TOP 100值得读的图神经网络----架构
Top100值得一读的图神经网络 (qq.com) https://mp.weixin.qq.com/s?__biz=MzIyNDY5NjEzNQ==&mid=2247491631&idx=1&sn=dfa36e829a84494c99bb2d4f755717d6&chksm=e809a207df7e2b1117578afc86569fa29ee62eb883fd35428888c0cc0be750faa5ef091f9092&mpshare=1&scene=23&srcid=1026NUThrKm2Vioj874F3gqS&sharer_sharetime=1635227630762&sharer_shareid=80f244b289da8c80b67c915b10efd0a8#rd清华大学的Top 100 GNN papers,其中分了十个方向,每个方向10篇
https://mp.weixin.qq.com/s?__biz=MzIyNDY5NjEzNQ==&mid=2247491631&idx=1&sn=dfa36e829a84494c99bb2d4f755717d6&chksm=e809a207df7e2b1117578afc86569fa29ee62eb883fd35428888c0cc0be750faa5ef091f9092&mpshare=1&scene=23&srcid=1026NUThrKm2Vioj874F3gqS&sharer_sharetime=1635227630762&sharer_shareid=80f244b289da8c80b67c915b10efd0a8#rd清华大学的Top 100 GNN papers,其中分了十个方向,每个方向10篇

本文是对架构方向10篇的阅读笔记:
- Semi-Supervised Classification with Graph Convolutional Networks. Thomas N. Kipf, Max Welling. NeuIPS'17.
- Graph Attention Networks. Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, Yoshua Bengio. ICLR'18.
- Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. NeuIPS'16.
- Predict then Propagate: Graph Neural Networks meet Personalized PageRank. Johannes Klicpera, Aleksandar Bojchevski, Stephan Günnemann. ICLR'19.
- Gated Graph Sequence Neural Networks. Li, Yujia N and Tarlow, Daniel and Brockschmidt, Marc and Zemel, Richard. ICLR'16.
- Inductive Representation Learning on Large Graphs. William L. Hamilton, Rex Ying, Jure Leskovec. NeuIPS'17.
- Deep Graph Infomax. Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, R Devon Hjelm. ICLR'19.
- Representation Learning on Graphs with Jumping Knowledge Networks. Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, Stefanie Jegelka. ICML'18.
- DeepGCNs: Can GCNs Go as Deep as CNNs?. Guohao Li, Matthias Müller, Ali Thabet, Bernard Ghanem. ICCV'19.
- DropEdge: Towards Deep Graph Convolutional Networks on Node Classification. Yu Rong, Wenbing Huang, Tingyang Xu, Junzhou Huang. ICLR'20
目录
一、GCN 基于图卷积网络的半监督分类 SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
二、GAT 图注意力网络 Graph Attention Networks
三、具有快速局部谱滤波的图上的卷积神经网络 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
四、预测后传播:图神经网络满足个性化PageRank PREDICT THEN PROPAGATE: GRAPH NEURAL NETWORKS MEET PERSONALIZED PAGERANK
五、门控图序列神经网络 GATED GRAPH SEQUENCE NEURAL NETWORKS
六、GraphSAGE大型图的归纳表示学习 Inductive Representation Learning on Large Graphs
七、DGI DEEP GRAPH INFOMAX
八、JK Representation Learning on Graphs with Jumping Knowledge Networks
九、DeepGCNs: Can GCNs Go as Deep as CNNs?
十、DROPEDGE: TOWARDS DEEP GRAPH CONVOLUTIONAL NETWORKS ON NODE CLASSIFICATION
一、GCN 基于图卷积网络的半监督分类 SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
提出了一种全新的基于图结构的半监督学习方法,使用谱图理卷积的局域近似一阶进行卷积,模型在图的边数中线性缩放,并学习同时编码局部图结构和节点特征的隐含层表示
1 INTRODUCTION
- 图半监督学习:对图(如引文网络)中的节点(如文档)进行分类的问题,其中标签只对一小部分节点可用
- 传统的拉普拉斯正则项:
- 依赖于图中连接的节点可能共享相同标签的假设。然而,这种假设可能会限制建模能力,因为图的边不一定需要编码节点相似性,但可以包含附加信息
- 本文改进:
- 直接使用神经网络模型(,)对图结构进行编码
- 对所有带标签的节点在有监督的目标0上进行训练,从而避免了损失函数中显式的基于图的正则化。
- 图的邻接矩阵上的条件(·)将允许模型分发来自监督损失0的梯度信息,并将使其能够学习带和不带标签的节点的表示
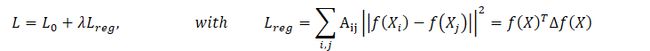
2 FAST APPROXIMATE CONVOLUTIONS ONGRAPHS 关于图的快速近似卷积
- 分层传播规则的多层图卷积网络(GCN)
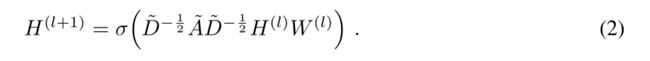
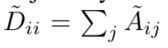
- 这种传播规则的形式可以通过图上的局域谱滤波的一阶近似来实现
谱图卷积
- 图上的谱卷积,计算量大,最后与U相乘需要(2)

