1.并发编程的本质问题
多线程是一个比较头疼的问题,编写正确的并发程序是很有挑战的,而出现问题之后的定位也是非常困难的,更郁闷的是这些故障往往难以复现,因此必须对其实现原理有非常深刻的理解,这样遇到问题之后才能更好的应对。
本部分将深入分析Java多线程的核心基础问题,本章我们会大量研究JDK的核心设计,并且阅读大量的源代码,逐步梳理出整个并发系统的核心逻辑。
并发编程是比较难的,而且很多核心设计在平时的工作中不会遇到,这又增加了学习的难度。一种可行的方法是每个知识点我们都思考:这个技术是干什么的?要解决什么问题?如何解决的?最后是代码是如何实现的?最后将各个知识连接起来才会豁然开朗。
1.1 并发编程面临的挑战
我们知道并发编程能够提高处理的效率,那为什么会提高效率呢?我们知道多核CPU已经是主流,那既然如此,操作系统又需要做什么才能让多核发挥出最大性能呢?既然操作系统支持多线程,那JVM和用户程序又需要干什么呢?这些问题需要我们先做一个界定,这样后面再学习会更加清晰。
公认的第一台计算机是1945年诞生在美国的冯.诺依曼计算,并且提出了冯诺依曼体系。在这个体系中计算机大致包含运算器、控制器、存储器、输入设备和输出设备几个核心部分。虽然计算机一直在发展,但是这个体系一直沿用至今。运算器主要负责各种运算操作,典型的有DSP和GPU;控制器主要是CPU,主要用于控制指令的执行,是计算机的大脑;存储器自然是用来存储信息的,主要包括指令、程序和数据等。输入输出设备,自吗然是为了与外部世界交互的。
在这个过程中,冯诺依曼体系貌似应该以CPU为中心,但实际上是以存储器为中心的,如下图:
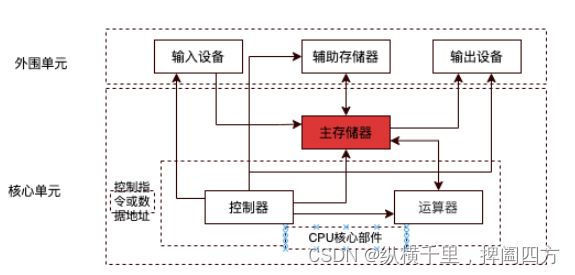
为什么以存储器为中心呢?因为CPU要能针对所有情况进行控制,因此响应速度必须要快,传输的数据要尽量少,而存储器要处理的数据量可能会非常大。这就带来了一个问题,存储器的速度跟不上控制器的,另外大部分设备执行时都要读入和读出数据,因此就会出现很多设备都在等存储器的情况。因此将存储器作为各个部件的中心,各个设备都与其相连,可以大大加快处理速度。可以想象一下,军队打仗的时候,司令官下达命令“全军收拾装备,午夜出发”后,就散会了,而所有人都会立马冲出去领武器、弹药、食品、药品等物资,因此后勤部装备部的人可能更忙。
CPU处理速度比较快,要处理的任务多,但是每个任务都比较轻。各个子任务谁完成了,谁就向CPU汇报“...任务已完成,请指示”,然后司令继续下达新命令。
那如果任务非常多,导致CPU仅仅处理指令都完成,怎么办呢?最简单的方式是再找一个司令来,一起分担,例如很大大型战役都是多个指挥官共同参与,一人指挥一方面的战斗。不过,此时该如何协同呢?例如:两个司令如何分工?部队之间如何协同?如何防止一个部队同时收到两个不一样的指令?这里也是多线程要解决的三个核心问题:分工问题、同步问题和互斥问题。
1.分工问题
分工合理,则各个部门之间能齐头并进开展工作,如果分工不合理则会导致工作混乱、效率低下、相互扯皮。因此合理的设计分工模型,将一个大任务细分为粒度更小的子任务,然后由多个线程分别完成,会大大加速任务的处理效率,而且在这个过程中,一定要注意将任务分给合适的线程去做。
在Java中,线程池、Fork/Join框架、Future接口都是实现分工的工具。而在多线程设计模式中,Guarded Suspension模式、Thread-per-Message模式、生产消费者模式、两阶段终止、Worker-Thread模式和Balking模式都是分工问题的实现方式。
2.同步问题
