Apache Druid(二、架构设计)
文章目录
- 回顾
- 架构
-
- 整体设计
- 进程服务作用
- 数据流
-
- 数据生产
- 数据查询
- 查询的优化
- 索引服务
- 存储设计
-
- Datasrouces and segments
- segment设计
-
- 特殊数据结构
- 命名设计
- 实际物理存储
- Segment创建过程
- 参考
回顾
上一篇提供druid的安装是很早的版本了 https://blog.csdn.net/yyoc97/article/details/88411429,目前druid的安装使用会更简洁些快速入门。因为现在接触的业务有使用到这个组件,今天我们再来学习下它整体的架构。
架构
整体设计
这个是Druid的架构图,可以整体可以分为两大块。上面蓝色部分为Druid自身的服务,分为master,query 和data节点。下面橘色的部分为Druid的外部依赖。主要是元数据存储,deep storage常用的就有hdfs, zk用于集群协调。
节点间相互不影响,都通过zk交互数据。
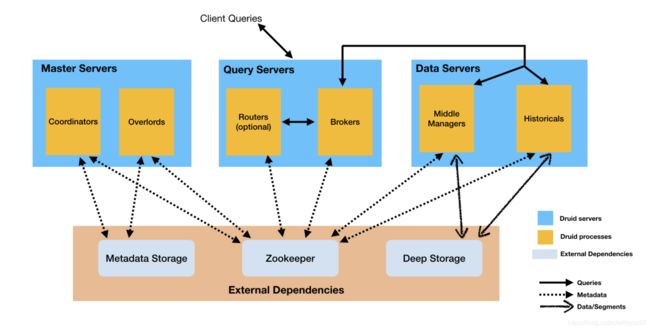
进程服务作用
- 进程
Coordinator 协调器进程管理集群上的数据可用性。
Overlord 进程控制数据摄取工作负载的分配。
Broker 代理进程处理来自外部客户端的查询。
Router 路由进程是可选进程,可以将请求路由到 Brokers、Coordinator 和 Overlords。
Historical 历史进程存储可查询的数据。
MiddleManager 进程负责摄取数据。 - 服务
Master:运行 Coordinator 和 Overlord 进程,管理数据可用性和摄取。
Query:运行 Broker 和可选的 Router 进程,处理来自外部客户端的查询。
Data:运行历史和 MiddleManager 进程,执行摄取工作负载并存储所有可查询的数据。
数据流
数据生产
master下overlords负责接收生产请求,然后把任务写入zk里面去,然后由data部分的middler managers去zk拉取消息,进行数据生产,完成生产后会将数据写入deep storage中。再回写完成标致。coordinator 是个协调节点负责数据的负载均衡,他会在data historicals中找寻压力比较小的节点,原理也是将标致写入zk中,去影响数据通过哪个historicals写入deep storage
数据查询
首先客户端会发送查询请求到Query部分,会根据routers选择之后,其中 Broker 将识别哪些段具有可能与该查询有关的数据。段列表总是按时间修剪,也可能由其他属性修剪,具体取决于数据源的分区方式。然后,Broker 将识别哪些Historian和 MiddleManager正在为这些段提供服务,并向这些进程中的每一个发送重写的子查询。Historical/MiddleManager 进程将接收查询、处理它们并返回结果。Broker 接收结果并将它们合并在一起以获得最终答案,并将其返回给原始调用者。
查询的优化
- 修剪每个查询访问哪些段。
- 在每个段内,使用索引来标识必须访问哪些行。
- 在每个段内,仅读取与特定查询相关的特定行和列。
索引服务
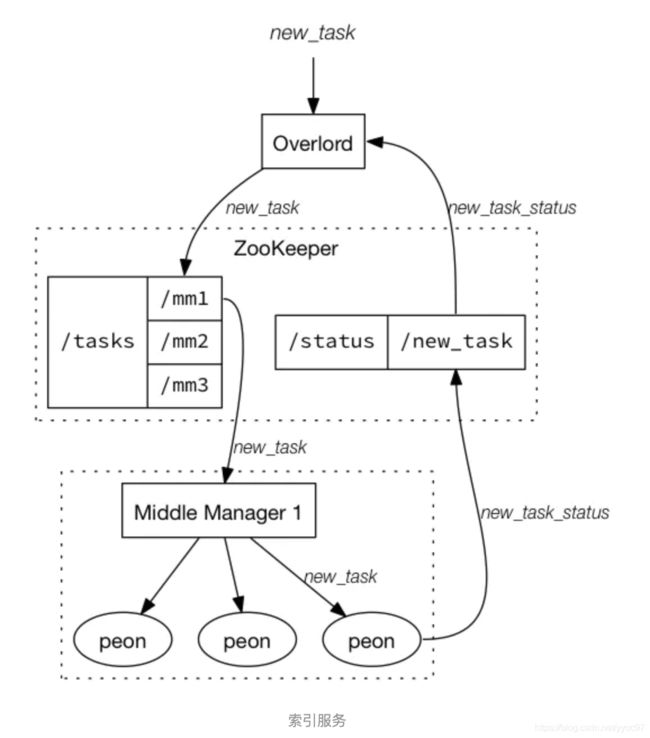
Druid提供一组支持索引服务(Indexing Service)的组件,也就是Overload和MiddleManager节点。索引服务是一种高可用的分布式服务,用于运行跟索引相关的任务,索引服务是数据摄入创建和销毁Segment的主要方式(还有一种是采用实时节点的方式,但是现在已经废弃了)。索引服务支持以pull或push的方式摄入外部数据。
索引服务采用的是主从架构,Overload为主节点,MiddleManager是从节点。索引服务架构图如下图所示:
存储设计
Datasrouces and segments
Druid 数据存储在“数据源”中,类似于传统 RDBMS 中的表。每个数据源都按时间分区,并且可以选择按其他属性进一步分区。每个时间范围称为一个“块”(例如,一天,如果您的数据源按天分区)。在一个块内,数据被分成一个或多个 “段”。每个段都是一个文件,通常包含多达几百万行的数据。
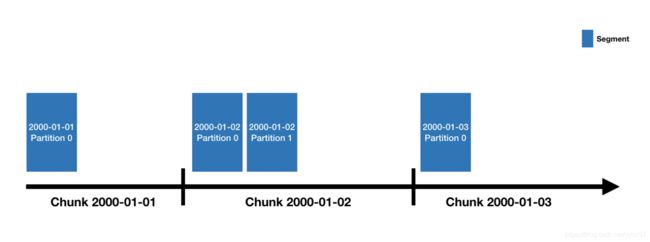
一个数据源可能只有几个段,也可能有数十万甚至数百万个段。每个段都是在 MiddleManager 上创建的,在这一点上,它是可变的且未提交的。段构建过程包括以下步骤,旨在生成紧凑且支持快速查询的数据文件:
1.转换为柱状格式
2.使用位图索引进行索引
3.使用各种算法进行压缩
定期提交和发布段。此时,它们被写入深存储,变得不可变,并从 MiddleManagers 移动到历史进程。有关该段的条目也被写入元数据存储。此条目是关于段的自描述元数据,包括段的架构、其大小及其在深度存储中的位置等内容。这些条目是协调器用来了解集群上应该提供哪些数据的条目。
segment设计
Segment是数据存储、复制、均衡(Historical的负载均衡)和计算的基本单元了。Segment具有不可变性,一个Segment一旦创建完成后(MiddleManager节点发布后)就无法被修改,只能通过生成一个新的Segment来代替旧版本的Segment。
特殊数据结构
对于时间戳列和指标列,实际存储是一个数组,Druid采用LZ4压缩每列的整数或浮点数。当收到查询请求后,会拉出所需的行数据(对于不需要的列不会拉出来),并且对其进行解压缩。解压缩完之后,在应用具体的聚合函数。
对于维度列不会像指标列和时间戳这么简单,因为它需要支持filter和group by,所以Druid使用了字典编码(Dictionary Encoding)和位图索引(Bitmap Index)来存储每个维度列。每个维度列需要三个数据结构:
- 需要一个字典数据结构,将维值(维度列值都会被认为是字符串类型)映射成一个整数ID。
- 使用上面的字典编码,将该列所有维值放在一个列表中。
- 对于列中不同的值,使用bitmap数据结构标识哪些行包含这些值。
Druid针对维度列之所以使用这三个数据结构,是因为:
- 使用字典将字符串映射成整数ID,可以紧凑的表示结构2和结构3中的值。
- 使用Bitmap位图索引可以执行快速过滤操作(找到符合条件的行号,以减少读取的数据量),因为Bitmap可以快速执行AND和OR操作。
- 对于group by和TopN操作需要使用结构2中的列值列表。
我们以上面"Page"维度列为例,可以具体看下Druid是如何使用这三种数据结构存储维度列:
1. 使用字典将列值映射为整数
{
"Justin Bieher":0,
"ke$ha":1
}
2. 使用1中的编码,将列值放到一个列表中
[0,0,1,1]
3. 使用bitmap来标识不同列值
value = 0: [1,1,0,0] //1代表该行含有该值,0标识不含有
value = 1: [0,0,1,1]
下图是以advertiser列为例,描述了advertiser列的实际存储结构:

命名设计
高效的数据查询,不仅仅体现在文件内容的存储结构上,还有一点很重要,就是文件的命名上。试想一下,如果一个Datasource下有几百万个Segment文件,我们又如何快速找出我们所需要的文件呢?答案就是通过文件名称快速索引查找。
Segment的命名包含四部分:数据源(Datasource)、时间间隔(包含开始时间和结束时间两部分)、版本号和分区(Segment有分片的情况下才会有)。
test-datasource_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T16:00:00.000Z_1
# 数据源名称_开始时间_结束时间_版本号_分区
分片号是从0开始,如果分区号为0,则可以省略:test-datasource_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T16:00:00.000Z
还需要注意如果一个时间间隔segment由多个分片组成,则在查询该segment的时候,需要等到所有分片都被加载完成后,才能够查询(除非使用线性分片规范(linear shard spec),允许在未加载完成时查询)
实际物理存储
下面我们以一个实例来看下Segment到底以什么形式存储的,我们以本地导入方式将下面rollup-tutorial.json数据导入到Druid中。
{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":20,"bytes":9024}
{"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":255,"bytes":21133}
{"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":11,"bytes":5780}
{"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":38,"bytes":6289}
{"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":377,"bytes":359971}
{"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":49,"bytes":10204}
{"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":38,"bytes":6289}
{"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":123,"bytes":93999}
{"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":12,"bytes":2818}
我们以单机形式运行Druid,这样Druid生成的Segment文件都在${DRUID_HOME}/var/druid/segments目录下。
segment通过datasource_beginTime_endTime_version_shard用于唯一标识,在实际存储中是以目录的形式表现的。
![]()
可以看到Segment中包含了Segment描述文件(descriptor.json)和压缩后的索引数据文件(index.zip),我们主要看的也是index.zip这个文件,对其进行解压缩。
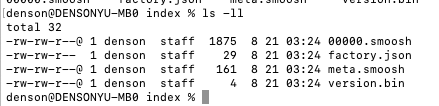
首先看下factory.json这个文件,这个文件并不是segment具体存储段数据的文件。因为Druid通过使用MMap(一种内存映射文件的方式)的方式访问Segment文件,通过查看这个文件内容来看,貌似是用于MMap读取文件所使用的(不太了解MMap)?
#factory.json文件内容
{"type":"mMapSegmentFactory"}
Druid实际存储Segment数据文件是:version.bin、meta.smoosh和xxxxx.smoosh这三个文件,下面分别看下这三个文件的内容。
version.bin是一个存储了4个字节的二进制文件,它是Segment内部版本号(随着Druid发展,Segment的格式也在发展),目前是V9,以Sublime打开该文件可以看到:
0000 0009
meta.smoosh里面存储了关于其它smoosh文件(xxxxx.smoosh)的元数据,里面记录了每一列对应文件和在文件的偏移量。除了列信息外,smoosh文件还包含了index.drd和metadata.drd,这部分是关于Segment的一些额外元数据信息。
#版本号,该文件所能存储的最大值(2G),smooth文件数
v1,2147483647,1
# 列名,文件名,起始偏移量,结束偏移量
__time,0,0,167
bytes,0,167,331
count,0,331,482
dstIP,0,982,1322
index.drd,0,1322,1507
metadata.drd,0,1507,1875
packets,0,482,642
srcIP,0,642,982
再看00000.smoosh文件前,我们先想一下为什么这个文件被命名为这种样式?因为Druid为了最小化减少打开文件的句柄数,它会将一个Segment的所有列数据都存储在一个smoosh文件中,也就是xxxxx.smoosh这个文件。但是由于Druid使用MMap来读取Segment文件,而MMap需要保证每个文件大小不能超过2G(Java中的MMapByteBuffer限制),所以当一个smoosh文件大于2G时,Druid会将新数据写入到下一个smoosh文件中。这也就是为什么这些文件命名是这样的,这里也对应上了meta文件中为什么还要标识列所在的文件名。
通过meta.smoosh的偏移量也能看出,00000.smoosh文件中数据是按列进行存储的,从上到下分别存储的是时间列、指标列、维度列。对于每列主要包会含两部分信息:ColumnDescriptor和binary数据。columnDescriptor是一个使用Jackson序列化的对象,它包含了该列的一些元数据信息,比如数据类型、是否是多值等。而binary则是根据不同数据类型进行压缩存储的二进制数据。
在smooth文件最后还包含了两部分数据,分别是index.drd和metadata.drd。其中index.drd中包含了Segment中包含哪些度量、维度、时间范围、以及使用哪种bitmap。metadata.drd中存储了指标聚合函数、查询粒度、时间戳配置等(上面内容的最后部分)。
下图是物理存储结构图(样例),存储未压缩和编码的数据就是最右边的内容。

Segment创建过程
Segment都是在MiddleManager节点中创建的,并且处在MiddleManager中的Segment在状态上都是可变的并且未提交的(提交到DeepStorage之后,数据就不可改变)。
Segment从在MiddleManager中创建到传播到Historical中,会经历以下几个步骤:
- MiddleManager中创建Segment文件,并将其发布到Deep Storage。
- Segment相关的元数据信息被存储到MetaStore中。
- Coordinator进程根据MetaStore中得知Segment相关的元数据信息后,根据规则的设置分配给复合条件的Historical节点。
- Historical节点得到Coordinator指令后,自动从DeepStorage中拉取Segment数据文件,并通过Zookeeper向集群声明负责提供该Segment数据相关的查询服务。
- MiddleManager在得知Historical负责该Segment后,会丢弃该Segment文件,并向集群声明不在负责该Segment相关的查询。
参考
https://druid.apache.org/docs/latest/design/architecture.html
https://www.jianshu.com/p/7a26d9153455