线性回归学习
以下笔记来自于黑马程序员十三天入门机器学习
线性回归
- 1. 什么是线性回归
-
- 1.1 定义与公式
- 1..2 线性回归的特征与⽬标的关系分析
- 2 线性回归api初步使⽤
-
- 2.1 线性回归API
- 2.2 举例
- 2.3 步骤分析
- 2.4 代码过程
- 3.线性回归的损失和优化
-
- 3.1 损失函数
- 3.2 优化算法
-
- 3.2.1 正规⽅程
-
- 3.2.1.1什么是正规方程
- 3.2.1.2 正规⽅程求解举例
- 3.2.1.3 正规⽅程的推导
- 3.2.2 梯度下降(Gradient Descent)
-
- 3.2.2.1 什么是梯度下降
- 3.2.2.2 梯度的概念
- 3.2.2.3 梯度下降举例
- 3.2.2.4 梯度下降(Gradient Descent) 公式
- 3.3 梯度下降和正规⽅程的对⽐
-
- 3.3.1 两种方法对比
- 3.3.2 算法选择依据:
- 4.梯度下降⽅法介绍
-
- 4.1 详解梯度下降算法
-
- 4.1.2 梯度下降法的推导流程
- 5.线性回归api再介绍
- 6 ⽋拟合和过拟合
-
- 6.1 定义
- 6.2 原因以及解决办法
- 6.3 正则化
-
- 6.3.1 什么是正则化
- 6.3.2 正则化类别
- 7.正则化线性模型
-
- 7.1 Ridge Regression (岭回归, ⼜名 Tikhonov regularization)
- 7.2 Lasso Regression(Lasso 回归)
- 7.3 Elastic Net (弹性⽹络)
- 8.线性回归的改进-岭回归
-
- 8.1 API
- 8.2 观察正则化程度的变化, 对结果的影响?
- 8.3 波⼠顿房价预测
- 9.模型的保存和加载
-
- 9.1 sklearn模型的保存和加载API
- 9.2 线性回归的模型保存加载案例
1. 什么是线性回归
1.1 定义与公式
线性回归(Linear regression)是利⽤回归⽅程(函数)对⼀个或多个⾃变量(特征值)和因变量(⽬标值)之间关系进⾏建模的⼀种分析⽅式