- 近似:可以用切比雪夫多项式的截断展开式很好地逼近,复杂度降为()


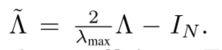


分层线性模型
- 让K近似为1,变为分层模型,然后可通过层的堆叠实现丰富的卷积滤波函数
- 进一步让≈2, 神经网络参数将在训练期间适应这种规模的变化

- 进一步减少参数:


得到最后的公式,Z为输出,Θ为可训练参数

3 SEMI-SUPERVISED NODE CLASSIFICATION
- 首先计算出来
- 然后进行两层的分层线性模型
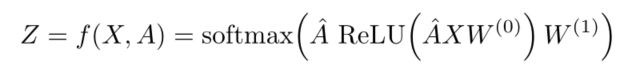


- 0为input-hidden, 1为hidden-output
二、GAT 图注意力网络 Graph Attention Networks
两种解释:
- 将注意力机制引入到图中
- 对特征X的再参数化(使用矩阵W对h进行的)
注意力机制(打分函数):

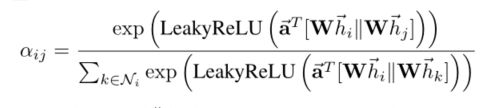
更新节点特征

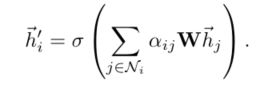
- 多头注意力的两种方式(拼接与平均)


三、具有快速局部谱滤波的图上的卷积神经网络 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
1 Introduction
- 将CNN推广到图的主要瓶颈:定义便于评估和学习的局部化图过滤器,也是本文的贡献
- 谱图理论的公式
- 严格的局部的滤波器:光谱滤波器可以被证明严格地局限在半径K的球体中,即从中心顶点开始的K跳
- 低计算复杂度
- 高效的池化
2 Proposed Technique

2.1 Learning Fast Localized Spectral Filters
- 将CNN迁移到图中的三个步骤:
- 图上局部卷积的设计
- 将相似的顶点组合在一起的图粗化过程
- 以空间分辨率换取更高过滤器分辨率的图形池化操作
- 两种方法的问题:都可以通过对图滤波器参数的特殊选择来克服
- 空间卷积:通过有限大小的核提供滤波器定位
- 尽管空间域中的图形卷积是可以想象的,但它面临着匹配局部邻域的挑战
- 因此,从空间的角度看,图上的平移没有唯一的数学定义
- 谱方法:通过Kronecker增量,利用卷积定理,在图上提供了定义良好的定位算子[31]
- 然而,定义在谱域中的滤波器不是自然局部化的,计算代价高(2)

- 然而,定义在谱域中的滤波器不是自然局部化的,计算代价高(2)
- 空间卷积:通过有限大小的核提供滤波器定位
- 谱图公式
- 使用多项式参数化局部滤波器
- 滤波器的参数学习
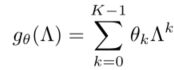

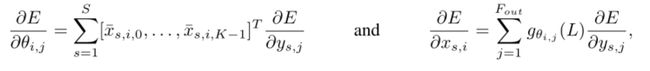
2.2 Graph Coarsening
- 图池化需要有意义的领域,因此需要聚类操作,而图聚类是NP问题,因此需要近似方法
- 多级聚类算法,其中每个级别生成一个更粗糙的图,该图对应于以不同分辨率看到的数据域。在每个级别将图表大小减少2倍的群集技术提供了对粗化和池化大小的精确控制
- Graclus的贪婪规则,一种非常快速的粗化方案,它将节点数从一个级别除以大约两个(可能存在一些单独的、不匹配的节点)到下一个较粗糙的级别。
- 在每个粗化级别选取未标记的顶点i,并将其与其未标记的邻居j之一进行匹配,从而最大化局部归一化切割(1/+1/)。
- 标记两个匹配的顶点,并将粗化权重设置为其权重之和
- 重复匹配,直到遍历完所有节点
2.3 Fast Pooling of Graph Signals
- 池操作要执行多次,并且必须高效
- 粗化后,输入图及其粗化版本的顶点不会以任何有意义的方式排列
- 池化操作的直接应用需要一个表来存储所有匹配的顶点
- 这将导致内存效率低下、速度慢且难以并行化的实现
- 可以这样安排顶点,使得图形合用操作变得与1D池化一样有效
- 创建平衡二叉树
- 重新排列顶点
四、预测后传播:图神经网络满足个性化PageRank PREDICT THEN PROPAGATE: GRAPH NEURAL NETWORKS MEET PERSONALIZED PAGERANK
- 问题:图分类任务中,传统的基于神经消息传递算法只考虑了较近节点,而且这种方法中,被利用的领域的大小很难扩展
- 新方法:将PageRank算法迁移到图神经网络中来,提出了PPNP
- 先使用神经网络计算单个节点的特征,然后再用PageRank算法进行传播
- 最后还是仿照的谷歌的解决方法,使用幂乘法进行近似,得到了线性复杂度
- 先使用神经网络计算单个节点的特征,然后再用PageRank算法进行传播

