sklearn入门与决策树
菜菜的机器学习sklearn实战-----sklearn入门与决策树
- 菜菜的机器学习sklearn实战-----sklearn入门与决策树
-
- sklearn入门
- 决策树
-
- 概述
-
- 决策树是如何工作的
- sklearn中的决策树
-
- sklearn 建模流程
- DecisionTreeClassifier与红酒数据
-
-
- 基本流程
- 重要参数
-
- criterion
- random_state&splitter
- 建立一棵树
- 剪枝参数
-
- max_depth
- min_samples_leaf & min_samples_split
- max_features & min_impurity_decrease
- 确认最优的剪枝参数
- 目标权重参数
- class_weight & min_weight_fraction_leaf
- 重要属性的接口
-
- DecisionTreeRegressor
-
- 重要参数,属性及接口
-
- criterion
- 回归树是如何工作的
-
- 交叉验证
- 实例:一维回归的图像绘制
- 实例:泰坦尼克号幸存者的预测
菜菜的机器学习sklearn实战-----sklearn入门与决策树
sklearn入门
官网:https://scikit-learn.org
决策树
概述
决策树是如何工作的
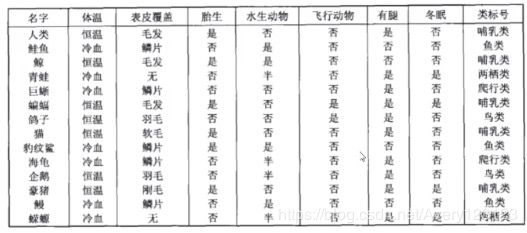 将上图转化成下面的树:
将上图转化成下面的树:
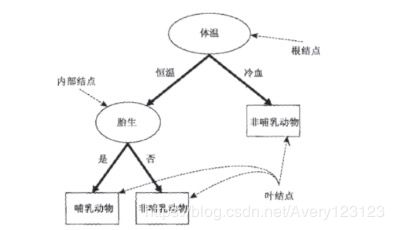
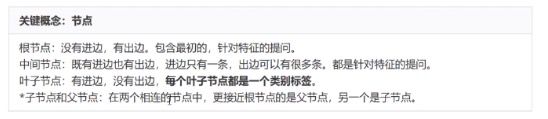
决策树算法的核心是要解决两个问题:
1)如何从数据表中找到最佳节点和最佳分枝叶?
2)如何让决策树停止生长,防止过拟合?
sklearn中的决策树
模块sklean.tree
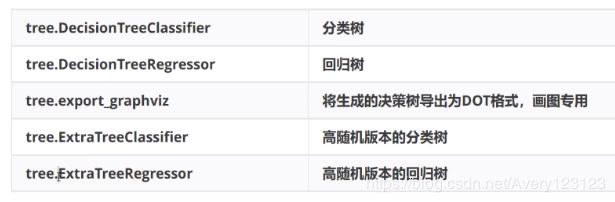
sklearn 建模流程
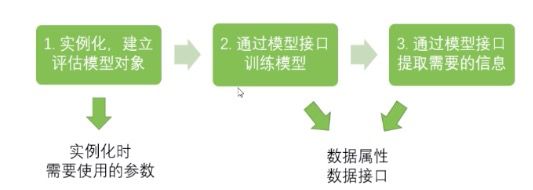
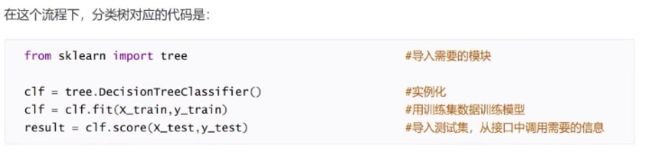
DecisionTreeClassifier与红酒数据
基本流程
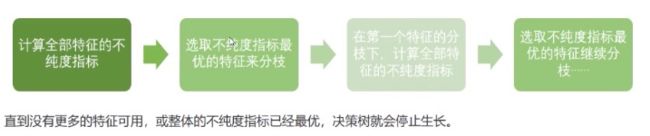
重要参数

criterion
Criterion这个参数是用来决定不纯度的计算方法,
sklearn提供两种选择:
1)输入“entropy”,使用信息熵(Entropy)
2)输入“gini”,使用基尼系数(Cini Impurity)
不填写默认为基尼系数
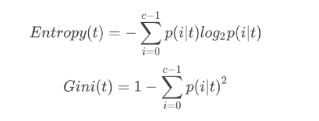
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。
但是在实际应用中,**信息熵和基尼系数的效果基本相同,**信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。
另外信息熵相对敏感,使用信息熵作为指标时,决策树生长会更加精细,因此对于高维数据或者噪声较多的数据,信息熵容易产生过拟合,基尼系数在这样的情况下效果往往更好。

