SparkCore入门编程
一、Spark的概述
1.1 Hadoop的回顾
- 版本号的发展
hadoop1.x : hdfs 和 mapreduce
hadoop2.x : hdfs、mapreduce、yarn、common
hadoop3.x : hdfs、mapreduce、yarn、common
- hadoop的重要模块组成
hdfs : 分布式文件存储系统 需要搭建和部署
mapreduce: 离线分析和计算框架 不需要搭建, 是程序要要开发的逻辑代码
yarn : 资源调度管理系统 需要搭建和部署
- HDFS的优点和缺点
优点:
-- datanode的可靠性、可以部署在廉价的商用硬件上(允许部分机器宕机)
-- 适合存储大数据集
-- 副本自动冗余策略(不满足3个的时候,会自动启动冗余,达到3个)
-- 集群易于横向扩展(增加节点)
缺点:
-- 不适合存储小文件
-- 只支持追加操作
-- 在同一时间内只允许一个writer
- MR的优点和缺点
优点:
-- 适合批处理(离线处理)计算大数据集
-- 易于编程
-- 容错性较好(task失败,可以进行重试)
-- 扩展性良好
缺点:
-- 不适合低延迟的工作
-- 不适合处理小文件
-- 调优困难
1.2 Spark的简介
1.2.1 Spark是什么
-1. spark是一个快速的、通用的、可扩展的大数据分析计算框架
-2. spark是用scala语言编写的
-3. spark在09年诞生、13年6月加入apache、14年2月成为顶级项目
-4. Spark快的原因:
(1)基于内存计算
(2)使用DAG执行引擎(调度)
(3)支持数据向上追踪(血缘追踪,临时存储)
-5. spark可以进行 批处理、迭代运算、交互式查询、流处理、机器学习、图处理等
-6. spark程序可以使用多种语言编写,比如java、scala、python、r语言等
-7. spark能处理的数据源,也比较多,比如可以处理mysql、hdfs、hive等各种地方的数据
-8. spark的安装部署方式有多种
本地模式: local
集群模式: standalone、yarn、mesos、k8s
1.2.2 Spark的模块组件
- Spark Core
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
- Spark SQL
是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
- Spark MLlib
提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- Spark GraphX
GraphX在Spark基础上提供了一站式的数据解决方案,可以高效地完成图计算的完整流水作业。GraphX是用于图计算和并行图计算的新的(alpha)Spark API。通过引入弹性分布式属性图(Resilient Distributed Property Graph),一种顶点和边都带有属性的有向多重图,扩展了Spark RDD。
1.3 Spark与Hadoop的比较
1.3.1 框架比较
| hadoop | spark | |
|---|---|---|
| 起源 | 2005 | 2009 |
| 起源地 | MapReduce (Google) Hadoop (Yahoo) | University of California, Berkeley |
| 数据处理引擎 | Batch | Batch |
| 处理 | Slower than Spark and Flink | 100x Faster than Hadoop |
| 编程语言 | Java, C, C++, Ruby, Groovy, Perl, Python | Java, Scala, python and R |
| 编程模型 | MapReduce | Resilient distributed Datasets (RDD) |
| Data Transfer | Batch | Batch |
| 内存管理 | Disk Based | JVM Managed |
| 延迟 | HIgh | Medium |
| 吞吐量 | Medium | High |
| 优化机制 | Manual | Manual |
| API | Low-level | High-level |
| 流处理支持 | NA | Spark Streaming |
| SQL支持 | Hive, Impala | SparkSQL |
| Graph 支持 | NA | GraphX |
| 机器学习支持 | NA | SparkML |
1.3.2 处理流程比较
1)MR中的迭代:

mr的整个应用程序,通常会有多个job串联, 在整个应用程序处理过程中,一个job所需要的数据使从磁盘上读取的,job执行完,会将处理结果存储到磁盘上,因此整个作业的迭代,涉及到大量的磁盘IO,所以慢
2)Spark中的迭代:
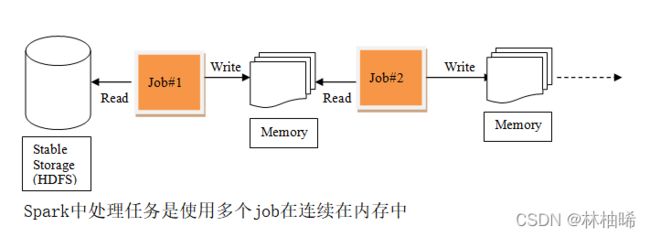
spark整个应用程序,也会有多个job串联,在处理过程中,第一个job从磁盘上读取数据,处理结果通常情况下存储到内存里,下一个job从内存中读取数据,进行处理,依次执行下去。所以说,整个作业的迭代,通常都是基于内存的,因此处理速度更快。
1.4 Spark的入门编程
说明:
创建maven项目,引入下面的jar包依赖
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>spark_sz2102artifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.8scala.version>
<spark.version>2.2.3spark.version>
<hadoop.version>2.7.6hadoop.version>
<scala.compat.version>2.11scala.compat.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter><artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
1.4.1 wordcount的编写方式1
1)编程思路
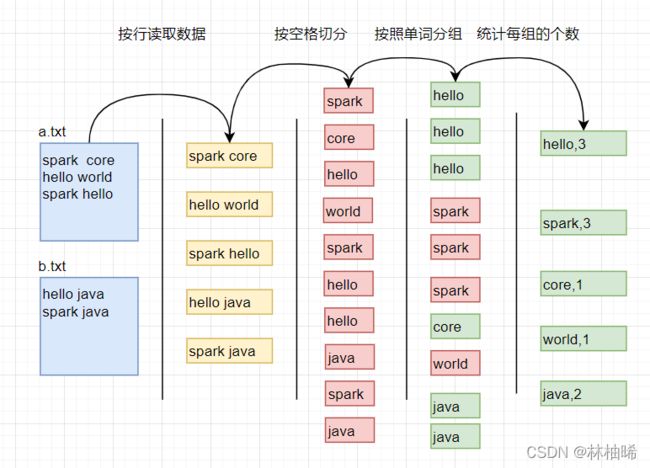
1:按行读取数据,2:按照空格切分成单词 3:按照单词分组 4:统计每组的单词个数
2)代码实现
package com.qf.sparkcore.day01
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark的入门案例: wordcount
* 思路:
* 1:按行读取数据,2:按照空格切分成单词 3:按照单词分组 4:统计每组的单词个数
*/
object WordCount1 {
def main(args: Array[String]): Unit = {
//1: 构建配置对象, 获取spark上下文对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
//2: 读取数据 RDD[String] : 指代的就是多个String的弹性分布式数据集 每个String都是一行记录。
val lines: RDD[String] = sc.textFile("D:/data/")
//3: 按照空格切分,并展平 [spark,core,hello.......]
val words: RDD[String] = lines.flatMap((line) => line.split(" "))
//4: 按照单词分组 每个元素都是一个具有两个元素的元组 第一个元素是单词 第二个元素是这个单词的集合,
// 比如 (spark,List(spark,spark,spark)) (hello,List(hello,hello,hello))......
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
//5:统计每一组的个数
val wordAndCount: RDD[(String, Int)] = wordGroup.mapValues(_.size)
//6: 将分布在各个计算节点的RDD搜集到客户端,并打印
val result: Array[(String, Int)] = wordAndCount.collect()
result.foreach(println)
//释放资源
sc.stop()
}
}
1.4.2 wordcount的编写方式2
1)编程思路

1:按行读取数据,2:按照空格切分成单词 3:构建元素 4:按照单词分组 5:统计每一组中的1的和
2)代码实现
package com.qf.sparkcore.day01
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark的入门案例: wordcount
* 思路2:
* 1:按行读取数据,2:按照空格切分成单词 3:构建元素 4:按照单词分组 5:统计每一组中的1的和
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1: 构建配置对象, 获取spark上下文对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
//2: 读取数据 RDD[String] : 指代的就是多个String的弹性分布式数据集 每个String都是一行记录。
val lines: RDD[String] = sc.textFile("D:/data/")
//3: 按照空格切分,并展平 [spark,core,hello.......]
val words: RDD[String] = lines.flatMap((line) => line.split(" "))
//4: 将每个单词和1 构建一个kv形式的元组 (spark,1) (core,1) (hello,1) (spark,1)........
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
/* //5: 按照元组的第一个元素即单词分组: (spark,List((spark,1),(spark,1),(spark,1)) (hello,List((hello,1),(hello,1),(hello,1)))....
val wordAndList: RDD[(String, Iterable[(String, Int)])] = wordAndOne.groupBy(_._1)
//6: 统计每一组中的1的累加值
val wordAndCount: RDD[(String, Int)] = wordAndList.map(group => {
val list: Iterable[(String, Int)] = group._2
var sum = 0;
for (elem <- list) {
sum += elem._2
}
(group._1, sum)
})*/
/**
* 5 : 使用reduceByKey直接计算
* 前提:元素必须是KV形式的数据
* 作用: 通过k进行分组,并对value进行聚合 。 也就是将同一个k的分为一组,然后将同一组的所有value进行reduce
* 参数:func:(Int,Int) =>Int 是一个函数:
* 函数的第一个参数接受这一组所有value的第一个value,并进行累加
* 函数的第二个参数接受这一组所有value除了第一个value的其他value 依次累加到第一个value上
* (spark,(1,1,1)) (hello,(1,1,1))....
* (spark,3) (hello,3).....
*/
val wordAndCount: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
//6: 搜集,打印
val result: Array[(String, Int)] = wordAndCount.collect()
result.foreach(println)
//释放资源
sc.stop()
}
}
1.4.3 日志文件的引入
我们的目的,程序正确时,控制台只打印结果,错误时,打印错误级别的信息
在项目的resources目录下,创建文件log4j.properties,存入下面的内容
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
二、Spark的安装部署
注意,注意,注意: spark在部署时, 不建议配置环境变量
2.1 安装部署的模式介绍
Spark的安装模式指的是运行spark程序时所需要的资源调度管理系统。
资源调度管理系统有两类,一种是本地模式,一种是集群模式。
1. 本地模式: local模式
指的是利用运行程序所在的那一台机器的系统平台,
比如在windows运行,利用的就是本地的windows系统
在linux运行,用的就是本地的windows系统
在mac运行,用的就是本地的mac系统
作用,用于开发人员测试、调试代码等,
2. 集群模式:
- Standalone:
spark本身自带的一个资源调度系统,也分为单机和集群模式
- yarn:
spark利用hadoop的yarn资源调度系统,进行spark程序的资源调度
在国内用的是最多的
- mesos:
这是一款在国外比较流行的资源调度系统
- k8s:
这个也是一种资源调度系统,出名的公司一般会用这个。
2.2 Spark的Local模式
1)上传、解压、更名
[root@qianfeng01 ~]# tar -zxvf spark-2.2.3-bin-hadoop2.7.tgz -C /usr/local/
[root@qianfeng01 ~]# cd /usr/local/
[root@qianfeng01 local]# mv spark-2.2.3-bin-hadoop2.7/ spark-local
2)启动,进入scala交互界面
[root@qianfeng01 local]# cd spark-local
[root@qianfeng01 spark-local]# ./bin/spark-shell
小贴士: 只要运行spark-shell脚本,进入scala交互界面,即成功
3)程序测试:
1. 在spark-local下的data目录,创建一个words.txt文件
hello spark
hello world
hello java
hello spark
2. 在spark-local目录下启动spark-shell指令
[root@qianfeng01 spark-local]# ./bin/spark-shell
3. 进入scala交互界面后,有两个变量可以直接使用,一个是sc(spark上下文),一个是spark(SparkSession)
scala> sc.textFile("data/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
(java,1)
(hello,4)
(world,1)
(spark,2)
2.3 Standalone集群模式
2.3.1 简要说明
standalone指的是spark程序自带的一个资源调度管理系统。支持集群模式,也支持单机模式。不管是什么模式,他都是一个主从架构,即一个活跃的master和N个worker.
