三、docker-k8s入门
参考https://blog.csdn.net/hanbing6174/article/details/90092800
一、硬件环境准备(virtualBox)
使用virtualBox尝试安装集成,最低配置 2G、2CPU。
1、新建虚拟机,命名【k8s_master】,并设置网卡1、网卡2
【网卡一】是为了虚拟机可以联网。
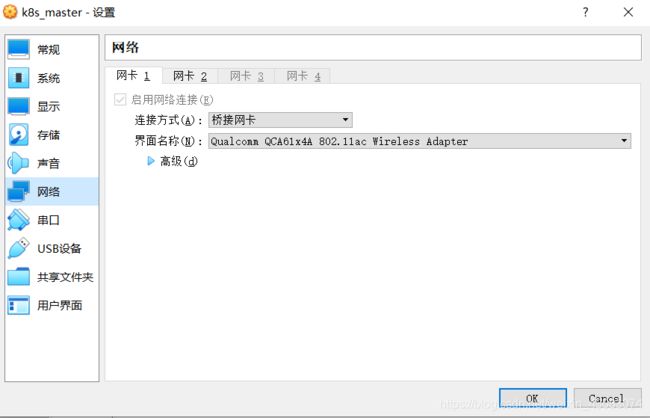
【网卡2(host-noly)】是为了可以通过xshell工具连接虚拟机,且虚拟机之间可互相通信。
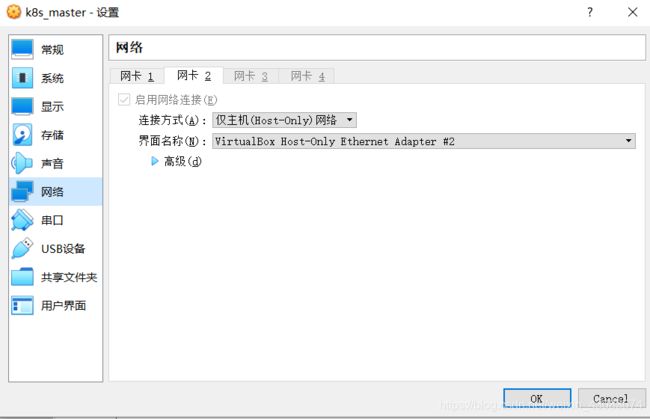
启动虚拟机,输入
ip addr
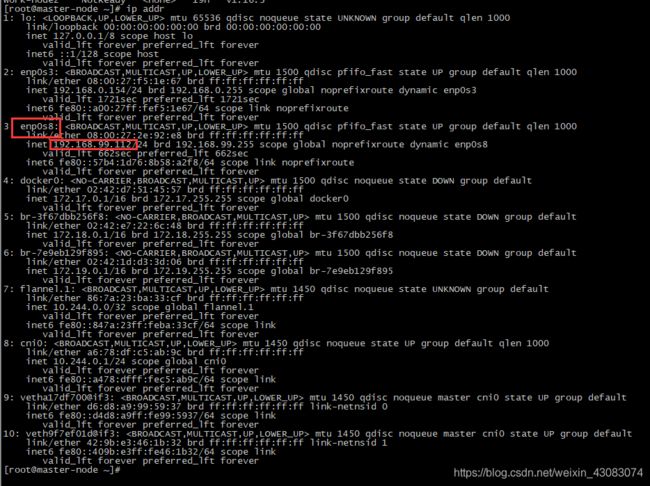
上面的enp0s3其实对应的就是“网卡1”,而enp0s8就是我们刚添加的“网卡2“
可使用xshell等工具 ,连接虚拟机操作了,如我的IP是192.168.99.112。
最后修改hostname 为 master-node。
二、软件准备
1、防火墙一定要提前关闭,否则在后续安装K8S集群的时候是个trouble maker。执行下面语句关闭,并禁用开机启动:
systemctl stop firewalld & systemctl disable firewalld
2、关闭Swap,类似ElasticSearch集群,在安装K8S集群时,Linux的Swap内存交换机制是一定要关闭的,否则会因为内存交换而影响性能以及稳定性。这里,我们可以提前进行设置:
- 执行swapoff -a可临时关闭,但系统重启后恢复
- 编辑/etc/fstab,注释掉包含swap的那一行即可,重启后可永久关闭,如下所示

3、关闭SeLinux
setenforce 0
4、配置yum源
a、首先去/etc/yum.repos.d/目录,删除该目录下所有repo文件(备份到backup目录)
[root@bogon yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Media.repo CentOS-Vault.repo
CentOS-CR.repo CentOS-fasttrack.repo CentOS-Sources.repo
[root@bogon yum.repos.d]# mkdir backup
[root@bogon yum.repos.d]# mv Cen* backup
b、下载centos基础yum源配置(这里用的是阿里云的镜像)
curl -o CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
c、下载docker的yum源配置
curl -o docker-ce.repo https://download.docker.com/linux/centos/docker-ce.repo
d、配置kubernetes的yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
e、执行下列命令刷新yum源缓存
# yum clean all
# yum makecache
# yum repolist
三、安装docker(k8s对版本有要求,我这装的是 18.06.3版本)
1、卸载原来的版本**(原本未安装,忽略此步骤)**
rpm -qa | grep docker

2、使用yum remove卸载软件**(原本未安装,忽略此步骤)**
# yum remove docker-1.13.1-53.git774336d.el7.centos.x86_64
# yum remove docker-client-1.13.1-53.git774336d.el7.centos.x86_64
# yum remove docker-common-1.13.1-53.git774336d.el7.centos.x86_64
再使用docker命令会提示docker不存在
![]()
3、安装指定版本docker
yum install docker-ce-18.06.3.ce-3.el7 -y
如果需要安装其他版本,则
yum list docker-ce --showduplicates | sort -r
列出所有版本

再使用 yum install docker-ce-版本号 -y 选择所要版本安装
4、启动Docker服务并激活开机启动
systemctl start docker & systemctl enable docker
5、运行一条命令验证一下:
docker run hello-world
6、修改docker Cgroup属性与 k8s 中的一致
命令查看
docker info | grep -i cgroup

我这里K8S Cgroup Driver是 systemd, docker是cgroupfs/g(不是我图片显示的system,图片已改过了),所以需要修改docker属性。
若 /etc/docker/目录下无daemon.json,则手动创建。并写入
{ "exec-opts": ["native.cgroupdriver=systemd"] }
重启docker
systemctl daemon-reload && systemctl restart docker
再次输入命令,查看是否一致
docker info | grep -i cgroup
四、kubeadm安装k8s
1、由于之前已经设置好了kubernetes的yum源,我们只要执行
yum install -y kubeadm
系统就会帮我们自动安装最新版的kubeadm了,一共会安装kubelet、kubeadm、kubectl、kubernetes-cni这四个程序。