- 线性回归⽤矩阵表示举例

1…2 线性回归的特征与⽬标的关系分析
线性回归当中主要有两种模型, ⼀种是线性关系, 另⼀种是⾮线性关系。 在这⾥我们只能画⼀个平⾯更好去理解, 所以都⽤单个特征或两个特征举例⼦。
- 线性关系
- 单变量线性关系:
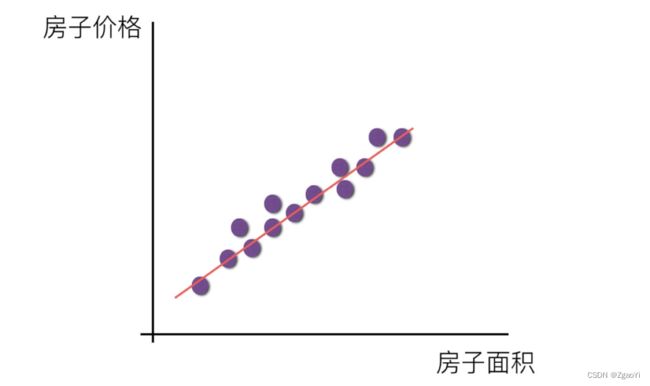
- 多变量线性关系
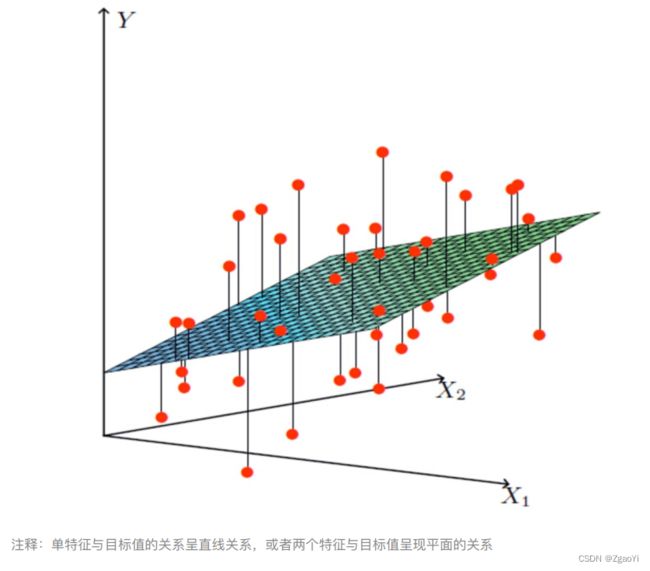
- 单变量线性关系:
- ⾮线性关系
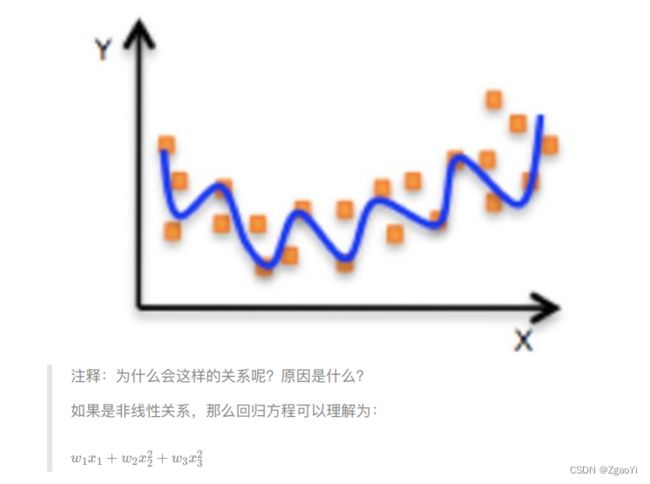
2 线性回归api初步使⽤
2.1 线性回归API
- sklearn.linear_model.LinearRegression()
- LinearRegression.coef_: 回归系数
2.2 举例
2.3 步骤分析
1.获取数据集
2.数据基本处理(该案例中省略)
3.特征⼯程(该案例中省略)
4.机器学习
5.模型评估(该案例中省略)
2.4 代码过程
- 导⼊模块
from sklearn.linear_model import LinearRegression
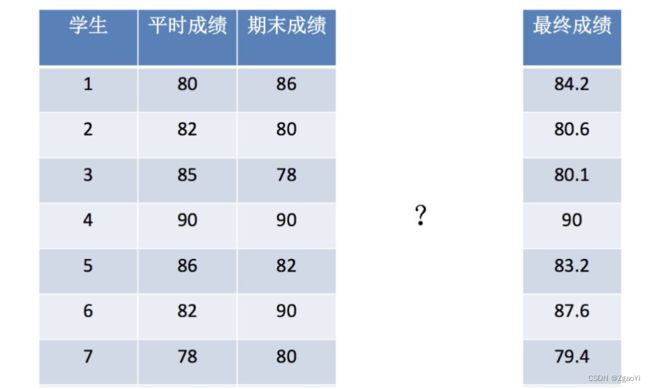
- 构造数据集
x = [[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]]
y = [84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]
- 机器学习-- 模型训练
# 实例化API
estimator = LinearRegression()
# 使⽤fit⽅法进⾏训练
estimator.fit(x,y)
estimator.coef_
estimator.predict([[100, 80]])
3.线性回归的损失和优化
3.1 损失函数

