcleaner.ttl | 10min | 保留 HLogs 的最长时间,加上如上两条解决oldWALs增长问题 |
1.7 优化:Hive
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| HiveServer2 | Java Heap Size | 4G | |
| Hive MetaStore | Java Heap Size | 8G | |
| Hive Gateway | Java Heap Size | 2G | |
| HiveServer2 | hive.execution.engine | Spark | 执行引擎切换 |
| HiveServer2 | hive.fetch.task.conversion | more | Fetch抓取修改为more,可以使全局查找,字段查找,limit查找等都不走计算引擎,而是直接读取表对应储存目录下的文件,大大普通查询速度 |
| Hive | hive.exec.mode.local.auto(hive-site.xml 服务高级配置,客户端高级配置) | true | 开启本地模式,在单台机器上处理所有的任务,对于小的数据集,执行时间可以明显被缩短 |
| Hive | hive.exec.mode.local.auto.inputbytes.max(hive-site.xml 服务高级配置,客户端高级配置) | 50000000 | 文件不超过50M |
| Hive | hive.exec.mode.local.auto.input.files.max(hive-site.xml 服务高级配置,客户端高级配置) | 10 | 个数不超过10个 |
| Hive | hive.auto.convert.join | 开启 | 在join问题上,让小表放在左边 去左链接(left join)大表,这样可以有效的减少内存溢出错误发生的几率 |
| Hive | hive.mapjoin.smalltable.filesize(hive-site.xml 服务高级配置,客户端高级配置) | 50000000 | 50M以下认为是小表 |
| Hive | hive.map.aggr | 开启 | 默认情况下map阶段同一个key发送给一个reduce,当一个key数据过大时就发生数据倾斜。 |
| Hive | hive.groupby.mapaggr.checkinterval(hive-site.xml 服务高级配置,客户端高级配置) | 200000 | 在map端进行聚合操作的条目数目 |
| Hive | hive.groupby.skewindata(hive-site.xml 服务高级配置,客户端高级配置) | true | 有数据倾斜时进行负载均衡,生成的查询计划会有两个MR Job,第一个MR Job会将key加随机数均匀的分布到Reduce中,做部分聚合操作(预处理),第二个MR Job在根据预处理结果还原原始key,按照Group By Key分布到Reduce中进行聚合运算,完成最终操作 |
| Hive | hive.exec.parallel(hive-site.xml 服务高级配置,客户端高级配置) | true | 开启并行计算 |
| Hive | hive.exec.parallel.thread.number(hive-site.xml 服务高级配置,客户端高级配置) | 16 | 同一个sql允许的最大并行度,针对集群资源适当增加 |
1.8 优化:Oozie、Hue、Solr、Spark
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| Oozie | Java Heap Size | 1G | 堆栈大小 |
| Hue | Java Heap Size | 4G | 堆栈大小 |
| solr | Java Heap Size | 2G | 堆栈大小 |
| spark | Java Heap Size of History Server in Bytes | 2G | 历史记录服务器的Java堆大小 |
2 线上集群参考方案
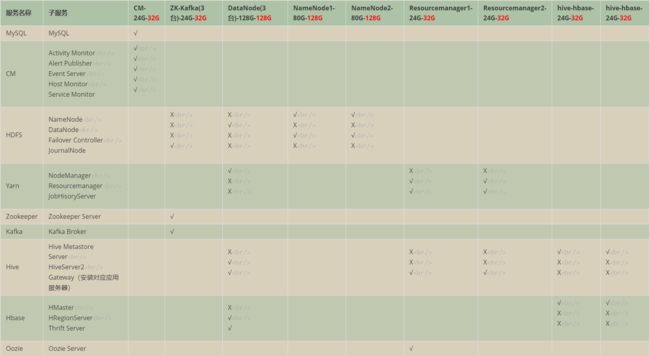
2.0 资源:集群服务安排
- 如下黑色字体是理论计算资源使用情况,红色字体是实际使用资源情况,注意理论值已经可以良好保证集群运行。
- 表格方便大家复制修改
| 服务名称 | 子服务 | CM-24G-32G | ZK-Kafka(3台)-24G-32G | DataNode(3台)-128G-128G | NameNode1-80G-128G | NameNode2-80G-128G | Resourcemanager1-24G-32G | Resourcemanager2-24G-32G | hive-hbase-24G-32G | hive-hbase-24G-32G |
|---|---|---|---|---|---|---|---|---|---|---|
| MySQL | MySQL | √ | ||||||||
| CM | Activity Monitor Alert Publisher Event Server Host Monitor Service Monitor |
√ √ √ √ √ |
||||||||
| HDFS | NameNode DataNode Failover Controller JournalNode |