1 导言
- 图深度学习算法
- 节点嵌入方法:随机行走或矩阵分解 直接训练单个节点嵌入,无监督方式
- 既使用图形结构又使用节点特征:谱图卷积神经网络、消息传递(或邻居聚合)算法,递归神经网络进行邻居聚合
- 在这些类别中,消息传递算法类由于其灵活性和良好的性能最近引起了特别的关注
- 有几项算法使用注意力机制来改进邻居聚合方法,但只使用了非常有限的领域信息----->对外围或者稀疏标签的节点使用较大的领域信息,问题:
- 本质上是拉普拉斯平滑,较多的层会导致过平滑
- 随着层数的增加,GCN收敛到随机游走的极限分布。极限分布是图的整体属性,不考虑随机游走的起始(根)节点。因此,它不适合描述根节点的邻域。因此,对于大量的层(或聚合/传播步骤),GCN的性能必然会下降(Keyulu Xu, Chengtao Li, Y onglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation Learning on Graphs with Jumping Knowledge Networks. InICML, 2018)
- 本文的解决方法
- 提出限制分布和PageRank之间的内在联系
- 使用Personalized PageRank派生新的消息传递类算法,添加了传送回根节点的机会
- 保证了PageRank分数对根节点的本地领域进行编码--->避免过度平滑
- 增加了处理大型领域的能力
2 GRAPH CONVOLUTIONAL NETWORKS AND THEIR LIMITED RANGE
- GCN可被表示为:
- 问题:
- 只有两层,因此只考虑了两跳(two-hop)的邻域
- 像GCN这种信息传递方法本质上不能扩展到更大的邻域
- 通过平均来聚合,使用多层会导致过平滑
- 已经证明,使用k层GCN方法和随机游走方法是等价的。当→∞时,得到的结果只依赖于整个图,与根节点没有关系了(可以称为 焦点丢失问题)
- 聚合方法在每一层中使用了可学习的权重矩阵,使用大的领域会导致学习参数的数量和深度的增加
- 通过平均来聚合,使用多层会导致过平滑

3 PERSONALIZED PROPAGATION OF NEURAL PREDICTIONS
From message passing to personalized PageRank
- 焦点丢失问题的解决:极限分布与PageRank之间的联系
- 唯一的区别是:加自环和标准化

- 传统PageRank
- 解方程得到了:
- 唯一的区别是:加自环和标准化
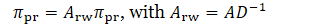
Personalized propagation of neural predictions (PPNP)
- 根据每个节点自身生成预测,然后使用 personalized PageRank进行传播,来生成最终的预测
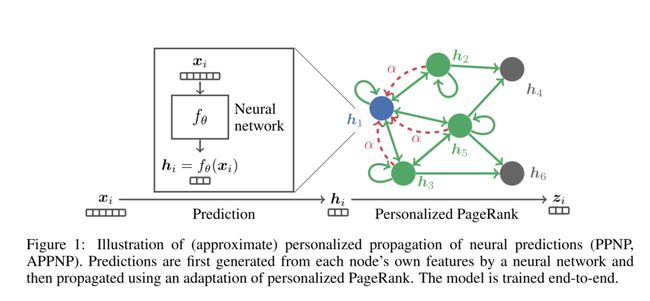

- 是特征矩阵,是带参数的神经网络

- PPNP将用于生成预测的神经网络从传播方案中分离出来。这种分离还解决了上面提到的第二个问题:神经网络的深度现在完全独立于传播算法

- 解决:
- 将Z的fullypersonalized PageRank看成是topic-sensitive PageRank,其中的每一列定义了一个(非标准化的)节点分布,该分布充当远程传输
- 因此,通过topic-sensitive PageRank的近似计算来近似PPNP
Approximate personalized propagation of neural predictions (APPNP)
- topic-sensitive PageRank的幂迭代具有线性计算复杂度,和带有重启的随机游走相关
- (0) ==()(+1) =(1−)()+() =softmax(1−)(−1)+
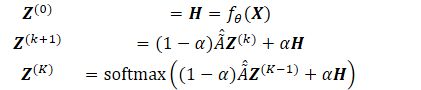
- 为初始向量和传播集
- 为幂迭代的次数,∈[0,−2]
- (0) ==()(+1) =(1−)()+() =softmax(1−)(−1)+
- 此模型的传播方案不需要任何额外的参数进行训练,而像GCN这样的模型通常需要为每个额外的传播层提供更多参数。因此,此模型可以用很少的参数传播到很远的地方
五、门控图序列神经网络 GATED GRAPH SEQUENCE NEURAL NETWORKS
工作:将门控方法引入到图神经网络,实现了基于图结构的序列模型
1 INTRODUCTION
- 先前关于图结构输入的特征学习的工作:主要集中到单一输出的模型上,如图级分类
- 问题:很多问题需要输出序列,图上路径、具有所有属性的图节点枚举等
- 图特征学习的两个设置
- 学习输入图的表征---->先前工作做了很多
- 在输出序列的过程中,学习内部表征---->很重要,因为我们需要来自图形结构问题的输出,而不仅仅是单独的分类
- 挑战:如何学习图形上的特征,这些特征对已经产生的部分输出序列(例如,如果输出路径,则到目前为止的路径)和仍然需要产生的特征(例如,剩余路径)进行编码
2 GRAPH NEURAL NETWORKS
- 将图映射到输出的两个步骤:
- 计算每个节点的表示
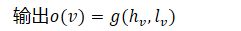
2.1 PROPAGATION MODEL
- 节点的初始表示被设置为任意值,每个节点的表示经过迭代学习:

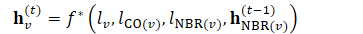
- 依次为:点的标签、以为输入或者输出的边的标签、指向或者指向的标签、指向或者指向的节点上衣时刻的状态
- ∗被建议的设置,边项之和:

2.2 OUTPUT MODEL AND LEARNING


- 图级分类:创建一个通过特殊类型的边连接到所有其他节点的虚拟“超级节点”,因此,图形级回归或分类可以采用与节点级回归或分类相同的方式进行处理
- 学习是通过Almeida-Pineda算法完成的,该算法的工作方式是运行传播到收敛,然后根据收敛的解计算梯度。
- 优点:不需要存储中间状态来计算梯度
- 缺点:参数必须受到约束,以便传播步骤是收缩映射---->会限制模型的表现力
- 当(·)是神经网络时,在网络的雅可比矩阵的1-范数上使用惩罚项
3 GATED GRAPH NEURAL NETWORKS
3.1 NODE ANNOTATIONS
- 为了将这些用作输入的节点标签(根据目标确定的)与前面介绍的节点标签(数据集提供的)区分开来,我们将其称为节点注释,并使用向量来表示这些注释
3.2 PROPAGATION MODEL
- 基础的传播模型

- r:reset gate, z:update gate
- (1):初始化
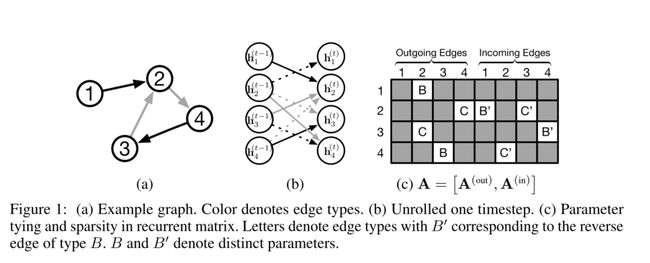
- (2):根据输入输出节点进行信息传播,其中为下图中的(c),描述节点是如何和其他节点关联
3.3 OUTPUT MODELS
- 节点级(节点选择任务)
- 图级,图水平的表示

4 GATED GRAPH SEQUENCE NEURA LNETWORKS
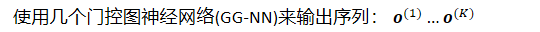

- 使用两个GG-NNs

- 训练门控图序列神经网络GGS-NN的两种方法:
- 使用可见的的注释进行序列输出:此时每步的节点注释都是人为规定的,比如要求每个节点只需要输出一次,需要在注释里弄清楚
- 使用潜在注释进行序列输出:使用反向传播训练注释
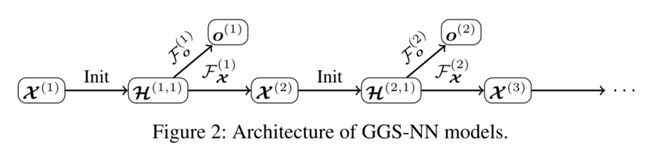
六、GraphSAGE大型图的归纳表示学习 Inductive Representation Learning on Large Graphs
- 以前方法的问题:要求所有所有的节点在嵌入的过程是可见的---->不能为没有看过的(unseen)节点生成嵌入
- 解决方式:通过采样和聚合节点的局部领域中的特征来生成嵌入,不同于传统的矩阵分解方法
1 Introduction
- 节点嵌入方法:
- 利用降维技术将节点图邻域的高维信息提取为密集的向量嵌入
- 节点嵌入可以被馈送到下游机器学习系统,并帮助执行诸如节点分类、聚类和链接预测之类的任务
- 现在方法的问题
- 集中在单个固定的图中,使用基于矩阵分解的方法嵌入节点,不能够快速地为没有见过或全新的(子)图快速生成嵌入,是直推式的
- 可以经过修改,在归纳式的设置中操作,但是计算昂贵,需要额外几轮梯度下降
- 归纳式嵌入问题比直推式困难很多
- 生成没见过的节点讲新观察到的子图“对齐”到已优化好的图中去:需要学会节点的领域属性,即揭示节点在图中的局部角色,也揭示其全局位置
- 解决
- 思路:使用卷积运算学习图结构,但以往的GCN只用作了固定图的直推式学习
- 本模型将GCN扩展到归纳无监督学习的任务中,并提出了可训练聚集函数的框架
- 具体方法
- 利用节点特征来实现聚合函数,而不是矩阵分解
- 学习每个节点邻域的拓扑结构以及节点特征在邻域的情况
- 通过聚合函数学习邻域的节点特征,而不是为每个节点训练单独的嵌入向量
- 每个聚合函数聚合给定节点不同跳数、搜索深度的信息
- 可以无监督、有监督训练
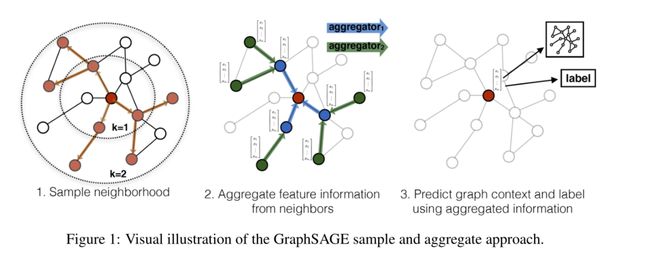
- 利用节点特征来实现聚合函数,而不是矩阵分解
2 Related work
- 基于矩阵分解的嵌入方法
- 图的有监督学习
- 图卷积网络
3 Proposed method: GraphSAGE
- 核心思想:如何从本地邻居聚合信息,如度或者文本属性
3.1 Embedding generation (i.e., forward propagation) algorithm
- 假定模型已经经过训练并且参数是固定的



