深度学习之基于Xception实现四种动物识别
本次实验类似于猫狗大战,只不过将两种动物识别变为了四种动物识别。
本文的重点是卷积神经网络Xception的实践,在之前的学习中,我们已经实验过其他几种比较常用的网络模型,但是Xception网络并未实践过。在弄本科毕设的时候,一个好朋友的毕设就是基于Xception实现海洋垃圾的识别,最终的实验效果达到了99%左右,由此可见Xception的模型性能还是不错的。
本次实验基于Xception实现动物识别,最终的模型准确率在95%左右。
1.导入库
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import os,pathlib,PIL
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
2.数据加载
data_dir = "E:/tmp/.keras/datasets/animal_photos"
data_dir = pathlib.Path(data_dir)
img_count = len(list(data_dir.glob('*/*')))
共4000张图片
all_images_paths = list(data_dir.glob('*'))
all_images_paths = [str(path) for path in all_images_paths]
all_label_names = [path.split("\\")[5].split(".")[0] for path in all_images_paths]
分为四类: ['cat', 'chook', 'dog', 'horse']
超参数的设置:
height = 224
width = 224
epochs =10
batch_size = 128
图像增强:
一共分为4类,每一类有1000张图片,数据并不是很多,因此对原数据进行数据加强。并按照8:2的比例划分训练集与测试集。
train_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
rotation_range=45,
shear_range=0.2,
zoom_range=0.2,
validation_split=0.2,
horizontal_flip=True
)
train_ds = train_data_gen.flow_from_directory(
directory=data_dir,
target_size=(height,width),
batch_size=batch_size,
shuffle=True,
class_mode='categorical',
subset='training'
)
test_ds = train_data_gen.flow_from_directory(
directory=data_dir,
target_size=(height,width),
batch_size=batch_size,
shuffle=True,
class_mode='categorical',
subset='validation'
)
显示图像:
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds:
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(all_label_names[np.argmax(labels[i])])
plt.axis("off")
break
plt.show()
3.Xception模型
Xception是Inception的改进版本,创新点便是 深度可分离卷积。
深度可分离卷积 = 深度卷积+逐点卷积。具体步骤如下所示:
第一步:Depthwise 卷积,对输入的每个channel,分别进行 3 × 3 卷积操作,并将结果 concat。
第二步:Pointwise 卷积,对 Depthwise 卷积中的 concat 结果,进行 1 × 1 卷积操作。

标准卷积与深度可分离卷积的对比如下所示:图片来源
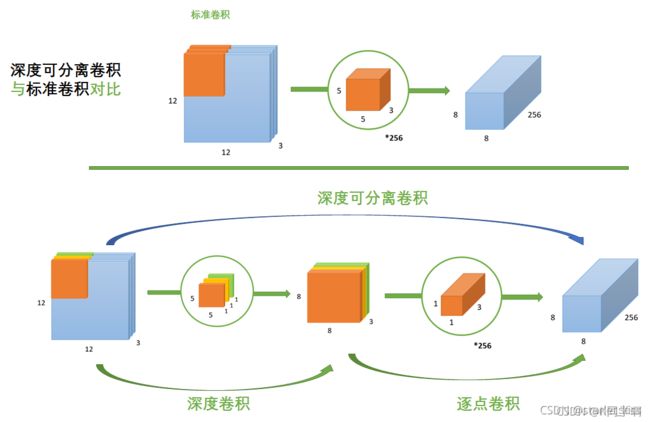
既然最终的结果是一样的,那为什么深度可分离卷积方式更优呢?
