优达学城《DeepLearning》2-1:卷积神经网络
本次由3部分组成:
- 可视化卷积神经网络。
- 设计和训练一个CNN来对MNIST手写数字分类。
- 设计并训练一个CNN来对CIFAR10数据集中的图像进行分类。
本次遇到的深度学习核心概念:
- SGD优化器:GD就是梯度下降(Gradient Descent),SGD就是随机梯度下降。SGD相对于GD优势在于:①不用计算全部图片输入网络的梯度,而用小批量图来更新一次网络,极大提升训练速度。②“歪歪扭扭”地走,天生容易跳出局部最优点,最终训练的精度往往比GD高的多。
-
Sobel 算子:是一个离散微分算子, 结合了高斯平滑和微分求导,主要用来计算图像中某一点在
横向/纵向上的近似梯度,如果梯度值大于某一个阈值,则认为该点为边缘点(像素值发生显著变化的地方)。-
图像近似梯度计算如下:
-

-
所以,sobel x和sobel y参数一般如下:
-

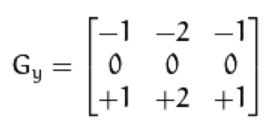
-
-
交叉熵损失:
-
二分类的交叉熵损失公式:
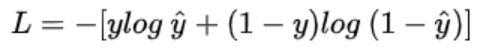 (y为标签,y^为预测为正样本的概率)
(y为标签,y^为预测为正样本的概率) -
训练过程中代价函数是对m个样本的损失函数求和然后除以m:

-
多分类交叉熵损失:

- K是种类数量
- y是标签,也就是如果类别是 i,则 yi =1,否则等于0
- p是神经网络的输出,也就是指类别是 i 的概率。这个输出值就是用 softmax 计算得来的。
-
目录
1 可视化卷积神经网络
1.1 自定义滤波器
1.2 可视化卷积层
1.3 可视化池化层
1.3.1 Import the image
1.3.2 Define and visualize the filters
1.3.3 Define convolutional and pooling layers
1.3.4 Visualize the output of each filter
1.3.5 Visualize the output of the pooling layer
2 设计和训练一个CNN对MNIST手写数字分类
2.1 加载并可视化数据
2.1.1 可视化训练集中一个batch图像集
2.1.2 观察单个图像更详细的信息
2.2 定义网络结构
2.3 指定损失函数和优化器
2.4 训练网络
2.5 测试训练好的网络
2.6 可视化test集预测结果
3 设计并训练一个CNN来对CIFAR10数据集中的图像进行分类
3.1 CUDA测试
3.2 加载数据
3.3 可视化一批训练数据
3.4 更详细地查看图像
3.5 定义网络结构
3.6 指定损失函数和优化器
3.7 训练网络
3.8 加载模型
3.9 测试训练好的模型
3.10 问题:你的模型有哪些缺点,如何改进?
3.11 可视化test集预测结果
1 可视化卷积神经网络
1.1 自定义滤波器
导入资源并显示图像:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import cv2
import numpy as np
%matplotlib inline
# Read in the image
image = mpimg.imread('data/curved_lane.jpg')
plt.imshow(image)
将图像转换为灰度图:
# Convert to grayscale for filtering
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
plt.imshow(gray, cmap='gray')
TODO:创建自定义内核
下面,我们为您提供了一种常见的边缘检测过滤器:Sobel操作符。
Sobel滤波器常用于边缘检测和图像强度模式的提取。对图像应用Sobel滤波器是一种分别获取图像在x或y方向上的导数(近似值)的方法。运算符如下所示。
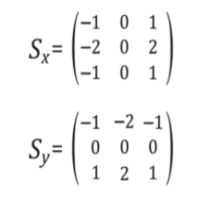
由您创建一个sobel x操作符并将其应用于给定的图像。
作为一个挑战,看看你是否可以对图像完成如下一系列滤波操作:模糊图像(采取平均像素),然后一个检测边缘。
# Create a custom kernel
# 3x3 array for edge detection
sobel_y = np.array([[ -1, -2, -1],
[ 0, 0, 0],
[ 1, 2, 1]])
## TODO: Create and apply a Sobel x operator
sobel_x = np.array([[ -1, 0, 1],
[ -2, 0, 2],
[ -1, 0, 1]])
# Filter the image using filter2D, which has inputs: (grayscale image, bit-depth, kernel)
filtered_image_x = cv2.filter2D(gray, -1, sobel_x)
filtered_image_y = cv2.filter2D(gray, -1, sobel_y)
plt.figure(figsize=(14,14))#设置图像尺寸(画面大小其实是 1400 * 1400)
#要生成两行两列,这是第一个图plt.subplot('行','列','编号')
plt.subplot(1,2,1)
plt.title('sobel x')
plt.imshow(filtered_image_x, cmap='gray')
plt.subplot(1,2,2)
plt.title('sobel y')
plt.imshow(filtered_image_y, cmap='gray')
plt.show()结果:

测试其他过滤器!