X X X √ |
X √ X X |
√ X √ X |
√ X √ X |
|||||
| Yarn | NodeManager Resourcemanager JobHisoryServer |
√ X X |
X √ √ |
X √ √ |
||||||
| Zookeeper | Zookeeper Server | √ | ||||||||
| Kafka | Kafka Broker | √ | ||||||||
| Hive | Hive Metastore Server HiveServer2 Gateway(安装对应应用服务器) |
X √ √ |
X X √ |
X X √ |
√ X X |
√ X X |
||||
| Hbase | HMaster HRegionServer Thrift Server |
X √ √ |
√ X X |
√ X X |
||||||
| Oozie | Oozie Server | √ | ||||||||
| Hue | Hue Server Load Balancer |
X √ |
√ X |
|||||||
| Spark | History Server Gateway(安装对应应用服务器) |
X √ |
X √ |
√ X |
||||||
| Flume | Flume Agent (安装对应应用服务器) | |||||||||
| Sqoop | Sqoop(安装对应应用服务器) | |||||||||
| sorl | √ |
- 图

2.1 优化:Cloudera Management
这些服务主要是提供监控功能,目前的调整主要集中在内存放,以便有足够的资源 完成集群管理。
| 服务 | 选项 | 配置值 |
|---|---|---|
| Activity Monitor | Java Heap Size | 2G |
| Alert Publisher | Java Heap Size | 2G |
| Event Server | Java Heap Size | 2G |
| Host Monitor | Java Heap Size | 4G |
| Service Monitor | Java Heap Size | 4G |
2.2 优化:Zookeeper
| 服务 | 选项 | 配置值 |
|---|---|---|
| Zookeeper | Java Heap Size (堆栈大小) | 4G |
| Zookeeper | maxClientCnxns (最大客户端连接数) | 1024 |
| Zookeeper | dataDir (数据文件目录+数据持久化路径) | /hadoop/zookeeper (建议独立目录) |
| Zookeeper | dataLogDir (事务日志目录) | /hadoop/zookeeper_log (建议独立目录) |
| Zookeeper | maxSessionTimeout | 180000 |
2.3 优化:HDFS
| 服务 | 选项 | 配置值 |
|---|---|---|
| NameNode | Java Heap Size (堆栈大小) | 56G |
| NameNode | dfs.namenode.handler.count (详见3.3.2) | 80 |
| NameNode | dfs.namenode.service.handler.count (详见3.3.2) | 80 |
| NameNode | fs.permissions.umask-mode (使用默认值022) | 027(使用默认值022) |
| DataNode | Java Heap Size (堆栈大小) | 8G |
| DataNode | dfs.datanode.failed.volumes.tolerated (详见3.3.3) | 1 |
| DataNode | dfs.datanode.balance.bandwidthPerSec (DataNode 平衡带宽) | 100M |
| DataNode | dfs.datanode.handler.count (服务器线程数) | 64 |
| DataNode | dfs.datanode.max.transfer.threads (最大传输线程数) | 20480 |
| JournalNode | Java Heap Size (堆栈大小) | 1G |
2.3.1 数据块优化
dfs.blocksize = 128M
- 文件以块为单位进行切分存储,块通常设置的比较大(最小6M,默认128M),根据网络带宽计算最佳值。
- 块越大,寻址越快,读取效率越高,但同时由于MapReduce任务也是以块为最小单位来处理,所以太大的块不利于于对数据的并行处理。
- 一个文件至少占用一个块(如果一个1KB文件,占用一个块,但是占用空间还是1KB)
- 我们在读取HDFS上文件的时候,NameNode会去寻找block地址,寻址时间为传输时间的1%时,则为最佳状态。
- 目前磁盘的传输速度普遍为100MB/S
- 如果寻址时间约为10ms,则传输时间=10ms/0.01=1000ms=1s
- 如果传输时间为1S,传输速度为100MB/S,那么一秒钟我们就可以向HDFS传送100MB文件,设置块大小128M比较合适。
- 如果带宽为200MB/S,那么可以将block块大小设置为256M比较合适。
2.3.2 NameNode 的服务器线程的数量
