2小时部署实时反欺诈深度学习模型 —— IBM主机机器学习平台社区版简介
说到过去这几年最热门的技术,人工智能毫无疑问是其中最受关注的之一。Gartner的研究报告指出,已经在其企业中部署了人工智能项目的组织已经从2019年的14%上升到了2021年的21%。但是和有意愿更广泛的应用人工智能却尚未部署的组织数量相比,21%这个数字仍然不算高。特别是对于金融、保险、政府这些有严格监管要求的组织,如何能够在将人工智能能力赋予大规模并发的关键应用的同时又不影响这些应用的服务质量成为他们部署人工智能项目的首要挑战。IBM主机机器学习平台(WMLz ——Watson Machine Learning for z/OS)即是针对这一问题而生的。它基于IBM Z所天生拥有的高可用、高可靠和高性能的硬件和架构优势,可以在几毫秒的响应时间内轻松处理大规模的机器学习推理(inferencing)运算。在本文中,我们将为您介绍IBM主机机器学习平台在深度学习推理方面的功能,与您分享如何在2小时内使用其社区版上线实时反欺诈深度学习应用。
深度学习
在谈到人工智能的时候,很多人会立刻想到深度学习。甚至有人认为深度学习是人工智能的代名词。事实上,人工智能是个很宽泛的概念,机器学习只是实现人工智能的方法之一,而深度学习是机器学习中的一个子领域。通常多于三层(包括三层)的神经网络模型被称为深度学习模型。神经网络算法通过模拟人脑运作的方式来挖掘信息之间的关系。神经网络算法本身并不是新的技术。它诞生于上世纪80年代,但是最初的神经网络只有很少的层数。最近十年,随之数据存储能力和计算能力的大幅度提升,数据科学家可以构建超过百层的神经网络并将其应用在包含海量数据的数据集上,进而在图像语音识别、自然语言处理等很多领域取得了重大的突破。除此之外,深度学习也被广泛的应用在结构化数据的分析中,在金融反欺诈,流程自动化等很多企业应用场景中发挥了重要作用。
在深度学习的发展过程中,开源社区的贡献功不可没。一代代深度学习框架在功能、性能和易用性上不断突破,让越来越多的人,特别是非计算机专业的人才,可以将深度学习应用于各自的领域。TensorFlow、Caffe、Caffe2、PyTorch都是当今流行的深度学习框架。它们提供了丰富的API和充分优化过的神经网络算法实现,使用户能够轻松而高效的创建自己的深度学习模型。
ONNX——开放的机器学习模型格式
另一方面,社区的碎片化也给深度学习的商业化应用带来了挑战。背景不同的数据科学家会对不同的深度学习框架和编程语言有自己的偏好。当深度学习模型被交付给开发人员时,开发人员可能需要把一种自己完全不熟悉的深度学习框架库集成到自己的应用中,这往往需要大量的学习成本和与数据科学家团队的沟通成本,从而大幅度的拖慢项目进度,增加项目成本。
ONNX(Open Neural Network Exchange)是一个开放的机器学习生态系统,它提供了用来表示机器学习模型的开放格式。ONNX定义了一个可扩展的计算图模型、一组常用的操作符和标准的数据类型。通过ONNX,各个深度学习框架之间可以实现互操作并可以在共享的格式更有针对性的就行性能优化。ONNX得到了业界的广泛支持,包括Facebook、微软、IBM、华为等有公司都积极参与到了ONNX社区的建设中来。PyTorch、Caffe2、CNTK等主流深度学习框架内置了对ONNX格式的支持。TensorFlow、Keras等也有相应的开源项目来完成从各自格式到ONNX的转换。
深度学习编译器(Deep Learning Compiler)
ONNX的开放和互操作性使之在深度学习模型推理中的应用具有显著的优势。基于ONNX的深度学习模型推理引擎可以更有针对性的进行推理运行时的优化,而不是对每一种深度学习框架各自做优化。这种针对性在硬件平台提供加速的情况下带来的开发成本优势就更为明显。因此,基于ONNX的推理运行时生态非常繁荣。ONNX Runtime和基于IBM深度学习编译器(DLC, Deep Learning Compiler)技术的ONNX-MLIR项目就是很好的例子。其中后者发源于IBM研究院。顾名思义,深度学习编译技术将一个ONNX格式的深度学习模型编译成本地可执行代码而避免了解释运行深度学习模型的格外开销,从而提升深度学习模型推理的性能。而且可执行代码还可以充分利用不同平台架构和硬件的加速特性。ONNX-MLIR生成的代码就针对IBM Power和IBM Z平台均做了优化。
IBM主机机器学习平台社区版(WMLz OSCE)
IBM主机机器学习平台Watson Machine Learning for z/OS是运行于z/OS 的端到端的机器学习平台,支持客户从模型的开发、部署到监控、持续自学习的全方位管理。在过去的几十年里,IBM主机一直是大规模关键交易系统的首选。IBM主机机器学习平台也l利用主机自身优势,在不影响关键业务吞吐量的情况下将AI推理融入客户的业务之中。这不仅仅包括传统的机器学习模型,也包括深度学习模型的推理。IBM主机机器学习平台的深度学习推理服务即基于IBM深度学习编译技术。IBM主机团队对DLC生成的代码对主机平台,特别是即将于2022年5月正式推出Telum处理器进行了针对性的优化。在强大的Telum处理器加持下,IBM主机机器学习平台可以支持高达每秒10万次以上的交易量而不影响核心系统交易的响应时间。