- 每次迭代或搜索深度时,节点从它们的本地邻居那里收集信息,并且随着这个过程的迭代,节点逐渐从图的更远的范围获得越来越多的信息
- 与魏斯费勒-雷曼同构检验的关系(Weisfeiler-Lehman Isomorphism Test):GraphSAGE是它的连续近似,前者为其提供了理论基础

- 为了minibatch,否则每一批量的空间和时间复杂度是不可预计的
3.2 Learning the parameters of GraphSAGE
- 无监督,基于图的损失函数(鼓励相邻节点有相似表示、不相干节点高度不同),使用随机梯度下降法
3.3 Aggregator Architectures
- 不同于多维点阵,图结构没有先后顺序,因此聚合函数必须是对称的,即对不同顺序的输入产生相同的结果
Mean aggregator
- 几乎等同于GCN中的传播规则
LSTM aggregator
- 有更好的表现力
- 但不是内在对称的(顺序输入)---->将LSTM应用于节点邻居的随机排列,我们使其适应于在无序集合上操作
Pooling aggregator
- 每个邻居的向量通过完全连接的神经网络独立馈送;在这种变换之后,应用元素层面的的最大池化操作来聚合邻居集合上的信息

- 为元素层面的max操作

- 为元素层面的max操作
七、DGI DEEP GRAPH INFOMAX
- 以无监督方式学习图结构中节点表示的通用方法
- 方法:最大化局部表示和相应高级图形摘要的互信息
1 INTRODUCTION
- 将神经网络推广到图神经网络是当前机器学习的主要挑战之一,但
- 最成功的方法是监督学习-->很多时候不可行,没有那没多标注的数据
- 从大规模图中发现新颖或有趣的结构是可取的
- 因此,图无监督学习至关重要
- 现行常用无监督算法是随机游走,问题
- 过度强调邻近信息而牺牲了结构信息
- 性能高度依赖于超参数选择
- 不清楚随机游走是否真的提供了有用信号:这些编码器实施了一种感应偏差,即相邻节点具有相似的表示
- 提出方法:用互信息替代随机游走
- DIM训练编码器模型,以最大化输入的高级“全局”表示和“局部”部分(如图像的面片)之间的互信息
- 这鼓励编码器携带存在于所有位置的信息类型(因此具有全局相关性)
2 RELATED WORK
Contrastive methods
- 对比学习是无监督学习的重要方法
- 使用打分函数,训练编码器增加“真实”输入(也称为正面示例)的分数,减少“虚假”输入(也称为负面示例)的分数
- DGI是对比的,目标是基于对局部-全局对和负采样对进行分类
Sampling strategies
- 对比方法的一个核心细节:如何对正样本和负样本进行采样
- 正样本:短随机游走出现的节点(语言建模角度,将节点视为单词,随机游走视为句子)
- 负样本:随机取样
- curriculum-based negative sampling scheme (with progressively “closer” negative examples)
- 引入对手来选择负样本
Predictive coding
- contrastive predictive coding(CPC)是另一种基于互信息最大化的深度表征方法
3 DGI METHODOLOGY
3.1 GRAPH-BASED UNSUPERVISED LEARNING
- 目标,学习一个编码器,将节点特征编码为局部特征h

- 此时h为局部特征,而不是节点特征
3.2 LOCAL-GLOBAL MUTUAL INFORMATION MAXIMIZATION
- 训练编码器的方法是互信息最大化:寻求节点表示,该表示捕获整个图的全局信息内容,由摘要向量表示


- h,表示这个局部-摘要对(patch-summary pair)的可能性分数,摘要中包含的局部的对应该更高
- 实现负采样
- 将图(,)的摘要和替代图(,)的局部表示h配对

- 对于单个图,corruption function:
- 将图(,)的摘要和替代图(,)的局部表示h配对
- 负采样程序的选择,将会决定,希望被捕获的特定类型的结构信息
- 优化目标:类似Deep InfoMax:
- 使用噪声对比型目标,在关节样本(正样本)和边缘产物(反样本)之间使用标准的二元交叉熵(BCE)损失
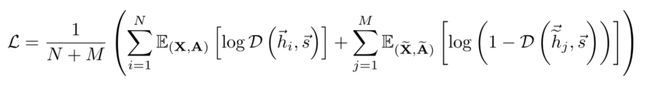
- 由于所有导出的局部表示都被驱动以保留与全局图摘要的互信息,这允许在局部级别上发现和保留相似性,例如,具有相似结构角色的遥远节点(已知对于许多节点分类任务来说,这是一个强预测器)
- 是 Hjelm et al. (2018)说法的反向版本:对于节点分类,我们要做的是让patches(局部节点)在整个图上进行连接,而不是让summary(摘要)保留所有的这些相似性



