2021高通AI应用创新大赛-创新赛道-垃圾分类识别 第三次会议研讨
GT 第三次会议研讨
一、较为详细的流程教程:
极市平台2020教程‘
debug平台训练及模型转换代码示例
关于模型训练测试等过程积分消耗
我们跑一个epoch 一共有220个iteration (batchsize=128的情况下),我看了下resnet18 10个iteration需要30s 一个epoch得11min 所以我估计epoch不能很大,否则我们积分消耗会过快,我目测了一下后面做dlc转换的时候一下就是100积分
二、目前进展:
1. 训练
-
已完成构建训练镜像并进行了epoch=50 以经典的resnet18为基础的网络训练;暂存的模型存储于2021428model中,名称为2021.04.29_model_resnet18.pkl id 1375

-
关于训练部分的详细流程:
前提使我们已经push了我们的代码,并在本地检查过可以运行模型注意push的时候把本地运行的路径一定要改过来
在线编码页面中,点击**构建训练镜像,进行训练代码真实运行环境的构建。构建完成后,进入开发环境中的对应赛题,点击发起训练。平台构建训练环境的依据是您在线编码目录/project/train/src_repo/下的Dockerfile文件内容。点击新建训练任务按钮,并且输入您的训练代码在linux**系统里执行的终端命令,比如bash /project/train/src_repo/start_train.sh

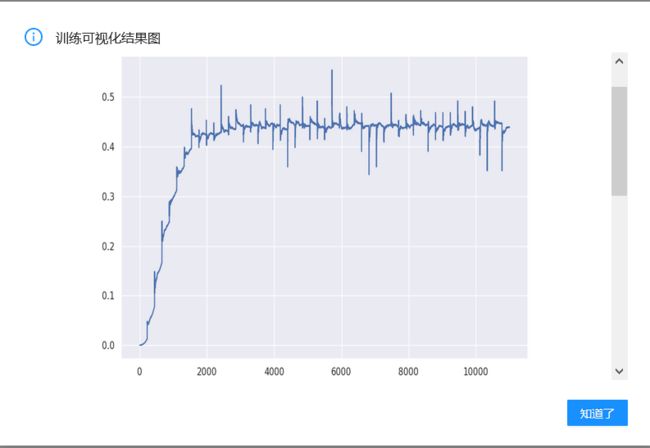
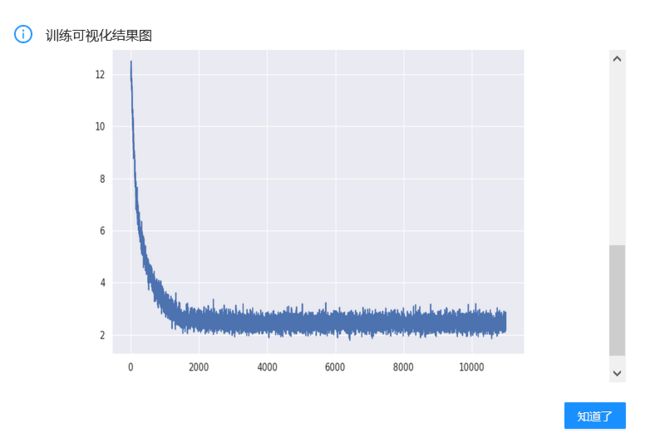
在trash_resnet.py中已经写了根据平台plot_tool.update_plot()的函数可以实现最后acc和loss曲线的生成,如果还有其他的去求可以添加或者直接print出来

注意主要的模型修改可以在下述.py中进行,也可以写个new_net.py之后我们Import进来
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("use device :{}".format(device))
#设置随机种子
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1)
# 参数设置
MAX_EPOCH = 50
BATCH_SIZE = 128
LR = 0.001
log_interval = 20
start_epoch = -1
lr_decay_step = 7
# step 1/5 数据
# 获取数据集文件夹下的类别文件夹名称赋值为type_list
train_dir = '../../../../home/data/'
num_classes = os.listdir(train_dir)
train_dir = os.path.join(train_dir,num_classes[0])
# 仅用于编码测试
type_lst = os.listdir(train_dir)
classes = type_lst
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = TrashDataset(data_dir = train_dir,transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# step 2/5 构建模型
resnet18 = models.resnet18()
resnet18.cuda()
#加载参数
path_pretrained_model = ("models/resnet18.pth")
state_dict_load = torch.load(path_pretrained_model)
resnet18.load_state_dict(state_dict_load)
#step 3/5 损失函数
criterion = nn.CrossEntropyLoss()
#step 4/5 优化器
flag = 0
# flag = 1
if flag:
fc_params_id = list(map(id, resnet18.fc.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0}, # 0
{'params': resnet18.fc.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(resnet18.parameters(), lr=LR, momentum=0.9)
fc_params_id = list(map(id, resnet18.fc.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0}, # 0
{'params': resnet18.fc.parameters(), 'lr': LR}], momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1)
#step 5/5 训练
train_curve = list()
train_acc = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
resnet18.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet18(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
train_acc.append(correct / total)
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
# if flag_m1:
print("epoch:{} conv1.weights[0, 0, ...] :\n {}".format(epoch, resnet18.conv1.weight[0, 0, ...]))