线程同步和线程通信基本是一回事,当一个任务完成之后,该如何通知其他线程继续执行任务,或者进行其他方式的协作,也是多线程要解决的问题。例如两个司令A和B,A手下有两个炮兵营,B一个都没有,假如B方敌方需要A帮忙火力支援,此时该如何让A配合呢?如果A要支援,也需要A先告知要打击的准确位置,不能乱打。打完之后,B不仅要停止炮击,也要告知A部队开始其他行动。这就是同步问题。
在多线程中,多个线程之间是有任务依赖关系的,可能是资源依赖,也可能是时间有要求,例如线程A需要等待线程B完成某项工作再进行,C则要在A和B之前完成等等。其中最经典的例子就是wait/notify组合、await/signal、condition,以及生产者/消费者模型都是针对该问题。
3.互斥问题
互斥问题也是非常重要的,假如一个分队进攻时收到两个司令不一样的命令,自然就要出现问题了。在计算中,互斥问题主要是在同一时刻只允许一个线程访问临界区的共享资源。互斥强调的是多个线程执行任务时的正确性。如果多个线程同时进入临界区抢夺资源就会出现问题,该问题也称为线性安全问题。
在Java中,最直接的是使用synchronized加锁,除此之外还有ThreadLocal、CAS、原子类和CopyOnWrite开发的并发容器类、Lock锁等等都是为了实现类的互斥机制。
在这三个问题中,分工问题相对简单。我们后面的内容主要以同步问题和互斥问题为主。
1.2 互斥失效的三个原因
在上面介绍的分工、同步和互斥三个问题中,导致互斥的原因,是由线程的原子性、可见性和有序性三个,这三个特性是什么意思呢?又是如何解决的呢?这里我们先解释其含义,而如何解决的,解决方案有很多,不同方案如何解决的将贯穿本课程全部章节。
1.2.1 原子性
原子性是一个或者多个操作在CPU中执行的过程是一个不可分割的整体,要么全部执行,要么不执行,而不能出现执行过程中中断的情况。
最典型的例子是银行转账,假如一个公司里两个人可以同时处理一个账户,A存入1000元,1min后又存了一千元,此时A检查账户应该有2000元。但是假如在A存入1000元后,B立马从中转走了500,这样A后面查的时候发现只有1500元,这就导致A发现账户对不上。为了解决该问题,最简单的方式是A存钱的时候,账户暂时锁定,不允许转账,直到A存完、退出才可以。这样假如A存钱期间B想转账,发现账户不可用,就会等待一段时间再看,从而保证整个过程是安全的。
而在计算机中,导致原子问题产生的根源是线程切换。如果线程在执行某项操作过程中,发生了线程切换,CPU去处理其他任务了,当再回来执行时,可能要处理的数据已经和之前不一样了,这就是原子性问题。
看个例子:
public class AtomicityTest {
private int count = 0;
public void incrementCount() {
count++;
}
}这里的incrementCount()方法只是将变量count进行了加1操作,那计算机是如何执行的呢?我们将其编译一下,然后使用命令看一下
javap -v AtomicityTest.class
此时输出的内容比较多,相关内容 ,我们在JVM课程中详细介绍过,这里我们看incrementCount()方法对应的内容:
public void incrementCount();
0: aload_0
1: dup
2: getfield #2 // Field count:I
5: iconst_1
6: iadd
7: putfield #2 // Field count:I
10: return上述incrementCount()方法的指令码大致包含三个步骤:
-
第一步:将变量count从内存中加载到CPU的寄存器中。
-
第二步:在CPU的寄存器中执行count++操作。
-
第三步:将count++后的结果写入到缓存。
很明显上面的过程只对应了我们一条语句 count++;,这本应该一次执行完成的。假设线程A和B同时执行incrementCount(),在线程A执行过程中,CPU完成指令码的步骤(1)之后发生了线程切换,此时线程B也开始执行步骤(1)了。当两个线程都完成incrementCount()方法之后,得到的count值就是2而不是1,切换过程如下图:
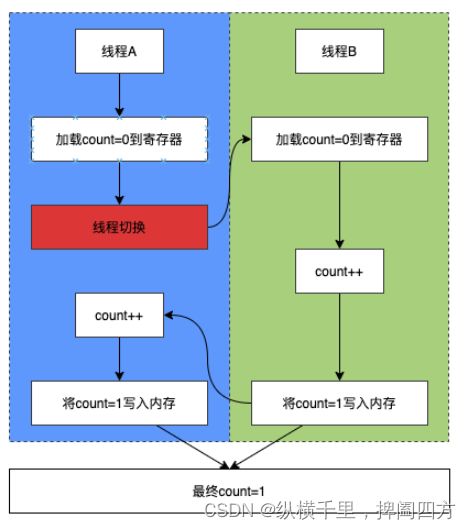
在这个图中,线程A将count=0加载到CPU的寄存器之后,发生了线程切换。此时由于还没执行count++操作,也没有将结果写到内存,所以count的值仍然是0,之后线程B将count++变成1,最后A再次执行count++,此时A得到的结果就是count=2。
为了提高CPU的处理效率而引入了时间片轮转、线程切换等机制,但是这直接导致很多操作无法保证原子性,进而带来多线程不安全。
1.2.2 可见性
可见性是线程修改了共享变量,其他线程应该能立刻读取到共享变量最新的值。如果不能及时获取会导致当前线程处理的数据是老的或者无效的,进而产生问题。
那为什么会出现无效数据呢?这个问题在单线程环境下几乎不存在的,而只在多核环境下非常明显,原因是在多核处理器中,每个CPU都有自己的缓存。这样多个线程就可能执行在不同的CPU上,对共享变量的读写就发生在不同的CPU核心上。这样,一个线程对共享变量进行了写操作,另一个线程就不能立刻感知到,因此就产生了可见性问题。这就好比,你在自己的电脑上写了代码,但是没有提交的话,其他人就不知道你改了什么。
例如在下面例子中,双核CPU的核心分别是CPU-1和CPU-2,线程1运行在CPU1上,线程2运行在CPU2上,两个CPU各有一个缓存,线程1和2同时读写主内存中的共享变量X,如下所示:

线程1和线程2运行在不同的CPU的核心上,当线程1和线程2同时读写到主内存的共享变量X时,并不是直接修改主内存中共享变量X的值,而是各自先将共享的变量X复制到对应的CPU中。而线程1和2都只能感知各自对应CPU内核的和主内存的,而无法感知对方的,因此就产生了可见性问题。
我们可以看到导致可见性的根本原因是多个CPU核都有各自的缓存,也就是有各自的工作内存。假如各个线程也有自己的缓存,自然单核多线程环境下也会存在可见性问题,这就是Java中Volatile关键字的作用。
1.2.3 有序性
在并发编程中,有序性指程序能够按照编写的代码应该顺序执行,不会发生跳过代码执行的情况,也不会发生跳过CPU指令的情况。
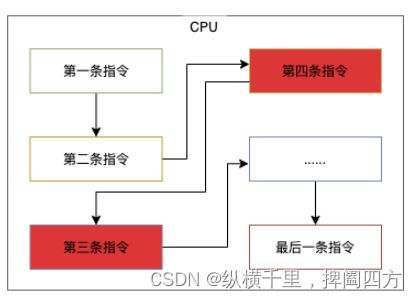
为了提高程序的执行性能和编译性能,计算机和编译器有时候会修改程序的执行顺序。在单线程场景下,编译器能保证修改执行顺序后的结果与程序顺序执行的结果一致。但是在多线程场景下,编译器对执行顺序的修改可能造成意想不到的后果。如果编译器修改了程序的执行顺序,则CPU在执行程序时,可能先执行第一条指令,再执行第二条指令,然后执行第四条,最后再执行第三条,如下图所示,此时就会在并发编程中的有序性问题。
1.2.4 小结
本小节我们分析了导致互斥问题的三个原因:原子性、可见性和有序性,这些问题在单线程环境下几乎不存在,但是在多线程环境下必须解决,否则将无法使用多核环境。不同的角度,不同的工具给出了解决这三个问题的不同方案,该问题也将贯穿我们整个课程。
1.3 多线程一定快吗