原因就是利用深度可分离卷积,参数更少,从而在迭代更新的过程中,计算量就更小。
本次实验利用迁移学习采用官方模型进行训练
base_model = tf.keras.applications.Xception(weights = 'imagenet',include_top = False,pooling = 'max',input_shape = (height,width,3))
base_model.trainable = False#前面的参数设置为不可训练
input = base_model.input
x = tf.keras.layers.Dense(256,activation='relu')(base_model.output)
x = tf.keras.layers.Dense(128,activation='relu')(x)
output = tf.keras.layers.Dense(4,activation='sigmoid')(x)
model = tf.keras.models.Model(inputs = input,outputs = output)
优化器的设置:
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=300,
decay_rate=0.96,
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
网络编译&&训练
model.compile(
optimizer = optimizer,
loss = "categorical_crossentropy",
metrics = ['accuracy']
)
history = model.fit(
train_ds,
validation_data = test_ds,
epochs = epochs
)
Accuracy与Loss图如下所示:

模型准确率比较高,在95%左右。
4.预测&&混淆矩阵
模型保存:
model.save("E:/Users/yqx/PycharmProjects/animal_rec/model.h5")
模型加载:
model = tf.keras.models.load_model("E:/Users/yqx/PycharmProjects/animal_rec/model.h5")
预测:
plt.figure(figsize=(50,50))
num = 0
for images,labels in test_ds:
for i in range(64):
ax = plt.subplot(8,8,i+1)
plt.imshow(images[i])
img_array = tf.expand_dims(images[i],0)
pre = model.predict(img_array)
if np.argmax(pre) == np.argmax(labels[i]):
plt.title(all_label_names[np.argmax(pre)])
else:
plt.title("False :"+str(all_label_names[np.argmax(pre)]))
if np.argmax(pre) == np.argmax(labels[i]):
num += 1
plt.axis("off")
break
plt.suptitle("The Acc rating is:{}".format(num / 64))
plt.show()
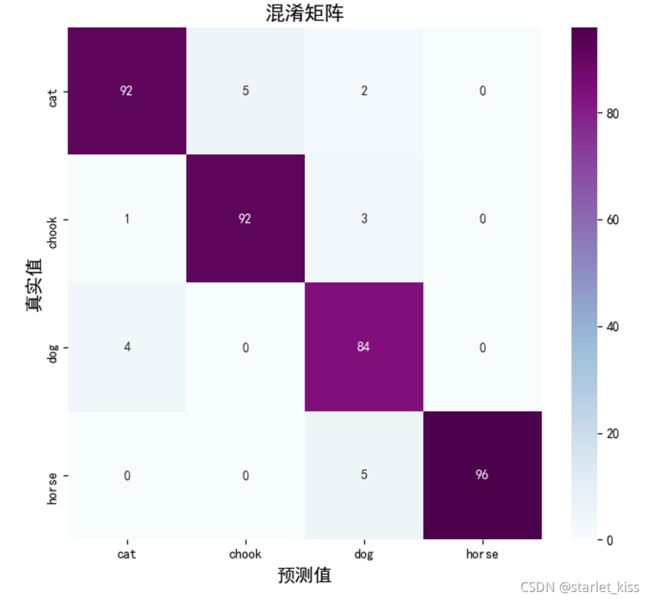
混淆矩阵的绘制:
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
#绘制混淆矩阵
def plot_cm(labels,pre):
conf_numpy = confusion_matrix(labels,pre)#根据实际值和预测值绘制混淆矩阵
conf_df = pd.DataFrame(conf_numpy,index=all_label_names,columns=all_label_names)#将data和all_label_names制成DataFrame
plt.figure(figsize=(8,7))
sns.heatmap(conf_df,annot=True,fmt="d",cmap="BuPu")#将data绘制为混淆矩阵
plt.title('混淆矩阵',fontsize = 15)
plt.ylabel('真实值',fontsize = 14)
plt.xlabel('预测值',fontsize = 14)
plt.show()
test_pre = []
test_label = []
num = 0
for images,labels in test_ds:
num = num + 1
for image,label in zip(images,labels):
img_array = tf.expand_dims(image,0)#增加一个维度
pre = model.predict(img_array)#预测结果
test_pre.append(all_label_names[np.argmax(pre)])#将预测结果传入列表
test_label.append(all_label_names[np.argmax(label)])#将真实结果传入列表
if num == 3:#由于硬件问题,只测试了3个batch_size
break
plot_cm(test_label,test_pre)#绘制混淆矩阵
努力加油a啊