Tensorflow学习笔记4——神经网络优化
Tensorflow学习笔记4
- 第四讲 神经网络优化
-
- 激活函数、神经网络的复杂度的简单介绍
- 神经网络优化的四大部分
-
- 1、损失函数loss
- 2、学习率learning_rate
- 3、滑动平均(影子值ema)
- 4、 正则化
第四讲 神经网络优化
这一讲的知识点很多,难度也一下子增大了,许多函数都没有讲解,需要一个一个去查,坚持就是胜利ヾ( ̄v ̄)X
激活函数、神经网络的复杂度的简单介绍
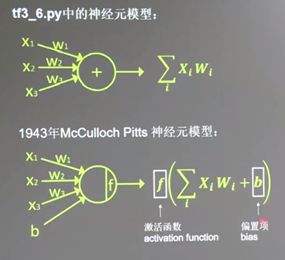
接下来将以第二种神经元模型为单位构建神经网络
激活函数(activation function):有效避免纯线性组合,使模型更具有区分度。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。
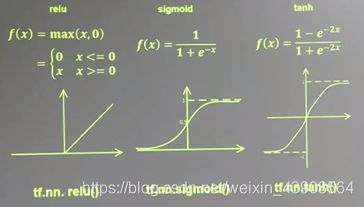
常见的几个激活函数如下图:
神经网络(包含输入层、隐藏层、输出层)的复杂度:多用NN层数和NN参数的个数表示
- 层数=隐藏层层数+1个输出层(有计算能力的层)
- 总参数=总W+总b
神经网络优化的四大部分
神经网络的优化主要包含四个部分:
损失函数loss、学习率learning_rate、滑动平均ema、正则化regularization
接下来会一一介绍,同时附上代码
1、损失函数loss
- 损失函数loss:预测值(前向传播的计算结果)y与已知答案y_的差距
NN优化目标就是loss值最小(即y与y_无限接近)主要表现形式有mse均方误差、自定义、ce交叉熵(Cross Entropy)
补充:
-
噪声影响
就像声音的波形会受到噪声的干扰,最终所得到的叠加的波形一般是输入的数据,所以我们要模拟噪声,对数据加上噪声的影响。噪声影响的方式有很多种,比如随机分布与高斯分布。 -
随机分布:简单来说,对生成的因变量数据加上一个纵向随机小范围的偏移量,主要保证如下的特点:
• 随机性
• 小范围的偏移
• 整体线性不会有变化
使用NP.RANDOM.RAND来生成随机噪声(通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。)
举例:X=NP.LINSPACE(0,1,100) Y1=2*X + NP.RANDOM.RAND(*X.SHAPE) + 1
什么场合适合什么损失函数呢?
MSE作为损失函数,默认认为预测多与预测少损失是一样的,然而如果预测商品销量,预测多了损失的是成本,预测少了损失的是利润,如果利润不等于成本,那么MSE产生的loss无法将利益最大化。
这里我们引入自定义损失函数:

所以自定义为分段函数更加合理。
此外还有交叉熵ce(Cross Entropy):表征两个概率分布之间的距离,交叉熵越大,表示两个概率分布越远,反之越近。
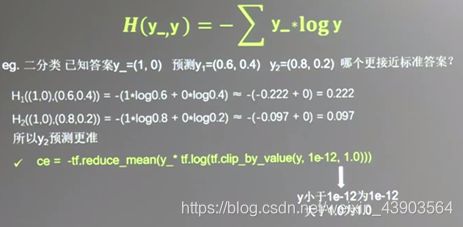
根据交叉熵的值可以预测哪个结果与标准答案更接近。

可以用这两行代码,替换上图中的那一句,最终输出就是当前计算出的预测值与标准答案的差距,也就是损失函数。
2、学习率learning_rate
学习率learning_rate:每次参数更新的幅度

举例:

目的是找到图中函数的w=-1的点(损失函数梯度最小)
此时学习率设置多少合适呢?以上述为例,当设置学习率为1时,w参数在5和-7之间跳跃,即震荡不收敛,学习率为0.001时,w缓慢减小,未到达-1。可见,学习率大了震荡不收敛,学习率小了收敛速度慢。所以我们采用指数衰减学习率:(根据BATCH_SIZE的轮数动态设置学习率)