scheduler.step() # 更新学习率
print('train finish!')
#获取当前时间
t = time.strftime('%Y.%m.%d',time.localtime(time.time()))
# path_model = '../models/2021428models/{}_model_resnet18.pkl'.format(t)
path_model = './models/2021429_model_resnet18.pkl'
# 保存整个模型
torch.save(resnet18, path_model)
#将绘制的曲线图进行可视化
def save_plot(train_curve,train_acc):
train_x = list(range(len(train_curve)))
train_loss = np.array(train_curve)
train_acc = np.array(train_acc)
train_iters = len(train_loader)
fig_loss = plt.figure(figsize = (10,6))
plt.plot(train_x, train_loss)
plot_tool.update_plot(name='loss', img=plt.gcf())
fig_loss.savefig('../result-graphs/loss.png')
fig_acc = plt.figure(figsize = (10,6))
plt.plot(train_x, train_acc)
plot_tool.update_plot(name='acc', img=plt.gcf())
fig_acc = plt.gcf()
fig_acc.savefig('../result-graphs/acc.png')
print('acc-loss曲线绘制已完成')
# save_plot(train_curve,train_acc)
2.自动测试
为了顺利运行测试任务,我们首先得保证测试代码在本地是畅通的。
- 模型转换
#!/bin/bash
# 在这里编写OpenVINO模型转换
# 系统会将所选择的原始模型放在目录/usr/local/ev_sdk/model下,转换后的OpenVINO模型请放在model/openvino目录下,
# 建议所有路径都使用绝对路径
# 获取当前脚本的绝对路径
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
source /opt/snpe/snpe_venv/bin/activate
# step 0:prepare
pip install onnx
pip install protobuf --upgrade
pip install opencv-python
# step 1:to_onnx
#commit version
python3.6 /usr/local/ev_sdk/src/to_onnx.py
# local version
# python3.6 /project/ev_sdk/src/to_onnx.py
# step 2:generate file_list.txt
# commit version
mkdir /usr/local/ev_sdk/pic
mkdir /usr/local/ev_sdk/raw
wget -O /usr/local/ev_sdk/pic/0.jpg https://www.baidu.com/img/bd_logo1.png
# local version
# mkdir /project/ev_sdk/pic
# mkdir /project/ev_sdk/raw
# wget -O /usr/local/ev_sdk/pic/0.jpg https://www.baidu.com/img/bd_logo1.png
# commit version
python3.6 /usr/local/ev_sdk/src/create_raws.py -i /usr/local/ev_sdk/pic -d /usr/local/ev_sdk/raw -s 224
python3.6 /usr/local/ev_sdk/src/create_list.py -i /usr/local/ev_sdk/raw -e *.raw
# local version
# python3.6 /project/ev_sdk/src/create_raws.py -i /project/ev_sdk/pic -d /project/ev_sdk/raw -s 224
# python3.6 /project/ev_sdk/src/create_list.py -i /project/ev_sdk/raw -e *.raw
# step 3:generate dlc
# commit version
snpe-onnx-to-dlc --input_network /usr/local/ev_sdk/model/model_resnet18.onnx --output_path /usr/local/ev_sdk/model/model_resnet18.dlc -d input 1,3,224,224 && echo "snpe-onx-to-dlc done"
snpe-dlc-quantize --input_dlc /usr/local/ev_sdk/model/model_resnet18.dlc --output_dlc /usr/local/ev_sdk/model/model_resnet18.dlc --input_list /usr/local/ev_sdk/model/file_list.txt --input_dlc --enable_htp && echo 'snpe-dlc-quantize done'
# # local version
# snpe-onnx-to-dlc --input_network /project/ev_sdk/model/model_resnet18.onnx --output_path /project/ev_sdk/model/model.dlc -d input 1,3,224,224 && echo "snpe-onx-to-dlc done"
# snpe-dlc-quantize --input_dlc /project/ev_sdk/model/model.dlc --output_dlc /project/ev_sdk/model/model_quantized.dlc --input_list /project/ev_sdk/model/file_list.txt --input_dlc --enable_htp && echo 'snpe-dlc-quantize done'
# local version
# rm /project/ev_sdk/model/model.dlc
# commit version
rm /usr/local/ev_sdk/model/model.dlc
**step 1:**我的代码是用pytorch写的,要先转为onnx才可以转为dlc。所以写了一个转onnx的python代码。(仅供参考)
在本地测试的时候,我是把本地训练产生的模型直接copy到ev_sdk/model文件夹下了。
import torch