我们鼓励您创建其他类型的过滤器并应用它们来查看发生了什么!作为可选练习,请尝试以下操作:
- 创建具有小数值参数的过滤器。
- 创建5x5过滤器
- 将过滤器应用于images目录中的其他图像。
image = mpimg.imread('data/bridge_trees_example.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
sobel_y = np.array([[ -1, -2, -1],
[ 0, 0, 0],
[ 1, 2, 1]])
sobel_y_2 = np.array([[ -1.5, -2.5, -1.5],
[ 0, 0, 0],
[ 1.5, 2.5, 1.5]])
sobel_x = np.array([[ -1, 0, 1],
[ -2, 0, 2],
[ -1, 0, 1]])
sobel_x_5x5 = np.array([[ -1, 0, 0, 0, 1],
[ -1, 0, 0, 0, 1],
[ -2, 0, 0, 0, 2],
[ -1, 0, 0, 0, 1],
[ -1, 0, 0, 0, 1]])
# Filter the image using filter2D, which has inputs: (grayscale image, bit-depth, kernel)
filtered_image_y = cv2.filter2D(gray, -1, sobel_y)
filtered_image_y_2 = cv2.filter2D(gray, -1, sobel_y_2)
filtered_image_x = cv2.filter2D(gray, -1, sobel_x)
filtered_image_x_5x5 = cv2.filter2D(gray, -1, sobel_x_5x5)
plt.figure(figsize=(14, 14))#设置图像尺寸(画面大小其实是 1200 * 1200)
plt.subplot(3,2,1)
plt.title('image')
plt.imshow(image)
plt.subplot(3,2,2)
plt.title('gray')
plt.imshow(gray, cmap='gray')
plt.subplot(3,2,3)
plt.title('sobel y')
plt.imshow(filtered_image_y, cmap='gray')
plt.subplot(3,2,4)
plt.title('sobel y decimal')
plt.imshow(filtered_image_y_2, cmap='gray')
plt.subplot(3,2,5)
plt.title('sobel x')
plt.imshow(filtered_image_x, cmap='gray')
plt.subplot(3,2,6)
plt.title('sobel x 5*5')
plt.imshow(filtered_image_x_5x5, cmap='gray')
plt.show()结果:

1.2 可视化卷积层
在本笔记本中,我们将卷积层的四个过滤输出(又称激活图)可视化。
在这个例子中,我们定义了四个滤波器,通过初始化卷积层的权值来应用于输入图像,经过训练的CNN将学习这些权值的值。
导入图像:
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# TODO: Feel free to try out your own images here by changing img_path