3.2 优化算法
如何去求模型当中的W, 使得损失最⼩? (⽬的是找到最⼩损失对应的W值)
- 线性回归经常使⽤的两种优化算法
- 正规⽅程
- 梯度下降法
3.2.1 正规⽅程
3.2.1.1什么是正规方程
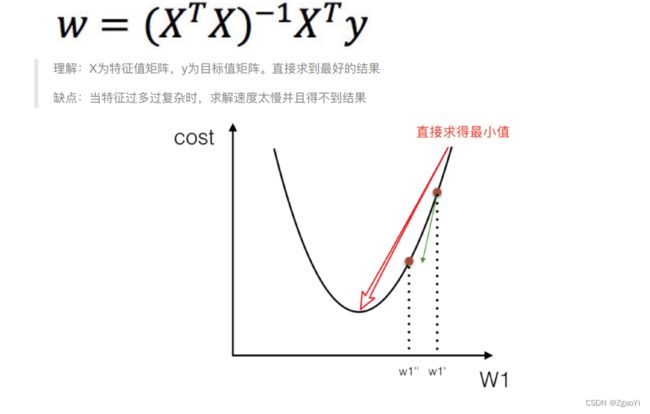
3.2.1.2 正规⽅程求解举例
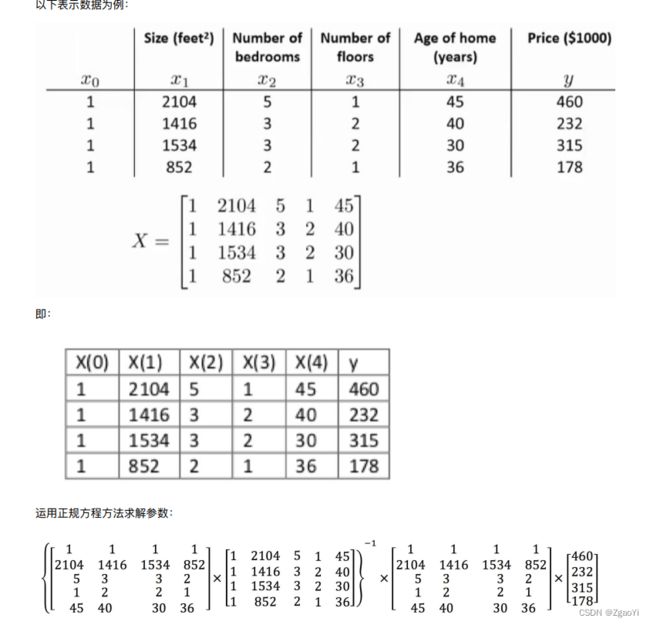
3.2.1.3 正规⽅程的推导
- 推导⽅式⼀:
把该损失函数转换成矩阵写法:

3.2.2 梯度下降(Gradient Descent)
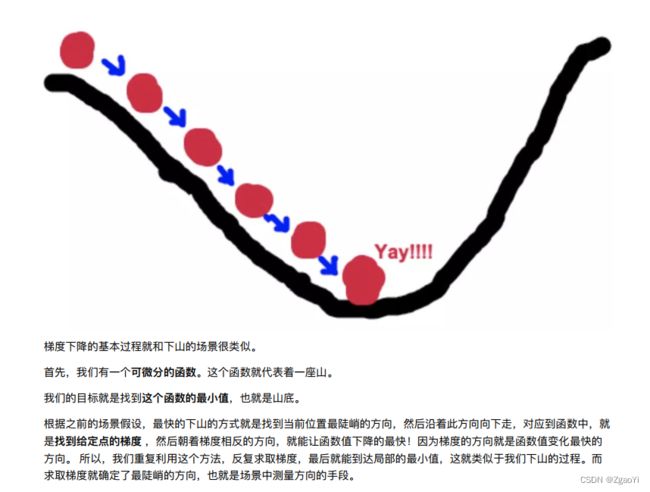
3.2.2.1 什么是梯度下降
梯度下降法的基本思想可以类⽐为⼀个下⼭的过程。
假设这样⼀个场景:
⼀个⼈被困在⼭上, 需要从⼭上下来(i.e. 找到⼭的最低点, 也就是⼭⾕)。 但此时⼭上的浓雾很⼤, 导致可视度很低。因此, 下⼭的路径就⽆法确定, 他必须利⽤⾃⼰周围的信息去找到下⼭的路径。 这个时候, 他就可以利⽤梯度下降算法来帮助⾃⼰下⼭。
具体来说就是, 以他当前的所处的位置为基准, 寻找这个位置最陡峭的地⽅, 然后朝着⼭的⾼度下降的地⽅⾛, (同理, 如果我们的⽬标是上⼭, 也就是爬到⼭顶, 那么此时应该是朝着最陡峭的⽅向往上⾛) 。 然后每⾛⼀段距离, 都反复采⽤同⼀个⽅法, 最后就能成功的抵达⼭⾕。
3.2.2.2 梯度的概念

