2020讯飞AI开发者大赛-温度预测赛道baseline改进
2020讯飞AI开发者大赛-温度预测赛道baseline改进分享
- 写在前面
- 数据清洗
-
- 缺失值处理
- 异常值处理
- 特征工程
- 模型训练
- 写在最后
写在前面
这是我参加的第二次数据竞赛,上次是上个月的“传染病趋势预测”,西交是主办方的那个,没进决赛(差的有点多)。这是我第一次写博客分享baseline(代码主要思路还是借鉴鱼佬的baseline),目前排名50多名,有希望进复赛。希望这篇po文对读者有所帮助。本文也可以当作入门数据科学竞赛的小白的实战教程。话不多说,我们开始吧!
鱼佬baseline地址,A榜得分0.14左右:link.
本次比赛网址链接:link
数据清洗
缺失值处理
训练数据的属性有缺失值的包括’outdoorTemp’, ‘outdoorHum’, ‘outdoorAtmo’, ‘indoorHum’, ‘indoorAtmo’, ‘temperature’;测试数据有缺失值的包括’outdoorTemp’, ‘outdoorHum’, ‘outdoorAtmo’, ‘indoorHum’, ‘indoorAtmo’。属性可分为室内和室外属性,这里的数据有个特点,对于某个样本点,室内的数据要么没有缺失,要么一起缺失,室外的也同样。观察发现,缺失情况分为三类:
第一类,室内数据缺失,室外数据没有缺失(处理方法:相邻项补全)
第二类,室内数据没有缺失,室外数据缺失(处理方法:相邻项补全)
第三类,同时缺失(处理方法:直接删除)
除此之外,还存在连续的样本值缺失,这种情况,我才用的是相邻项补全。至此,缺失值处理完毕,记得重置索引,否则后面处理异常值的时候容易报错。
异常值处理
主要的异常值存在于气压值,经过具体的观察之后,发现大多数气压异常值出现的毫无原因,故采用同小时内相邻填充。这里有一点,在hour变化的样本里,特征值变化会很大,要注意。
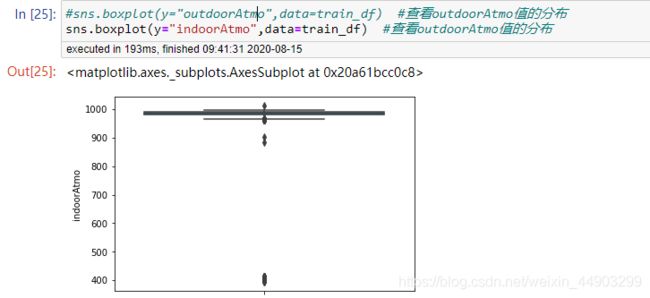
对气压值,湿度值都是这样处理,下面展示一些
#室内压强
for i in range(1,train_df.shape[0]):
if abs(train_df['indoorAtmo'].loc[i]-train_df['indoorAtmo'].loc[i-1])>5:
if train_df['hour'].loc[i]==train_df['hour'].loc[i-1]: #小时相同
if train_df['min'].loc[i]-train_df['min'].loc[i-1]<=7: #分钟相差7分钟之内
if train_df['indoorAtmo'].loc[i]-train_df['indoorAtmo'].loc[i-1]>5:
train_df['indoorAtmo'].loc[i]=train_df['indoorAtmo'].loc[i-1]+0.1
if train_df['indoorAtmo'].loc[i]-train_df['indoorAtmo'].loc[i-1]<-5:
train_df['indoorAtmo'].loc[i]=train_df['indoorAtmo'].loc[i-1]-0.1
此外,对于’temperature’,'outdoorTemp’要不要进行异常值处理 根据个人有需求吧。
特征工程
提供几个方参考:
1:month,day,hour,min做处理,从这几个特征中挖掘出隐藏的信息,包括但不限于:节假日、节假日第 n 天、节假日前 n 天、节假日后 n 天;一天的某个时间段:上午、中午、下午、傍晚、晚上、深夜、凌晨等;月初、月末、周内、周末等;根据需求构建特征。pandas中提供了方法
# 年、季度、季节、月、星期、日、时
data_df['date'] = pd.to_datetime(data_df['date'], format="%m/%d/%y")
data_df['quarter']=data_df['date'].dt.quarter
data_df['month'] = data_df['date'].dt.month
data_df['day'] = data_df['date'].dt.day
data_df['dayofweek'] = data_df['date'].dt.dayofweek
data_df['weekofyear'] = data_df['date'].dt.week # 一年中的第几周
# Series.dt 下有很多属性,可以去看一下是否有需要的。
data_df['is_year_start'] = data_df['date'].dt.is_year_start
data_df['is_year_end'] = data_df['date'].dt.is_year_end
data_df['is_quarter_start'] = data_df['date'].dt.is_quarter_start
data_df['is_quarter_end'] = data_df['date'].dt.is_quarter_end
data_df['is_month_start'] = data_df['date'].dt.is_month_start
data_df['is_month_end'] = data_df['date'].dt.is_month_end
2:离散型变量处理:顺序编码,one_hot编码
3:交叉特征,特征交叉一般从重要特征线下手,可以考虑比值、差分值
# 基本交叉特征
for f1 in tqdm(['outdoorTemp','outdoorHum','outdoorAtmo','indoorHum','indoorAtmo']+group_feats):
for f2 in ['outdoorTemp','outdoorHum','outdoorAtmo','indoorHum','indoorAtmo']+group_feats:
if f1 != f2:
colname = '{}_{}_ratio'.format(f1, f2)
data[colname] = data[f1].values / data[f2].values
data = data.fillna(method='bfill')
4.聚合特征(注意,这些统计特征mad,skew,std等添加与否要自己实验才知道)
for f in tqdm(['outdoorTemp', 'outdoorHum', 'outdoorAtmo', 'indoorHum', 'indoorAtmo']):
#基于month,day,hour做聚合特征
data_df['MDH_{}_medi'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('median')
data_df['MDH_{}_mean'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('mean')
data_df['MDH_{}_max'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('max')
data_df['MDH_{}_min'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('min')
data_df['MDH_{}_mad'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('mad')
data_df['MDH_{}_skew'.format(f)] = data_df.groupby(['month', 'day', 'hour'])[f].transform('skew')
还可以值根据hour,或者day,hour进行聚合(亲测有效,提升虽然不大)
for f in tqdm(['outdoorTemp', 'outdoorHum', 'outdoorAtmo', 'indoorHum', 'indoorAtmo']):
#直接基于day,hour做聚合特征
data_df['H_{}_medi'.format(f)] = data_df.groupby(['hour'])[f].transform('median')
data_df['H_{}_mean'.format(f)] = data_df.groupby(['hour'])[f].transform('mean')
data_df['H_{}_max'.format(f)] = data_df.groupby(['hour'])[f].transform('max')
data_df['H_{}_min'.format(f)] = data_df.groupby(['hour'])[f].transform('min')
data_df['H_{}_mad'.format(f)] = data_df.groupby(['hour'])[f].transform('mad')
data_df['H_{}_skew'.format(f)] = data_df.groupby(['hour'])[f].transform('skew')
5.开窗统计:统计前n天的outdoorTemp,outdoorHum等特诊的mean,medain’等统计特征,n为窗口大小,自己尝试。可选3,4,5等等,pandas中给出了函数
data['avg_'+ str(n) +'_days_' + col] = temp.mean(axis=1)
data['median_'+ str(n) +'_days_' + col] = temp.median(axis=1)
data['max_'+ str(n) +'_days_' + col] = temp.max(axis=1)
data['min_'+ str(n) +'_days_' + col] = temp.min(axis=1)
data['std_'+ str(n) +'_days_' + col] = temp.std(axis=1)
data['mad_'+ str(n) +'_days_' + col] = temp.mad(axis=1)
data['skew_'+ str(n) +'_days_' + col] = temp.skew(axis=1)
data['kurt_'+ str(n) +'_days_' + col] = temp.kurt(axis=1)
data['q1_'+ str(n) +'_days_' + col] = temp.quantile(q=0.25, axis=1)
data['q3_'+ str(n) +'_days_' + col] = temp.quantile(q=0.75, axis=1)
6.特征选择,这方面我目前只采用了方差filter,后面可能会尝试其他的特征选择方法
7.特征缩放:我主要使用boosting中的XBG模型和LGB模型,可以不做特征缩放
8.离散化:我用的分桶,也就是baseline里的,添加了:对前面得到的窗口统计值的分桶。
模型训练
采用单LGB模型就可达到0.10几的分数,比XGB来的快,这里采用10%的数据作为验证集8-2也可
nums = int(train_x.shape[0] * 0.90)
trn_x, trn_y, val_x, val_y = train_x[:nums], train_y[:nums], train_x[nums:], train_y[nums:]
train_matrix = lgb.Dataset(trn_x, label=trn_y)
valid_matrix = lgb.Dataset(val_x, label=val_y)
data_matrix = lgb.Dataset(train_x, label=train_y)
params = {
'boosting_type': 'gbdt',
'objective': 'mse',
'min_child_weight': 5,
'num_leaves': 64 ,
'max_depth': 10,
'objective': 'regression',
'feature_fraction': 0.8,
'bagging_fraction': 0.7,
'bagging_freq': 1,
'learning_rate': 0.005,
'seed': 520,
'min_data_in_leaf': 120,
#'lambda_l1':0.01,
#'lambda_l2':0.01
}
model = lgb.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix], verbose_eval=500,early_stopping_rounds=1000)
model2 = lgb.train(params, data_matrix, model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model2.best_iteration).reshape(-1,1)
参数仅供参考,调参是不可避免的。
写在最后
比赛前期我把大量时间花在了模型调参上,事实证明这么做实在是太臭了,浪费时间且提高不大。最近把精力转向了数据分析、特征挖掘,越来越领悟到那句话的含义:特征工程决定了精度上限,而用什么模型只是逼近这个上限。这是我第一次写完整的博客,如果有不当的地方还请评论指出。