master守护进程是一个管理节点,worker守护进程,有多个,是工作节点
部署安排
qianfeng01: master worker
qianfeng02: worker
qianfeng03: worker
准备条件:
三台机器的免密登录认证、防火墙关闭、时间同步、jdk1.8+,hadoop2.7.6
2.3.2 安装部署
1)上传、解压、更名
[root@qianfeng01 ~]# tar -zxvf spark-2.2.3-bin-hadoop2.7.tgz -C /usr/local/
[root@qianfeng01 ~]# cd /usr/local/
[root@qianfeng01 local]# mv spark-2.2.3-bin-hadoop2.7/ spark-standalone
PS: 如果想要使用多种模式的话,不建议配置环境变量,
2)配置spark的环境脚本
[root@qianfeng01 ~]# cd /usr/local/spark-standalone/conf/
[root@qianfeng01 conf]# cp spark-env.sh.template spark-env.sh
[root@qianfeng01 conf]# vim spark-env.sh
.......在文件末尾添加如下内容..........
export JAVA_HOME=/usr/local/jdk
export SPARK_MASTER_HOST=qianfeng01
export SPARK_MASTER_PORT=7077
解析:
环境变量SPARK_MASTER_HOST或SPARK_MASTER_IP,这两个任选其一,如果使host那就配置主机名,如果使ip就配置相关IP
7077 是master的端口号,用于内部组件之间的通信
3)配置slaves文件,即工作节点的主机名
[root@qianfeng01 conf]# cp slaves.template slaves
[root@qianfeng01 conf]# vim slaves
qianfeng01
qianfeng02
qianfeng03
- 分发到其他节点
[root@qianfeng01 ~]# scp -r /usr/local/spark-standalone/ qianfeng02:/usr/local/
[root@qianfeng01 ~]# scp -r /usr/local/spark-standalone/ qianfeng03:/usr/local/
5) 启动测试
[root@qianfeng01 spark-standalone]# ./sbin/start-all.sh
注意:
1. 查看进程是否已经启动
jps
2. 如果没有成功,需要查看日志,在spark自己的logs目录下
6)查看webUI
在浏览器上输入:
http://qianfeng01:8080
7)端口号的总结:
7077: worker和master通信的端口号
8080: master的webui端口
4040: spark-shell交互平台的一个历史作业的webui
8088: yarn的webui端口
50070: namenode的webui端口
8020: datanode和namenode的端口
16010: hmaster的webui端口
2.3.3 spark-shell脚本的应用
该脚本为spark提供了一个交互式平台,可以在此进行spark编程,以及调节spark程序。
运行模式有两种:一种是本地模式,一种是集群模式
1)本地模式的运行:
直接在命令行上输入
[root@qianfeng01 spark-standalone]# ./bin/spark-shell

2)集群模式的运行
[root@qianfeng01 ~]# /usr/local/spark-standalone/bin/spark-shell \
--master spark://qianfeng01:7077 \
--executor-memory 512m \
--total-executor-cores 1
注意:集群模式,必须指定master,其他属性可选
3)退出交互界面
正规方式:
:quit
:q
尽量不要用ctrl + c,有可能会造成4040依然被占用,也就使没有完全退出,
如果不小心ctrl+c,没有完全退出,使用命令查看监听端口 netstat - apn | grep 4040 在使用kill -9 端口号 杀死即可
2.3.4 配置Job History Server
1)说明
因为在spark程序运行期间,driver会提供webui界面,来监控并显示运行状态。但是如果程序运行完,Driver会停止该webui界面的通信,就看不到之前的运行信息了。
如果想要查看原来的运行信息,可以配置作业历史服务器,将作业运行状态信息保存到HDFS上
2)配置如下
1. 启动HDFS、在HDFS上创建一个目录,用于存储spark作业的历史记录
[root@qianfeng01 ~]# start-dfs.sh
[root@qianfeng01 ~]# hdfs dfs -mkdir /sparkJobHistory
2. 修改spark的spark-default.conf文件
[root@qianfeng01 ~]# cd /usr/local/spark-standalone/conf
[root@qianfeng01 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@qianfeng01 conf]# vim spark-defaults.conf
......
#开启历史服务
spark.eventLog.enabled true
#存储路径
spark.eventLog.dir hdfs://qianfeng01:8020/sparkJobHistory
#是否压缩
spark.eventLog.compress true
3. 修改spark-env.sh文件,添加如下配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://qianfeng01:8020/sparkJobHistory"
4. 分发两个配置文件到其他节点
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng02:$PWD
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng03:$PWD
5. 启动历史服务器
先启动spark,
/usr/local/spark-standalone/sbin/start-all.sh
然后启动历史服务器
/usr/local/spark-standalone/sbin/start-history-server.sh
6. 查看进程
[root@qianfeng01 conf]# jps
5623 Master
5847 Jps
5048 DataNode
4905 NameNode
5773 HistoryServer <--------
5710 Worker
7. 使用webui查看
http://qianfeng01:4000
2.4 Spark的高可用
就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠
2.4.1 Spark集群规划:
Master: qianfeng01,qianfeng02
Worker: qianfeng01,qianfen02,qianfeng03
2.4.2 配置方式如下:
1)上传、解压、更名
[root@qianfeng01 ~]# tar -zxvf spark-2.2.3-bin-hadoop2.7.tgz -C /usr/local/
[root@qianfeng01 ~]# cd /usr/local/
[root@qianfeng01 local]# mv spark-2.2.3-bin-hadoop2.7/ spark-ha
2)配置spark的环境脚本
[root@qianfeng01 ~]# cd /usr/local/spark-ha/conf/
[root@qianfeng01 conf]# cp spark-env.sh.template spark-env.sh
[root@qianfeng01 conf]# vim spark-env.sh
.......在文件末尾添加如下内容..........
export JAVA_HOME=/usr/local/jdk
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=qianfeng01,qianfeng02,qianfeng03 -Dspark.deploy.zookeeper.dir=/sparkZookeeper"
3)配置slaves文件
[root@qianfeng01 conf]# cp slaves.template slaves
[root@qianfeng01 conf]# vim slaves
qianfeng01
qianfeng02
qianfeng03
- 分发到其他节点
[root@qianfeng01 ~]# scp -r /usr/local/spark-ha/ qianfeng02:/usr/local/
[root@qianfeng01 ~]# scp -r /usr/local/spark-ha/ qianfeng03:/usr/local/
5) 启动测试
1. 先启动zookeeper
2. 在qianfeng01上,运行/usr/local/spark-ha/sbin/start-all.sh
3. 在qianfeng02上,运行/usr/local/spark-ha/sbin/start-master.sh
6)查看webUI
在浏览器上输入:
http://qianfeng01:8080 应该是alive状态
http://qianfeng02:8080 应该使standby状态
7)模拟宕机
kill掉qianfeng01上的master, 在浏览器上检查qianfeng02的状态(注意要等一段时间,才会改变状态)
注意:若使用spark-shell启动集群需要添加配置
spark-shell --master spark://qianfeng01:7077,qianfeng02:7077
2.4.3 配置历史服务器
1. 启动HDFS、在HDFS上创建一个目录,用于存储spark作业的历史记录
[root@qianfeng01 ~]# start-dfs.sh
[root@qianfeng01 ~]# hdfs dfs -mkdir /sparkHaHistory
2. 修改spark的spark-default.conf文件
[root@qianfeng01 ~]# cd /usr/local/spark-standalone/conf
[root@qianfeng01 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@qianfeng01 conf]# vim spark-defaults.conf
......
#开启历史服务
spark.eventLog.enabled true
#存储路径
spark.eventLog.dir hdfs://qianfeng01:8020/sparkHaHistory
#是否压缩
spark.eventLog.compress true
3. 修改spark-env.sh文件,添加如下配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://qianfeng01:8020/sparkHaHistory"
4. 分发两个配置文件到其他节点
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng02:$PWD
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng03:$PWD
5. 启动历史服务器
先启动spark,
/usr/local/spark-standalone/sbin/start-all.sh
然后启动历史服务器
/usr/local/spark-standalone/sbin/start-history-server.sh
6. 查看进程
[root@qianfeng01 conf]# jps
5623 Master
5847 Jps
5048 DataNode
4905 NameNode
5773 HistoryServer <--------
5710 Worker
7. 使用webui查看
http://qianfeng01:4000
注意:查看历史服务器,必须查看alive节点上的历史服务器
2.4.4 测试程序
[root@qianfeng01 spark-ha]# /usr/local/spark-ha/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://qianfeng01:7077,qianfeng02:7077 \
--executor-memory 512m \
--total-executor-cores 2 \
/usr/local/spark-ha/examples/jars/spark-examples_2.11-2.2.3.jar \
100
问题总结:
1. 如果报以下提示: 说明 worker节点不正常,请检查
WARN TaskSchedulerImpl: Initial job has not accepted any resources;
2.5 Spark的YARN模式
2.5.1 说明
在国内的生产环境中,spark-yarn模式用的是最多的, 也就是用yarn作为spark程序运行时的资源调度框架
环境准备:
1. hdfs要安装好
2. yarn要配置好
2.5.2 搭建步骤
1)上传、解压、更名
[root@qianfeng01 ~]# tar -zxvf spark-2.2.3-bin-hadoop2.7.tgz -C /usr/local/
[root@qianfeng01 ~]# cd /usr/local/
[root@qianfeng01 local]# mv spark-2.2.3-bin-hadoop2.7/ spark-yarn
PS:如果在服务器上使用多种模式来跑spark程序的话,不建议配置环境变量
2)配置spark的环境脚本
[root@qianfeng01 ~]# cd /usr/local/spark-yarn/conf/
[root@qianfeng01 conf]# cp spark-env.sh.template spark-env.sh
[root@qianfeng01 conf]# vim spark-env.sh
.......在文件末尾添加如下内容..........
export JAVA_HOME=/usr/local/jdk
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop
3)配置slaves文件
[root@qianfeng01 conf]# cp slaves.template slaves
[root@qianfeng01 conf]# vim slaves
qianfeng01
qianfeng02
qianfeng03
- 分发到其他节点
[root@qianfeng01 ~]# scp -r /usr/local/spark-yarn/ qianfeng02:/usr/local/
[root@qianfeng01 ~]# scp -r /usr/local/spark-yarn/ qianfeng03:/usr/local/
- 修改hadoop的yarn-site.xml,并同步
这两项判断是否启动一个线程检查每个任务正使用的物理内存量/虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true 如果不配置这两个选项,在spark-on-yarn的client模式下,可能会报错,导致程序被终止。
在文件中增加以下两个属性:
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
别忘记同步
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml qianfeng02:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml qianfeng03:/usr/local/hadoop/etc/hadoop/
到此为止,yarn的配置结束
2.5.3 提交作业进行测试
要先启动hdfs和yarn才行。
使用spark-submit 提交spark自带的一个计算π值的程序到集群上运行,运算100次,求平均值,注意该指令直接在linux的命令行上使用
[root@qianfeng01 ~]# /usr/local/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 2 \
/usr/local/spark-yarn/examples/jars/spark-examples_2.11-2.2.3.jar 100
2.5.4 注意事项
1. 如果使用yarn模式,不需要启动standalone模式,两者没有关系,也就是不需要运行spark的start-all.sh
2. 那么一定要启动hdfs和yarn
3. 直接使用spark-submit在命令行上提交作业即可
也可以使用yarn的集群模式提交作业: 信息可以在yarn的webui:8088里查看
/usr/local/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 2 \
/usr/local/spark-yarn/examples/jars/spark-examples_2.11-2.2.3.jar \
100
2.5.5 配置历史服务器
1. 启动HDFS、在HDFS上创建一个目录,用于存储spark作业的历史记录
[root@qianfeng01 ~]# start-dfs.sh
[root@qianfeng01 ~]# hdfs dfs -mkdir /sparkYarnHistory
2. 修改spark的spark-default.conf文件
[root@qianfeng01 ~]# cd /usr/local/spark-yarn/conf
[root@qianfeng01 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@qianfeng01 conf]# vim spark-defaults.conf
......