# to a file path to another image on your computer!
img_path = 'data/udacity_sdc.png'
# load color image
bgr_img = cv2.imread(img_path)
# convert to grayscale
gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
# normalize, rescale entries to lie in [0,1]
gray_img = gray_img.astype("float32")/255
# plot image
plt.imshow(gray_img, cmap='gray')
plt.show()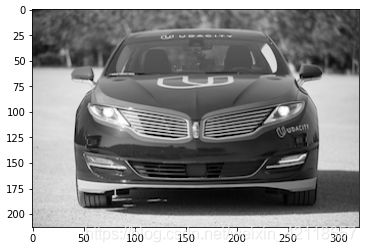
定义并可视化过滤器:
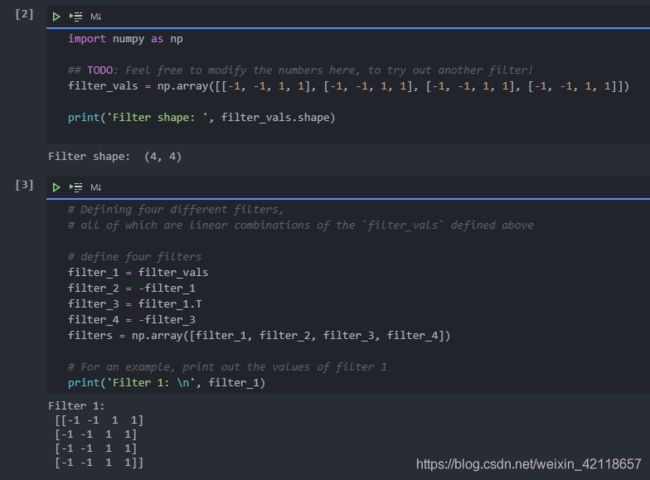
# visualize all four filters
fig = plt.figure(figsize=(10, 5))
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
width, height = filters[i].shape
for x in range(width):
for y in range(height):
ax.annotate(str(filters[i][x][y]), xy=(y,x),
horizontalalignment='center',
verticalalignment='center',
color='white' if filters[i][x][y]<0 else 'black')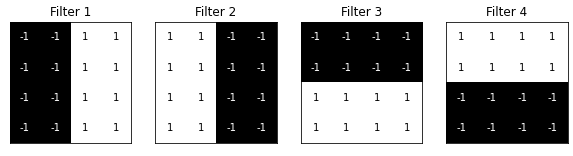
定义卷积层
初始化单个卷积层,使其包含所有创建的过滤器。请注意,您没有训练此网络;您正在卷积层中初始化权重,以便可以直观地看到前向传播此网络后发生的情况!
下面,我定义了一个名为Net类的结构,它有一个卷积层,可以包含四个4x4灰度过滤器。
import torch
import torch.nn as nn
import torch.nn.functional as F
# define a neural network with a single convolutional layer with four filters
class Net(nn.Module):
def __init__(self, weight):
super(Net, self).__init__()
# initializes the weights of the convolutional layer to be the weights of the 4 defined filters
k_height, k_width = weight.shape[2:]
# assumes there are 4 grayscale filters
self.conv = nn.Conv2d(1, 4, kernel_size=(k_height, k_width), bias=False)
self.conv.weight = torch.nn.Parameter(weight)
def forward(self, x):
# calculates the output of a convolutional layer
# pre- and post-activation
conv_x = self.conv(x)
activated_x = F.relu(conv_x)
# returns both layers
return conv_x, activated_x
# instantiate the model and set the weights
weight = torch.from_numpy(filters).unsqueeze(1).type(torch.FloatTensor)
model = Net(weight)
# print out the layer in the network
print(model)
可视化每个过滤器的输出
首先,我们将定义一个helper函数,即接受特定层和过滤器数量(可选参数)的 viz_layer,并在图像通过后显示该层的输出。
# helper function for visualizing the output of a given layer
# default number of filters is 4
def viz_layer(layer, n_filters= 4):
fig = plt.figure(figsize=(20, 20))
for i in range(n_filters):
ax = fig.add_subplot(1, n_filters, i+1, xticks=[], yticks=[])
# grab layer outputs
ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray')
ax.set_title('Output %s' % str(i+1))在应用ReLu激活函数之前和之后,让我们看看卷积层的输出。
# plot original image
plt.imshow(gray_img, cmap='gray')