- dfs.namenode.handler.count=20*log2(Cluster Size),比如集群规模为16 ,8以2为底的对数是4,故此参数设置为80
- dfs.namenode.service.handler.count=20*log2(Cluster Size),比如集群规模为16 ,8以2为底的对数是4,故此参数设置为80
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。该值需要设置为集群大小的自然对数乘以20,。
2.3.3 DataNode 停止提供服务前允许失败的卷的数量
DN多少块盘损坏后停止服务,默认为0,即一旦任何磁盘故障DN即关闭。 对盘较多的集群(例如DN有超过2块盘),磁盘故障是常态,通常可以将该值设置为1或2,避免频繁有DN下线。
2.4 优化:YARN + MapReduce
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| ResourceManager | Java Heap Size (堆栈大小) | 4G | |
| ResourceManager | yarn.scheduler.minimum-allocation-mb (最小容器内存) | 2G | 给应用程序 Container 分配的最小内存 |
| ResourceManager | yarn.scheduler.increment-allocation-mb (容器内存增量) | 512M | 如果使用 Fair Scheduler,容器内存允许增量 |
| ResourceManager | yarn.scheduler.maximum-allocation-mb (最大容器内存) | 32G | 给应用程序 Container 分配的最大内存 |
| ResourceManager | yarn.scheduler.minimum-allocation-vcores (最小容器虚拟 CPU 内核数量) | 1 | 每个 Container 申请的最小 CPU 核数 |
| ResourceManager | yarn.scheduler.increment-allocation-vcores (容器虚拟 CPU 内核增量) | 1 | 如果使用 Fair Scheduler,虚拟 CPU 内核允许增量 |
| ResourceManager | yarn.scheduler.maximum-allocation-vcores (最大容器虚拟 CPU 内核数量) | 16 | 每个 Container 申请的最大 CPU 核数 |
| ResourceManager | yarn.resourcemanager.recovery.enabled | true | 启用后,ResourceManager 中止时在群集上运行的任何应用程序将在 ResourceManager 下次启动时恢复,备注:如果启用 RM-HA,则始终启用该配置。 |
| NodeManager | Java Heap Size (堆栈大小) | 4G | |
| NodeManager | yarn.nodemanager.resource.memory-mb | 40G | 可分配给容器的物理内存数量,参照资源池内存90%左右 |
| NodeManager | yarn.nodemanager.resource.cpu-vcores | 32 | 可以为容器分配的虚拟 CPU 内核的数量,参照资源池内存90%左右 |
| ApplicationMaster | yarn.app.mapreduce.am.command-opts | 右红 | 传递到 MapReduce ApplicationMaster 的 Java 命令行参数 "-Djava.net.preferIPv4Stack=true " |
| ApplicationMaster | yarn.app.mapreduce.am.resource.mb (ApplicationMaster 内存) | 4G | |
| JobHistory | Java Heap Size (堆栈大小) | 2G | |
| MapReduce | mapreduce.map.memory.mb (Map 任务内存) | 4G | 一个MapTask可使用的资源上限。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| MapReduce | mapreduce.reduce.memory.mb (Reduce 任务内存) | 8G | 一个 ReduceTask 可使用的资源上限。如果 ReduceTask 实际使用的资源量超过该值,则会被强制杀死 |
| MapReduce | mapreduce.map.cpu.vcores | 2 | 每个 MapTask 可使用的最多 cpu core 数目 |
| MapReduce | mapreduce.reduce.cpu.vcores | 4 | 每个 ReduceTask 可使用的最多 cpu core 数目 |
| MapReduce | mapreduce.reduce.shuffle.parallelcopies | 20 | 每个 Reduce 去 Map 中取数据的并行数。 |