3.2.2.3 梯度下降举例
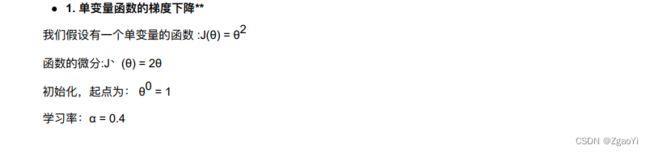

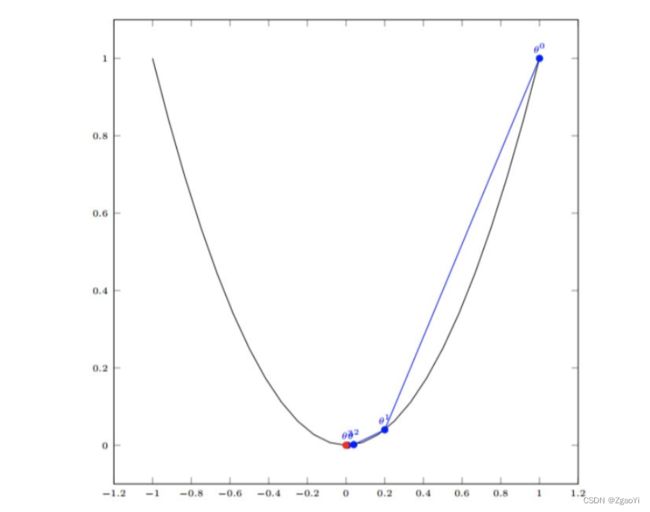

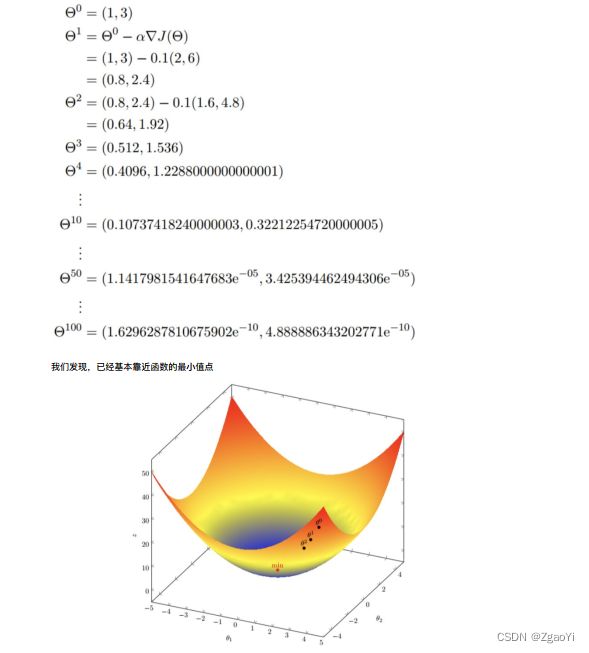
3.2.2.4 梯度下降(Gradient Descent) 公式
-
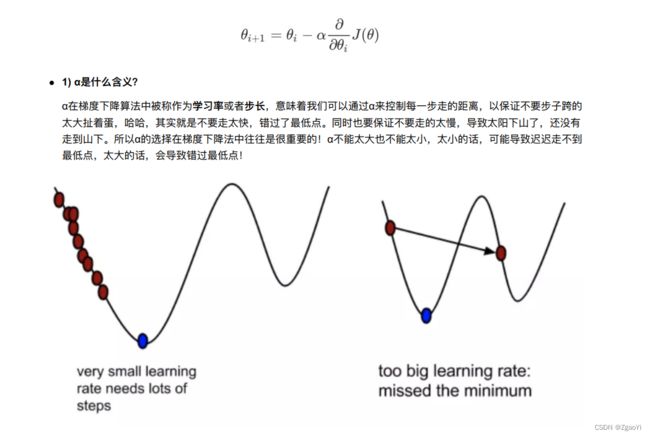
- 为什么梯度要乘以⼀个负号?
梯度前加⼀个负号, 就意味着朝着梯度相反的⽅向前进! 我们在前⽂提到, 梯度的⽅向实际就是函数在此点上升最快的⽅向! ⽽我们需要朝着下降最快的⽅向⾛, ⾃然就是负的梯度的⽅向, 所以此处需要加上负号我们通过两个图更好理解梯度下降的过程
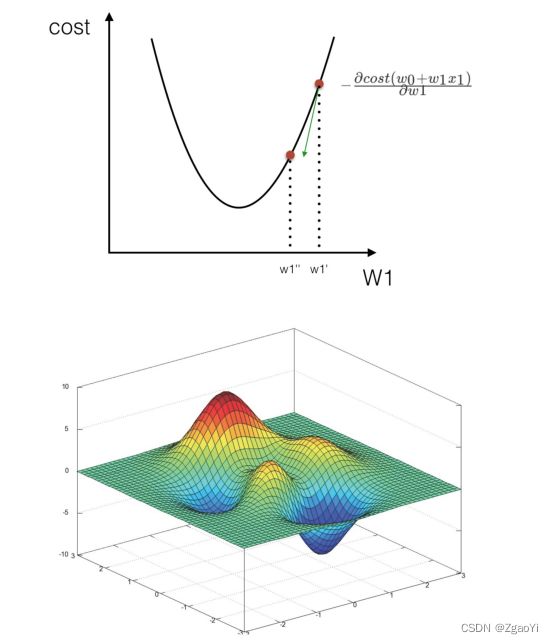
3.3 梯度下降和正规⽅程的对⽐
3.3.1 两种方法对比
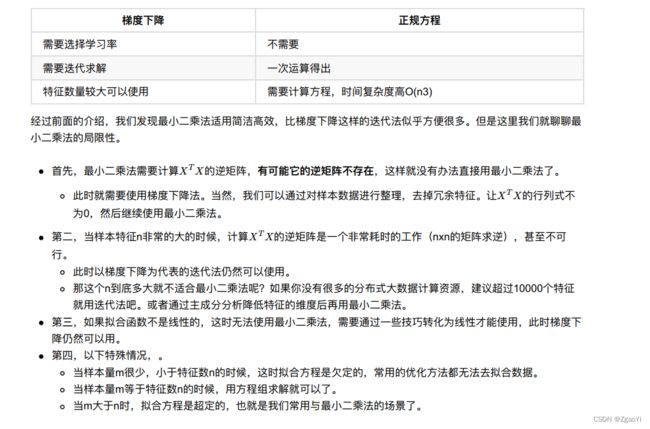
3.3.2 算法选择依据:

4.梯度下降⽅法介绍
4.1 详解梯度下降算法

4.1.2 梯度下降法的推导流程



5.线性回归api再介绍
- sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规⽅程优化
- 参数
- fit_intercept: 是否计算偏置
- 属性
- LinearRegression.coef_: 回归系数
- LinearRegression.intercept_: 偏置
- sklearn.linear_model.SGDRegressor(loss=“squared_loss”, fit_intercept=True, learning_rate =‘invscaling’,eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习, 它⽀持不同的loss函数和正则化惩罚项来拟合线性回归模型。
- 参数:
- loss:损失类型
- loss=”squared_loss”: 普通最⼩⼆乘法
- fit_intercept: 是否计算偏置
- learning_rate : string, optional
- 学习率填充
- ‘constant’: eta = eta0
- ‘optimal’: eta = 1.0 / (alpha * (t + t0)) [default]
- ‘invscaling’: eta = eta0 / pow(t, power_t)
- power_t=0.25:存在⽗类当中
- 对于⼀个常数值的学习率来说, 可以使⽤learning_rate=’constant’ , 并使⽤eta0来指定学习率。
- loss:损失类型
- 属性:
- SGDRegressor.coef_: 回归系数
- SGDRegressor.intercept_: 偏置
6 ⽋拟合和过拟合
6.1 定义
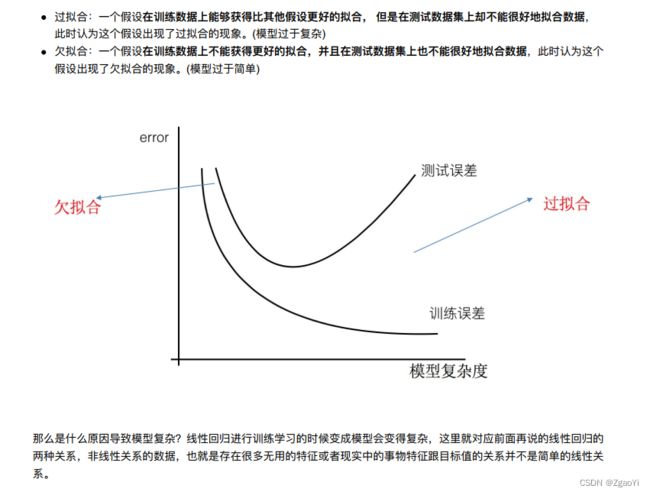
6.2 原因以及解决办法