# visualize all filters
fig = plt.figure(figsize=(12, 6))
fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05)
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
# convert the image into an input Tensor
gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
# get the convolutional layer (pre and post activation)
conv_layer, activated_layer = model(gray_img_tensor)
# visualize the output of a conv layer
viz_layer(conv_layer)结果:

ReLu 激活函数
在这个模型中,我们使用了一个激活函数来缩放卷积层的输出。我们选择了一个ReLu函数来实现这一点,这个函数只是将所有负像素值转换为0(黑色)。关于输入像素值x,请参见下图中的公式。
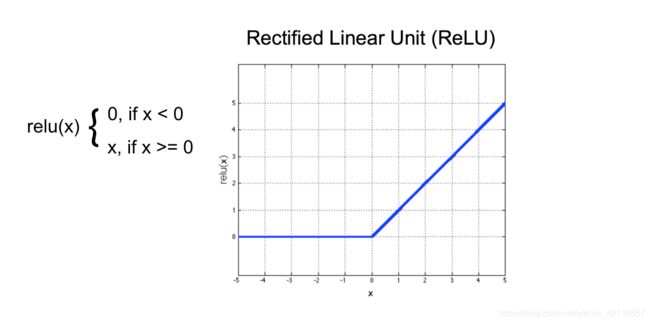
# after a ReLu is applied
# visualize the output of an activated conv layer
viz_layer(activated_layer)结果:

1.3 可视化池化层
在这个笔记本中,我们添加并可视化了CNN中maxpooling层的输出。
卷积层+激活函数、池化层和线性层(用于创建所需的输出大小)构成CNN的基本层。

1.3.1 Import the image
1.3.2 Define and visualize the filters
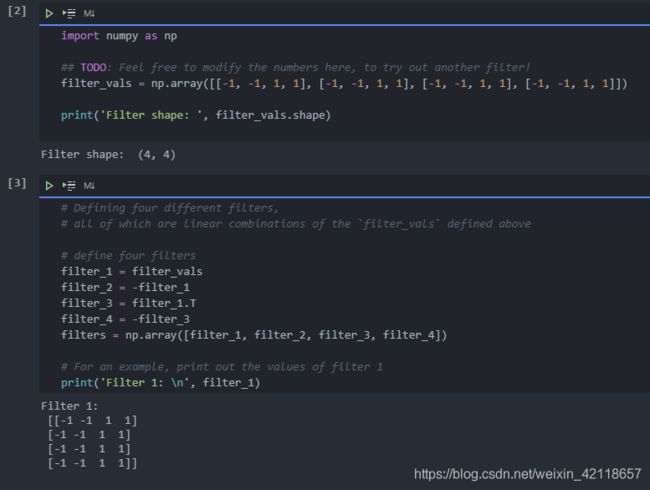
1.3.3 Define convolutional and pooling layers
在下一个单元中,我们初始化一个卷积层,以便它包含所有创建的过滤器。然后添加一个maxpooling层,内核大小为(2x2),这样您就可以看到在这一步之后图像分辨率已经降低了!
maxpooling层减少了输入的大小,并且只保留最活跃的像素值。下面是一个2x2池内核的示例,步长为2,应用于一小块灰度像素值;将面片的大小减少2倍。只有2x2中的最大像素值保留在新的合并输出中。


1.3.4 Visualize the output of each filter
首先,我们将定义一个helper函数,即接受特定层和过滤器数量(可选参数)的viz_layer,并在图像通过后显示该层的输出。
# helper function for visualizing the output of a given layer
# default number of filters is 4
def viz_layer(layer, n_filters= 4):
fig = plt.figure(figsize=(20, 20))
for i in range(n_filters):
ax = fig.add_subplot(1, n_filters, i+1)
# grab layer outputs
ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray')
ax.set_title('Output %s' % str(i+1))让我们看看应用ReLu激活函数后卷积层的输出:
# plot original image
plt.imshow(gray_img, cmap='gray')
# visualize all filters
fig = plt.figure(figsize=(12, 6))
fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05)
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
# convert the image into an input Tensor
gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
# get all the layers
conv_layer, activated_layer, pooled_layer = model(gray_img_tensor)
# visualize the output of the activated conv layer
viz_layer(activated_layer)结果:
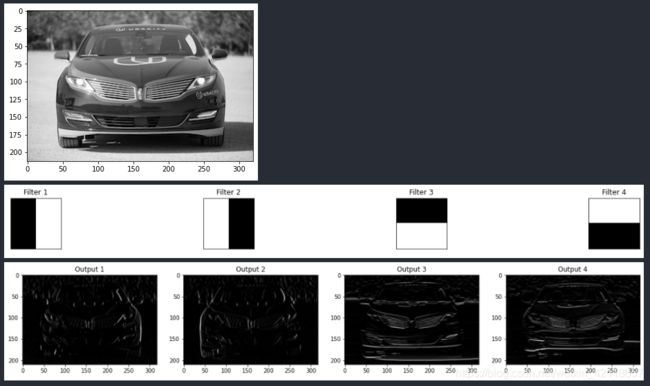
1.3.5 Visualize the output of the pooling layer
然后,看看池层的输出。池化层将上图中的特征映射作为输入,通过某种池化因子,通过在给定的内核区域中构造一个只有最大值(最亮值)的新的、更小的图像来降低这些映射的维数。
仔细观察x、y轴上的值,以查看图像大小的变化。
2 设计和训练一个CNN对MNIST手写数字分类
在本笔记本中,我们将训练一个MLP(Multi-Layer Perceptron 多层感知器)来对MNIST数据库手写数字数据库中的图像进行分类。
该过程将分为以下步骤:
- 加载并可视化数据
- 定义神经网络
- 训练模型
- 在测试数据集上评估我们训练模型的性能!
