数据分析真不是一门省油的灯,搞的人晕头转向,而且涉及到很多复杂的计算,还是书读少了,小学毕业的我,真是死了不少脑细胞,
学习二元Logistic回归有一段时间了,今天跟大家分享一下学习心得,希望多指教!
二元Logistic,从字面上其实就可以理解大概是什么意思,Logistic中文意思为“逻辑”但是这里,并不是逻辑的意思,而是通过logit变换来命名的,二元一般指“两种可能性”就好比逻辑中的“是”或者“否”一样,
Logistic 回归模型的假设检验——常用的检验方法有似然比检验(likelihood ratio test) 和 Wald检验)
似然比检验的具体步骤如下:
1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0
2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InL1
3:最后比较两个对数似然函数值的差异,若两个模型分别包含l个自变量和P个自变量,记似然比统计量G的计算公式为 G=2(InLP - InLl). 在零假设成立的条件下,当样本含量n较大时,G统计量近似服从自由度为 V = P-l 的 x平方分布,如果只是对一个回归系数(或一个自变量)进行检验,则 v=1.
wald 检验,用u检验或者X平方检验,推断各参数βj是否为0,其中u= bj / Sbj, X的平方=(bj / Sbj), Sbj 为回归系数的标准误
这里的“二元”主要针对“因变量”所以跟“曲线估计”里面的Logistic曲线模型不一样,二元logistic回归是指因变量为二分类变量是的回归分析,对于这种回归模型,目标概率的取值会在(0-1),但是回归方程的因变量取值却落在实数集当中,这个是不能够接受的,所以,可以先将目标概率做Logit变换,这样它的取值区间变成了整个实数集,再做回归分析就不会有问题了,采用这种处理方法的回归分析,就是Logistic回归
设因变量为y, 其中“1” 代表事件发生, “0”代表事件未发生,影响y的 n个自变量分别为 x1, x2 ,x3 xn等等
记事件发生的条件概率为 P
那么P= 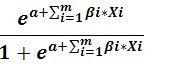 事件未发生的概理为 1-P
事件未发生的概理为 1-P
事件发生跟”未发生的概率比 为( p / 1-p ) 事件发生比,记住Odds
将Odds做对数转换,即可得到Logistic回归模型的线性模型: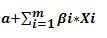
还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示:
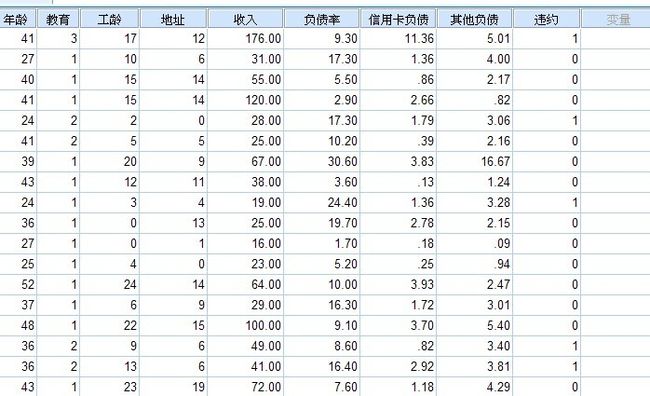
上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下:
1:设置随机抽样的随机种子,如下图所示:

选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、
2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面:
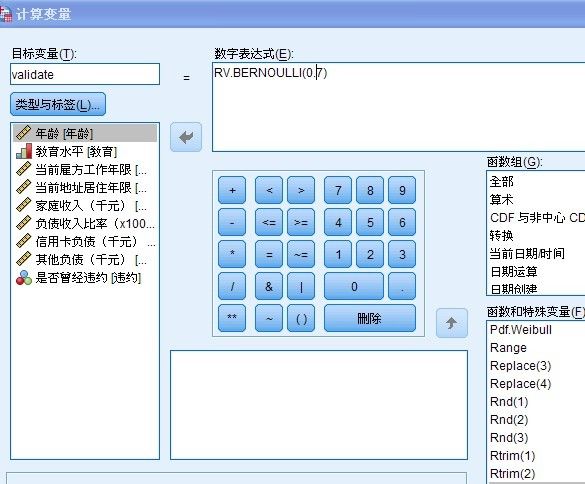
在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值
如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"
为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件”
点击“如果”按钮,进入如下界面:

如果“违约”变量中,确实存在缺失值,那么当使用"missing”函数的时候,它的返回值应该为“1”或者 为“true", 为了剔除”缺失值“所以,结果必须等于“0“ 也就是不存在缺失值的现象
点击 ”继续“按钮,返回原界面,如下所示:
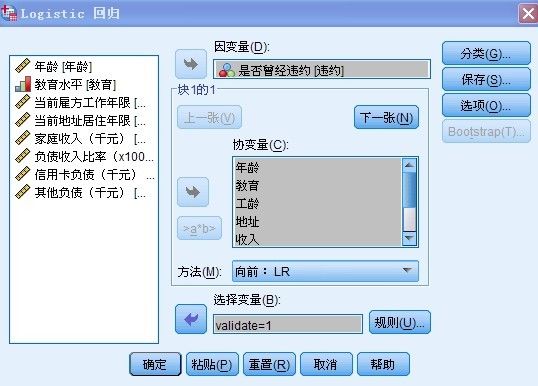
将是“是否曾经违约”作为“因变量”拖入因变量选框,分别将其他8个变量拖入“协变量”选框内, 在方法中,选择:forward.LR方法
将生成的新变量“validate" 拖入"选择变量“框内,并点击”规则“设置相应的规则内容,如下所示:
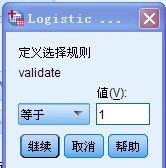
设置validate 值为1,此处我们只将取值为1的记录纳入模型建立过程,其它值(例如:0)将用来做结论的验证或者预测分析,当然你可以反推,采用0作为取值记录
点击继续,返回,再点击“分类”按钮,进入如下页面
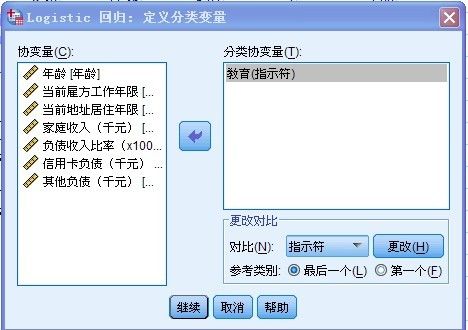
在所有的8个自变量中,只有“教育水平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育水平分为:初中,高中,大专,本科,研究生等等, 参考类别选择:“最后一个” 在对比中选择“指示符” 点击继续按钮,返回
再点击—“保存”按钮,进入界面:

在“预测值"中选择”概率, 在“影响”中选择“Cook距离” 在“残差”中选择“学生化”
点击继续,返回,再点击“选项”按钮,进入如下界面:

分析结果如下:
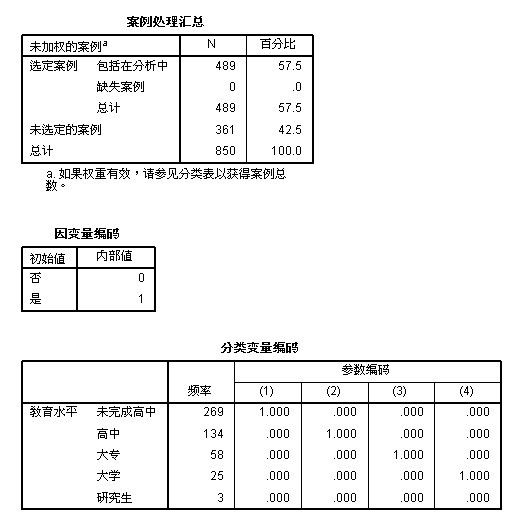
1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替, 在“分类变量编码”中教育水平分为5类, 如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为 489个
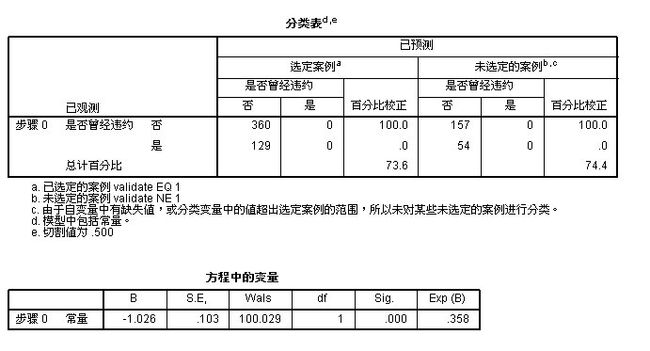
1:在“分类表”中可以看出: 预测有360个是“否”(未违约) 有129个是“是”(违约)
2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026, 标准误差为:0.103
那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,
B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著
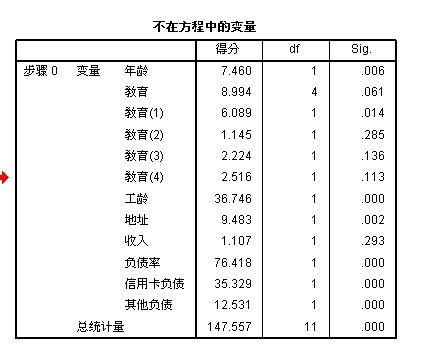
1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内
表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:
 (公式中 (Xi- X¯) 少了一个平方)
(公式中 (Xi- X¯) 少了一个平方)
下面来举例说明这个计算过程:(“年龄”自变量的得分为例)
从“分类表”中可以看出:有129人违约,违约记为“1” 则 违约总和为 129, 选定案例总和为489
那么: y¯ = 129/489 = 0.2638036809816
x¯ = 16951 / 489 = 34.664621676892
所以:∑(Xi-x¯)² = 30074.9979
y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216
则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372
则:[∑Xi(yi - y¯)]^2 = 43570.8
所以:
=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)
计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:

从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!