kubeadm:k8集群的一键部署工具,通过把k8的各类核心组件和插件以pod的方式部署来简化安装过程
kubelet:运行在每个节点上的node agent,k8集群通过kubelet真正的去操作每个节点上的容器,由于需要直接操作宿主机的各类资源,所以没有放在pod里面,还是通过服务的形式装在系统里面
kubectl:kubernetes的命令行工具,通过连接api-server完成对于k8的各类操作
kubernetes-cni:k8的虚拟网络设备,通过在宿主机上虚拟一个cni0网桥,来完成pod之间的网络通讯,作用和docker0类似。
安装完后,关闭系统。是的,关闭系统。
四、复制k8s_master虚拟机,为k8s_node1,k8s_node2(注意MAC地址设定),并启动
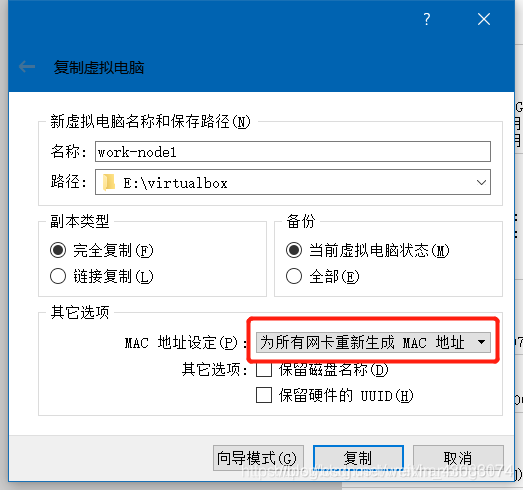
修改hostname 分别为 work-node1,work-node2。
并在三个虚拟机 分别配置host地址

五、主节点初始化K8S
主节点就是本文提到的“master-node”虚拟机。 执行下列代码,开始master节点的初始化工作:
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.56.109
注意这边的–pod-network-cidr=10.244.0.0/16,是k8的网络插件所需要用到的配置信息,用来给node分配子网段,用到的网络插件是flannel,就是这么配,其他的插件也有相应的配法。选项–apiserver-advertise-address表示绑定的网卡IP,这里一定要绑定前面提到的enp0s8网卡,否则会默认使用enp0s3网卡。
一堆信息如下:
[root@master-node ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.56.109
I0511 02:44:59.286251 4117 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I0511 02:44:59.286366 4117 version.go:97] falling back to the local client version: v1.14.1
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
提示:/proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
解决方法如下:
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
再次执行上面的初始化代码。等待一会之后又出现了新的问题:
[root@master-node ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.56.109
I0511 02:47:13.060854 4194 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I0511 02:47:13.060910 4194 version.go:97] falling back to the local client version: v1.14.1
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.14.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-controller-manager:v1.14.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-scheduler:v1.14.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-proxy:v1.14.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/pause:3.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/etcd:3.3.10: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns:1.3.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
ERROR ImagePull指的是gcr.io无法访问(谷歌自己的容器镜像仓库)。我们的思路是,先从国内阿里云拉取镜像,然后再修改名字,改为和谷歌容器镜像仓库名字相同的镜像。当然,你可以按照错误提示,一个个执行:
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.16.3
下载完后修改tag:
docker tag
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.16.3
k8s.gcr.io/k8s.gcr.io/kube-apiserver:v1.16.3
为了执行效率更高,我只做了一个shell文件,可以批处理执行。内容如下,你可以复制下来,然后保存成“k8s_docker.sh”文件:
echo ""
echo "=========================================================="
echo "Pull Kubernetes v1.16.3 Images from aliyuncs.com ......"