#开启历史服务
spark.eventLog.enabled true
#存储路径
spark.eventLog.dir hdfs://qianfeng01:8020/sparkYarnHistory
#是否压缩
spark.eventLog.compress true
3. 修改spark-env.sh文件,添加如下配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=8089 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://qianfeng01:8020/sparkYarnHistory"
4. 关联yarn的历史服务与spark的历史服务
[root@qianfeng01 conf]# vim spark-defaults.conf
#spark历史服务器webui
spark.history.ui.port=8089
#点击yarn的日志时跳转到spark历史服务器webui
spark.yarn.historyServer.address=qianfeng01:8089
5. 分发两个配置文件到其他节点
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng02:$PWD
[root@qianfeng01 conf]# scp -r ./spark-env.sh ./spark-defaults.conf root@qianfeng03:$PWD
5. 启动历史服务器
/usr/local/spark-yarn/sbin/start-history-server.sh
6. 查看进程
[root@qianfeng01 conf]# jps
5623 Master
5847 Jps
5048 DataNode
4905 NameNode
5773 HistoryServer <--------
5710 Worker
7. 使用webui查看
http://qianfeng01:8089
注意:查看历史服务器,必须查看alive节点上的历史服务器
2.5.6 做测试
/usr/local/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 2 \
/usr/local/spark-yarn/examples/jars/spark-examples_2.11-2.2.3.jar \
100
运行作业后,访问webui 8088 或者8089
三、Spark的架构概述
3.1 Spark的运行架构
spark程序在运行期间,也是一个主从(master-slaves)架构,会涉及到图中的一些核心组件。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ISBkdwqO-1648306731546)(ClassNotes.assets/20191113162240.png)]
- Driver
每一个spark程序在运行时,都会启动一个Driver进程. 负责管理作业,相当于yarn的job提交流程中的appMaster(或者是client)
1. 用来提交和初始化作业: 路径的检查,权限,以及产生DAGScheduler,TaskScheduler
2. 与executor之间的通信(任务调度)
小贴士: 不启动作业,没有Driver
- executor
1. 真正执行Task的地方
2. 并向driver汇报运行情况
3. 一个worker节点上,可能运行多个Executor,一个Executor可以执行一到N个Task。
小贴士: 不启动作业时,没有executer
- Cluster Manager
资源调度框架的管理者,负责真正的分配资源
standalone:
Cluster Manager就是Master
yarn:
Cluster Manager就是ResourceManager
- Worker Node
节点的资源管理者,只负责本节点的资源分配
standalone:
Worker Node就是Worker
yarn:
Worker Node就是NodeManager
3.2 Spark中的其他概念
1)core和memory
作业在运行时,所使用的资源,也就是虚拟核数和内存。以下这些参数,就是用来指定资源的
--executor-memory <MEM>
用来指定每一个executor所使用的最大内存
--executor-cores <NUM>
用来指定每一个executor所使用的核数(也就是真正的线程数据)
--num-executors <NUM>
用来指定executor的总数量
2)并行度和并发
--并行度:
指的是线程真正的并行运行,指定的线程数量和服务器的核数一样,并且每个线程占用一个核
--并发:
指的是多线程并发运行,底层有可能是断断续续的
3)有向无环图
如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图 ,有向图中一个点经过两种路线到达另一个点未必形成环,因此有向无环图未必能转化成树,但任何有向树均为有向无环图。
ps: 通俗的来说就是有方向,没有回流的图可以称为有向无环图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-02npYIVG-1648306731546)(ClassNotes.assets/1图片5-1642431668793.png)]
相对复杂的DAG:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0z0DIeB6-1648306731547)(ClassNotes.assets/111图片4-1642431668794.jpg)]
4)stage
一个Spark作业一般包含一到多个Stage。Stage是由DAGScheduler在解析有向无环图时,根据宽依赖算子来划分Stage的。
--宽依赖算子:
指的通常都是发生了shuffle操作的算子
5)task
1. 一个Stage里通常会有多个分区的数据
2. 每个分区的数据由一个Task来执行, 这样就做到了spark的并行计算。
6)DAGScheduler
1. 将程序中的代码解析成DAG
2. 根据算子将DAG划分多个Stage
3. 每个Stage里会根据分区情况来产生Task
4. 将Task调度给TaskScheduler
7)TaskScheduler
1. 接收DAGScheduler传输的Task,保存到任务池中,
2. TaskScheduler将任务池里的Task分配给Executor进行执行
3.3 Spark的提交流程
3.3.1 spark-submit的用法说明
该指令的作用,是将spark程序,提交到集群上运行。直接在命令行上输入spark-submit 就可以查看用法
[root@qianfeng01 local]# /usr/local/spark-standalone/bin/spark-submit
Usage: spark-submit [options] <app jar | python file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
3.3.2 standalone的提交
standalone在运行程序时,有两种提交模式,分别是client和cluster
准备程序
将在idea写好的wordcount程序修改(arg(0),args(1))后,并打包上传到qianfeng01上。
1)client模式提交程序
/usr/local/spark-standalone/bin/spark-submit \
--class com.qf.sparkcore.day01.WordCount3 \
--master spark://qianfeng01:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 2 /root/sz2103_spark-1.0.jar hdfs://qianfeng01:8020/input/ hdfs://qianfeng01:8020/output110
最后两个参数,表示程序要统计的输入路径,以及输出路径
- cluster模式提交程序
/usr/local/spark-standalone/bin/spark-submit \
--class com.qf.sparkcore.day01.WordCount3 \
--master spark://qianfeng01:7077 \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 2 \
hdfs://qianfeng01:8020/jars/sz2103_spark-1.0.jar hdfs://qianfeng01:8020/input/ hdfs://qianfeng01:8020/output1110
注意事项:
1. cluster模式下,必须将程序提前上传到hdfs上, 即使用hdfs上的jar包程序
2. 运行时,会报以下警告, Master必须是REST server才可以运行
Warning: Master endpoint spark://qianfeng01:7077 was not a REST server. Falling back to legacy submission gateway instead
REST server 要求 端口号是6066 不是7077
3.3.3 yarn的提交(重点)
1. spark程序在使用yarn进行调度时,也有两种模式,分别使client和cluster
2. 运行spark-submit指令的那台机器,我们称之为spark程序提交时的客户端
1)使用yarn-client模式提交程序
/usr/local/spark-yarn/bin/spark-submit \
--class com.qf.sparkcore.day01.WordCount3 \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 2 \
/root/sz2103_spark-1.0.jar hdfs://qianfeng01:8020/input/ hdfs://qianfeng01:8020/yarn02
小贴士:
1. 最后两个参数,表示程序要统计的输入路径,以及输出路径
2. 客户端模式提交时,jar包 不需要上传到hdfs上
3. driver运行在提交作业的那台机器上
提交流程如下(重点)
YARN-client的工作流程步骤为:
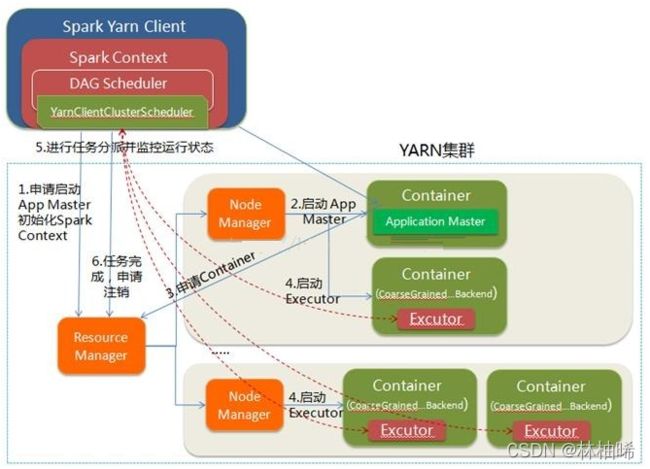
1. 在client端启动Driver进程,初始化作业,解析程序,初始化DAGScheduler,TaskScheduler.
-- 初始化作业: 判断路径是否存在,权限校验等
-- DAGScheduler将程序的执行流程解析成DAG图,并划分阶段,根据阶段内的分区初始化Task
-- TaskScheduler接收Task,等待分配Task给executor
2. Driver会向ResourceManager,申请资源,想要启动该应用程序的AppMaster
3. ResourceManager会分配一个节点,来运行AppMaster,由NodeManager负责真正分配资源并运行AppMaster
4. AppMaster会向ResourceManager申请整个程序所需要的其他资源,准备运行executor进程
5. ResourceManager分配资源后,由各个节点的NodeManager来启动executer,executor会向Driver进行反向注册,要求分配任务
6. TaskScheduler将Task分配到不同的executor,并监控实时状态,executor开始执行任务,
7. TaskScheduler收到executor执行完的信息后,表示整个应用程序完成,会向ResouceManager申请注销
2)使用yarn-cluster模式提交程序
/usr/local/spark-yarn/bin/spark-submit \
--class com.qf.sparkcore.day01.WordCount3 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 2 \
hdfs://qianfeng01:8020/jars/sz2103_spark-1.0.jar hdfs://qianfeng01:8020/input/ hdfs://qianfeng01:8020/yarn05
小贴士:
1. yarn的cluster模式提交时,jar包的位置可以在hdfs上,也可以在运行spark-submit指令的那一台机器上
3. driver不一定是在提交spark程序的那一台机器上
具体执行流程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AUz3wimB-1648306731548)(ClassNotes.assets/400827-20171206175225316-227997670-1642431668794.png)]
1. client会首先向ResourceManager申请资源,要求启动AppMaster进程
2. ResouceManager会分配一个节点,由NodeManager来运行AppMaster,并在AppMaster所在节点运行Driver进程
Driver进程的作用:,初始化作业,解析程序,初始化两个DAGScheduler,TaskScheduler.
