elasticsearch三节点集群,关闭master服务,集群状态改变为yellow后,重新自动选举产生新的master节点,集群恢复。
同一台服务器启动三节点测试:
1.修改配置文件:
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.59.138:9300","192.168.59.138:9301","192.168.59.138:9302"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.system_call_filter: false
2.指定node名称、logs、data路径启动三个elasticsearch集群节点,集群名称如果不指定的话默认为"elasticsearch",也可分别指定"-E http.port=920x -E transport.port=930x",如果不指定的话,三个节点会自动从9200/9300往后创建。
./bin/elasticsearch -d -E node.name=node-1 -E path.logs=logs1 -E path.data=data1
./bin/elasticsearch -d -E node.name=node-2 -E path.logs=logs2 -E path.data=data2
./bin/elasticsearch -d -E node.name=node-3 -E path.logs=logs3 -E path.data=data3
三节点时集群健康状态,节点数为3:
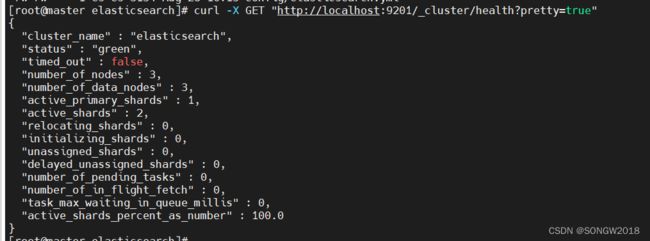
4.手动杀掉主节点服务:
查看shard状态,此时,主分片在node-1上。找到node-1对应的进程,直接kill。
curl -X GET "http://localhost:9201/_cat/shards?v"
此时其他节点连接不上node-1,日志报错

集群状态变为yellow,节点数为2:

等待几分钟后,集群自动重新选举node-02为主节点:

主节点切换后,集群状态恢复,节点数量为2:
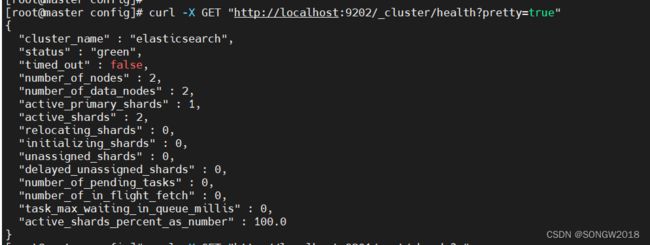
查看此时shard状态,和节点状态
[root@master config]# curl -X GET "http://localhost:9201/_cat/shards?v"
index shard prirep state docs store ip node
.kibana 0 r STARTED 9 20.7kb 192.168.59.138 node-3
.kibana 0 p STARTED 9 40.5kb 192.168.59.138 node-2
[root@master config]# curl -X GET "http://localhost:9201/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.59.138 41 94 2 0.02 0.15 0.35 dilmrt * node-2
192.168.59.138 48 94 2 0.02 0.15 0.35 dilmrt - node-3
5.重启第一个节点,并查看集群状态
[es@master logs2]$ ../bin/elasticsearch -d -E node.name=node-1 -E path.logs=logs1 -E path.data=data1
[root@master config]# curl -X GET "http://localhost:9202/_cluster/health?pretty=true"
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 1,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
[root@master config]# curl -X GET "http://localhost:9201/_cat/shards?v"
index shard prirep state docs store ip node
.kibana 0 r STARTED 9 20.7kb 192.168.59.138 node-3
.kibana 0 p STARTED 9 40.9kb 192.168.59.138 node-2
[root@master config]# curl -X GET "http://localhost:9201/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.59.138 38 96 20 5.78 1.69 0.69 dilmrt * node-2
192.168.59.138 38 96 20 5.78 1.69 0.69 dilmrt - node-3
192.168.59.138 17 96 90 5.78 1.69 0.69 dilmrt - node-1
(master列,带星号的为主节点,此时启动后,主节点还是后来选举的node-2)
疑问:两个节点和三个节点的shard数量时一样的,这是哪里定义的呢 ?
"active_primary_shards" : 1,
"active_shards" : 2,
=====================================================
测试关闭两个节点,集群是否可用:
此时只剩下node-1,集群无法正常使用,再启动一个就好了
***如果需要确保集群仍然可用,你不得同时停止投票配置中的一半或更多节点。只要有一半以上的投票节点可用,集群可以正常工作