echo "=========================================================="
echo ""
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.16.3
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.16.3
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.16.3
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.16.3
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.15-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.16.3 k8s.gcr.io/kube-apiserver:v1.16.3
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.16.3 k8s.gcr.io/kube-controller-manager:v1.16.3
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.16.3 k8s.gcr.io/kube-scheduler:v1.16.3
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.16.3 k8s.gcr.io/kube-proxy:v1.16.3
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.15-0 k8s.gcr.io/etcd:3.3.15-0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.2 k8s.gcr.io/coredns:1.6.2
执行后,可以看到,镜像已经拉取到了本地,并且名字已经改为初始化中提到的名字。再次执行
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.56.109
[root@master-node share]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.56.109
I0511 03:04:59.473877 5085 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I0511 03:04:59.474160 5085 version.go:97] falling back to the local client version: v1.14.1
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [master-node kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.56.109]
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [master-node localhost] and IPs [192.168.56.109 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [master-node localhost] and IPs [192.168.56.109 127.0.0.1 ::1]
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 16.002135 seconds
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --experimental-upload-certs
[mark-control-plane] Marking the node master-node as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master-node as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: vmwftc.2034sih0ok8kyy3w
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.56.109:6443 --token vmwftc.2034sih0ok8kyy3w \
--discovery-token-ca-cert-hash sha256:c4bac97ad9d4ab4f8ef37bfe623e56acf0532b58208cecb54b1b3d264895330e
可以看到终于安装成功了,kudeadm帮你做了大量的工作,包括kubelet配置、各类证书配置、kubeconfig配置、插件安装等等。注意最后一行,kubeadm提示你,其他节点需要加入集群的话,只需要执行这条命令就行了:
kubeadm join 192.168.56.109:6443 --token vmwftc.2034sih0ok8kyy3w \
--discovery-token-ca-cert-hash sha256:c4bac97ad9d4ab4f8ef37bfe623e56acf0532b58208cecb54b1b3d264895330e
请记住你自己电脑上的这个命令,接下来配置计算节点的时候会用到,里面包含了加入集群所需要的token。
同时kubeadm还提醒你,要完成全部安装,还需要安装一个网络插件kubectl apply -f [podnetwork].yaml。同时也提示你,需要执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
上述三条命令逐条执行。
六、启动kubelet
安装kubelet、kubeadm、kubectl三者后,要求启动kubelet:
systemctl enable kubelet && systemctl start kubelet
执行完以后,查看节点情况:
[root@master-node share]# kubectl get node
NAME STATUS ROLES AGE VERSION
master-node NotReady master 3m40s v1.14.1
发现只有主节点。这时当然了,以为我们还没把计算节点加进来。
再查看下pod情况
[root@master-node share]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-fb8b8dccf-ggw6c 0/1 Pending 0 5m7s
coredns-fb8b8dccf-xwgl5 0/1 Pending 0 5m7s
etcd-master-node 1/1 Running 0 4m28s
kube-apiserver-master-node 1/1 Running 0 4m28s
kube-controller-manager-master-node 1/1 Running 0 4m21s
kube-proxy-rdpv9 1/1 Running 0 5m7s
kube-scheduler-master-node 1/1 Running 0 4m2s
可以看到coredns的两个pod都是pending状态,这是因为网络插件还没有安装。我们kubernetes初始化语句可以看出,我用到的是flannel,其实还有其他的网络插件,比如Calico网络,但是我一直配不好,对应的pod总是显示失败状态。Calico网络改天再回过头来研究。
安装flannel比较简单,执行代码如下:
kubectl create -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果后面的网址不通,可以先把yml文件下载到本地,然后导入虚拟机执行。上述代码执行结果如下:
[root@master-node share]# kubectl create -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
podsecuritypolicy.extensions/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.extensions/kube-flannel-ds-amd64 created
daemonset.extensions/kube-flannel-ds-arm64 created
daemonset.extensions/kube-flannel-ds-arm created
daemonset.extensions/kube-flannel-ds-ppc64le created
daemonset.extensions/kube-flannel-ds-s390x created
再次查看pods,发现都正常了:
[root@master-node share]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-fb8b8dccf-ggw6c 1/1 Running 0 15m
coredns-fb8b8dccf-xwgl5 1/1 Running 0 15m
etcd-master-node 1/1 Running 0 14m
kube-apiserver-master-node 1/1 Running 0 14m
kube-controller-manager-master-node 1/1 Running 0 14m
kube-flannel-ds-amd64-dc92s 1/1 Running 0 2m41s
kube-proxy-rdpv9 1/1 Running 0 15m
kube-scheduler-master-node 1/1 Running 0 14m
至此,主节点配置完毕!