八、JK Representation Learning on Graphs with Jumping Knowledge Networks
问题:现有的图神经网络都是从邻居来聚合节点,但“相邻”节点的范围很大程度上取决于图结构,类似随机游走
提出:跳跃知识网络,灵活使用每个节点的不同邻域范围,以实现更好的结构感知表示
1 introduction
- 图神经网络非常有效,但是,随着层数的加深,使用聚合(或称消息传递)的GCN,表现反倒没有两层的好
- 提出两个问题
- 邻域聚合方案的性质与局限性
- 基于分析提出不同的结构,这种结构支持自适应、结构感知的表示
- model analysis
- influence distribution:the effective range of nodes that any given node's representation draws from,任何给定节点取值的有效范围,这个有效范围隐式地编码了关于节点应该从哪些“最近邻居”中提取信息的先前假设
- Changing locality

- 对不同的节点,相同的随机游走步数回有不同的效果
- JK networks
- 问题:是否可以调整每个节点或者任务的影响半径
2 Background and Neighborhood aggregation schemes
- 传统的聚合方法
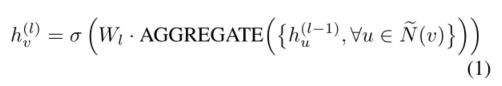
- GCN
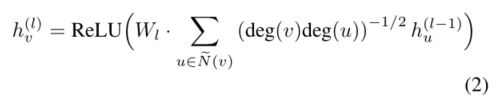
- inductive(归纳式) settings的变体
- Neighborhood Aggregation with Skip Connections
- 当下的研究不同于以前的将所有的节点同时聚合,而是先聚合另据节点,再将其与节点表征聚合
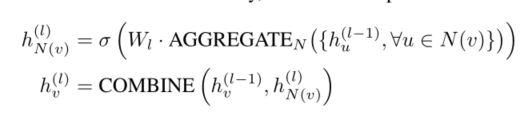
- COMBINE在特定模型中的定义不一样,是skip connection的一种形式
- 这些skip connection是特定于输入的,但不是特定于输出单元的
- 因此,skip connection无法独立地自适应调整最终层表示的邻域大小
- 当下的研究不同于以前的将所有的节点同时聚合,而是先聚合另据节点,再将其与节点表征聚合
- Neighborhood Aggregation with Directional Biases
- 如GAT,给边加了“重要性”权值
- GraphSAGE的max池化隐式地选择了重要节点
- 这些工作与本文正交:前者调整了扩展的方向,后者调整了扩展的位置
- 因此两种模型可以结合以add representational power

3 Influence Distribution and Random Walks
- 定义3.1 Influence score and distribution
- 定义3.2 随机游走分布
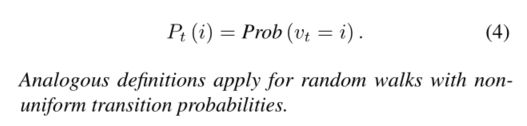
- 随着t的增加,随机游动分布变得更加分散,并且如果图是非二部的,它收敛到极限分布。收敛速度取决于子图的结构,并且可以由随机游动转移矩阵的谱隙(或电导)来限定

3.1 Model Analysis
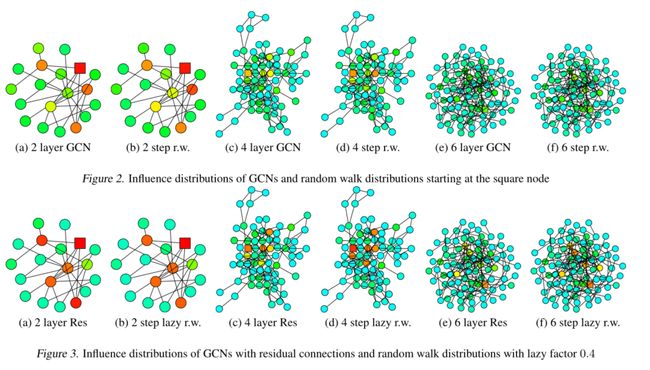
- 定理1:给定一个k层GCN,其聚合方式如等式(3)所示,假设模型计算图中的所有路径均以相同的概率ρ激活。则,任何节点∈的影响分布为相当于从节点开始的上的步随机游动分布

- Fast Collapse on Expanders
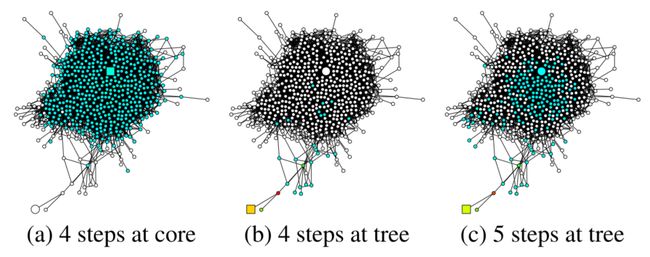
- 从内部开始随机游走的迅速收敛到均匀分布,在经过O(log||)次邻域聚合迭代后,每个节点的表示几乎同样受到其他任何表示的影响,因此,节点表示代表全图,只携带单个节点的有限信息