在开始之前,我们必须导入处理数据和PyTorch所需的库。
# import libraries
import torch
import numpy as np2.1 加载并可视化数据
下载可能需要一些时间,您应该可以在加载数据时看到您的进度。如果要一次加载更多数据,也可以选择更改批处理大小。
这个单元格将为每个数据集创建数据加载器。
# The MNIST datasets are hosted on yann.lecun.com that has moved under CloudFlare protection
# Run this script to enable the datasets download
# Reference: https://github.com/pytorch/vision/issues/1938
from six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)from torchvision import datasets
import torchvision.transforms as transforms
# number of subprocesses to use for data loading
num_workers = 0
# how many samples per batch to load
batch_size = 20
# convert data to torch.FloatTensor
transform = transforms.ToTensor()
# choose the training and test datasets
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# prepare data loaders
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
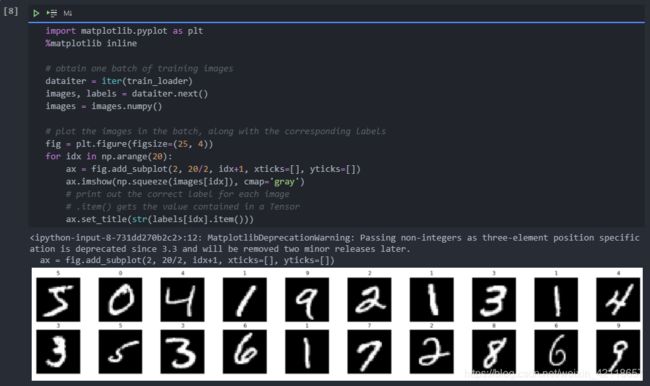
num_workers=num_workers)2.1.1 可视化训练集中一个batch图像集
分类任务的第一步是查看数据,确保数据正确加载,然后对数据中的模式进行任何初始观察。
2.1.2 观察单个图像更详细的信息

2.2 定义网络结构
该网络结构将784维度张量作为输入,并输出长度为10(我们的类别数)的张量,该张量指示输入图像的类分数。这个特殊的例子使用了2个隐藏层和dropout来避免过度拟合。
import torch.nn as nn
import torch.nn.functional as F
## TODO: Define the NN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# linear layer (784 -> 1 hidden node)
self.fc1 = nn.Linear(28 * 28, 256)
self.fc2 = nn.Linear(256, 64)
self.fc3 = nn.Linear(64, 10)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
# flatten image input
x = x.view(-1, 28 * 28)
# add hidden layer, with relu activation function
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = F.log_softmax(self.fc3(x), dim=1)
return x
# initialize the NN
model = Net()
print(model)
2.3 指定损失函数和优化器
建议使用交叉熵损失进行分类。如果您查看文档,您可以看到PyTorch的交叉熵函数将softmax函数应用于输出层,然后计算日志损失。
## TODO: Specify loss and optimization functions
from torch import nn, optim
# specify loss function
criterion = nn.CrossEntropyLoss()
# specify optimizer
optimizer = optim.SGD(model.parameters(), lr=0.01)2.4 训练网络
从一批数据中训练/学习的步骤在下面的注释中描述:
- 1.清除所有优化变量的梯度
- 2.前向传播:通过将输入传递到模型来计算预测输出
- 3.计算损失
- 4.反向传播:计算相对于模型参数的损失梯度
- 5.执行单个优化步骤(参数更新)
- 6.更新平均训练损失
以下是30个epoch的循环训练;请随意更改此值。目前,我们建议在20-50个epoch之间。在训练时,看看训练损失的值是如何随着时间的推移而减少的。我们希望它减少,同时也避免过拟合训练数据。
# number of epochs to train the model
n_epochs = 30 # suggest training between 20-50 epochs
model.train() # prep model for training
for epoch in range(n_epochs):
# monitor training loss
train_loss = 0.0
###################
# train the model #
###################
for data, target in train_loader:
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update running training loss
train_loss += loss.item()*data.size(0)
# print training statistics
# calculate average loss over an epoch
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(
epoch+1,
train_loss
))训练结果:
- Epoch: 1 Training Loss: 0.950629
- Epoch: 2 Training Loss: 0.378016
- Epoch: 3 Training Loss: 0.292131
- Epoch: 4 Training Loss: 0.237494
- Epoch: 5 Training Loss: 0.203416
- Epoch: 6 Training Loss: 0.178869