| MapReduce | mapreduce.task.io.sort.mb(Shuffle 的环形缓冲区大小) | 512M | 当排序文件时要使用的内存缓冲总量。注意:此内存由 JVM 堆栈大小产生(也就是:总用户 JVM 堆栈 - 这些内存 = 总用户可用堆栈空间) |
| MapReduce | mapreduce.map.sort.spill.percent | 80% | 环形缓冲区溢出的阈值 |
| MapReduce | mapreduce.task.timeout | 10分钟 | Task 超时时间,经常需要设置的一个参数,该参数表 达的意思为:如果一个 Task 在一定时间内没有任何进 入,即不会读取新的数据,也没有输出数据,则认为 该 Task 处于 Block 状态,可能是卡住了,也许永远会 卡住,为了防止因为用户程序永远 Block 住不退出, 则强制设置了一个该超时时间。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是 :AttemptID:attempt_12267239451721_123456_m_00 0335_0 Timed out after 600 secsContainer killed by the ApplicationMaster。 |
2.5 优化:Kafka
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| Kafka Broker | Java Heap Size of Broker | 2G | Broker堆栈大小 |
| Kafka Broker | Data Directories | 多块独立磁盘 | |
| Kafka 服务 | Maximum Message Size | 10M | 服务器可以接收的消息的最大大小。此属性必须与使用者使用的最大提取大小同步。否则,不守规矩的生产者可能会发布太大而无法消费的消息 |
| Kafka 服务 | Replica Maximum Fetch Size | 20M | 副本发送给leader的获取请求中每个分区要获取的最大字节数。此值应大于message.max.bytes。 |
| Kafka 服务 | Number of Replica Fetchers | 6 | 用于复制来自领导者的消息的线程数。增大此值将增加跟随者代理中I / O并行度。 |
2.6 优化:HBase
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| HBase | Java Heap Size | 18G | 客户端 Java 堆大小(字节)主要作用来缓存Table数据,但是flush时会GC,不要太大,根据集群资源,一般分配整个Hbase集群内存的70%,16->48G就可以了 |
| HBase | hbase.client.write.buffer | 512M | 写入缓冲区大小,调高该值,可以减少RPC调用次数,单数会消耗更多内存,较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。 |
| HBase Master | Java Heap Size | 8G | HBase Master 的 Java 堆栈大小 |
| HBase Master | hbase.master.handler.count | 300 | HBase Master 中启动的 RPC 服务器实例数量。 |
| HBase RegionServer | Java Heap Size | 31G | HBase RegionServer 的 Java 堆栈大小 |
| HBase RegionServer | hbase.regionserver.handler.count | 100 | RegionServer 中启动的 RPC 服务器实例数量,根据集群情况,可以适当增加该值,主要决定是客户端的请求数 |
| HBase RegionServer | hbase.regionserver.metahandler.count | 60 | 用于处理 RegionServer 中的优先级请求的处理程序的数量 |
| HBase RegionServer | zookeeper.session.timeout | 180000ms | ZooKeeper 会话延迟(以毫秒为单位)。HBase 将此作为建议的最长会话时间传递给 ZooKeeper 仲裁 |
| HBase RegionServer | hbase.hregion.memstore.flush.size | 1G | 如 memstore 大小超过此值,Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。 |
| HBase RegionServer | hbase.hregion.majorcompaction | 0 | 合并周期,在合格节点下,Region下所有的HFile会进行合并,非常消耗资源,在空闲时手动触发 |
| HBase RegionServer | hbase.hregion.majorcompaction.jitter | 0 | 抖动比率,根据上面的合并周期,有一个抖动比率,也不靠谱,还是手动好 |