1:从“块1” 中可以看出:采用的是:向前步进 的方法, 在“模型系数的综合检验”表中可以看出: 所有的SIG 几乎都为“0” 而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,
根据设定的显著性值 和 自由度,可以算出 卡方临界值, 公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果
2:在“模型汇总“中可以看出:Cox&SnellR方 和 Nagelkerke R方 拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,
最大似然平方的对数值 都比较大,明显是显著的
似然数对数计算公式为:
计算过程太费时间了,我就不举例说明 计算过程了
Cox&SnellR方的计算值 是根据:
1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)
2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)
再根据公式: 即可算出:Cox&SnellR方的值!
即可算出:Cox&SnellR方的值!
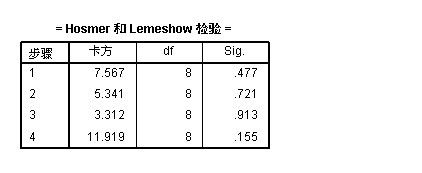
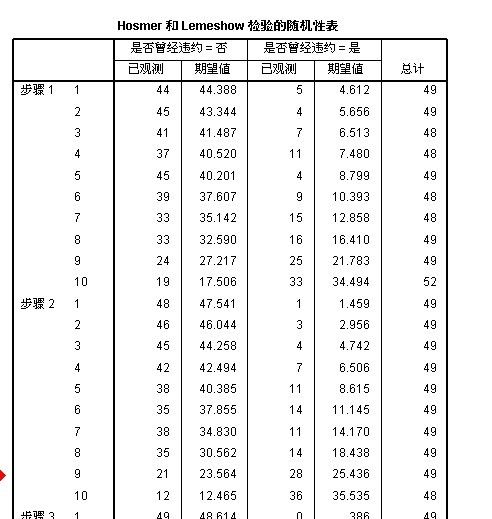
提示: 将Hosmer 和 Lemeshow 检验 和“随机性表” 结合一起来分析
1:从 Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919, 而临界值为:CHINV(0.05,8) = 15.507
卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
2:从Hosmer 和 Lemeshow 检验随即表中可以看出: ”观测值“和”期望值“几乎是接近的,不存在很大差异,说明模型拟合效果比较理想,印证了“Hosmer 和 Lemeshow 检验”中的结果
而“Hosmer 和 Lemeshow 检验”表中的“卡方”统计量,是通过“Hosmer 和 Lemeshow 检验随即表”中的数据得到的(即通过“观测值和”预测值“)得到的,计算公式如下所示:
x²(卡方统计量) = ∑(观测值频率- 预测值频率)^2 / 预测值的频率
举例说明一下计算过程:以计算 "步骤1的卡方统计量为例 "
1:将“Hosmer 和 Lemeshow 检验随即表”中“步骤1 ” 的数据,复制到 excel 中,得到如下所示结果:
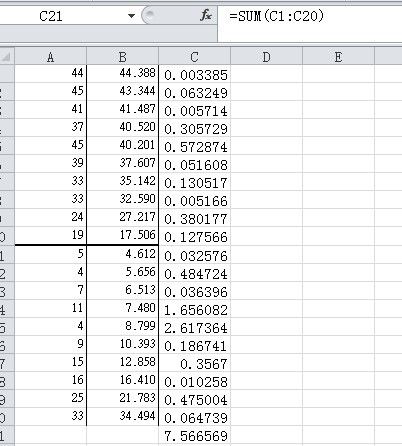
从“Hosmer 和 Lemeshow 检验”表中可以看出, 步骤1 的卡方统计量为:7.567, 在上图中,通过excel计算得到,结果为 7.566569 ~~7.567 (四舍五入),结果是一致的,答案得到验证!!