我们知道使用多线程是为了快,那开线程越多就越快吗?看个例子:
public class ConcurrencyTest {
// 执行次数
private static final long count = 1000l;
public static void main(String[] args) throws InterruptedException {
//并发执行
concurrency();
//串行执行
serial();
}
//并发执行
private static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
System.out.println(a);
}
});
thread.start();
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
thread.join();
long time = System.currentTimeMillis() - start;
System.out.println("concurrency :" + time + "ms,b=" + b);
}
//串行计算
private static void serial() {
long start = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long time = System.currentTimeMillis() - start;
System.out.println("serial:" + time + "ms,b=" + b + ",a=" + a);
}
}这个代码有两个方法,就是计算累加和累减,但是一个是并行计算的一个是串行计算的,count代表执行的次数。我们不断增加count的值会发现一个很有趣的现象,当count比较小的时候串行耗费时间更少,之后会逐渐持平,然后count比较大的时候并行耗时会更小。
因此,任务数量比较少的时候不一定非要使用串行。
为什么任务数量少的时候串行反而更快呢?这是因为线程有创建和上下文切换的开销。
那具体有哪些开销呢?主要有以下几种:
-
1.读个任务抢占synchronized同步锁资源。
-
2.在线程在IO阻塞,这会影响处理时间。
-
3.线程在阻塞和恢复之间换时,CPU调度会切换时间片。
从不同的角度和场景分析,具体切换的内容也是不一样的,例如进程上下文切换、线程上下文切换和中断上下文切换等等情况。读者可以想象一下,你正在吃饭,孩子要你将桌子收拾好要画画, 画完之后又要将桌子恢复到饭桌的样子,是否是比较耽误时间?假如一小时让你换10次呢?
既然频繁切换影响性能,那该如何做来减少呢?常见的方式有如下几种:
-
1.减少线程数,同一时刻能够运行的线程数是由CPU核数决定的,创建过多的线程,自然会造成CPU频繁切换时间片。
-
2.采用无锁设计来解决竞争问题,比如再同步锁场景中,如果存在多线程竞争,那么没抢到锁的线程会阻塞,这个过程涉及用户态和核心态的转换,这个转换的代价是非常高的。因此采用无锁涉及减少切换也是提高性能的重要方式。
-
3采用自旋等待的方式,线程执行时如果得不到资源,在一定时间内重试几次就有可能获得资源,因此第一次得不到,可以重试几次,这样也可以避免用户态和核心态的切换。
在上面几种方式中,加锁主要是synchronized和重入锁两种机制,这种“宁可错杀,不可放过”的方式,也叫“悲观锁”。而除此之外还有大量无锁设计,除了自旋等待,还有volatile以及JUC的众多工具,这种“先干,有问题再说”的方式也叫“乐观锁”。
事实上synchronized经过优化之后,有“偏向锁”、“轻量级锁”和“重量级锁”三个阶段,其中前两者也属于乐观锁。因此乐观锁和悲观锁更多是一种思想,不能一概而论。在我们后面章节里会详细介绍相关内容。
1.4 操作系统的进程和线程
本节介绍一些常见概念,几个进程和线程相关的概念以及Java线程与操作系统线程之间的关系等。
1.4.1 进程与线程的关系
首先是线程和进程的关系,一般的说法是”在有进程和线程的系统中,进程是系统资源分配的独立单位,而线程是可调度运行的独立单位,线程比进程更加轻量。这个概念还是让很多人感觉不好理解,两者关系到底如何呢?我们可以只考虑在Java中的场景 ,当我们启动一个Java程序的时候,就会启动一个JVM虚拟机,而这个虚拟机相对于操作系统来说就是一个进程,我们可以通过jps命令来查看。而我们的Java程序里可能会启动很多具体的,例如管理tomcat、DB连接、网络监听等等,这些都是线程。
1.4.2 操作系统的线程
无论使用什么语言写的多线程程序,最后都是通过调用操作系统的线程来执行任务的,线程是CPU调度的最小单位,在操作系统层面,又可以分为用户级、内核级和混合级三种线程。理解其功能和含义有助于后面理解高并发场景下的性能优化问题。
用户级线程是用户在操作系统的用户空间中创建的,不依赖操作系统内核,因此操作系统也感知不到用户级线程的存在,线程运行期间也不会有用户态和内核态之间切换的问题。CPU的时间片是以进程为单位分配的,而每个进程会维护一个线程表来管理自己的线程,可以理解为线程是被进程控制的,而进程又被操作系统控制的。
内核级线程是操作系统内核创建和管理的线程,此时操作系统会同时维护线程表和进程表来管理其状态。
用户级和内核级的关系如下:
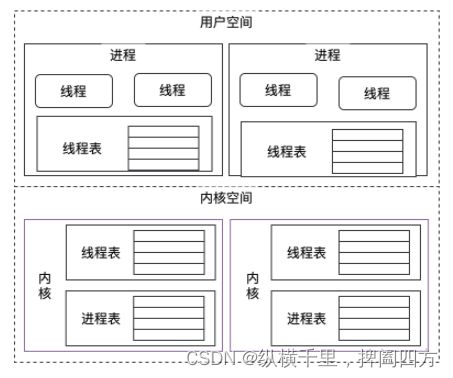
用户级线程和内核级线程之间的区别有很多,我们介绍几条比较重要的:
-
1.最重要的区别就是内核级是操作系统内核管理和维护的,如果出现问题可能导致整个系统崩溃,因此更为重要。而用户态是用户程序管理的,即使崩溃,最多导致用户程序不可用。
-
2.在用户级线程中,一个线程阻塞可以导致整个进程阻塞,但是在内核态会调用进程中的其他线程而不会出现这种情况。
-
3.内核级线程创建和管理由操作系统内核来完成,与用户线程相比,这些操作是比较慢的。
另外还有一种方式叫”混合级线程“,顾名思义就是混用了用户态和内核态的特征。具体来说就是在用户空间创建和管理用户级线程,在内核空间中创建和管理内核级线程。在这种场景下,操作系统内核只感应内核创建的线程,而用户级线程是基于内核线程来执行的,可以简单理解为内核线程兼顾了进程的部分角色来管理用户级线程。
1.4.3 Java线程和操作系统线程的关系
Java语言创建的线程与操作系统的线程是一一对应的。使用Thread类创建线程时,并不会真正创建线程。此时JVM会将其进一步处理并创建一个操作系统线程。同样,线程如果要执行,也不是JVM决定的,而是CPU执行了操作系统线程,然后将状态通过JVM再返回给用户,也就是说JVM只是一个中间商的角色,该问题在后面分析启动线程为什么用start()时还会进一步分析。

1.5 小结
本章主要介绍了多线程与高并发相关的概念、原理、常见问题和核心设计等方面的问题,理解这些内容有助于我们后面逐步建立起完整的多线程技术体系。
本章设计的内容,我们会在后面逐步展开,请读者后面学习每个技术点都要思考:这个技术是干什么的,是为了解决什么问题,是如何解决的,有什么优点或不足等等,只有不断思考这些问题,我们才能逐步透彻理解多线程和高并发。