-- 初始化作业: 判断路径是否存在,权限校验等
-- DAGScheduler将程序的执行流程解析成DAG图,并划分阶段,根据阶段内的分区初始化Task
-- TaskScheduler接收Task,等待分配Task给executor
3. AppMaster会向ResourceManager申请整个程序所需要的其他资源,准备运行executor进程
4. ResourceManager分配资源后,由各个节点的NodeManager来启动executer,executor会向Driver进行反向注册,要求分配任务
5. TaskScheduler将Task分配到不同的executor,并监控实时状态,executor开始执行任务,
6. TaskScheduler收到executor执行完的信息后,表示整个应用程序完成,会向ResouceManager申请注销
3.3.4 yarn-client提交和yarn-cluster提交的区别
Driver的位置不同:
1. yarn-client的driver在提交作业的client节点上
2. yarn-cluster的driver在appMaster节点
四、Spark的核心编程
整个Spark的核心编程涉及到三个核心内容,分别是RDD、累加器、广播变量,用于Spark的分布式并行计算。
4.1 RDD的基本概念
4.1.1 RDD是什么
1. RDD是Resilient Distributed Dataset的简写,叫做弹性分布式数据集,是Spark程序运行的最小单元
2. RDD是spark进行计算的数据的抽象,RDD不存储数据。
3. RDD代表一个不可变的,多分区的,可以并行计算的数据集合
4. RDD具有自动容错、位置感知性调度和可伸缩性
5. RDD提供了缓存机制,可以临时缓存到内存或者磁盘,用于下游的RDD直接从该处计算,可以提高查询效率
小贴士: 与MR的分片做一下比较。 分片是逻辑的,分片不存储真正的128M的数据
4.1.2 RDD与IO的比较

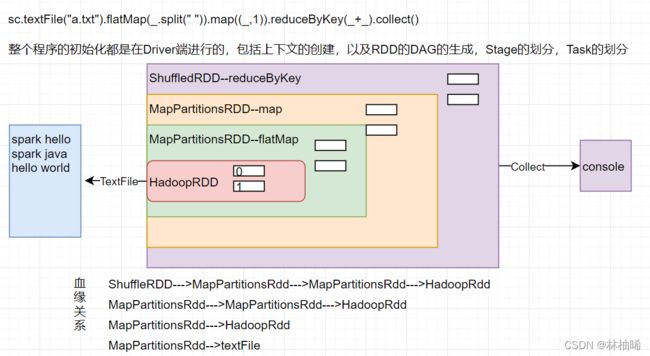
4.1.3 RDD的五大主要特性
RDD是一个抽象的、不可变的、已分区、可以并行计算的数据集合。RDD有多种子类型,比如HadoopRDD,ShuffledRDD,PairPartitionsRDD等,不管哪一种RDD,都具备五个主要特性。
- A list of partitions # 每一个RDD都会维护着一个分区列表,即有哪些分区号, 用来决定有多少个Task并行运行
- A function for computing each split #每个RDD里都有一个计算函数 (真正处理分区对应的数据的逻辑运算)
- A list of dependencies on other RDDs #每个RDD里都维护着一个依赖关系( 该RDD是如何转换而来)
# 可选的分区器:针对于KV形式的RDD,可以指定某一种分区器,非KV形式的RDD不能指定分区器
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
# 可选的首选位置:可以存储每个分区对应的数据的具体位置,这样的优势,方便移动计算到有数据的节点
- Optionally, a list of preferred locations to compute each split on (e.g. block locations foran HDFS file)
4.1.4 RDD的弹性体现
如果一个框架具有弹性概念,表示这个框架的优点很多,弹性就是好处、可变的意思,可以调节,改变。
1. 存储的弹性:内存与磁盘
2. 自动切换容错的弹性:可以选择丢失一小部分数据。
3. 自动恢复计算的弹性:计算出错重试机制 ---->Task失败时,可以重启Task
4. 分片的弹性:根据需要重新分片 ,也就是可以自定义分区规则
小贴士:
spark的分片即分区,类似于mr的Map端的分片(inputSplit-->FileSplit)。
4.2 RDD的编程
4.2.1 RDD的获取方式
RDD的获取方式有四种
1. RDD来源于直接读取内存的数据
2. RDD来源于读取外部数据(文件)
3. RDD来源于上游RDD (这种情况使指程序在运行时,转换而来)
4. RDD可以new出来 (这种情况,在生产环境中,用的非常少,一般情况下指的是源码中的new操作)
前两种的获取方式源码:
//从内存中创建RDD
val rdd: RDD[Int] = sc.parallelize(List(1,2,3,4,5))
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
//从文件中创建RDD
val rdd: RDD[String] = sc.textFile("D:/input/words.txt")
val rdd: RDD[String] = sc.textFile("data/1.txt")
4.2.2 RDD的并行度与分区
rdd的并行度,指的就是rdd里的分区个数,表示spark程序在运行时,可以同时运行多少个Task。并行度指的每个execoter的core数与Task数据一致。
1)读取内存数据的并行度和分区
package com.qf.sparkcore.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 并行度:
* 分区的数量,表示可以同时运行多少个Task. 在设置参数时每个executor的vcore数量要与Task的数量保持一致
*
* 1 :读取内存数据的并行度和分区
*/
object Spark_03_parallelize_1 {
def main(args: Array[String]): Unit = {
/**
* local: 表示一个并行度,即使用本地的cpu的一个内核
* local[4]:使用4个core计算程序
* local[*]: 使用cpu的总core数计算程序 : 总core数量,去任务管理器或者此电脑-->管理-->设备管理器-->处理器
*/
val conf = new SparkConf().setMaster("local").setAppName("")
val sc = new SparkContext(conf)
/**
* makeRDD(seq: Seq[T],numSlices: Int = defaultParallelism)
* 第二个参数:是用来指定分区数量的。
*
* 解析:
* 如果自定义了分区的数量,那么一定是自定义的值。
* 如果没有自定义,则使用默认值 defaultParallelism --->taskScheduler.defaultParallelism
* 即使用setMaster()指定的并行度。
*
*/
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5))
/**
* 将数据存储到文件中,就可以查看具体的分区数量
*/
rdd1.saveAsTextFile("output3")
sc.stop()
}
}
2)读取文件数据的并行度和分区
package com.qf.sparkcore.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 2 :读取文件数据的并行度和分区
*/
object Spark_04_parallelize_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("")
val sc = new SparkContext(conf)
//读取文件
val rdd1 = sc.textFile("input/words.txt")
/**
* 将数据存储到文件中,就可以查看具体的分区数量
* 注意:输出目录不能提前存在
* 11/3
* long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // 计算要统计的文件的总字节数量
*
* long blockSize = file.getBlockSize();
* long splitSize = computeSplitSize(goalSize, minSize, blockSize); //求goalSize minSize blockSize的中间值
*
* 计算真正的分区个数
* long bytesRemaining = length; // 文件总字节长度
* while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
* String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
* length-bytesRemaining, splitSize, clusterMap);
* splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts[0], splitHosts[1]));
* bytesRemaining -= splitSize;
* }
* 11 / 3 > 1.1 --> 获取一个分片
* 8 / 3 > 1.1 --> 获取一个分片
* 5 / 3 > 1.1 --> 获取一个分片
* 2 / 3 > 1.1 --> 2个字节单独封装一个分片 共四个分片,也就是四个分区
*
* 总结:
* 当我们自定义分区数量时,真正的分区数量可能大于该值。 原因是因为使用了mr的分片计算方式。
* 小贴士: 可能某些分区里没有数据。 按行读取数据, 一个分区如果想要有数据,那么至少要读取一行。读过的数据不会重新读取,所以后续的分区可能没有数据
*
* 如果没有自定义分区数量, 则使用默认值,即Int = math.min(defaultParallelism, 2)
* 该逻辑是用 2和setMaster()指定的数量做比较 取较小值。 但是实际分区数量可能大于该值,原因是因为使用了mr的分片计算方式。
*/
rdd1.saveAsTextFile("output8")
sc.stop()
}
}
3)研究一下分区内部的数据
先研究一下读取内存数据时,数据是如何分区的
package com.qf.sparkcore.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 研究: 读取内数据时,是如何分区的
*/
object Spark_05_parallelize_3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("")
val sc = new SparkContext(conf)
/**
* def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
* (0 until numSlices).iterator.map { i =>
* val start = ((i * length) / numSlices).toInt
* val end = (((i + 1) * length) / numSlices).toInt
* (start, end)
* }
* }
* length: 元素的个数 5
* numSlices: 分区数量 3
* i = 0 时
* start = 0
* end = 1
* (0, 1) --> [1]
* i = 1 时
* start = 1
* end = 3
* (1,3) --> [2,3]
* i = 2 时
* start = 3
* end = 5
* (3,5) --> [4,5]
*
* 总结:当数据的个数可以被分区数整除,则均分,如果不能整除,则从后面开始尽量均分,也就是span分段
*/
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5), 3)
rdd1.saveAsTextFile("output1001")
sc.stop()
}
}
再研究一下读取文件时,数据是如何分区的
package com.qf.sparkcore.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 研究: 读取文件时,数据是如何分区的
*/
object Spark_06_parallelize_4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("")
val sc = new SparkContext(conf)
/**
* 当读取文件时,真正的分区数量可能大于该值
*
* long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // 计算要统计的文件的总字节数量
*
* long blockSize = file.getBlockSize();
* long splitSize = computeSplitSize(goalSize, minSize, blockSize); //求goalSize minSize blockSize的中间值
*
* 计算真正的分区个数
* long bytesRemaining = length; // 文件总字节长度
* while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
* String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
* length-bytesRemaining, splitSize, clusterMap);
* splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts[0], splitHosts[1]));
* bytesRemaining -= splitSize;
* }
* if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length, bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining, splitHosts[0], splitHosts[1]));
}
*
*
* 11 / 3 > 1.1 --> 获取一个分片
* 8 / 3 > 1.1 --> 获取一个分片
* 5 / 3 > 1.1 --> 获取一个分片
* 2 / 3 > 1.1 --> 2个字节单独封装一个分片 共四个分片,也就是四个分区
*
* 真正的数据如下:
* 12@@
* 3456@@
* 1
* 共有11个字节,
* 先计算分区数量: goalSize= 11/2 = 5 再计算 1、5 128M的中间值 也就是splitSize = 5
* 11/5 = 2.2 > 1.1 ---- > 获取一个分片
* 6/5 = 1.2 > 1.1 ---- > 获取一个分片
* 1/5 = 0.2 > 1.1 不大于,因此单独构建一个分片
* 即 共有三个分片,也就是三个分区
* 3个分区
* 每个分区的字节数:应该为splitSize指定的字节数 也就是5个
* 行偏移量
* [0,4]:
* [4,10]
* [10,]
* 按照行读取数据: 第一次读取第一行的记录,4个字节,不满足5个字节。因此要继续读取一行
* 第一个分区的数据如下:
* 12@@
* 3456@@
* 第二个分区的数据如下: 因为读过的数据不会重读,因此读取的是第三行的数据
* 1
* 第三个分区的数据:是空,没有数据了
*
*
*/
val rdd1 = sc.textFile("input/words.txt",2)
rdd1.saveAsTextFile("output1002")
sc.stop()
}
}
4.2.3 RDD的读取和保存
1)先测试保存
package com.qf.sparkcore.day03
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 研究:sparkcore的读取文件和保存成文件
*/
object Spark_01_SaveFile_01 {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("readAndSave")
var sc:SparkContext = new SparkContext(conf)
val rdd1: RDD[String] = sc.textFile("input/words.txt")
/**
* 保存文件: 目录不能提前存在
* 1.保存成纯文本文件
* saveAsTextFile(path:String)
* 2. 保存成Sequence文件
* saveAsObjectFile(path:String) : object文件,也叫sequenc文件,但是格式和saveAsSequenceFile方法保存的格式不一样
* saveAsSequenceFile(path:String) : 存储一个键值对形式的数据
*/
rdd1.saveAsTextFile("textFile")
rdd1.saveAsObjectFile("objectFile")
rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsSequenceFile("sequenceFile")
sc.stop()
}
}
2)再测试读取
package com.qf.sparkcore.day03
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 研究:sparkcore的读取文件和保存成文件
*/
object Spark_02_ReadFile_01 {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("readAndSave")
var sc:SparkContext = new SparkContext(conf)
/**
* 读取文件:
* 1. 读取纯文本文件 用来读取纯文本文件, 包括json,csv文件
* textFile(path:String)
* 如果是json文件,需要自行解析,代码参考mr的json案例,hive的自定义json函数,
* 如果是csv文件,只需要使用逗号切分即可。
*
* 2. 读取sequenceFile文件
* objectFile(path:String) : 只能读取sequence文件
* sequenceFile(path:String)
* 3. wholeTextFiles(path:String)
* 读文件时,将文件路径和文件内容构成对偶形式的元组
*/
val rdd1: RDD[String] = sc.textFile("input/words.txt")
val rdd2 = sc.wholeTextFiles("input/words.txt")
val rdd3: RDD[String] = sc.objectFile("objectFile")
val rdd4: RDD[(String, Int)] = sc.sequenceFile[String, Int]("sequenceFile")
rdd1.saveAsTextFile("output1")
rdd2.saveAsTextFile("output2")
rdd3.saveAsTextFile("output3")
rdd4.saveAsTextFile("output4")
sc.stop()
}
}
4.2.4 RDD的算子介绍
rdd里的函数,
(1)从类型上分为两种类型,一种是转换(Transformation)算子,一种是行动(Action)算子.