这里首先要理解的是什么是BATCH_SIZE
Batch Size定义:一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。适当Batch Size使得梯度下降方向更加准确。
Batch Size从小到大的变化对神经网络的影响:
1、没有Batch Size,梯度准确,只适用于小样本数据库
2、Batch Size=1,梯度变来变去,非常不准确,网络很难收敛。
3、Batch Size增大,梯度变准确,
4、Batch Size增大,梯度已经非常准确,再增加Batch Size也没有用
首先定义一个计数器(global_step),记录运行了多少轮BATCH_SIZE个数据,该变量只用于计数,没有参与训练参数,所以标注为不可训练(trainable=False)。staircase为True时,指数上的计数器除以多少轮更新一次学习率的值取整数,则学习率呈阶梯型衰减,如果为False,学习率为平滑的曲线。
重要函数:
tf.train.exponential_decay(
learning_rate,初始学习率
global_step,当前迭代次数
decay_steps,衰减速度(在迭代到该次数时学习率衰减为earning_rate * decay_rate)
decay_rate,学习率衰减系数,通常介于0-1之间。
staircase=False,(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
name=None
)
代码:
#coding:utf-8
#设损失函数loss=(w+1)^2,w初值为10。反向传播就是求最优w,即求最小loss对应的w值
#使用指数衰减的学习率,在迭代初期得到较高的下下降速度,在较小的训练轮数下取得更有收敛度的训练结果
import tensorflow as tf
LEARNING_RATE_BASE = 0.1 #最初学习率
LEARNING_RATE_DECAY = 0.99 #学习衰减率
LEARNING_RATE_STEP = 1 #喂入多少轮BATCH_SIZE后更新一次学习率,一般设为:总样本数/BATCH_SIZE
#运行了几轮BATCH_SIZE的计数器,初值为0,设为不被训练
global_step = tf.Variable(0, trainable=False)
#定义指数下降学习率
learing_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,LEARNING_RATE_STEP,LEARNING_RATE_DECAY,staircase=True)
#定义待优化参数
w = tf.Variable(tf.constant(10,dtype=tf.float32))
#定义损失函数
loss = tf.square(w+1)
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss,global_step=global_step)
#声称会话
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
learing_rate_val = sess.run(learing_rate)
global_step_val = sess.run(global_step)
w_val = sess.run(w)
loss_val = sess.run(loss)
print "After %s steps:global_step is %f,w is %f,learning_rate is %f,loss is %f"%(i,global_step_val,w_val,learing_rate_val,loss_val)
运行结果:
修改参数w初始值(10修改为5)运行结果:
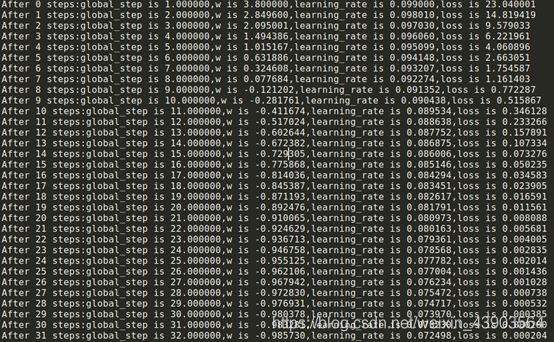
可见损失函数的初始值就不同,参数最终训练结果更接近-1.
修改最初学习率为1运行结果:
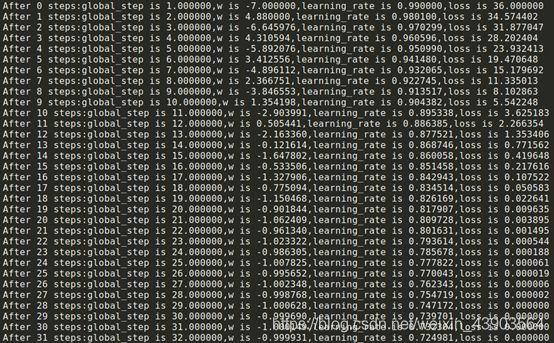

可见,虽然之前测试中学习率为1时参数是震荡且不收敛的,但由于学习率在动态衰减,由1逐渐减小,由于学习率仍然很大所以w改变幅度很大,很快w到达-1,损失函数也减小为0.
最初学习率不变,修改学习衰减率为0.1运行结果:

可见,学习衰减率越小,学习率衰减越快(正比),这也和前面的公式对应。由于学习率很快减到了0,从而反向传播时无法对w参数进行训练。导致w停在3.693549不动了。
最初学习率和学习衰减率不变,修改喂入多少轮BATCH_SIZE后更新一次学习率为10运行结果:

可以看出损失函数几乎减小到0,w非常接近-1,这也说明增大BATCH_SIZE可以使学习率下降得慢,可以使参数训练更准确。
3、滑动平均(影子值ema)
滑动平均(影子值ema):记录了每个参数一段时间内过往值的平均,它不仅表现了当前值,还表现了过去一段时间的平均值,所以它增加了模型的泛化性。针对所有参数进行优化:所有w和b。(像是给参数加了个影子,参数变化,影子缓慢追随)