import torch.onnx
#乾哥这个已经编译好了不用改了
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
m_path = '/usr/local/ev_sdk/model/2021.04.29_model_resnet18.pkl'
model = torch.load(m_path)
dummy_input1 = torch.randn(146,3,224,224).to(device)
input_names = [ "input"]
output_names = [ "output1" ]
# torch.onnx.export(model, dummy_input1,"/usr/local/ev_sdk/model/model_resnet18.onnx", verbose=True,input_names=input_names,output_names=output_names)
torch.onnx.export(model, dummy_input1,"/usr/local/ev_sdk/model/model_resnet18.onnx", verbose=True,input_names=input_names,output_names=output_names)
print('to_onnx is finish!')
**step 2:**生成file_list。大家可以在step 3 中看到,有一个参数是–input_list ,我们这一步就是为其生成一个文件。
大家可以看到我先建了一个文件夹,一个是pic,一个是raw。
然后下载了一张图片到pic文件夹中。为什么下载而不用/home/data/里面的图片呢?是因为平台在执行测试任务的时候没有/home/data 这个文件夹,用不了啊。我随便下了一张进行测试(是度娘的logo)。
接下来执行create_raws.py(这个是从/opt/snpe/models/Inception v3/scripts/ 里copy过来的),它的目的是将参数(-i)这个文件夹里面的内容转换为 (.raw)文件并输出到参数(-d)文件夹,参数-s是指你要将图片resize的大小,要跟你模型的输入大小匹配。 大家可以根据需要对代码进行修改,保证raw文件的维度正确。
最后一步就是运行create_list.py(跟create_raws.py同一个位置copy过来的)将raw文件夹里面内容生成一个file_list文件,这个文件的内容是.raw文件的绝对路径。参数-i 就是说raw文件保存的位置,参数-e是指具体的文件类型,这个参数的默认值是.jpg。
create_craw.py
import argparse
import numpy as np
import os
from PIL import Image
RESIZE_METHOD_ANTIALIAS = "antialias"
RESIZE_METHOD_BILINEAR = "bilinear"
def __get_img_raw(img_filepath):
img_filepath = os.path.abspath(img_filepath)
img = Image.open(img_filepath)
img_ndarray = np.array(img) # read it
if len(img_ndarray.shape) != 3:
raise RuntimeError('Image shape' + str(img_ndarray.shape))
if (img_ndarray.shape[2] != 3):
raise RuntimeError('Require image with rgb but channel is %d' % img_ndarray.shape[2])
# reverse last dimension: rgb -> bgr
return img_ndarray
def __create_mean_raw(img_raw, mean_rgb):
if img_raw.shape[2] != 3:
raise RuntimeError('Require image with rgb but channel is %d' % img_raw.shape[2])
img_dim = (img_raw.shape[0], img_raw.shape[1])
mean_raw_r = np.empty(img_dim)
mean_raw_r.fill(mean_rgb[0])
mean_raw_g = np.empty(img_dim)
mean_raw_g.fill(mean_rgb[1])
mean_raw_b = np.empty(img_dim)
mean_raw_b.fill(mean_rgb[2])
# create with c, h, w shape first
tmp_transpose_dim = (img_raw.shape[2], img_raw.shape[0], img_raw.shape[1])
mean_raw = np.empty(tmp_transpose_dim)
mean_raw[0] = mean_raw_r
mean_raw[1] = mean_raw_g
mean_raw[2] = mean_raw_b
# back to h, w, c
mean_raw = np.transpose(mean_raw, (1, 2, 0))
return mean_raw.astype(np.float32)
def __create_raw_incv3(img_filepath, mean_rgb, div, req_bgr_raw, save_uint8):
img_raw = __get_img_raw(img_filepath)
mean_raw = __create_mean_raw(img_raw, mean_rgb)
snpe_raw = img_raw - mean_raw
snpe_raw = snpe_raw.astype(np.float32)
# scalar data divide
snpe_raw /= div
if req_bgr_raw:
snpe_raw = snpe_raw[..., ::-1]
if save_uint8:
snpe_raw = snpe_raw.astype(np.uint8)
else:
snpe_raw = snpe_raw.astype(np.float32)
img_filepath = os.path.abspath(img_filepath)
filename, ext = os.path.splitext(img_filepath)
snpe_raw_filename = filename
snpe_raw_filename += '.raw'
snpe_raw.tofile(snpe_raw_filename)
return 0
def __resize_square_to_jpg(src, dst, size,resize_type):
src_img = Image.open(src)
# If black and white image, convert to rgb (all 3 channels the same)
if len(np.shape(src_img)) == 2: src_img = src_img.convert(mode = 'RGB')
# center crop to square
width, height = src_img.size
short_dim = min(height, width)
crop_coord = (
(width - short_dim) / 2,
(height - short_dim) / 2,
(width + short_dim) / 2,
(height + short_dim) / 2
)
img = src_img.crop(crop_coord)
# resize to inceptionv3 size
if resize_type == RESIZE_METHOD_BILINEAR :
dst_img = img.resize((size, size), Image.BILINEAR)
else :
dst_img = img.resize((size, size), Image.ANTIALIAS)
# save output - save determined from file extension
dst_img.save(dst)
return 0
def convert_img(src,dest,size,resize_type):
print("Converting images for resnet 18 network.")
print("Scaling to square: " + src)
for root,dirs,files in os.walk(src):
for jpgs in files:
src_image=os.path.join(root, jpgs)
if('.jpg' in src_image):
print(src_image)
dest_image = os.path.join(dest, jpgs)
__resize_square_to_jpg(src_image,dest_image,size,resize_type)
print("Image mean: " + dest)
for root,dirs,files in os.walk(dest):
for jpgs in files:
src_image=os.path.join(root, jpgs)
if('.jpg' in src_image):
print(src_image)
mean_rgb=(128,128,128)
__create_raw_incv3(src_image,mean_rgb,128,False,False)
def main():
parser = argparse.ArgumentParser(description="Batch convert jpgs",formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('-d', '--dest',type=str, required=True)
parser.add_argument('-s','--size',type=int, default=299)
parser.add_argument('-i','--img_folder',type=str, required=True)
parser.add_argument('-r','--resize_type',type=str, default=RESIZE_METHOD_BILINEAR,
help='Select image resize type antialias or bilinear. Image resize type should match '
'resize type used on images with which model was trained, otherwise there may be impact '
'on model accuracy measurement.')
args = parser.parse_args()
size = args.size
# src = args.img_folder
src = os.path.abspath(args.img_folder)
dest = os.path.abspath(args.dest)
resize_type = args.resize_type
assert resize_type == RESIZE_METHOD_BILINEAR or resize_type == RESIZE_METHOD_ANTIALIAS, \
"Image resize method should be antialias or bilinear"
convert_img(src,dest,size,resize_type)
if __name__ == '__main__':
exit(main())
create_list.py
import argparse
import glob
import os
def create_file_list(input_dir, output_filename, ext_pattern, print_out=False, rel_path=False):
input_dir = os.path.abspath(input_dir)
output_filename = os.path.abspath(output_filename)
output_dir = os.path.dirname(output_filename)
if not os.path.isdir(input_dir):
raise RuntimeError('input_dir %s is not a directory' % input_dir)
if not os.path.isdir(output_dir):
raise RuntimeError('output_filename %s directory does not exist' % output_dir)
glob_path = os.path.join(input_dir, ext_pattern)
file_list = glob.glob(glob_path)
if rel_path:
file_list = [os.path.relpath(file_path, output_dir) for file_path in file_list]
if len(file_list) <= 0:
if print_out: print('No results with %s' % glob_path)
else:
with open(output_filename, 'w') as f:
f.write('\n'.join(file_list))
if print_out: print('%s created listing %d files.' % (output_filename, len(file_list)))
def main():
parser = argparse.ArgumentParser(description="Create file listing matched extension pattern.",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('-i', '--input_dir',
help='Input directory to look up files.',
default='.')
parser.add_argument('-o', '--output_filename',
help='Output filename - will overwrite existing file.',
default='file_list.txt')
parser.add_argument('-e', '--ext_pattern',
help='Lookup extension pattern, e.g. *.jpg, *.raw',
default='*.jpg')
parser.add_argument('-r', '--rel_path',
help='Listing to use relative path',
action='store_true')
args = parser.parse_args()
create_file_list(args.input_dir, args.output_filename, args.ext_pattern, print_out=True, rel_path=args.rel_path)
if __name__ == '__main__':
main()
**step 3:**生成dlc
有一个要注意的点是这个-d参数它的输出是 两个值,一个是输入节点名称,一个是大小。输入节点名称要跟onnx的一样,然后确保输入的大小正确(pytorch是NCHW)。
编写ji.py(目前还有问题,仍旧是调用gpu)
from __future__ import print_function
import logging as log
import logging
import json
import os
import torch
import cv2
import numpy as np
log.basicConfig(level = log.DEBUG)
f = open('class.txt','r')
a = f.read()
label_id_map = eval(a)
f.close()
logging.info(label_id_map)
print('logging is finish!')
# def init():
# # save_model = "/usr/local/ev_sdk/model/"
# # save_model = "/project/ev_sdk/models/"
# if not os.path.isfile(save_model):
# log.error(f"{model_pb_path} does not exist")
# m_path = '/usr/local/ev_sdk/model/2021429_model_resnet18.pkl'
# model = torch.load(m_path)
# log.info('Initializing model...')
# model = model.cuda()
# return model
# def process_image(net,input_image,args=None):
# img = cv2.resize(input_image,(256,256)).astype(np.float32)
# img = img.transpose(2,0,1)
# img = cv2.normalize(img,None)
# img = torch.tensor([img]).cuda()
# output = net(input_image)
# data = {'class':label_id_map[int(output[0])]}
# return json.dumps(data, indent=4)
def init():
os.system("bash /usr/local/ev_sdk/src/convert_model.sh")
path = "/usr/local/ev_sdk/src"
if not os.path.exists(os.path.join(path,"pic")):
os.makedirs(os.path.join(path,"pic"))
if not os.path.exists(os.path.join(path,"raw")):
os.makedirs(os.path.join(path,"raw"))
if not os.path.exists(os.path.join(path,"output")):
os.makedirs(os.path.join(path,"output"))
save_model = "/usr/local/ev_sdk/model/model_resnet18.dlc"
return save_model
def process_image(save_model,input_image,args=None):
cv2.imwrite("/usr/local/ev_sdk/src/pic/0.jpg",input_image)
convert_img("/usr/local/ev_sdk/src/pic/","/usr/local/ev_sdk/src/raw/",224,RESIZE_METHOD_BILINEAR)
cmd = ['snpe-net-run',
'--input_list', "/usr/local/ev_sdk/src/input_list.txt",
'--container',"/usr/local/ev_sdk/model/model_resnet18.dlc",
'--output_dir',"/usr/local/ev_sdk/src/output"]
# '--output_dir',"/usr/local/ev_sdk/src/output","--use_dsp","--platform_options", "unsignedPD:ON"]
subprocess.call(cmd)
# assert os.path.exists("/usr/local/ev_sdk/src/output/Result_0/output1.raw")
float_array = np.fromfile("/usr/local/ev_sdk/src/output/Result_0/output1.raw", dtype=np.float32) ## 读取这个文件内容
max_prob = max(float_array)
max_prob_index = np.where(float_array == max_prob)[0][0]
data = {'class':label_id_map[max_prob_index]}
return json.dumps(data, indent=4)
if __name__ == '__main__':
"""Test python api
"""
# img = cv2.imread('/usr/local/ev_sdk/data/dog.jpg')
img = np.random.randn(224,224,3)
predictor = init()
result = process_image(predictor, img)
logging.info(result)
重点是执行了snpe-net-run,它的输入是一个list文件,里面是raw文件的路径,container是模型位置,output_dir是输出文件的位置。最后从输出文件里读取结果。这个版本测试一次消耗了100个积分,并且成绩跟上一个版本完全一样,用的gpu。
三、进一步工作的计划
- 五一期间修改一版新的网络替换resnet18,首先通过本地的测试,(目前我手头有10分类的图像数据,验证网络在性能,train的时间和准确率上都能够优于resnet18(如果在这个数据集上也可,泛化能力也理应有更好的体现)
- 为了更快的实现网络迭代更新,五一收假的那一天我们集中讨论一下各自看到文献,归纳出其有价值的点,最好能够在经典的mnist或者cifar10上面复现;
- 着力解决性能方面的问题,目前还没有解决gpu to dsp的问题,性能分会大打折扣。