鉴于深度学习技术对大部分主机用户来说尚属新事物,IBM主机平台还推出了社区版本(IBM WMLz OSCE - Online Scoring Community Edition)供客户免费试用。社区版运行在IBM z/OS Container Extensions (zCX)中。简单来说,社区版以Docker Image的形式发布。只要客户拥有IBM zCX环境,就可以迅速将社区版部署到自己的zCX环境中,将模型以ONNX上传到社区版,得到REST接口并使用了。
下面就让我们看一下如何在2小时内利用IBM主机机器学习平台社区版上线反欺诈应用。
IBM OSCE 反欺诈实战
用户场景
某欧洲金融机构决定在其银行卡交易系统中部署反欺诈模型,从而尽早发现欺诈交易、避免客户和自身的损失,并且提高客户的满意度。该模型由该机构的数据科学家团队采用TensorFlow开发。由于客户的核心交易系统运行在IBM主机上,客户系统希望能够将模型的推理功能部署在核心交易系统中,从而减少网络延迟和复杂架构带来的不确定性。但是客户并不确定IBM主机是否能满足此功能。因此,客户决定试用IBM主机机器学习平台社区版。
第一步 下载IBM主机机器学习平台社区版
IBM主机机器学习平台社区版可以从下面的链接获取。
IBM Watson Machine Learning for z/OS - Overview | IBM
点击”Download trial code”即可获取社区版安装包。最新版本为1.1.0。
第二步 部署IBM主机机器学习平台社区版
您可参照下面的安装步骤安装和配置社区版。
首先在USS下解压安装包
pax -rvf ibm-wmlz-online-scoring-ce-s390x-v1.1.0.pax -ppx然后需修改用户profile,将Java, bash加入用户的路径并修改用户缺省Code Page设置
# Java environment variable
export JAVA_HOME=
# PATH
PATH=/bin:
PATH=$PATH://bash4.3
PATH=$PATH:"${JAVA_HOME}"/bin
export PATH="$PATH"
#LIBPATH
LIBPATH=/lib:/usr/lib
LIBPATH=$LIBPATH:"${JAVA_HOME}"/bin/classic
LIBPATH=$LIBPATH:"${JAVA_HOME}"/bin/j9vm
LIBPATH=$LIBPATH:"${JAVA_HOME}"/lib/s390x
export LIBPATH="$LIBPATH"
# Other system environment variables
export IBM_JAVA_OPTIONS="-Dfile.encoding=UTF-8"
export _BPXK_AUTOCVT=ON
export _BPX_SHAREAS=NO
export _ENCODE_FILE_NEW=ISO8859-1
export _ENCODE_FILE_EXISTING=UNTAGGED
export _CEE_RUNOPTS="FILETAG(AUTOCVT,AUTOTAG) POSIX(ON)" 在让新的用户profile生效后,即可通过./online-scoring-ce.sh脚本启动IBM主机机器学习平台社区版。
./online-scoring-ce.sh start
################################################################################################
### Starting online scoring community edition (OSCE) server in the specified zCX instance. ###
################################################################################################
Do you want to connect to zCX [email protected]:8022 (Y/N): y
Enter the port number of the OSCE server on zCX or press to use default port 8080:
Successfully started OSCE service on zCX.