- Epoch: 7 Training Loss: 0.157555
- Epoch: 8 Training Loss: 0.143985
- Epoch: 9 Training Loss: 0.132015
- Epoch: 10 Training Loss: 0.122434
- Epoch: 11 Training Loss: 0.113976
- Epoch: 12 Training Loss: 0.105239
- Epoch: 13 Training Loss: 0.098839
- Epoch: 14 Training Loss: 0.093791
- Epoch: 15 Training Loss: 0.088727
- Epoch: 16 Training Loss: 0.081909
- Epoch: 17 Training Loss: 0.079282
- Epoch: 18 Training Loss: 0.074924
- Epoch: 19 Training Loss: 0.071149
- Epoch: 20 Training Loss: 0.068345
- Epoch: 21 Training Loss: 0.065399
- Epoch: 22 Training Loss: 0.062431
- Epoch: 23 Training Loss: 0.060230
- Epoch: 24 Training Loss: 0.056332
- Epoch: 25 Training Loss: 0.055859
- Epoch: 26 Training Loss: 0.053873
- Epoch: 27 Training Loss: 0.050490
- Epoch: 28 Training Loss: 0.049184
- Epoch: 29 Training Loss: 0.046799
- Epoch: 30 Training Loss: 0.047051
2.5 测试训练好的网络
最后,我们在以前看不到的测试数据上测试了我们的最佳模型,并评估了它的性能。在看不见的数据上进行测试是检验我们的模型是否具有良好的泛化能力的一个好方法。在这个分析中,细化模型,看看这个模型在每个类上的表现,以及它的总体损失和准确性,也可能是有用的。
model.eval() 将模型中的所有层设置为评估模式。这会影响像dropout这样的层,这些层在训练期间以一定的概率关闭节点,但是评估时dropout的功能会被关闭。
# initialize lists to monitor test loss and accuracy
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval() # prep model for *evaluation*
for data, target in test_loader:
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct = np.squeeze(pred.eq(target.data.view_as(pred)))
# calculate test accuracy for each object class
for i in range(batch_size):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# calculate and print avg test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
str(i), 100 * class_correct[i] / class_total[i],
class_correct[i], class_total[i]))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))
2.6 可视化test集预测结果
此单元格按以下格式显示测试图像及其标签:predicted (ground-truth)。文本将是绿色的准确分类的例子和红色的错误预测。
# obtain one batch of test images
dataiter = iter(test_loader)
images, labels = dataiter.next()
# get sample outputs
output = model(images)
# convert output probabilities to predicted class
_, preds = torch.max(output, 1)
# prep images for display
images = images.numpy()
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20/2, idx+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(images[idx]), cmap='gray')
ax.set_title("{} ({})".format(str(preds[idx].item()), str(labels[idx].item())),
color=("green" if preds[idx]==labels[idx] else "red"))
3 设计并训练一个CNN来对CIFAR10数据集中的图像进行分类
在本笔记本中,我们训练CNN对CIFAR-10数据库中的图像进行分类。
该数据库中的图像是小彩色图像,分为10个类;下面是一些示例图片。

3.1 CUDA测试
由于这些是更大(32x32x3)的图像,因此使用GPU加速训练可能会很有用。CUDA是一个并行计算平台,CUDA张量与典型张量相同,只是利用GPU进行计算。
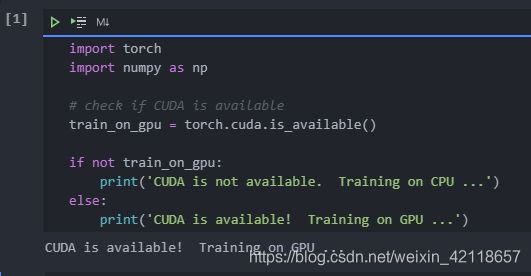
3.2 加载数据
下载可能需要一分钟。我们加载训练和测试数据,将训练数据拆分为训练和验证集,然后为每个数据集创建数据加载器。
from torchvision import datasets
import torchvision.transforms as transforms
from torch.utils.data.sampler import SubsetRandomSampler
# number of subprocesses to use for data loading
num_workers = 0
# how many samples per batch to load
batch_size = 20
# percentage of training set to use as validation
valid_size = 0.2