七、计算节点初始化K8S
计算节点就是本问提到的“work-node1”和“work-node2”。计算节点同样需要docker镜像,只是不像主节点那样多。但是为了省事,我们同样执行k8s_docker.sh,这其中可能包含了一些无用的镜像,但是无关紧要。
分别执行k8s_docker.sh:
[root@work-node1 share]# ./k8s_docker.sh
执行节点加入命令
kubeadm join 192.168.56.109:6443 --token vmwftc.2034sih0ok8kyy3w \
--discovery-token-ca-cert-hash sha256:c4bac97ad9d4ab4f8ef37bfe623e56acf0532b58208cecb54b1b3d264895330e
回到主节点,查看当前节点状况:
[root@master-node share]# kubectl get node
NAME STATUS ROLES AGE VERSION
master-node Ready master 27m v1.14.1
work-node1 Ready <none> 88s v1.14.1
work-node2 Ready <none> 52s v1.14.1
发现两个计算节点都已经加进来了。
至此kubernets配置完毕。
以下为开发中碰到的一些问题
一、计算节点执行kubeadm join命令时,报错
参考文章 https://blog.csdn.net/qianghaohao/article/details/82624920
kubeadm join 192.168.99.112:6443 --token 7gdywr.i2rqrrcaxp3rjrwr --discovery-token-ca-cert-hash sha256:01edf6857eb95e03cd1e463cc826daaa74a21e08f6b39d7d751b2faa57f1ee44
[root@work-node2 home]# kubeadm join 192.168.99.112:6443 --token 7gdywr.i2rqrrcaxp3rjrwr --discovery-token-ca-cert-hash sha256:01edf6857eb95e03cd1e463cc826daaa74a21e08f6b39d7d751b2faa57f1ee44
[preflight] Running pre-flight checks
[WARNING Hostname]: hostname "work-node2" could not be reached
[WARNING Hostname]: hostname "work-node2": lookup work-node2 on 192.168.0.1:53: no such host
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
出现如上问题的主要原因是之前 kubeadm init 初始化过,所以一些配置文件及服务均已存在,重新执行 kubeadm join 时必然
会导致冲突,解决方法如下:
1.先执行 kubeadm reset,重新初始化节点配置:
kubeadm reset
[root@work-node2 home]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W1205 01:19:19.988016 13814 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /etc/cni/net.d /var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
reset之后再次执行join命令
kubeadm join 192.168.99.112:6443 --token 7gdywr.i2rqrrcaxp3rjrwr --discovery-token-ca-cert-hash sha256:01edf6857eb95e03cd1e463cc826daaa74a21e08f6b39d7d751b2faa57f1ee44
[root@work-node2 home]# kubeadm join 192.168.99.112:6443 --token 7gdywr.i2rqrrcaxp3rjrwr --discovery-token-ca-cert-hash sha256:01edf6857eb95e03cd1e463cc826daaa74a21e08f6b39d7d751b2faa57f1ee44
[preflight] Running pre-flight checks
[WARNING Hostname]: hostname "work-node2" could not be reached
[WARNING Hostname]: hostname "work-node2": lookup work-node2 on 192.168.0.1:53: no such host
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.16" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
二、master节点pod 卡 init:0/1状态
参考
https://www.v2ex.com/t/547244
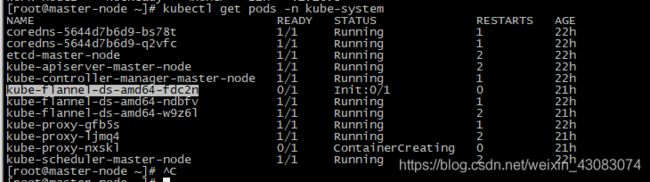
kubectl get node,出现notReady 状态,出现这个原因发现是对应的计算节点的没安装对应镜像、运行,计算节点运行docker ps 可以看到无相关镜像运行,以下为正常的状态
![]()
。解决方案是 重新执行 上面的k8s-docker.sh 执行文件就行,并执行kubeamd join命令