Open your browser, copy and paste http://9.30.71.52:8080 into the address field, and launch the OSCE web interface with access token "3ad344d7-db41-4e52-97fe-8b9772727214". 更多详细步骤请参照用户手册wmlz_osce_userguide。用户手册可以与安装包在同一网址获取。
第三步 转换TensorFlow模型为ONNX格式
tf2onnx是一款可以将TensforFlow模型转换为ONNX格式的工具。tf2onnx可以从Pypi直接获取:
pip install -U tf2onnx假定我们要转换的TensforFlow模型被存储在/Users/wmlz/antifraud.tf,执行下面的命令即可将模型转换为onnx格式。
python -m tf2onnx.convert --saved-model /Users/wmlz/antifraud.tf --output antifraud.onnx第四步 上传ONNX模型至IBM主机机器学习平台社区版
打开浏览器,输入IBM主机机器学习平台社区版的地址,使用启动服务时生成的验证码登录用户界面。
使用用户界面上的“Import model”按钮将ONNX文件上传至机器学习平台。


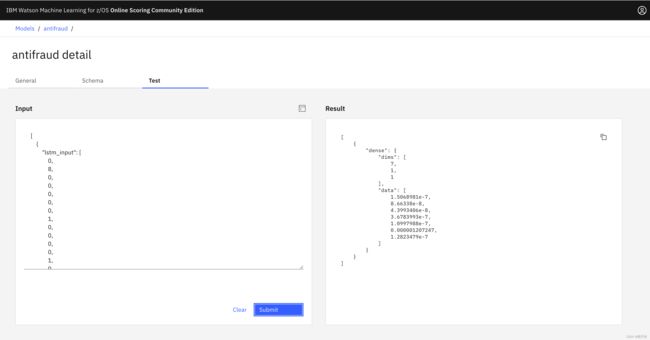
模型成功上传之后, 使用平台提供的测试页面即可很方便的测试模型的推理功能。
第五步 修改应用调用IBM主机机器学习平台社区版的推理服务
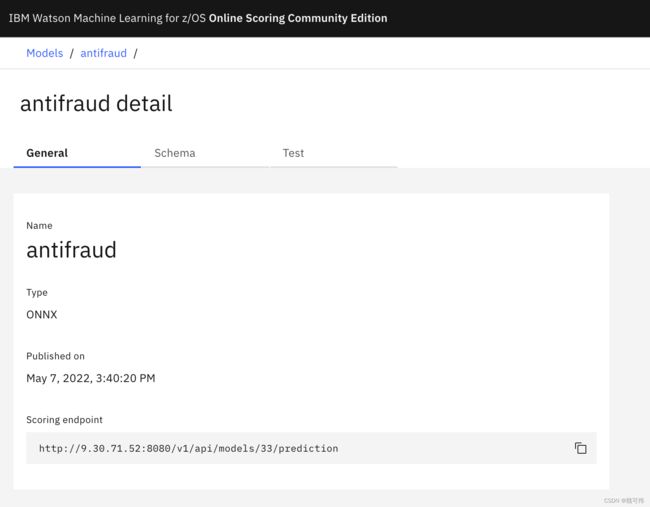
IBM主机机器学习平台社区版的推理服务以REST API的形式提供,针对每个导入的ONNX模型提供唯一的推理服务RESTful API。如下图所示,可通过页面的“Scoring endpoint”获取到我们刚刚部署的antifraud模型的推理服务API地址。
各种编程语言都提供了工具包与RESTful服务进行交互。下面是一段Python代码示意,使用requests模块请求调用API对所输入的记录进行推理预测。
import requests
score_url=’http://9.30.71.52:8080/v1/api/models/33/prediction’
req_auth=’f6b86e5d-1bf7-48e1-a276-28ab5899e3af’
score_request_header = {
'Authorization': req_auth,
"Content-Type": 'application/json'}
score_payload= [{"lstm_input": [0.0, 8.0, 0.0,…]}]
score_response = requests.post(score_url,
headers=score_request_header,
data=score_payload,
verify=False)通过处理推理服务的返回结果,即可实现对欺诈交易的实时侦测了。
作为IBM主机机器学习平台的社区版本,WMLz OSCE免费且易于安装配置。但是,和IBM主机机器学习平台的商业版本相比,社区版本还是有一些限制。例如社区版本并不提供高可用、版本管理等企业级应用所需的功能;同时可以部署的模型数量也有限制。如果您有在IBM Z关键应用中部署深度学习模型的需求,可以首先通过社区版本完成功能验证,再平滑过渡到企业版本。无论是对哪个版本有问题,都欢迎您和我们的开发团队联系讨论。
关于作者:
本文由IBM主机机器学习平台开发团队共同完成
魏可伟(Kewei Wei, [email protected]),IBM主机机器学习平台首席架构师,资深技术主管(Senior Technical Staff Member)
于爽(Shuang Yu,[email protected]),IBM主机机器学习平台资深架构师
时振宇(Zhenyu Shi, [email protected]),IBM主机机器学习平台资深软件工程师
符积高(Jigao Fu, [email protected]),IBM主机机器学习平台高级软件工程师