注意这里的衰减率不是学习衰减率。MOVING_AVERAGE_DECAY为滑动平均衰减率。
什么是超参数:
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。MOVING_AVERAGE_DECAY是一个超参数。

重要函数tf.trainable_variables():
对于一些我们不需要训练的变量,比较典型的例如学习率或者计步器这些变量,我们都需要将trainable设置为False,这时tf.trainable_variables() 就不会打印这些变量,而是只把需要训练的参数转化为列表。

我们常把计算滑动平均和训练过程绑定在一起运行,使它们合成一个训练结点。
代码:
#coding:utf-8
import tensorflow as tf
#定义变量及滑动平均类
#定义一个待优化参数,初始值为0
w1 = tf.Variable(0,dtype = tf.float32)
#定义num_updates(NN的迭代轮数),初始值为0,不可被优化(训练)
global_step = tf.Variable(0,trainable=False)
#实例化滑动平均类,给衰减率为0.99,global_step为当前轮数
MOVING_AVERAGE_DECAY = 0.99
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
#ema.apply后括号里为更新列表,每次运行sess.run(ema_op)时,对列表中的元素求滑动平均
#ema_op = ema.apply([w1])
ema_op = ema.apply(tf.trainable_variables())
#查看不同迭代中w1参数的变化
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#用ema.average(w1)获取w1的滑动平均值
print sess.run([w1,ema.average(w1)])
#将w1赋值为1
sess.run(tf.assign(w1,1))
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
#更新step和w1的值,模拟100轮后
sess.run(tf.assign(global_step,100))
sess.run(tf.assign(w1,10))
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
#每次sess.run会更新一次w1的滑动平均值
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
sess.run(ema_op)
print sess.run([w1,ema.average(w1)])
运行结果如下:
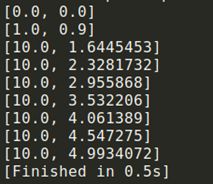
可以看出滑动平均向着w1逼近。
4、 正则化
正则化:有效缓解过拟合,即在损失函数中引入模型复杂度指标,利用给w加权值,弱化了训练数据的噪声(一般不正则化b)
过拟合: 有时候我们发现,模型在训练数据集上的正确率非常高,但这个模型却很难对从未见过的数据做出正确相应,就说这个模型存在过拟合现象。

现在的loss=以前的loss(y,y_)+参数权重*loss(w)(有以下两种计算方法l1,l2)

losses是个集合。
正则化的作用:

新模块matplotlib:Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。 它也可以和图形工具包一起使用,如 PyQt 和 wxPython。
几个主要函数:
- plt.scatter() #绘制散点图(传如一对x和y坐标,在指定位置绘制一个点,传入列表时,可同时绘制多个点)
- plt.contour()#使用contour绘制等高线。如:C=plt.contour(X,Y,height(X,Y),10,colors=‘black’)
- plt.show()#显示图片
- np.mgrid[start: end:step]
start:开始坐标
stop:结束坐标(不包括)
step:步长
举例子res = np.mgrid[-3:3:.1,-3:3:.1] 生成从-3到3的二维坐标,返回数组的res[0]是一个轴,res[1]是一个轴

- np.ravel()和np.flatten():两者的功能是一致的,将多维数组降为一维,但是两者的区别是返回拷贝还是返回视图,np.flatten()返回一份拷贝,对拷贝所做修改不会影响原始矩阵,而np.ravel()返回的是视图,修改时会影响原始矩阵。
- np.c_()和np.r_():np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。 - numpy的.shape函数可以快速读取矩阵形状(几行几列)
- numpy的.reshape函数:就是将一个矩阵转化为另一种形状

- squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
例如:
>>>a = e.reshape(1,1,10)
>>>a
array([[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]])
>>>np.squeeze(a)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
体现在画图时:
/>>> plt.plot(a)
Traceback (most recent call last):
File “”, line 1, in
File “C:\Python27\lib\site-packages\matplotlib\pyplot.py”, line 3240, in plot
ret = ax.plot(*args, **kwargs)
File “C:\Python27\lib\site-packages\matplotlib_init_.py”, line 1710, in inner
return func(ax, *args, **kwargs)
File “C:\Python27\lib\site-packages\matplotlib\axes_axes.py”, line 1437, in plot
for line in self._get_lines(*args, **kwargs):
File “C:\Python27\lib\site-packages\matplotlib\axes_base.py”, line 404, in _grab_next_args
for seg in self._plot_args(this, kwargs):
File “C:\Python27\lib\site-packages\matplotlib\axes_base.py”, line 384, in _plot_args
x, y = self._xy_from_xy(x, y)
File “C:\Python27\lib\site-packages\matplotlib\axes_base.py”, line 246, in _xy_from_xy
“shapes {} and {}”.format(x.shape, y.shape))
ValueError: x and y can be no greater than 2-D, but have shapes (1L,) and (1L, 1L, 10L)
(这里会报错)
>>> plt.plot(np.squeeze(a))
[](不报错)
>>> plt.show() - 矩阵的选取方式:X[:,0]就是取所有行的第0个数据(相当于选取矩阵写出来之后的第一列),X[:,1]就是取所有行的第1个数据(相当于选取矩阵写出来之后的第二列)。
代码:
#coding:utf-8
#导入模块,生成模拟数据集
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_SIZE = 30
seed = 2
#基于seed产生随机数
rdm = np.random.RandomState(seed)
#随机数返回300行2列的矩阵表示300组坐标点(x0,x1)作为输入数据集
X = rdm.randn(300,2)
#从X这个300行2列的矩阵中取出一行,判断坐标平方和小于2给Y赋值1,否则赋值0
#Y_作为输入数据集的标签(正确答案)
Y_ = [int(x0*x0 + x1*x1 < 2) for (x0,x1) in X]
#遍历Y_中的每个元素,1为红色,0为蓝色
Y_c = [['red' if y else 'blue'] for y in Y_]
#对数据集X和标签Y进行shape整理,-1表示n行,把X整理为n行2列,Y整理为n行1列
X = np.vstack(X).reshape(-1,2)
Y_ = np.vstack(Y_).reshape(-1,1)
print X
print Y_
print Y_c
#用plt.scatter画出数据集X各行中第0列元素和第1列元素的点即各行的(x0,x1),用各行的Y_c对应的值表示颜色
plt.scatter(X[:,0],X[:,1],c = np.squeeze(Y_c))
plt.show()
#定义神经网络的输入、参数和输出,定义前向传播过程
#计算w权重
def get_weight(shape, regularizer):
w = tf.Variable(tf.random_normal(shape),dtype=tf.float32)
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
#计算偏置b为0.01
def get_bias(shape):
b = tf.Variable(tf.constant(0.01,shape=shape))
return b
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.placeholder(tf.float32,shape=(None,1))
#注意shpq都是以列表形式给出
w1 = get_weight([2,11],0.01)
b1 = get_bias([11])
y1 = tf.nn.relu(tf.matmul(x,w1)+b1)
w2 = get_weight([11,1],0.01)
b2 = get_bias([1])
y = tf.matmul(y1,w2)+b2 #输出层不过激活函数
#定义损失函数
loss_mse = tf.reduce_mean(tf.square(y-y_))
loss_total = loss_mse + tf.add_n(tf.get_collection('losses'))
#定义反向传播方法:不含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_mse)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%2000 == 0:
loss_mse_v = sess.run(loss_mse,feed_dict={x:X,y_:Y_})
print("After %d steps, loss is:%f"%(i,loss_mse_v))
#xx在-3,3之间以步长为0.01,yy在-3,3之间以步长0.01,生成二维网格坐标点
xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
#将xx,yy拉直,合并成一个2列矩阵,得到一个网格坐标点的集合
grid = np.c_[xx.ravel(),yy.ravel()]
#将网格坐标点喂入网络,prods为输出
probs = sess.run(y, feed_dict={x:grid})
#probs的shape调整为xx的样子
probs = probs.reshape(xx.shape)
print "w1:\n",sess.run(w1)
print "b1:\n",sess.run(b1)
print "w2:\n",sess.run(w2)
print "b2:\n",sess.run(b2)
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5])
plt.show()
#定义反向传播方法:包含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_total)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%2000 == 0:
loss_v = sess.run(loss_mse,feed_dict={x:X,y_:Y_})
print("After %d steps, loss is:%f"%(i,loss_v))
xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
grid = np.c_[xx.ravel(),yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape)
print "w1:\n",sess.run(w1)
print "b1:\n",sess.run(b1)
print "w2:\n",sess.run(w2)
print "b2:\n",sess.run(b2)
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5])
plt.show()
运行结果:
第一次生成的图:
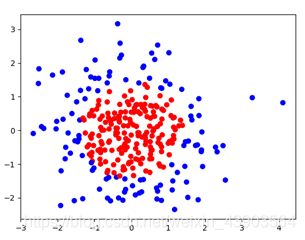
经过不含正则化训练的图:

经过正则化训练的图:
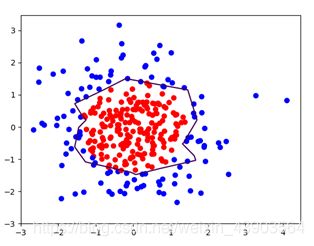
可以看出来差距还是挺大的,利用正则化使训练更加高效。
以上学习内容来自中国MOOC网课程:https://www.icourse163.org/course/PKU-1002536002