6.3 正则化
6.3.1 什么是正则化
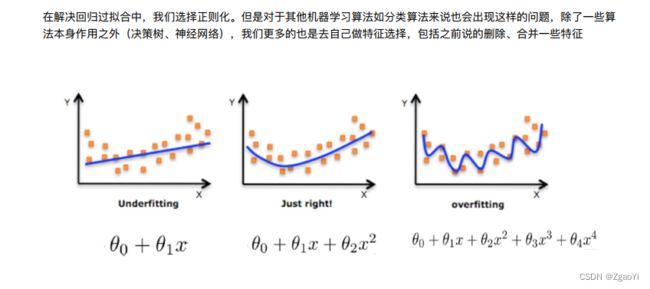
- 如何解决?

6.3.2 正则化类别

7.正则化线性模型
7.1 Ridge Regression (岭回归, ⼜名 Tikhonov regularization)

7.2 Lasso Regression(Lasso 回归)


7.3 Elastic Net (弹性⽹络)

8.线性回归的改进-岭回归
8.1 API

8.2 观察正则化程度的变化, 对结果的影响?
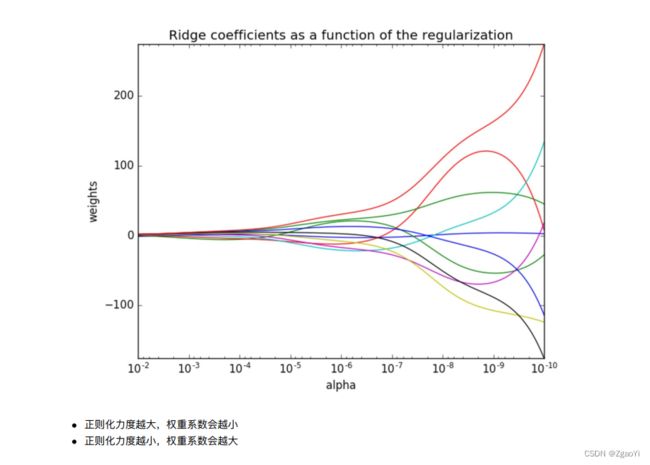
8.3 波⼠顿房价预测
def linear_model3():
"""
线性回归:岭回归
:return:
"""
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征⼯程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习-线性回归(岭回归)
estimator = Ridge(alpha=1)
# estimator = RidgeCV(alphas=(0.1, 1, 10))
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\n", y_predict)
print("模型中的系数为:\n", estimator.coef_)
print("模型中的偏置为:\n", estimator.intercept_)
# 5.2 评价
# 均⽅误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\n", error)
9.模型的保存和加载
9.1 sklearn模型的保存和加载API
- from sklearn.externals import joblib
- 保存: joblib.dump(estimator, ‘test.pkl’)
- 加载: estimator = joblib.load(‘test.pkl’)
9.2 线性回归的模型保存加载案例
def load_dump_demo():
"""
模型保存和加载
:return:
"""
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征⼯程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习-线性回归(岭回归)
# # 4.1 模型训练
# estimator = Ridge(alpha=1)
# estimator.fit(x_train, y_train)
# #
# 4.2 模型保存
# joblib.dump(estimator, "./data/test.pkl")
# 4.3 模型加载
estimator = joblib.load("./data/test.pkl")
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\n", y_predict)
print("模型中的系数为:\n", estimator.coef_)
print("模型中的偏置为:\n", estimator.intercept_)
# 5.2 评价
# 均⽅误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\n", error)