- 而从有界树宽的部分开始的随机游走,保留了更多的本地信息
4 Jumping Knowledge Networks
- 两个简单有效的结构改变:
- 跳转连接
- 随后的选择性但自适应聚合机制(a subsequent selective but adaptive aggregation mechanism)
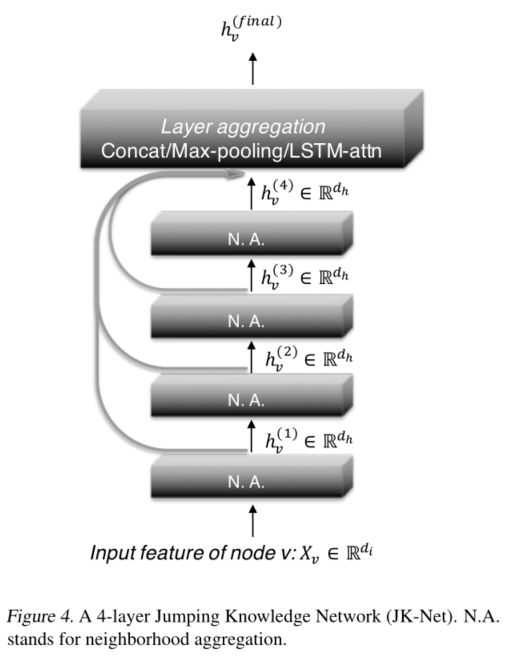
- combine这些跳层连接的方法

- 后面需要接一个线性变换层,如果变换层权重在节点间共享,那么不是节点自适应的
- 但是它用适合整个数据集的方式结合子图特征来优化参数,适合小型图
- Max-pooling,元素层面的max操作
- 是节点自适应的
- 不需要学习额外的参数
- LSTM-attention
- 另一种可能的实现将LSTM与最大池结合起来
- 是节点自适应的,注意力分数对每个节点都不同
- 在大型图表现好,但是在小型图容易过拟合
4.1 JK-Net Learns to Adapt
- 层聚合函数设计的关键思想是在查看所有层上的学习特征后,确定不同范围内节点子图特征的重要性,而不是优化和固定所有节点的相同权重


4.2 Intermediate Layer Aggregation and Structures
- 是否可以在所有层之间绘制相同的层间连接
- 如果应用逐层级联聚合,则得到的体系结构近似于DenseNets的图对应,DenseNets是为计算机视觉问题引入的
- 然而,这个版本需要学习更多的功能
- 从图论的角度看DenseNet设置(图像),图像实际上对应于规则的近平面图
- 这样的图远远不是扩展器,也不会给具有不同子图结构的图带来挑战。
- 事实上,具有级联聚合的模型在具有更规则结构的图(例如图像和结构良好的社区)上表现良好。作为一个更通用的框架,JK-Net支持通用的LayerWise聚集模型,能够在复杂结构的图上实现更好的结构感知表示
九、DeepGCNs: Can GCNs Go as Deep as CNNs?
问题:GCNs解决了非欧数据的卷积问题,但由于梯度消失问题,往往只能非常浅

解决:仿照CNN,将CNN中的残差/密集连接和膨胀卷积迁移到GCNs中来
1 Introduction
- ResNet引入残差连接,减轻了了梯度消失问题
- DenseNet引入跨层连接,解决了随着层数增加,更多空间信息随着池化而消失的问题
2 Related Work
- EdgeConv方法:一种用于点云语义分割的动态边缘卷积算法,利用点特征之间的距离动态计算每个图层的节点邻接关系
3 Methodology

- GCN的卷积操作
- 节点特征的计算
- 动态边
- 与固定图结构的GCNS相比,动态图卷积(允许图结构在每一层中改变)可以学习更好的图表示。
- ECC(Edge-Conditioned Convolution)使用动态边缘条件滤波器来学习边缘特定的权重矩阵。
- EdgeConv[42]在每个EdgeConv层之后,在当前特征空间中查找最近的邻居来重建图形
- 为了学习生成点云,Graph-Convolution GAN(Generative Adversarial Network)[38]还应用k-NN图来构造每一层中每个顶点的邻域
- 动态改变GCNS中的邻居有助于缓解过度平滑问题,并且当考虑更深层次的GCNS时,有效地产生更大的感受野。在我们的框架中,我们提出在每一层的特征空间中通过Dilated k-NN函数重新计算顶点之间的边,以进一步增加感受野
- 与固定图结构的GCNS相比,动态图卷积(允许图结构在每一层中改变)可以学习更好的图表示。


3.2 Residual Learning for GCNs

3.3 Dense Connections in GCNs

- 类似于JK,只是将表达变为了图级
3.4 Dilated Aggregation in GCNs
- 使用膨胀卷积聚合多尺度上下文信息可以显著提高语义分割任务的准确率:膨胀卷积在不损失分辨率的情况下扩大了感受野


十、DROPEDGE: TOWARDS DEEP GRAPH CONVOLUTIONAL NETWORKS ON NODE CLASSIFICATION
问题:随着GCN网络深度的增加,过拟合和过平滑出现
贡献:DropEdge在每个训练时期随机地从输入图中移除一定数量的边,其作用类似于数据增强器和消息传递减少器
- 理论上证明了DropEdge既降低了超平滑的收敛速度,又减轻了超平滑带来的信息损失
- DropEdge是一项通用技术,可以与许多其他主干模型(例如GCN、ResGCN、GraphSAGE和JKNet)配合使用
1 INTRODUCTION
- 过拟合的原因:过参数化,导致在训练集拟合地很好,但在测试集表现很差
- 图形卷积本质上推动相邻节点的表示相互混合,这样,如果我们使用无限数量的层,则所有节点的表示都将收敛到一个固定点,使它们与输入要素无关,并导致梯度消失

- DropEdge可以缓解这两个问题:在每个训练时间随机丢弃输入图的一定比率的边
- DropEdge可以被认为是一种数据增强技术。通过DropEdge,实际上生成了原始图形的不同随机变形副本;从而增加了输入数据的随机性和多样性,因此能够更好地防止过度拟合
- DropEdge也可以被视为消息传递减少器。在GCNs中,相邻节点之间的消息传递沿边缘路径进行。删除某些边会使节点连接更加稀疏,从而在GCN深入时在一定程度上避免过度平滑
- DropEdge要么降低了过度平滑的收敛速度,要么减轻了过度平滑造成的信息损失
2 Related Work
- GCNs:基于谱图理论的和基于采样的,GAT是DropEdge的后导版本
- Deep GCNs
3 NOTATIONS AND PRELIMINARIES
- 图的记号
- GCN的表示
4 OUR METHOD: DROPEDGE
4.1 METHODOLOGY
- 随机让邻接矩阵的一部分(,为节点数,为丢弃比率)非零元素变为0,

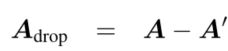
- 同时使用了re-normalization trick(就是归一化)
- Preventing over-fitting 直观理解
- GCNS的关键是聚合每个节点的邻居信息,这可以理解为邻居特征的加权和(权重与边相关联)
- 从邻居聚合的角度来看,DropEdge在GNN训练期间支持随机子集聚合,而不是完全聚合
- 从统计上讲,如果我们丢弃概率为p的边,DropEdge只会将邻居聚合的期望值更改为倍增
- 在权重归一化之后,该乘数实际上将被删除,这在实践中通常是这样的
- 因此,DropEdge不改变邻居聚集的期望,是一种用于GNN训练的无偏数据增强技术,类似于典型的图像增强技术(例如旋转、裁剪和摆动),其能够阻止训练CNN中的过拟合
- Layer-Wise DropEdge
- 可以在不同的层,使用不同的

- 这种层级的版本带来了原始数据的更多随机性和变形
- 可以在不同的层,使用不同的
4.2 TOWARDS PREVENTING OVER-SMOOTHING
- 超平滑:收敛到子空间,而不是收敛到固定点
- 定义

- 从两个方面论证采用DropEdge来缓解-h平滑问题
- 通过减少节点连接,DropEdge被证明减缓了过平滑的收敛速度;换言之,只有使用DropEdge时,松弛的-h的值才会增加
- 通过减少节点连接,证明了DropEdge可以减缓过平滑的收敛速度,也就是说,松弛的-h的值只会在使用DropEdge的情况下增加
- 原始空间的维度与收敛的子空间的维度之间的差距,即N−M,衡量了信息损失的大小;差距越大,信息损失越严重。DropEdge能够增加收敛的子空间的维数,从而能够减少信息损失

4.3 DISCUSSIONS
- DropEdge vs. Dropout
- Dropout技巧试图通过将特征维度随机设置为零来扰乱特征矩阵,这可能会降低过拟合的效果,但无助于防止过度平滑,因为它不会对邻接矩阵进行任何改变
- DropEdge可以看作是从丢弃特征尺寸到丢弃边的一种Dropout,这既减轻了过度拟合,也减轻了过度平滑
- 事实上,Dropout和DropEdge的影响是相辅相成的,它们的兼容性将在实验中得到体现
- DropEdge vs. DropNode
- GraphSAGE、FastGCN 、AS-GCN 本质上是一种DropNode
- DropNode对丢弃边的影响是面向节点的间接效果
- 相比之下,DropEdge是面向边的,可以为训练保留所有节点特征(如果它们可以一次装入内存),表现出更大的灵活性
- 为了保持期望的性能,当前DropNode方法中的采样策略通常效率低下,例如,GraphSAGE遭受指数级增长的层大小的困扰,以及AS-GCN要求逐层递归地进行采样
- DropEdge既不会随着深度的增加而增加层大小,也不需要递归进度,因为所有边的采样都是平行的
- DropEdge vs. Graph-Sparsification
- Graph-Sparsification优化目标是在保留输入图的几乎所有信息的同时,去除不必要的边进行图压缩(边被丢弃时保持输出不变)
- DropEdge将在每个训练时间随机移除输入图的边,而Graph-Sparsiization则求助于繁琐的优化方法来确定要删除哪些边