1:从“分类表”—“步骤1” 中可以看出: 选定的案例中,“是否曾今违约”总计:489个,其中 没有违约的 360个,并且对360个“没有违约”的客户进行了预测,有 340个预测成功,20个预测失败,预测成功率为:340 / 360 =94.4%
其中“违约”的有189个,也对189个“违约”的客户进行了预测,有95个预测失败, 34个预测成功,预测成功率:34 / 129 = 26.4%
总计预测成功率:(340 + 34)/ 489 = 76.5%
步骤1 的 总体预测成功率为:76.5%, 在步骤4终止后,总体预测成功率为:83.4,预测准确率逐渐提升 76.5%—79.8%—81.4%—83.4。 83.4的预测准确率,不能够算太高,只能够说还行。
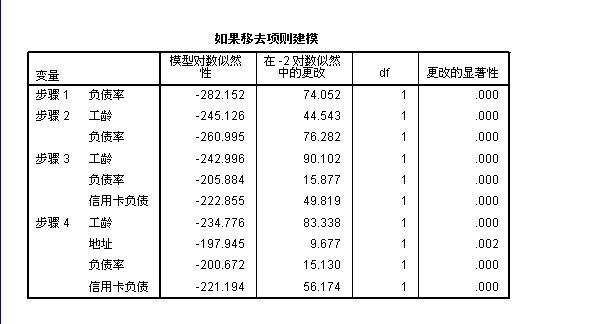
从“如果移去项则建模”表中可以看出:“在-2对数似然中的更改” 中的数值是不是很眼熟???,跟在“模型系数总和检验”表中“卡方统计量"量的值是一样的!!!
将“如果移去项则建模”和 “方程中的变量”两个表结合一起来看
1:在“方程中的变量”表中可以看出: 在步骤1中输入的变量为“负债率” ,在”如果移去项则建模“表中可以看出,当移去“负债率”这个变量时,引起了74.052的数值更改,此时模型中只剩下“常数项”-282.152为常数项的对数似然值
在步骤2中,当移去“工龄”这个自变量时,引起了44.543的数值变化(简称:似然比统计量),在步骤2中,移去“工龄”这个自变量后,还剩下“负债率”和“常量”,此时对数似然值 变成了:-245.126,此时我们可以通过公式算出“负债率”的似然比统计量:计算过程如下:
似然比统计量 = 2(-245.126+282.152)=74.052 答案得到验证!!!
2:在“如果移去项则建模”表中可以看出:不管移去那一个自变量,“更改的显著性”都非常小,几乎都小于0.05,所以这些自变量系数跟模型显著相关,不能够剔去!!
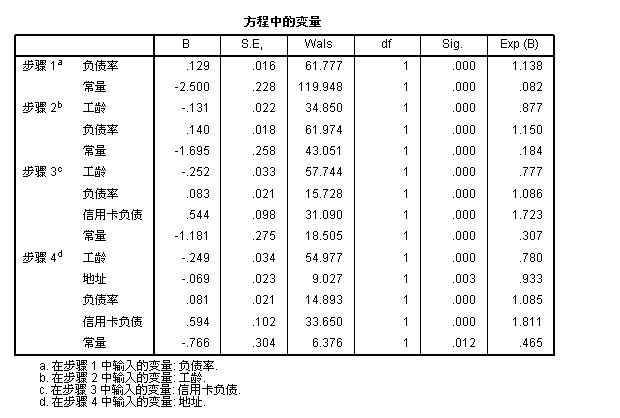
3:根据" 方程中的变量“这个表,我们可以得出 logistic 回归模型表达式:
= 1 / 1+ e^-(a+∑βI*Xi) 我们假设 Z = 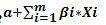 那么可以得到简洁表达式:
那么可以得到简洁表达式:
P(Y) = 1 / 1+e^ (-z)
将”方程中的变量“ —步骤4中的参数代入 模型表达式中,可以得到 logistic回归 模型 如下所示:
P(Y) = 1 / 1 + e ^ -(-0.766+0.594*信用卡负债率+0.081*负债率-0.069*地址-0.249*功龄)
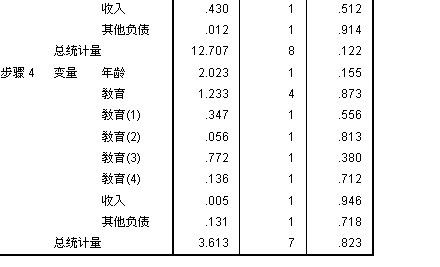
从”不在方程中的变量“表中可以看出: 年龄,教育,收入,其它负债,都没有纳入模型中,其中:sig 值都大于 0.05,所以说明这些自变量跟模型显著不相关。

在”观察到的组和预测概率图”中可以看出:
1:the Cut Value is 0.5, 此处以 0.5 为切割值,预测概率大于0.5,表示客户“违约”的概率比较大,小于0.5表示客户“违约”概率比较小。
2:从上图中可以看出:预测分布的数值基本分布在“左右两端”在大于0.5的切割值中,大部分都是“1” 表示大部分都是“违约”客户,( 大约230个违约客户) 预测概率比较准,而在小于0.5的切割值中,大部分都是“0” 大部分都是“未违约”的客户,(大约500多个客户,未违约) 预测也很准
在运行结束后,会自动生成多个自变量,如下所示:

1:从上图中可以看出,已经对客户“是否违约”做出了预测,上面用颜色标记的部分-PRE_1 表示预测概率,
上面的预测概率,可以通过 前面的 Logistic 回归模型计算出来,计算过程不演示了
2:COOK_1 和 SRE_1 的值可以跟 预测概率(PRE_1) 进行画图,来看 COOK_1 和 SRE_1 对预测概率的影响程度,因为COOK值跟模型拟合度有一定的关联,发生奇异值,会影响分析结果。如果有太多奇异值,应该单独进行深入研究!