Explain你真的会用吗?
文章目录
-
- 前言
- 1. Explain的作用?
-
- 1.1 id
-
- 1.1.1 id相同
- 1.1.2 id不同
- 1.1.3 id有相同有不同
- 1.2 select_type
-
- 1.2.1 SIMPLE
- 1.2.2 PRIMARY
- 1.2.3 UNION RESULT
- 1.2.5 SUBQUERY
- 1.2.6 DEPENDENT SUBQUERY
- 1.2.8 DEPENDENT DERIVED
- 1.2.10 UNCACHEABLE SUBQUERY
- 1.2.11 UNCACHEABLE UNION
- 1.3 table
- 1.4 type
-
- 1.4.1 all(Full Table Scan)
- 1.4.2 index(Full Index Scan)
- 1.4.3 range
- 1.4.4 ref
- 1.4.5 eq_ref
- 1.4.6 const
- 1.5 possible_keys
- 1.6 key
- 1.7 key_len
- 1.8 ref
- 1.9 rows
- 1.10 filtered
- 1.11 Extra
- 小结
前言
- 环境:Mysql 8.0.21
- Mysql 版本不同 explain 执行结果会不相同
1. Explain的作用?
EXPLAIN语句提供有关MySQL如何执行语句的信息。EXPLAIN可以作用于SELECT、DELETE、INSERT、REPLACE和UPDATE语句。
explain 为 select 语句中使用的每个表返回一行信息。它按 mysql 在处理语句时读取的顺序列出输出的表。mysql 使用嵌套循环连接方法解析所有连接,这意味着 mysql 从第一个表中读取一行,然后在第二个表中、第三个表中找到匹配的行,依此类推。处理完所有表后,Mysql 输出所选列,并在表列表中回溯,直到找到一个有更多匹配行的表。从该表中读取下一行,并继续处理下一个表。
explain 输出列信息
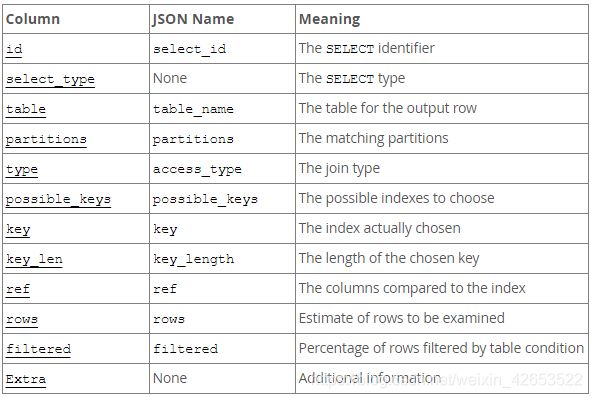
1.1 id
这是查询中 select 的序列号,如果该行引用其他行的并集结果,则该行可以为 Null
id 列的值代表着表的执行顺序,一共分为三种情况:
1.1.1 id相同
EXPLAIN SELECT
s.*,
t.*
FROM
student s,
teacher t

可以看到,explain 命令为 select 标识符语句中每个表生成了一行信息,其中 id 相同,代表着 两个表的执行顺序从上到下,与 sql 中执行的顺序无关。
1.1.2 id不同
EXPLAIN SELECT
*
FROM
teacher t
WHERE
id = ( SELECT s.tid FROM student s WHERE s.id = "2" )

嵌套子查询的两个表的执行顺序是不同的,所以 explain 解析出的查询信息 id 是不同的。其中,id 越大代表优先级越大,越先被执行。
1.1.3 id有相同有不同
EXPLAIN SELECT
s.id,
s.NAME,
c.id,
c.NAME
FROM
class c,
student s
WHERE
s.tid = (
SELECT
t.id
FROM
teacher t
WHERE
t.id = "1")

如果 id 有相同,可以认为是一组,从结果集中显示的顺序从上往下执行(与 SQL 中声明顺序无关);id 值越大,优先级越高,越先执行。
1.2 select_type
select 的类型,所有的情况见下表:

1.2.1 SIMPLE
简单查询,查询中不包含子查询或者union等任何复杂查询,点击见示例详情
1.2.2 PRIMARY
查询中若包含任何复杂的子查询,则最外层被标记为 primary,俗称:鸡蛋壳。点击见示例详情
1.2.3 UNION
EXPLAIN SELECT
`NAME`
FROM
tb_employees_china UNION
SELECT
`NAME`
FROM
tb_employees_usa

union 之后的 select 被标记为 union,而 union 前的 select 被标记为 primary;若 union 包含在 from 子句的子查询中,外层 select 将被标记为 derived
1.2.3 UNION RESULT
两种 union 合并的结果。详情见示例
1.2.4 DEPENDENT UNION
EXPLAIN SELECT
`NAME`
FROM
tb_employees_china
WHERE
`NAME` IN (
SELECT
`NAME`
FROM
tb_employees_china UNION
SELECT
`NAME`
FROM
tb_employees_usa
)