# convert data to a normalized torch.FloatTensor
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# choose the training and test datasets
train_data = datasets.CIFAR10('data', train=True,
download=True, transform=transform)
test_data = datasets.CIFAR10('data', train=False,
download=True, transform=transform)
# obtain training indices that will be used for validation
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(valid_size * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
# define samplers for obtaining training and validation batches
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# prepare data loaders (combine dataset and sampler)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
sampler=train_sampler, num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
sampler=valid_sampler, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
num_workers=num_workers)
# specify the image classes
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']3.3 可视化一批训练数据

3.4 更详细地查看图像
在这里,我们将标准化后的红色、绿色和蓝色(RGB)颜色通道视为三个独立的灰度强度图像。
rgb_img = np.squeeze(images[6]) #上图第6序号的红色鸟
channels = ['red channel', 'green channel', 'blue channel']
fig = plt.figure(figsize = (36, 36))
for idx in np.arange(rgb_img.shape[0]):
ax = fig.add_subplot(1, 3, idx + 1)
img = rgb_img[idx]
ax.imshow(img, cmap='gray')
ax.set_title(channels[idx])
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
val = round(img[x][y],2) if img[x][y] !=0 else 0
ax.annotate(str(val), xy=(y,x),
horizontalalignment='center',
verticalalignment='center', size=8,
color='white' if img[x][y]结果如下(图像可以放大查看):
3.5 定义网络结构
这一次,您将定义一个CNN架构:
- 卷积层,可以看作是过滤图像的滤波器堆叠。
- Maxpooling层,它减少输入的x-y大小,只保留前一层中最活跃的像素。
- 通常的线性+dropout层,以避免过度拟合,并产生一个10维度的输出。
下面的图片和代码中显示了一个具有两个卷积层的网络,您已经获得了具有一个卷积层和一个maxpooling层的起始代码。
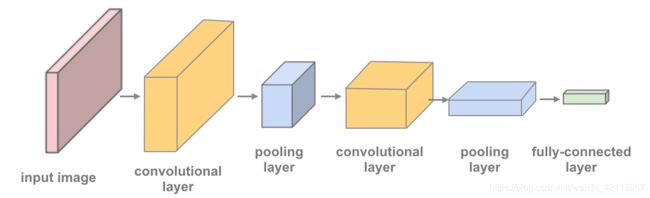
TODO:定义具有多个卷积层的模型,并定义前馈网络行为。
包含的卷积层越多,模型可以检测到的颜色和形状的模式就越复杂。建议您的最终模型包括2或3个卷积层以及线性层+dropout,以避免过拟合。
将相关模型的现有研究和实现作为定义您自己的模型的起点是一种很好的做法。您可能会发现查看这个PyTorch分类示例或这个更复杂的Keras示例有助于确定最终结构。
https://github.com/pytorch/tutorials/blob/master/beginner_source/blitz/cifar10_tutorial.py
https://github.com/keras-team/keras/blob/master/examples/cifar10_cnn.py
卷积层的输出大小:
为了计算给定卷积层的输出大小,我们可以执行以下计算(摘自斯坦福的cs231n课程):
- 我们可以计算输出卷的空间大小,作为输入卷大小(W)、内核大小(F)、应用它们的步长(S)和边界上使用的零填充量(P)的函数。计算输出的正确公式为:(W−F+2P)/S + 1。
例如,对于7x7输入和3x3滤波器,步幅1和pad 0,我们将得到5x5输出。如果用步幅2,我们可以得到3x3的输出。
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# convolutional layer
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
# convolutional layer
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
# convolutional layer
self.conv3 = nn.Conv2d(32, 64, 3, padding=1)
# max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# linear layer (64 * 4 * 4 -> 200)
self.fc1 = nn.Linear(64 * 4 * 4, 200)
# linear layer (200 -> 10)
self.fc2 = nn.Linear(200, 10)
# dropout layer (p=0.2)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool( F.relu( self.conv1(x))) #输出维度:16 * 16*16
x = self.pool( F.relu( self.conv2(x))) #输出维度:32 * 8*8