(2)从处理的数据形式来分类:
--单value类型的转换算子
--双value类型的转换算子 双value指的使双数据源(双RDD)
--KV对类型的转换算子
转换算子: 指的是一个RDD类型转换成另一个RDD类型
行动算子: 用于触发真正计算的算子
为什么叫算子,而不叫函数了?
scala的函数都是作用在一个机器节点上的
spark的函数是将一个机器节点上的数据转到其他节点上计算的,
为了区分这两种情况,spark的函数就叫算子,而不叫函数了
4.2.5 转换算子之单Value算子
1)map算子
方法签名:map[U: ClassTag](f: T => U): RDD[U]
作用:将一个泛型为T的序列里的value映射成另外一个U类型的值
T和U可以相同,也可以不同
优点:
map函数可以做任何类型的一对一映射
缺点:
因为map函数是对分区内的值,一个一个处理的,所以性能比较低
练习: 获取data.log.txt里的ip地址
参考代码:com.qf.spark.wc.day03.singleValue._03TestMap_parallelize
2)mapPartitions算子
方法签名:mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
作用:将带处理的数据以分区为单位,进行处理操作,内部提供了一个缓存。
性能高于map函数,类似于字节流包装了字节缓冲流,提供了缓存区
缺点:分区的数据被缓存到内存中,如果没有处理完这个缓存中的数据,还有就是该缓存会一直被引用变量引用,则可能会出现该缓存不能一直释放掉,所以,容易造成内存泄漏。
练习:获取每个分区的最大值
参考:com.qf.spark.wc.day03.singleValue._05TestMapPartitions_exercise
map和mapPartitions函数的区别
map:
-- 以单个值为单位进行处理
-- 效率低,如果处理的数据量大,不追求效率,建议使用map函数
--
mapPartitions:
-- 以分区为单位进行处理
-- 效率高,如果处理的数据量小,可以使用mapPartitions函数
3)mapPartitionsWithIndex
方法签名:
mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false)
作用:将带处理的数据以分区为单位,进行处理操作,内部提供了一个缓存,同时使用一个参数表示该迭代器所对应的分区号
练习:打印每个分区的最大值,以及所在分区号
参考代码:com.qf.spark.wc.day03.singleValue._07TestMapPartitionsWithIndex_exercise
4)flatMap算子
方法签名:flatMap[U](f:T=>TraversableOnce(U)) :RDD[U]
作用:将元素扁平化,并做一一映射。
练习:
List("hello world","hello spark")
List(List(1,2,3),3,List(4,5,6))
5)glom算子
作用:将RDD中的每一个分区的所有数据转成内存数组,并返回, 保持分区数不变
6)groupBy算子
方法签名: groupBy[K](f:T=>K):RDD[(K,Iterator[T])]
作用:
将元素按照指定的规则转成K,然后进行分组。返回的类型是一个对偶元组,该元组的第二个参数是相同K对应的所有元素
小贴士:
底层发生了shuffle操作
shuffle: 一个分区的数据被打乱并重新组到下游的RDD的不同的分区。
练习1:
将List("Hello","Spark","world","Scala","Hadoop") 按照首字母进行分组
练习2:
数据文件:data.log.txt 需求:统计每个手机号出现的次数
7)filter算子
方法签名:
filter(f:T=>Boolean):RDD[T]
作用:
用于过滤满足条件的数据, 满足条件就返回,不满足就过滤
可能出现数据倾斜
8)sample算子
抽样函数
方法签名:
sample( withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong)
作用:
通常用于对分区里的数据进行采样,然后判断数据是否倾斜,当然也可以模拟抽奖操作
解析:
第一个参数表示,是否放回进行抽取 false表示不放回,true表示放回
第二个参数:
--如果不放回,第二个参数表示每个数字出现的概率,通常要指定0~1以内的小数
--如果放回,则表示每个数字应该被抽取的次数, 通常指定>=1的自然数,不表示都使被抽取指定次数,而是在指定次数左右
9)distinct算子
方法签名:
distinct()
distinct(numPartions:Int)
作用: 用于去重,
逻辑: 先分区内去重,然后分区间去重
10) coalesce算子
注意:该算子为缩减分区算子,通常用于减少分区
方法签名:coalesce(numPartitions:Int,shuffle:Boolean=false)
作用:用于缩减分区,默认情况下,不发生shuffle,也就说上游的一个分区的所有数据都会进入下游的某一个分区中,不会被打散。
能不能用于增加分区?
-- 能,如果指定一个参数,不会生效
如果想要生效,那么需要指定shuffle为true
11) repatition算子
方法签名
作用:用于对上游的数据进行重新分区
分区数量可以变大,也可以变小
底层逻辑:调用的是coalesce(numPartitions,true)
12)sortBy算子
方法签名:
sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)
解析:
第一个参数:用于指定排序字段
第二个参数:表示是否升序,默认为升序,false表示降序
注意:底层会涉及到shuffle
练习题:
List(("11","11"),("1",1),("2",2)) 按照K进行排序
4.2.6 转换算子之双Value算子
双value指的使两个RDD进行操作、常用的有交集、并集、差集、以及拉链操作
1)intersection、union、subtract
package com.qf.spark.wc.day04.doubleValue
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 测试 RDD之间的交集、并集、差集、拉链操作
*/
object _01TestDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("createRdd")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
var rdd2: RDD[Int] = sc.makeRDD(List(3,4,7,8), 2)
/**
* 进行交集、并集、差集操作时、两个RDD的泛型要一致
*/
//测试交集算子
val result1: RDD[Int] = rdd1.intersection(rdd2)
//测试并集算子
val result2: RDD[Int] = rdd1.union(rdd2)
//测试差集算子
val result3: RDD[Int] = rdd1.subtract(rdd2)
result1.collect().foreach(println)
println("---------------")
result2.collect().foreach(println)
println("---------------")
result3.collect().foreach(println)
sc.stop()
}
}
2)拉链(zip)
package com.qf.spark.wc.day04.doubleValue
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 测试 RDD之间的交集、并集、差集、拉链操作
*/
object _01TestZip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("createRdd")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
var rdd2: RDD[Int] = sc.makeRDD(List(3,4,7,8), 2)
var rdd3: RDD[String] = sc.makeRDD(List("3","4","7","8"), 2)
var rdd4: RDD[Int] = sc.makeRDD(List(7,8),2)
val result1: RDD[(Int, Int)] = rdd1.zip(rdd2)
/**
* 研究:类型不一样的情况
* 注意: 两个rdd在进行拉链时,可以是不同类型的RDD做拉链
*/
val result2: RDD[(Int, String)] = rdd1.zip(rdd3)
/**
* 研究长度不一致的情况
*
* 结论: 长度不一致,不可以拉链
* 分区数不相同,也不能拉链
*/
//val result3: RDD[(Int, Int)] = rdd1.zip(rdd4)
result1.collect().foreach(println)
println("-----------------")
result2.collect().foreach(println)
//result3.collect().foreach(println)
sc.stop()
}
}
4.2.7 转换算子之KV型算子
1)mapValues算子
方法签名:
mapValues[U](f: V => U): RDD[(K, U)]
作用:和map算子的功能一样,唯一的区别就是处理的数据是PairRDD,对PairRDD的V进行映射
2)partitionBy算子
作用: 通过指定的分区器用来对上游的RDD的数据进行分区
方法签名:
partitionBy(partitioner:Partitioner)
总结:
1. 数据的分布,可能会发生shuffle
2. HashPartitioner,RangePartitioner
3. 除了spark自带的分区器之外,可以根据自定义分区器来进行分区
3)reduceByKey算子
方法签名:
reduceByKey(func: (V, V) => V): RDD[(K, V)]
作用:
按照key进行分组,然后同组内的多个value做归约运算
注意:
1. value在做归约运算时,一般情况都是两两运算
2. 如果一个组里只有一条数据时,就直接返回
4)groupByKey算子
方法签名:
groupByKey() 底层会按照默认的分区器进行分组。默认的分区器使Hashpartitioner
groupByKey(numPartitions:Int)
groupByKey(partitioner:Partitioner)
作用:通过key进行分组操作,默认使用Hashpartitioner
相同key的数据分到一个组中,形成一个对偶元组,
元组中的第一个元素,就是Key
元组中的第二个元素,就是同一个Key的多个value对应的迭代器
groupBykey与groupBy的区别
1. 在处理的数据上:
groupByKey只能处理PairRDD
groupBy可以处理任何类型的数据
2. 在返回值上:
groupBykey返回的是对偶元组,元组的第一个元素是Key,第二个元素是value的迭代器
groupBy返回的也是对偶元组,元组的第一个元素是自定义的Key,第二个元素是上游RDD的元素的迭代器
小貼士:groupBy底层会调用groupBykey
reduceByKey与groupByKey的区别
1. 在shuffle的过程中
-- 两个都会发生shuffle,groupByKey不会进行预聚合,reduceByKey会进行预聚合
-- 数据都会进行落盘操作
性能上,虽说两者都变慢了,但是reduceByKey快,原因是reduceByKey减少了数据量的磁盘IO。
2. 在功能上:
reduceByKey会有分组和聚合的功能
groupByKey只有分组的功能。
所以在真正使用时,要看实际需求,如果只需要分组,不需要聚合,则使用groupByKey
如果需求中有分组和聚合需求,只需要使用reduceByKey就可以
5)aggregateByKey算子
方法签名:
aggregateByKey[U: ClassTag]
(zeroValue: U)
(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
第一个参数列表:
提供一个默认值
第二个参数列表:
第一个参数seqOp: 表示预聚合的函数,也就是分区内的运算逻辑
第二个参数combOp:表示分区间的运算逻辑
练习
分区内的数据求最大值,分区间的数据求和
6)foldByKey算子
方法签名:
foldByKey(zeroValue: 0)(func: (V, V) => V): RDD[(K, V)]
作用:
提供一个默认值,并且提供一个计算逻辑,用于分区内的计算以及分区间的计算
7)combineByKey算子
方法签名:combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C)
第一个参数:就是第一个value的转换操作,使之当成默认值
第二个参数:用于指定分区内的计算逻辑:
第三个参数:用于指定分区间的计算逻辑
研究:reduceByKey、aggregateBykey、flodByKey、combineByKey的区别
package com.qf.spark.wc.day04.kv
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object _09TestReduceAggregateFlodCombineByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("a", 2), ("b", 4), ("b", 5)), 2)
/**
* reduceByKey的底层调用方法:
* combineByKeyWithClassTag[V](
* (v: V) => v, //第一个value直接返回
* func, //用于指定分区内的计算逻辑
* func, //用于指定分区间的计算逻辑
* partitioner)
*
* aggregateByKey的底层调用方法:
* combineByKeyWithClassTag[U](
* (v: V) => cleanedSeqOp(createZero(), v), // 使用指定的默认值与第一个v做运算
* cleanedSeqOp, //用于指定分区内的计算逻辑
* combOp, //用于指定分区间的计算逻辑
* partitioner)
*
*
* flodByKey的底层调用方法:
* combineByKeyWithClassTag[V](
* (v: V) => cleanedFunc(createZero(), v), // 使用指定的默认值与第一个v做运算
* cleanedFunc, //用于指定分区内的计算逻辑
* cleanedFunc, //用于指定分区间的计算逻辑
* partitioner)
*
* combineByKey的底层调用方法:
*
* combineByKeyWithClassTag(
* createCombiner, //表示对第一个value的转换操作,使之成为默认值
* mergeValue, //用于指定分区内的计算逻辑
* mergeCombiners, //用于指定分区间的计算逻辑
* defaultPartitioner(self))
*
*
* 相同点:底层调用的是同一个方法
*/
rdd.reduceByKey(_+_)
rdd.aggregateByKey(0)(_+_,_+_)
rdd.foldByKey(0)(_+_)
val value: RDD[(String, Int)] = rdd.combineByKey(x=>x, (x: Int, y: Int) => math.max(x, y), (x: Int, y: Int) => x + y)
value.collect().foreach(println)
}
}
8)join、leftOuterJoin、rightOuterJoin
package com.qf.spark.wc.day04.kv
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object _10TstJoinDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("c", 4),("d",5)), 2)
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a", 5), ("b", 6), ("b", 7), ("c", 8),("e",9)), 2)
/**
* join/leftOuterJoin/rightOuterJoin算子
* 作用:就是让两个pairRDD进行内连接/左外连接/右外连接
* 通过key连接
*
*/
val value1: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
val value2: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
val value3: RDD[(String, (Option[Int], Int))] = rdd1.rightOuterJoin(rdd2)
value1.collect().foreach(println)
println("----------------------------")
value2.collect().foreach(println)
println("----------------------------")
value3.collect().foreach(println)
}
}
9)cogroup算子
package com.qf.spark.wc.day04.kv
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object _11TestCoGroup {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("c", 4),("d",5)), 2)
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a", 5), ("b", 6), ("b", 7), ("c", 8),("e",9)), 2)
/**
*
* cogroup:
*
* 作用:
* 相当于两个rdd先各自分组(groupByKey),再进行全外jion。
* 参考输出结果
*
* (a,(List(1,2),List(5)))
* (b,(List(3),List(6,7)))
* (c,(List(4),List(8)))
* (d,(List(5),List()))
* (e,(List(),List(9)))
*/
val value: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
value.collect().foreach(println)
}
}
4.2.8 行动算子的应用
1)行动算子的介绍
行动算子,是用于触发spark应用程序的真正提交操作的。
参考代码解析:com.qf.spark.wc.day05.action._01ActionIntroduce
2)常用的简单行动算子
collect: 搜集函数
按照分区号从小到大的顺序收集,并返回给Driver端
collectAsMap:搜集函数,
对KV形式的RDD按照分区号从小到大顺序收集,并返回给Driver端,返回值类型为Map
count: 统计RDD里的数据的个数
first: 获取RDD中的第一个元素
take: 获取RDD中的前N个元素,返回值类型为数组
takeOrdered: 获取RDD中升序排序后的前N个元素,返回值类型为数组
top: 获取RDD中降序排序后的前N个元素,返回值类型为数组
takeSameple: 从RDD中抽取N个样本
countByKey: 统计PairRDD的每种key的个数,返回值类型 (K,N)
countByValue:统计rdd的每种值的个数,返回值类型 (V,N)
3)保存算子
saveAsTextFile
saveAsObjectFile
saveAsSequenceFile
4) reduce、aggregate、fold
reduce: 用于归约运算,先分区内计算,然后分区间计算
aggregate: 做聚合计算,需要指定一个默认值, 分区内指定计算规则,分区间可以指定计算规则
fold: aggregate(分区内和分区间计算规则一样时)算子的简化函数
5)foreach
行动算子,用于在executor端口迭代, 所以说,如果是集群模式提交作业,那么根本在client处看不到打印信息
4.3 RDD的其他相关概念
4.3.1 RDD的序列化
1)闭包检测
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。
Scala2.12 版本后闭包编译方式发生了改变
package com.qf.sparkcore.day04
import org.apache.spark.{SparkConf, SparkContext}
object Spark_09_closePacket_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("kv").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
//创建一个Student对象
val s1 = new Student("michael", 23)
/**
* foreach行动算子是在executor端运行的。
* 所以,如果行动算子中涉及到了外部的变量或者对象等数据。而外部变量都是在driver端创建的,会涉及到传输操作,那么需要序列化操作
*
* 这里有一个机制:叫闭包检测机制
*
* 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。
* 那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,
* 如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,
* 这个操作我们称之为闭包检测。
*
*
* 回顾:闭包的概念
* 当匿名函数使用了外部环境的变量时,就会将本身和外部的变量一起打包存储到堆里。 会涉及一个序列化检查机制。
*
* 源码如下:
* val cleanF = sc.clean(f)
* --- ClosureCleaner.clean(f, checkSerializable)
* ......
* if (!isClosure(func.getClass)) { // 没有闭包,就报错
* logWarning("Expected a closure; got " + func.getClass.getName)
* return
* }
* ....
* if (checkSerializable) { // 闭包,并检查序列化
* ensureSerializable(func) // 确保序列化,如果没有序列化,则报错
* }
*/
rdd1.foreach(elem => {
println("这个学生的年龄:" + s1.age + "\t 元素是:" + elem)
})
sc.stop()
}
}
class Student() extends Serializable {
var name: String = ""
var age: Int = 0
def this(name: String, age: Int) {
this()
this.name = name
this.age = age
}
}
2)函数和属性传递
package com.qf.sparkcore.day04
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark_10_FunctionAndPropertyPass_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("spark","hadoop","java","scala"),2)
val searchFunctions = new SearchFunctions("hadoop",5)
/**
* 调用getMatchesFunctionReference方法,研究函数的传递
* 即filter(isMatch),传入了一个函数,真正计算时是在executor位置上计算的
*
* 总结:函数的传递,也需要函数所在的类继承序列化接口
*/
/* val result: RDD[String] = searchFunctions.getMatchesFunctionReference(rdd1)
result.collect().foreach(println)*/
/**
* getMatchesFieldReference,研究属性的传递
* filter(x => x.contains(query)),传入了一个query,query是对象的属性
* 真正计算时是在executor位置上计算的
*
* 总结:属性的传递,也需要属性所在的类继承序列化接口
*/
/* val result: RDD[String] = searchFunctions.getMatchesFieldReference(rdd1)
result.collect().foreach(println)*/
/**
* 研究局部变量的传递,前提局部变量的类型是已经序列化过的类型, --- 闭包检测是一定发生的
*
* 用途:当想要将某一个类的属性传递到算子中,而且这个类还不想序列化,则可以将该属性
* 用一个局部变量来接收。 前提该局部变量的类型是已经序列化过的。
*/
val result: RDD[String] = searchFunctions.getMatchesNoReference(rdd1)
result.collect().foreach(println)
}
}
//准备一个类,提供几个函数 : 注意事项, 主构造器中的形式参数,会转成类的属性
class SearchFunctions(query: String,num:Int) { // 主构造器中的参数,如果是var|val声明的,
// 就是属性,如果没有修饰,则是局部变量,但是,如果类里的方法应用到了该参数,则会将该参数"提升"为属性
//就是提供一个普通方法
def isMatch(s: String): Boolean = {
s.contains(query)
}
//
def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = {
//该方法中用到了算子filter,而filter中传入了一个普通方法
rdd.filter(this.isMatch)
}
def getMatchesFieldReference(rdd: RDD[String]): RDD[String] = {
//该方法中用到了算子filter,而filter中传入了一个匿名函数
rdd.filter(x => x.contains(this.query))
}
def getMatchesNoReference(rdd:RDD[String]):RDD[String] = {
val query_ = this.query
//该方法中用到了算子filter,而filter中传入了一个匿名函数,但是匿名函数用到了外部的局部变量
rdd.filter(x => x.contains(query_))
}
}
3)Kryo序列化机制
几乎所有的资料都显示kryo 序列化方式优于java自带的序列化方式,而且在spark2.*版本中都是默认采用kryo 序列化。
1.先给出定义:
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为内存中的对象的过程称为对象的反序列化。
2.序列化的两大应用领域
- 存储
- 网络传输
3.spark中的序列化
那么对象以何种形式进行传输性能更好呢?
在spark2.0+版本的官方文档中提到:spark默认提供了两个序列化库:Java自身的序列化和Kryo序列化
目前:Kryo序列化机制,只能序列化部分类型,因此spark采用了两个序列化机制的混合形式
4.3.2 RDD的依赖关系
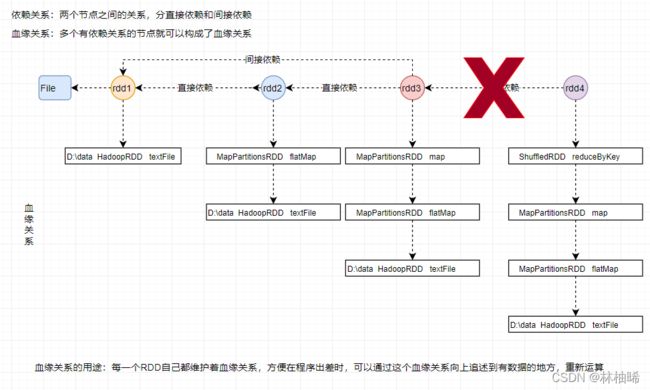
1)血缘关系
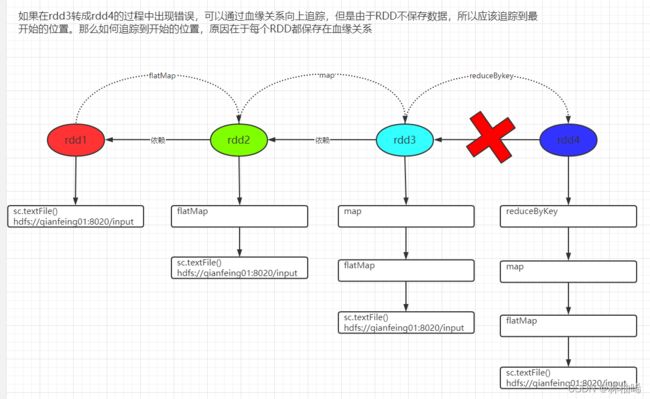
血缘关系的应用,如下图所示
2)宽窄依赖
shuffle: 上游的RDD的一个分区的数据被打散,重新分到下游的不同的分区中。
窄依赖,如下图所示
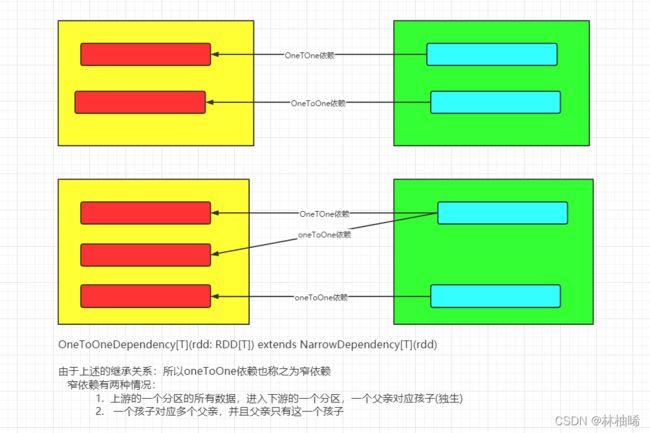
窄依赖:就是上游RDD的每一个分区都对应下游RDD的一个分区。 即一个父亲对应一个孩子,一个分区对应一个分区
宽依赖:
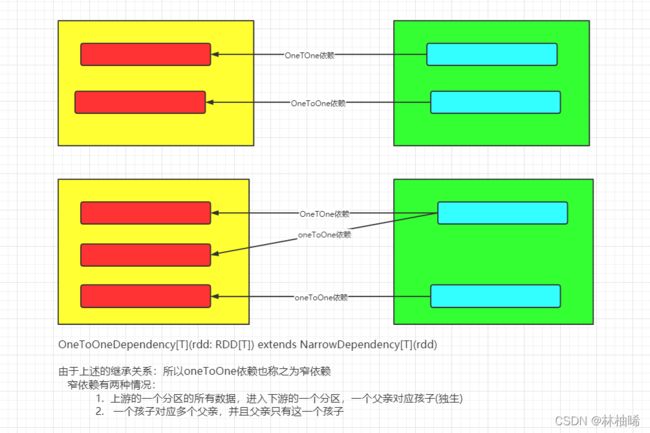
总结: 宽和窄依赖 是针对于两个有直接依赖关系的RDD来说的。
换句话说: 宽窄依赖都是针对于RDD是由上游RDD怎么转换而划分的两个概念。
groupBy
groupByKey
reduceByKey
aggregateBykey
foldByKey
combineByKey
partitonBy
3)阶段划分和Task划分
阶段划分图解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6k73m0ta-1648306731550)(ClassNotes.assets/image-20211020172937708-1642640176195.png)]
Task划分图解:
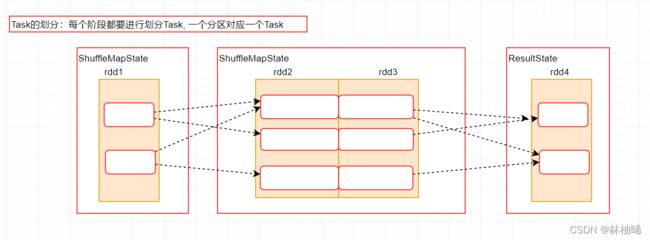
1. 阶段的名称 任务名称
ShuffleMapState--->ShuffleMapTask
ResultState--->ResultTask
2. 四个概念
--Application:初始化一个SparkContext,即生成一个Application, 说白了就是submit指令提交的一个应用程序 appId
--Job:一个Action算子就会生成一个Job
--State:宽依赖是State划分的界限,因此State的个数等于宽依赖的个数+1
--Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数
3. 四个概念的对应关系
Application-->Job-->State-->Task四者的关系都是1对多的关系
4)webUI中查看Stage和Task
自己提交一个yarn-cluster模式的application,然后查看历史服务器
5)Driver提交作业的四个阶段
四个步骤:
1,构建所有的Job的DAG
用户提交的application将首先被转换成一系列RDD并通过RDD之间的依赖关系构建DAG,然后将DAG提交到调度系统;
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算;
DAG是有边界的:开始(通过sparkcontext创建的RDD),结束(触发action,调用runjob就是一个完整的DAG形成了,一旦触发action,就形成了一个完整的DAG);
一个RDD描述了数据计算过程中的一个环节,而一个DAG包含多个RDD,描述了数据计算过程中的所有环节;
一个spark application可以包含多个DAG,取决于具体有多少个action。
强调: 上述的内容强调的其实是一个DAG对应一个JOB
就是DAG有向无环图中的某一条路。即job
2,DAGScheduler将DAG切分stage(切分依据是shuffle),将stage中生成的task以taskset的形式发送给TaskScheduler
为什么要切分stage?
复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)
如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,下一个阶段的计算依赖上一个阶段的数据
在同一个stage中,会有多个算子,可以合并到一起,我称其为pipeline(流水线,严格按照流程、顺序执行)
3,TaskScheduler 调度task(根据资源情况将task调度到Executors)
4,Executors接收task,然后将task交给线程池执行。
4.3.3 RDD的缓存和持久化
1)没有持久化操作的演示
RDD对象的重用,但是数据无法重用
package com.qf.spark.wc.day06.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object _01TestCache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val context: SparkContext = new SparkContext(conf)
var lines: RDD[String] = context.textFile("D:/input/words.txt")
var words: RDD[String] = lines.flatMap((line) => {
println("------------------")
line.split(" ")
})
var wordAndOne: RDD[(String, Int)] = words.map((_, 1))
var value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
var result: Array[(String, Int)] = value.collect()
//利用value再产生一个job,该job不会从头读取数据,直接利用临时文件
value.foreach(println)
result.foreach(println)
println("--------------另起一个job 进行对单词分组----------------")
//该job会从头读取数据
wordAndOne.groupByKey().collect().foreach(println)
context.stop()
}
}
2)cache和persist的基本原理
问题?什么时候适合使用缓存或者持久化机制
1. 想要重用算子计算出来的数据
2. 某一个算子计算时间过长,可以使用
3. 算子过多时,可以使用
小贴士:
都是在触发行动算子之后,才会进行缓存
package com.qf.spark.wc.day06.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object _02TestCache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val context: SparkContext = new SparkContext(conf)
var lines: RDD[String] = context.textFile("D:/input/words.txt")
var words: RDD[String] = lines.flatMap((line) => {
println("------------------")
line.split(" ")
})
var wordAndOne: RDD[(String, Int)] = words.map((_, 1))
/**
* cache: 底层调用的使persist,实际上存储到内存中
*
* 注意:
*
* 1. cache不算转换算子,因为返回的this.type 而不是新的RDD
* 2. 官方建议cache方法,直接在获取算子后调用
* 3. 如果整个application结束,内存会立即释放
*/
//wordAndOne.cache()
/**
* persist: 单词是持久化的意思,目的应该是要存在磁盘上,
* 因此调用无参形式的方法是与意向违背,因为无参表示存储到内存中
*
* 因此需要设置存储级别:
* StorageLevel.MEMORY_ONLY:
* 数据只保存到内存中,特点:如果内存存不下,则存不下的那些数据丢弃
* StorageLevel.MEMORY_AND_DISK:
* 内存和磁盘都使用,先使用内存,内存不够情况下,再使用磁盘
* StorageLevel.DISK_ONLY
* StorageLevel.DISK_ONLY_2:
* 存磁盘,副本2个
* StorageLevel.MEMORY_ONLY_SER:
* 内存并序列化
*
*
* 注意:
* 1. 使用持久化机制时,也使产生临时文件,
* 当application执行完后,要立即删除的。
* 2. 不算转换算子,因为返回的this.type 而不是新的RDD
*/
wordAndOne.persist(StorageLevel.DISK_ONLY)
var value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
var result: Array[(String, Int)] = value.collect()
//利用value再产生一个job,该job不会从头读取数据,直接利用临时文件
// value.foreach(println)
result.foreach(println)
println("--------------另起一个job 进行对单词分组----------------")
//该job会从头读取数据
wordAndOne.groupByKey().collect().foreach(println)
context.stop()
}
}
3)checkpoint机制
package com.qf.spark.wc.day06.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object _03TestCheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val context: SparkContext = new SparkContext(conf)
context.setCheckpointDir("checkpoint")
var lines: RDD[String] = context.textFile("D:/input/words.txt")
var words: RDD[String] = lines.flatMap((line) => {
println("------------------")
line.split(" ")
})
var wordAndOne: RDD[(String, Int)] = words.map((_, 1))
/**
* 使用spark的检查点机制,用来持久存储数据
*
* 注意:
* 1. 需要自定义存储位置 sc.setCheckpointDir(path:String)
* 2. 如果想要其他job从持久化文件中读取数据,需要配合cache方法
*/
wordAndOne.cache()
wordAndOne.checkpoint()
var value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
var result: Array[(String, Int)] = value.collect()
//利用value再产生一个job,该job不会从头读取数据,直接利用临时文件
// value.foreach(println)
result.foreach(println)
println("--------------另起一个job 进行对单词分组----------------")
//该job会从头读取数据
wordAndOne.groupByKey().collect().foreach(println)
context.stop()
}
}
4)三者的区别
package com.qf.spark.wc.day06.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object _04TestCacheAndPersistAndCheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val context: SparkContext = new SparkContext(conf)
context.setCheckpointDir("checkpoint")
var lines: RDD[String] = context.textFile("D:/input/words.txt")
var words: RDD[String] = lines.flatMap((line) => {
println("------------------")
line.split(" ")
})
var wordAndOne: RDD[(String, Int)] = words.map((_, 1))
/**
* 1. cache只保存到内存,程序结束,立即释放
* persist进行持久化,产生的是临时文件,程序结束会立即释放
* checkpoint的目录是持久化保存
*
* 2. cache后,会在血缘关系中间,添加一个缓存依赖关系
* 优点:
* --下游的rdd如果计算异常,则可以通过血缘关系追踪到cache,
* 可以直接读取cache的数据
* -- 如果追踪到cache,发现没有数据,就可以继续向上追踪,
*
* 设想一下,应用了缓存,在血缘关系中不保存cache依赖,则根本不会使用cache
*
* 3. checkpoint机制后,会切断原有的血缘关系,然后重建血缘关系。
*
* 为什么:因为可以直接从持久化文件开始读取。
*/
//wordAndOne.cache()
//wordAndOne.persist(StorageLevel.DISK_ONLY)
wordAndOne.checkpoint()
var value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
//打印血缘关系
println(value.toDebugString)
var result: Array[(String, Int)] = value.collect()
//利用value再产生一个job,该job不会从头读取数据,直接利用临时文件
// value.foreach(println)
result.foreach(println)
println("--------------另起一个job 进行对单词分组----------------")
//该job会从头读取数据
var rdd5 = wordAndOne.groupByKey()
println(rdd5.toDebugString)
rdd5.collect().foreach(println)
context.stop()
}
}
4.4 累加器的编程
4.4.1 案例演示:
需求: 计算所有元素的和
package com.qf.sparkcore.day05
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_01_accumulator_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
var rdd1:RDD[Int] = sc.makeRDD(Array(1,2,3,4,5),2)
/**
* 需求: 定义一个变量,用于存储RDD中的所有元素的和。
*/
var sum = 0;
rdd1.foreach(elem=>{
sum += elem
})
/**
* 为什么sum的值 是0,而不是15. 原因是 foreach这个行动算子是在executor端执行的,计算的数据3和12并不会
* 返回到Driver,因此Driver的输出语句打印的一定是Driver处的值。也就是0
*
*
* 如何解决上述问题? 有两种方式:
*
* 1. 使用collect算子 将executer端的数据搜集到Driver,然后再计算
* 2. 使用累加器
*/
println("sum的值:"+sum)
// collect算子
rdd1.collect().foreach(x=>{
sum+=x
})
println("使用collect算子后的sum的值:"+sum)
sc.stop()
}
}
4.4.2 介绍
通常算子在计算时,不会影响到Driver里的变量,原因是算子使用的其实都是Driver里的变量的一个副本,如果想要影响Driver里的变量,需要搜集数据到Driver端才行
而除了搜集之外,也可以在Driver端使用Spark提供的累加器,累加器是Spark的两个共享变量之一,另一个共享变量是广播变量
注意事项
1. 多加情况,原因是如果累加器在executor处用的地方比较多,那么每次用完都要返回到Driver端
因此可能会出现多加的情况
4.4.3 自定义累加器
package com.qf.sparkcore.day05
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* 需求: 自定义一个累加器,用于计算单词的频率统计
*/
object Spark_03_accumulator_3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
var rdd1:RDD[String] = sc.textFile("input/words.txt")
// words对应的RDD存储的都是单词
val words: RDD[String] = rdd1.flatMap(_.split(" "))
// 第一步:获取自定义的累加器对象
val wordcount = new MyAccumulator()
// 第二步: 注册累加器
sc.register(wordcount)
words.foreach(word=>{
wordcount.add(word)
})
//获取累加器的值
var map = wordcount.value
map.foreach(println)
sc.stop()
}
}
/**
* 模拟 LongAccumulator的写法。注意泛型AccumulatorV2[IN,OUT]
* IN:表示要统计的内容, 单词的话 应该String
* OUT:返回的结果 Map
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Int]]{
//需要自定义一个属性,用来存储每个单词的数量
var map =mutable.Map[String,Int]()
/**
* 判断是否为初始化状态
* @return
*/
override def isZero: Boolean = {
map.size ==0
}
/**
* 创建副本
* @return
*/
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {
new MyAccumulator
}
/**
* 重置, 恢复到最初的状态
*/
override def reset(): Unit = {
map.clear()
}
/**
* 向map属性添加一个单词,进行统计,如果这个单词存在过,就将value取出来+1,否则直接设置为1
* @param v
*/
override def add(v: String): Unit = {
map.put(v,map.getOrElse(v,0)+1)
}
/**
* 两个累加器和平, this 和 other
* @param other
*/
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
//取出other的map属性, 和this的map合并
val map1 = other.value
map1.foreach(x=>{
x match {
case (k,v) => this.map.update(k,v+map.getOrElse(k,0))
}
})
}
/**
* 返回累加器的值
* @return
*/
override def value: mutable.Map[String, Int] = map
}
4.5 广播变量的应用
package com.qf.sparkcore.day05
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Spark_04_broadCast_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
//定义一个10M左右的集合对象,用于存储敏感词语
val list = List("a","b","c","hello","world")
// 即将集合对象,设置成广播变量。
val b1 = sc.broadcast(list)
//读取文件或者是日志中的所有评论信息
var rdd1 = sc.makeRDD(List("hello","world","spark","java"))
//需求:排除集合中的敏感词
val rdd2: RDD[String] = rdd1.filter(word => {
//!list.contains(word)
//在使用的使用,不能直接使用集合,而是使用广播变量
!b1.value.contains(word)
})
/**
* 问题出现了: 算子中用到了Driver中定义的10M的集合对象。 那么一定会涉及到该集合对象传输到executor上运行
* 如果Task的数量是1024个。 那么每一个Task都要使用10M的数据。 最终传入的数据量大小在10M*1024. 也就是10G的数量
*
* 这严重影响了传输过程中的性能,以及内存开销。
*
* 解决办法:
* 使用广播变量(两个共享变量之一,另一个是累加器)。 广播变量的作用就是一个executer上只有一份,该executor上的所有的Task
* 共用这一个广播变量。
* 而多个Task同时使用一个广播变量,很容易造成被修改,所以,广播变量被设置成了一个只读的变量
*/
rdd2.collect().foreach(println)
sc.stop()
}
}
4.6 Spark的shuffle
4.6.1 介绍
1. shuffle概念: 上游RDD的一个分区的数据被打散重组到下游RDD的不同分区。
2. 性能问题: 参考图片
3. shuffle 分为两个阶段
-- shuffle write
-- shuffle read
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJu4kXaH-1648306731552)(ClassNotes.assets/image-20220121115543461.png)]
4.6.2 shuffle的演变![在这里插入图片描述]
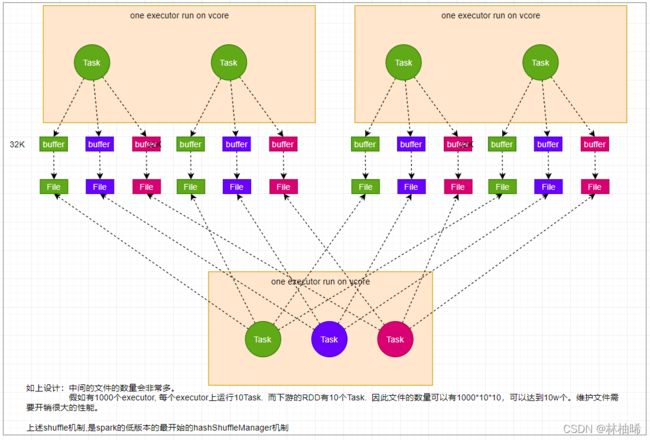
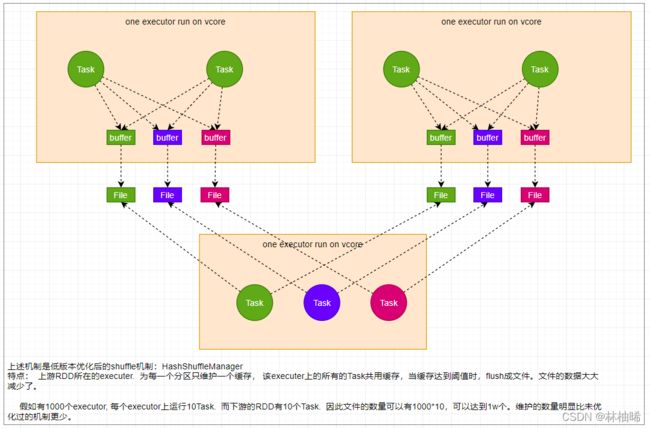
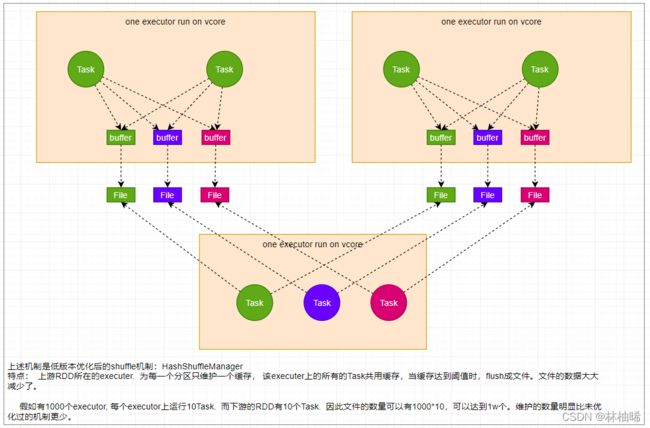

4.6.3 分区器的介绍
1)说明
1. 分区器一般都是作用在PairRDD对应的算子里,因为会涉及到shuffle,也就是需要重新分区。
2. spark提供的默认分区器:
-- HashPartitioner: spark源码中90%的地方使用的都是该分区器
-- RangePartitionner: spark源码中10%的地方使用的都是该分区器
-- PythonPartitioner
HashPartitioner的源码
//父类:
abstract class Partitioner extends Serializable {
def numPartitions: Int //获取分区数量
def getPartition(key: Any): Int //计算key属于哪一个分区号
}
// 主构造器:用来指定重新分区的数量
class HashPartitioner(partitions: Int) extends Partitioner {
def numPartitions: Int = partitions // 重写方法,获取分区数量
def getPartition(key: Any): Int = key match { //重写方法,计算key属于哪一个分区号
case null => 0 // 将null值设置到0分区中
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
// 计算Key对应的分区号 x是key的hash值,mod是分区数量
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod // hash对分区数量取模
rawMod + (if (rawMod < 0) mod else 0) // 获取结果的绝对值作为分区号
}
注意一个问题: 不同对象的hash值有可能碰撞(相同)
4.6.4 自定义分区
package com.qf.sparkcore.day05
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
/**
* 单词统计,并自定义分区器,按照首字符分区
* [a-nA-N]在0分区
* [o-zO-Z]在1分区
* 其他字符开头的在2分区
*/
object Spark_06_CustomPartitioner_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.makeRDD(List("hello world", "hello kitty",
"hello spark", "spark and flink", "redis", "kafka","1999"))
//调用HashParitioner重新分区
rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(new MyPartitioner,_+_).saveAsTextFile("mypartitioner")
sc.stop()
}
class MyPartitioner extends Partitioner{
override def numPartitions: Int = 3
override def getPartition(key: Any): Int = {
var word:String = null
if(key.isInstanceOf[String]){
word = key.asInstanceOf[String]
}else{
throw new Exception()
}
var first = word.charAt(0)+""
if(first.matches("[a-nA-N]")){
0
}else if(first.matches("[o-zO-Z]")){
1
}else{
2
}
}
}
}
Task都要使用10M的数据。 最终传入的数据量大小在10M*1024. 也就是10G的数量
*
* 这严重影响了传输过程中的性能,以及内存开销。
*
* 解决办法:
* 使用广播变量(两个共享变量之一,另一个是累加器)。 广播变量的作用就是一个executer上只有一份,该executor上的所有的Task
* 共用这一个广播变量。
* 而多个Task同时使用一个广播变量,很容易造成被修改,所以,广播变量被设置成了一个只读的变量
*/
rdd2.collect().foreach(println)
sc.stop()
}
}
## 4.6 Spark的shuffle
### 4.6.1 介绍
- shuffle概念: 上游RDD的一个分区的数据被打散重组到下游RDD的不同分区。
- 性能问题: 参考图片
- shuffle 分为两个阶段
– shuffle write
– shuffle read
[外链图片转存中...(img-eJu4kXaH-1648306731552)]
### 4.6.2 shuffle的演变过程
[外链图片转存中...(img-LwE94BJs-1648306731552)]
[外链图片转存中...(img-UfL8D9RA-1648306731553)]
[外链图片转存中...(img-VZHOl0k6-1648306731553)]
### 4.6.3 分区器的介绍
1)说明
- 分区器一般都是作用在PairRDD对应的算子里,因为会涉及到shuffle,也就是需要重新分区。
- spark提供的默认分区器:
– HashPartitioner: spark源码中90%的地方使用的都是该分区器
– RangePartitionner: spark源码中10%的地方使用的都是该分区器
– PythonPartitioner
HashPartitioner的源码
```scala
//父类:
abstract class Partitioner extends Serializable {
def numPartitions: Int //获取分区数量
def getPartition(key: Any): Int //计算key属于哪一个分区号
}
// 主构造器:用来指定重新分区的数量
class HashPartitioner(partitions: Int) extends Partitioner {
def numPartitions: Int = partitions // 重写方法,获取分区数量
def getPartition(key: Any): Int = key match { //重写方法,计算key属于哪一个分区号
case null => 0 // 将null值设置到0分区中
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
// 计算Key对应的分区号 x是key的hash值,mod是分区数量
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod // hash对分区数量取模
rawMod + (if (rawMod < 0) mod else 0) // 获取结果的绝对值作为分区号
}
注意一个问题: 不同对象的hash值有可能碰撞(相同)
4.6.4 自定义分区
package com.qf.sparkcore.day05
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
/**
* 单词统计,并自定义分区器,按照首字符分区
* [a-nA-N]在0分区
* [o-zO-Z]在1分区
* 其他字符开头的在2分区
*/
object Spark_06_CustomPartitioner_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.makeRDD(List("hello world", "hello kitty",
"hello spark", "spark and flink", "redis", "kafka","1999"))
//调用HashParitioner重新分区
rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(new MyPartitioner,_+_).saveAsTextFile("mypartitioner")
sc.stop()
}
class MyPartitioner extends Partitioner{
override def numPartitions: Int = 3
override def getPartition(key: Any): Int = {
var word:String = null
if(key.isInstanceOf[String]){
word = key.asInstanceOf[String]
}else{
throw new Exception()
}
var first = word.charAt(0)+""
if(first.matches("[a-nA-N]")){
0
}else if(first.matches("[o-zO-Z]")){
1
}else{
2
}
}
}
}