首先要满足 UNION 的条件,以及 union 中的第二个或以后的 select ,依赖于外部查询。
1.2.5 SUBQUERY
EXPLAIN SELECT
*
FROM
tb_employees_china
WHERE
id = (
SELECT
id
FROM
tb_employees_china
WHERE
`name` = "lisi"
)

子查询中的第一个 select 被标识为 subquery
1.2.6 DEPENDENT SUBQUERY
在子查询中的 select ,依赖于外部查询 点击见示例详情 此示例中子查询的第一个 select 被标识为 dependent subquery
1.2.7 DERIVED
在 from 子句中包含的子查询被标记为 derived ,mysql 会递归这些子查询,把结果放在临时表中(临时表会增加系统负担,但有时不得不用)。
注:此实例中,mysql 环境为:5.7
EXPLAIN SELECT
*
FROM
( SELECT id FROM tb_course tc ) temp

由于 Mysql 8.0 在 Mysql 5.7 基础上做了优化,上述实例在 8.0 版本环境 explain ,子查询是不会被标识为 derived 的,暂时没有找到 mysql 8.0 derived 的实例。(后续发现会做补充)
1.2.8 DEPENDENT DERIVED
在 derived 的基础上,依赖于外部查询。
1.2.9 MATERIALIZED
注:此实例中,mysql 环境为:5.7EXPLAIN SELECT
*
FROM
tb_class
WHERE
`NAME` IN (
SELECT
`NAME`
FROM
tb_class)

将子查询结果集中的记录保存到临时表的过程称之为物化(Materialize)。那个存储子查询结果集的临时表称之为物化表
在查询优化器执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询会被标识为 MATERIALIZED
执行计划的第三条记录的 id 值为2,说明该条记录最先被执行,并且是个单表查询,它被标识为 MATERIALIZED ,查询优化器是要把子查询先转换为物化表。执行计划的第二条记录,也就是id 为1,table 为
1.2.10 UNCACHEABLE SUBQUERY
无法缓存其结果的子查询,必须为外部查询的每一行重新计算结果
1.2.11 UNCACHEABLE UNION
union 中第二个或以后的 select ,属于不可缓存的子查询
1.3 table
输出行所引用的表的名称,除表名称外还有三种 case
:id值为 M 和 N 之间的并集,点击见详情实例 :id 值为 N 的派生表结果,点击见详情实例 :id 值为 N 的物化的子查询的结果,点击见详情实例
1.4 type
官方全称是"join type",意为:连接类型。Mysql 8.0 中 type 类型达到了12种,下面着重介绍常用的 6 种。从上到下,效率依次是增强的,我们应该尽量优化我们的 sql,使它的type尽量更优,当然还要综合考虑实际情况。
1.4.1 all(Full Table Scan)
全盘扫描,对表中的每行组合都执行一次完整的表扫描,如果表是第一个没有标记 const 的表,通常可以通过索引来避免 ALL,这些索引允许基于先前表中的常量值或列值从表中检索行。
ALL 是一种暴力和原始的查找方法,非常耗时低效。但Mysql官方介绍了一些情况可以使用ALL扫描:
- 该表很小,以至于执行表扫描要比打扰key查找快得多,对于少于10行且行长较短的表,是比较常见的
- 对于索引列,ON 或者 WHERE 子句中没有可用的限制
- 正在将索引列与常量值进行比较
- 正在通过另一列使用基数较低的键(许多行与键值匹配),这种情况下,Mysql假定通过使用键可能需要进行多次键查找,并且表扫描会更快。
对于小型表,表扫描通常是合适的,并且对于性能的影响可以忽略不计,对于大型表,一定要进行优化查询。
SELECT
*
FROM
`tb_employees_china`
WHERE
`name` = "zhangsan"

这是因为 name 列既不是主键也没有索引,所以采用全盘扫描的方式查找。
1.4.2 index(Full Index Scan)
index 与 all 都是全盘扫描,区别就是 index 扫描的是索引树,这种扫描根据索引回表取数据,和 all 相比,他们都是取得了全表的数据,而且 index 要先读索引而且要回表随机取数据,index 不会比 all 快。
SELECT
id
FROM
`tb_employees_usa`

而如果 type 为 index,并且 Extra 为 Using index ,如上图这种情况,就使用了覆盖索引,也就是无需回表,当前的索引树满足了当前的查询需求。
1.4.3 range
range指的是有范围的索引扫描,相对于 index的索引扫描,它有范围限制,因此要优于 index,range一定是基于索引的,一般常见的范围查找:between...and,<,>,in ,or 都属于索引范围扫描。
1.4.4 ref
出现该连接类型的条件是,查找条件列使用了索引而且不为主键和 Unique,也就是使用了普通索引,而非主键索引和唯一索引。这样,即使使用索引快速查找到了第一条数据,也不能停止扫描,要进行目标值附近的小范围扫描,好处是不需要扫全表,因为索引是有序的,即使有重复值,也是一个非常小的范围内扫描。
将以下表中 tb_employees_usa 中 name 字段新建索引后执行以下语句。
explain select * from tb_employees_usa where `name` = 'rose';
![]()
1.4.5 eq_ref
eq_ref 与 ref 相比厉害的地方在于,eq_ref 知道这种类型的查找结果集只有一个,只有使用了主键或者唯一索引进行查找的情况,结果集才会是一个。在查找前就已经知道结果集一定只有一个,所以,当首次查找到值时,就立即停止了查询。这种连接类型每次都进行着精确查询,无需过多的扫描,因此查找效率更高。
select * from tb_employees_usa join tb_employees_china using(id);

1.4.6 const
通常情况下,如果将一个主键放置到 where 子句作为查询条件,MySQL 优化器会把这个查询优化为一个常量,也就是 const
select * from tb_employees_usa where `id` = '3';
![]()
1.5 possible_keys
查询可能使用到的索引都会在这里列出来
1.6 key
查询真正使用到的索引
1.7 key_len
key_len 表示使用的索引长度,key_len可以衡量索引的好坏,key_len越小索引效果越好,那么 key_len 长度是如何计算的呢?
| 列类型 | 是否为空 | 长度 | key_len | 备注 |
|---|---|---|---|---|
| tinyint | 允许Null | 1 | key_len = 1+1 | 允许NULL,key_len长度加1 |
| tinyint | 不允许Null | 1 | key_len = 1 | 不允许NULL |
| int | 允许Null | 4 | key_len = 4+1 | 允许NULL,key_len长度加1 |
| int not null | 不允许Null | 4 | key_len = 4 | 不允许NULL |
| bigint | 允许Null | 8 | key_len = 8+1 | 允许NULL,key_len长度加1 |
| bigint not null | 不允许Null | 8 | key_len = 8 | 不允许NULL |
| char(1) | 允许Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 1*3 + 1 | 允许NULL,字符集utf8,key_len长度加1 |
| char(1) not null | 不允许Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 1*3 | 不允许NULL,字符集utf8 |
| varchar(10) | 允许Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 10*3 + 2 + 1 | 动态列类型,key_len长度加2,允许NULL,key_len长度加1 |
| varchar(10) not null | 不允许Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 10*3+ 2 | 动态列类型,key_len长度加2 |
拿我们上述的执行计划来看,计算一个索引的长度。

其中,索引名称为 idx_name 的索引类型是 varchar(30),根据上述图表得知,varchar(30) key_len 为:30*3+2+1 = 93
key_len还可用于判断联合索引是否生效以及覆盖了哪个联合索引,我们举个实例来看。
我们将 tb_employees_usa 表的索引全部删除,新建联合索引 (name,age)

执行以下SQL,查看执行计划
explain select * from tb_employees_usa where name='rose';
![]()
key_len 值为93,经计算,此 SQL 使用了联合索引其中的单个索引 name
再执行如下SQL,查看执行计划
EXPLAIN SELECT
*
FROM
tb_employees_usa
WHERE
`name` = 'rose'
AND age = 2;
![]()
key_len 值为98,经计算,此 SQL 使用了联合索引。
1.8 ref
ref字段的值是列或者常数,指的是这个列或常数与 key 的值一起从表中选择行数据。如上述实例
select * from tb_employees_usa join tb_employees_china using(id);
ref 字段值为 test.tb_employees_usa.id,代表 tb_employees_usa 的 id 列与 tb_employees_china 的主键一起筛选行数据。
如 where 子句中条件是等值常量,则 ref 值为 const
1.9 rows
用来表示在SQL执行过程中会被扫描的行数,该数值越大,意味着需要扫描的行数,相应的耗时更长。但是需要注意的是EXPLAIN 中输出的 rows 只是一个估算值,不能完全对其百分之百相信。
1.10 filtered
表示存储引擎返回的数据在 server 层过滤后,剩下多少满足查询的记录数量的比例,此值是百分比,不是具体记录数量。
1.11 Extra
性能从好到坏排列:
using index > using where > using temporary > using filesort
using index:表示覆盖索引,不需要回表操作using where:列数据是从仅仅使用了using temporary:表示 MySQL 需要使用临时表来存储结果集,常见于排序和分组查询using filesort:MySQL 中无法利用索引完成的排序操作称为“文件排序”,一般有此值建议使用索引进行优化using join buffer:强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果,如果出现此值,应该根据具体情况添加索引来改进性能distinct:在select部分使用了distinc关键字
小结
本文介绍了 EXPLAIN 中各个字段的代表含义,如对 MySQL 感兴趣可继续关注 MySQL 专栏。