x = self.pool( F.relu( self.conv3(x))) #输出维度:64 * 4*4
# flatten image input
x = x.view(-1, 64 * 4 * 4)
# add dropout layer
x = self.dropout(x)
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc1(x)) #输出维度:200
# add dropout layer
x = self.dropout(x)
x = self.fc2(x) #输出维度:10
return x
# create a complete CNN
model = Net()
print(model)
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()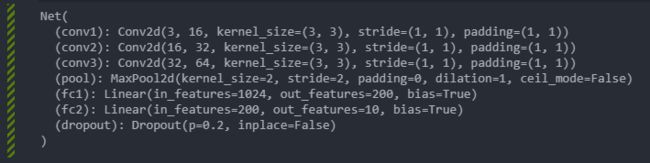
3.6 指定损失函数和优化器
import torch.optim as optim
# specify loss function
criterion = nn.CrossEntropyLoss()
# specify optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)3.7 训练网络
记住看看训练集和验证集损失是如何随着时间的推移而减少的;如果验证集损失增加,则表明可能过拟合。
# number of epochs to train the model
n_epochs = 8 # you may increase this number to train a final model
valid_loss_min = np.Inf # track change in validation loss
for epoch in range(1, n_epochs+1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()*data.size(0)
######################
# validate the model #
######################
model.eval()
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item()*data.size(0)
# calculate average losses
train_loss = train_loss/len(train_loader.dataset)
valid_loss = valid_loss/len(valid_loader.dataset)
# print training/validation statistics
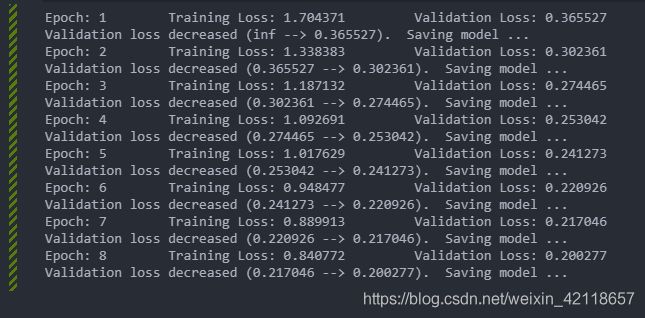
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss结果:
3.8 加载模型
model.load_state_dict(torch.load('model_cifar.pt'))3.9 测试训练好的模型
在以前看不到的数据上测试你的训练模型!一个“好”的训练结果大约有70%分类精度(或更多,尽你最大的努力!)。
# track test loss
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval()
# iterate over test data
for data, target in test_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct_tensor = pred.eq(target.data.view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
# calculate test accuracy for each object class
for i in range(batch_size):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# average test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
classes[i], 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]), np.sum(class_total[i])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))结果:

3.10 问题:你的模型有哪些缺点,如何改进?
答:
- 训练结束时,loss还在快速下降,训练的epoch数远远不够。
- 不同类别的测试结果差异较大,类别比较复杂多变的类预测效果普遍较差(如狗、小汽车、鸟类),这些类相对其他类,类内距离较大,这要么表示模型训练时间不够还没掌握复杂类的预测,要么模型结构的复杂度还较低导致无法表达复杂类情况。
3.11 可视化test集预测结果
# obtain one batch of test images
dataiter = iter(test_loader)
images, labels = dataiter.next()
images.numpy()
# move model inputs to cuda, if GPU available
if train_on_gpu:
images = images.cuda()
# get sample outputs
output = model(images)
# convert output probabilities to predicted class
_, preds_tensor = torch.max(output, 1)
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
if train_on_gpu:
images = images.cpu()
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20/2, idx+1, xticks=[], yticks=[])
imshow(images[idx] if not train_on_gpu else images[idx].cpu())
ax.set_title("{} ({})".format(classes[preds[idx]], classes[labels[idx]]),
color=("green" if preds[idx]==labels[idx].item() else "red"))结果:
