UNETR 医学图像分割架构 2D版 (Tensorflow2 Keras 实现UNETR)
文章目录
- 前言
- 一、UNETR网络结构
- 二、代码
-
- 1.引入库
- 2.辅助函数和自定义keras层
- 3.构建Vision Transformer
- 4.构建完整UNETR
- 5.简单测试
前言
现在在尝试各种网络做医学图像分割,这算是我第一次开始尝试Transformer-CNN的图像分割方法。首先想试试这个用完整Vision Transformer(ViT)做编码器的UNETR,可惜这次网上甚至找不到公开的Tensorflow版代码了,无奈只能自己动手试(缝)试(合),日常抛砖引玉。
这次实现的是2D图像分割版本。不过要转成3D的也很简单,ViT本身对图片维度也不敏感,CNN部分把二维卷积换三维就完事儿了。
文献:UNETR: Transformers for 3D Medical Image Segmentation
参考代码:1. Keras官方示例:Transformer图像分类
2. GitHub用户tamasino52的非官方Pytorch实现
一、UNETR网络结构
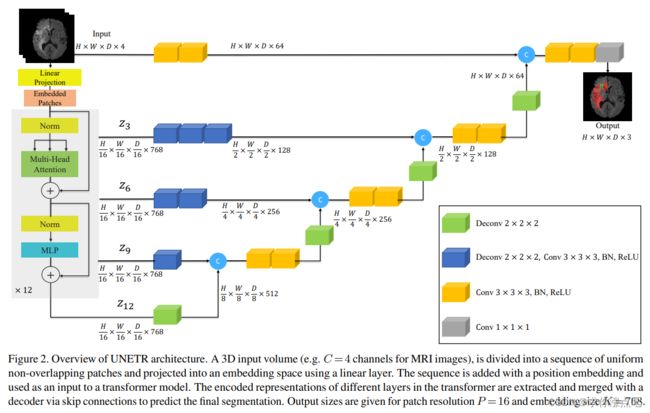
UNETR的完整结构如上,感觉和U-Net相比,最主要的变化就是编码器换成了类似Vision Transformer 16 Base的结构,其它的改变基本都是因此而生的。比如说,由于ViT的输出是固定的patches大小([H/p, W/p, D/p], p=patch_size),导致UNETR中类似“跳跃连接”的部分必须使用连续的反卷积恢复特征图分辨率(图中蓝色块),随后再传输到传统U-Net的解码器层(图中黄色块)。
完整的ViT架构和额外添加的诸多卷积块导致UNETR的参数量骤增,达到92M(UNETR论文中表示nn-UNet为19M),但效果确实是好的,现在已经成了很多3D医学图像分割任务的对比方法了。
二、代码
- 本人Tensorflow版本2.8.0,建议2.5.0以上使用。
- 如果没有安装tensorflow_addons,注释掉相关语句就可以
1.引入库
代码如下:
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import keras
import keras.backend as K
from keras.layers import (Layer, BatchNormalization, LayerNormalization, Conv2D, Conv2DTranspose, Embedding,
Activation, Dense, Dropout, MultiHeadAttention, add, Input, concatenate, GlobalAveragePooling1D)
from keras.models import Model
2.辅助函数和自定义keras层
mlp, Patches 和 PatchEncoder 代码来自keras的Code Example
def mlp(x, hidden_units, dropout_rate):
if not isinstance(hidden_units, list): hidden_units = [hidden_units]
for units in hidden_units:
x = Dense(units, activation=tf.nn.gelu)(x)
x = Dropout(dropout_rate)(x)
return x
class Patches(Layer):
'''
提取图像块并序列化
[B, H, W, C]
-> [B, H/patch_size, W/patch_size, C*(patch_size^2)]
-> [B, H*W/(patch_size^2), C*(patch_size^2)]
'''
def __init__(self, patch_size):
super(Patches, self).__init__()
self.patch_size = patch_size
def call(self, images):
batch_size = tf.shape(images)[0]
patches = tf.image.extract_patches(
images = images,
sizes=[1, self.patch_size, self.patch_size, 1],
strides=[1, self.patch_size, self.patch_size, 1],
rates=[1, 1, 1, 1],
padding='VALID',
)
patch_dims = patches.shape[-1]
patches = tf.reshape(patches, [batch_size, -1, patch_dims])
return patches
class PatchEncoder(Layer):
'''
将图块线性投影到projection_dim
并且为图块引入一个可学习的位置嵌入
'''
def __init__(self, num_patches, projection_dim):
super(PatchEncoder, self).__init__()
self.num_patches = num_patches
self.projection = Dense(units=projection_dim)
self.position_embeding = Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = tf.range(start=0, limit=self.num_patches, delta=1)
encoded = self.projection(patch) + self.position_embeding(positions)
return encoded
def normalization(input_tensor, normalization, name=None):
if normalization=='batch':
return(BatchNormalization(name=None if name is None else name + '_batchnorm')(input_tensor))
elif normalization=='layer':
return(LayerNormalization(epsilon=1e-6, name=None if name is None else name + '_layernorm')(input_tensor))
elif normalization=='group':
return(tfa.layers.GroupNormalization(groups=8, name=None if name is None else name + '_groupnorm')(input_tensor))
elif normalization == None:
return input_tensor
else:
raise ValueError('Invalid normalization')
def conv_norm_act(input_tensor, filters, kernel_size , norm_type='batch', act_type='relu', dilation=1):
'''
Conv2d + Normalization(norm_type:str) + Activation(act_type:str)
'''
output_tensor = Conv2D(filters, kernel_size, padding='same', dilation_rate=(dilation, dilation), use_bias=False if norm_type is not None else True, kernel_initializer='he_normal')(input_tensor)
output_tensor = normalization(output_tensor, normalization=norm_type)
if act_type is not None: output_tensor = Activation(act_type)(output_tensor)
return output_tensor
def conv2d_block(input_tensor, filters, kernel_size,
norm_type, use_residual, act_type='relu',
double_features = False, dilation=[1, 1], name=None):
x = Conv2D(filters, kernel_size, padding='same', dilation_rate=dilation[0], use_bias=False, kernel_initializer='he_normal', name=None if name is None else name + '_conv2d_0')(input_tensor)
x = normalization(x, norm_type, name=None if name is None else name + '_0')
x = Activation(act_type, name=None if name is None else name + act_type + '_0')(x)
if double_features:
filters *= 2
x = Conv2D(filters, kernel_size, padding='same', dilation_rate=dilation[1], use_bias=False, kernel_initializer='he_normal', name=None if name is None else name + '_conv2d_1')(x)
x = normalization(x, norm_type, name=None if name is None else name + '_1')
if use_residual:
if K.int_shape(input_tensor)[-1] != K.int_shape(x)[-1]:
shortcut = Conv2D(filters, kernel_size=1, padding='same', use_bias=False, kernel_initializer='he_normal', name=None if name is None else name + '_shortcut_conv2d')(input_tensor)
shortcut = normalization(shortcut, norm_type, name=None if name is None else name + '_shortcut')
x = add([x, shortcut])
else:
x = add([x, input_tensor])
x = Activation(act_type, name=None if name is None else name + act_type + '_0')(x)
return x
def deconv_conv_block(x,
filters_list: list,
kernel_size,
norm_type,
act_type,
):
'''
对应UNETR结构图中的蓝色块
'''
for filts in filters_list:
x = Conv2DTranspose(filts, 2, (2, 2), kernel_initializer='he_normal')(x)
x = conv_norm_act(x, filts, kernel_size, norm_type, act_type)
return x
def conv_deconv_block(x,
filters,
kernel_size,
norm_type,
use_residual,
act_type,
):
'''
对应UNETR结构图中的黄色+绿色块
'''
x = conv2d_block(x, filters, kernel_size, norm_type, use_residual, act_type)
x = Conv2DTranspose(filters // 2, 2, (2, 2), kernel_initializer='he_normal')(x)
return x
3.构建Vision Transformer
这一部分也是来自keras的Code Example,主要是去掉了分类头,并且增添了要在特定层输出“跳跃连接”的部分,源码中的注释我基本都保留了。
def create_vit(x,
patch_size,
num_patches,
projection_dim,
num_heads,
transformer_units,
transformer_layers,
dropout_rate,
extract_layers,
):
skip_connections = []
# Create patches.
patches = Patches(patch_size)(x)
# Encode patches.
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for layer in range(transformer_layers):
# Layer normalization 1.
x1 = LayerNormalization(epsilon=1e-6)(encoded_patches)
# Create a multi-head attention layer.
attention_output = MultiHeadAttention(
num_heads=num_heads, key_dim=projection_dim//num_heads, dropout=dropout_rate
)(x1, x1)
# Skip connection 1.
x2 = add([attention_output, encoded_patches])
# Layer normalization 2.
x3 = LayerNormalization(epsilon=1e-6)(x2)
# MLP.
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=dropout_rate)
# Skip connection 2.
encoded_patches = add([x3, x2])
if layer + 1 in extract_layers:
skip_connections.append(encoded_patches)
return skip_connections
4.构建完整UNETR
def build_model(# ↓ Base arguments
input_shape = (256, 256, 3),
class_nums = 5,
# ↓ ViT arguments
patch_size = 16,
projection_dim = 768,
num_heads = 12,
transformer_units = [2048, 768],
transformer_layers = 12,
extract_layers = [3, 6, 9, 12],
dropout_rate = 0.1,
# ↓ Conv arguments
kernel_size = 3,
conv_norm = 'batch',
conv_act = 'relu',
use_residual = False,
# ↓ Other arguments
show_summary = True,
output_act = 'auto',
):
'''
input_shape: tuple, (height, width, channel) 注意这是2D分割
class_nums: int, 输出通道数
patch_size: int, 图像分块尺寸
projection_dim: int, ViT中的投影维度
num_heads: int, 多头注意力的头数
transformer_units: list, ViT中MLP模块的隐藏层数,注意是列表形式
transformer_layers: int, Transformer的堆叠层数
extract_layers: list, 决定ViT中哪些层要加入"跳跃连接"中,默认是[3, 6, 9, 12]
dropout_rate: float, ViT部分的dropout比率
kernel_size: int, 卷积核尺寸
conv_norm: str, 卷积层的normalization方式, 'batch'或'layer'或'group'
conv_act: str, 卷积层的激活函数
use_residual: bool, 是否使用残差连接
show_summary: bool, 是否显示模型概况
output_act: str, 输出层的激活函数, 'auto'时会根据class_nums决定, 也可以自己指定'softmax'或'sigmoid'
'''
z4_de_filts = 512
z3_de_filts_list = [512]
z2_de_filts_list = [512, 256]
z1_de_filts_list = [512, 256, 128]
z34_conv_filts = 512
z23_conv_filts = 256
z12_conv_filts = 128
z01_conv_filts = 64
if output_act == 'auto': output_act = 'sigmoid' if class_nums == 1 else 'softmax'
assert input_shape[0] == input_shape[1] and input_shape[0] // patch_size
num_patches = (input_shape[0] * input_shape[1]) // (patch_size ** 2)
inputs = Input(input_shape)
z0 = inputs
z1, z2, z3, z4 = create_vit(z0,
patch_size,
num_patches,
projection_dim,
num_heads,
transformer_units,
transformer_layers,
dropout_rate,
extract_layers)
z1 = tf.reshape(z1, (-1, input_shape[0] // patch_size, input_shape[1] // patch_size, projection_dim)) # [B, H/16, W/16, projection_dim]
z2 = tf.reshape(z2, (-1, input_shape[0] // patch_size, input_shape[1] // patch_size, projection_dim))
z3 = tf.reshape(z3, (-1, input_shape[0] // patch_size, input_shape[1] // patch_size, projection_dim))
z4 = tf.reshape(z4, (-1, input_shape[0] // patch_size, input_shape[1] // patch_size, projection_dim))
z4 = Conv2DTranspose(z4_de_filts, 2, (2, 2), kernel_initializer='he_normal')(z4)
z3 = deconv_conv_block(z3, z3_de_filts_list, kernel_size, conv_norm, conv_act)
z3 = concatenate([z3, z4])
z3 = conv_deconv_block(z3, z34_conv_filts, kernel_size, conv_norm, use_residual, conv_act)
z2 = deconv_conv_block(z2, z2_de_filts_list, kernel_size, conv_norm, conv_act)
z2 = concatenate([z2, z3])
z2 = conv_deconv_block(z2, z23_conv_filts, kernel_size, conv_norm, use_residual, conv_act)
z1 = deconv_conv_block(z1, z1_de_filts_list, kernel_size, conv_norm, conv_act)
z1 = concatenate([z1, z2])
z1 = conv_deconv_block(z1, z12_conv_filts, kernel_size, conv_norm, use_residual, conv_act)
z0 = conv2d_block(z0, z01_conv_filts, kernel_size, conv_norm, use_residual, conv_act)
z0 = concatenate([z0, z1])
z0 = conv2d_block(z0, z01_conv_filts, kernel_size, conv_norm, use_residual, conv_act)
outputs = Conv2D(class_nums, 1, activation=output_act)(z0)
model = Model(inputs=inputs, outputs=outputs)
if show_summary: model.summary()
return model
5.简单测试
如果以上代码全部放在同一个python脚本中,可以添加下面的代码并运行脚本,尝试构建网络:
if __name__ == '__main__':
x = np.random.uniform(size=(1, 256, 256, 3))
model = build_model(# ↓ Base arguments
input_shape = (256, 256, 3),
class_nums = 5,
# ↓ ViT arguments
patch_size = 16,
projection_dim = 768,
num_heads = 12,
transformer_units = [2048, 768],
transformer_layers = 12,
extract_layers = [3, 6, 9, 12],
dropout_rate = 0.1,
# ↓ Conv arguments
kernel_size = 3,
conv_norm = 'batch',
conv_act = 'relu',
use_residual = False,
# ↓ Other arguments
show_summary = True,
output_act = 'auto',)
y = model(x)
print(x.shape, y.shape)
唉。