| HBase RegionServer | hbase.hstore.compactionThreshold | 6 | 如在任意一个 HStore 中有超过此数量的 HStoreFiles,则将运行压缩以将所有 HStoreFiles 文件作为一个 HStoreFile 重新写入。(每次 memstore 刷新写入一个 HStoreFile)您可通过指定更大数量延长压缩,但压缩将运行更长时间。在压缩期间,更新无法刷新到磁盘。长时间压缩需要足够的内存,以在压缩的持续时间内记录所有更新。如太大,压缩期间客户端会超时。 |
| HBase RegionServer | hbase.client.scanner.caching | 1000 | 内存未提供数据的情况下扫描仪下次调用时所提取的行数。较高缓存值需启用较快速度的扫描仪,但这需要更多的内存且当缓存为空时某些下一次调用会运行较长时间 |
| HBase RegionServer | hbase.hregion.max.filesize | 50G | HStoreFile 最大大小。如果列组的任意一个 HStoreFile 超过此值,则托管 HRegion 将分割成两个 |
| HBase Master | hbase.master.logcleaner.plugins | 日志清除器插件 | org.apache.hadoop.hbase.master.cleaner.TimeToLiveLogCleaner |
| HBase | hbase.replication | false | 禁用复制 |
| HBase | hbase.master.logcleaner.ttl | 10min | 保留 HLogs 的最长时间,加上如上两条解决oldWALs增长问题 |
2.7 优化:Hive
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| HiveServer2 | Java Heap Size | 4G | |
| Hive MetaStore | Java Heap Size | 8G | |
| Hive Gateway | Java Heap Size | 2G | |
| Hive | hive.execution.engine | Spark | 执行引擎切换 |
| Hive | hive.fetch.task.conversion | more | Fetch抓取修改为more,可以使全局查找,字段查找,limit查找等都不走计算引擎,而是直接读取表对应储存目录下的文件,大大普通查询速度 |
| Hive | hive.exec.mode.local.auto(hive-site.xml 服务高级配置,客户端高级配置) | true | 开启本地模式,在单台机器上处理所有的任务,对于小的数据集,执行时间可以明显被缩短 |
| Hive | hive.exec.mode.local.auto.inputbytes.max(hive-site.xml 服务高级配置,客户端高级配置) | 50000000 | 文件不超过50M |
| Hive | hive.exec.mode.local.auto.input.files.max(hive-site.xml 服务高级配置,客户端高级配置) | 10 | 个数不超过10个 |
| Hive | hive.auto.convert.join | 开启 | 在join问题上,让小表放在左边 去左链接(left join)大表,这样可以有效的减少内存溢出错误发生的几率 |
| Hive | hive.mapjoin.smalltable.filesize(hive-site.xml 服务高级配置,客户端高级配置) | 50000000 | 50M以下认为是小表 |
| Hive | hive.map.aggr | 开启 | 默认情况下map阶段同一个key发送给一个reduce,当一个key数据过大时就发生数据倾斜。 |
| Hive | hive.groupby.mapaggr.checkinterval(hive-site.xml 服务高级配置,客户端高级配置) | 200000 | 在map端进行聚合操作的条目数目 |
| Hive | hive.groupby.skewindata(hive-site.xml 服务高级配置,客户端高级配置) | true | 有数据倾斜时进行负载均衡,生成的查询计划会有两个MR Job,第一个MR Job会将key加随机数均匀的分布到Reduce中,做部分聚合操作(预处理),第二个MR Job在根据预处理结果还原原始key,按照Group By Key分布到Reduce中进行聚合运算,完成最终操作 |
| Hive | hive.exec.parallel(hive-site.xml 服务高级配置,客户端高级配置) | true | 开启并行计算 |
| Hive | hive.exec.parallel.thread.number(hive-site.xml 服务高级配置,客户端高级配置) | 16 | 同一个sql允许的最大并行度,针对集群资源适当增加 |
2.8 优化:Oozie、Hue、solr、spark
| 服务 | 选项 | 配置值 | 参数说明 |
|---|---|---|---|
| Oozie | Java Heap Size | 2G | 堆栈大小 |
| Hue | Java Heap Size | 4G | 堆栈大小 |
| solr | Java Heap Size | 8G | 堆栈大小 |
| spark | Java Heap Size of History Server in Bytes | 4G | 历史记录服务器的Java堆大小 |