random_state&splitter
random_state用来设置分枝中的随机模式参数,默认为None,输出一个稳定的树
splitter也是用来控制决策树中的随机选项,
两个输入值
输入“best”,决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看)
输入“random”,决策树在分枝时更加随机,树会更深,对训练集的拟合将会降低。这也是防止过拟合的一种方式。
建立一棵树
1 导入需要的算法库
from sklearn import tree
from sklearn sklearn.datasets import load_wine
from sklearn.model_selection import
2 探索数据
wine = load_wine()
wine.data
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
3 决策树分类模型
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
4 可视化
import graphviz
feature_name = ['alcohol',
'malic_acid',
'ash',
'alcalinity_of_ash',
'magnesium',
'total_phenols',
'flavanoids',
'nonflavanoid_phenols',
'proanthocyanins',
'color_intensity',
'hue',
'od280/od315_of_diluted_wines',
'proline']
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=["琴酒","雪梨","贝尔摩德"]
,filled=True#填充颜色
,rounded = True#圆形轮廓
)
graph = graphviz.Source(dot_data)
graph
用一些参数来确定一下决策树
# 确定一颗决策树
cls = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter = "random"
)
cls = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)#返回预测的准确度
score
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=[“琴酒”,“雪梨”,“贝尔摩德”]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
剪枝参数
过拟合
模型在训练集上表现很好,在测试集上却表现糟糕
提升决策树泛化能力
剪枝策略对决策树的影响十分大,正确的剪枝能够应对过拟合问题
max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉,通常从=3开始,看看是否需要增加深度或者限制深度
min_samples_leaf & min_samples_split
min_sample_leaf限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会议朝着满足每个子节点都包含min_samples_leaf个样本方向去发生
一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型更加平滑,如果设置太小就会引起过拟合,设置得太大就会组止模型学习数据。一般来说从=5开始使用。
min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分歧,否则分枝就不会发生。
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=3
,min_samples_leaf=10
,min_samples_split=10
)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
dot_data = tree.export_graphviz(clf
,feature_names=wine.feature_names
,class_names=[“琴酒”,“雪梨”,“贝尔摩德”]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
max_features & min_impurity_decrease
一般max_depth使用,用作树的“精修”
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。
与max_depth异曲同工,max_features是用来限制高维度数据的过拟合的剪枝参数。
min_impurity_decrease限制信息增益的大小,信息增益小于设定数值的分枝不会发生。
确认最优的剪枝参数
如何确定?使用确定超参数的曲线来判断
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion=“entropy”
,random_state=30
,splitter=“random”
)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
test.append(score)
plt.plot(range(1,11),test,color = “red”,label = “max_depth”)
plt.legend()
plt.show()
目标权重参数
class_weight & min_weight_fraction_leaf
完成样本标签平衡的参数
样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例。比如说,在银行要判断‘一个办了信用卡的人是否会违约’,就是 是vs否(1% : 99%)的比例。
因此我们要使用class_weight参数对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向少数类的方法建模。该参数默认为None,此模型表示给与数据集中的所有标签相同的权重。
有了权重之后,样本量就不再是单纯的记录数目,而是受输入的权重影响了,因此这时候剪枝,就要搭配min_weight_fraction_leaf这个基于权重的剪枝参数来使用。
重要属性的接口
属性是在模型训练之后,能够调用查看的模型的各种性质。
对于决策树来说,最重要的是feature_importances_能够查看各个对模型的重要性
sklearn中许多算法的接口都是相似的:
fit 与 score
apply 与 predict
**注意:**所有接口中要求输入X_train和X_test的部分,必须至少是一个二维矩阵,因为sklearn不接受任何一维矩阵作为特征矩阵被输入
假设你的数据只有一个特征,必须使用reshape(-1,1)来增维
假设你的数据只有一个特征和一个样本,必须使用reshape(1,-1)来增维
DecisionTreeRegressor
重要参数,属性及接口
criterion
回归树衡量分枝质量的指标表,支持的标准有三种:
1 )输入“mse”使用均方误差mean squared error(MSE),父节点与子节点之间的均方误差,这种方法通过使用叶子节点的均值来最小化L2损失

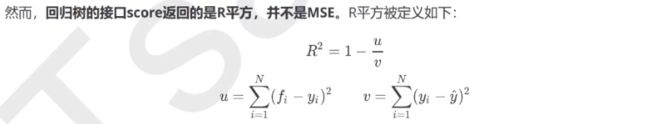


2 )输入“Friedman_mse”使用费尔德曼均方误差
3 )输入“mae”使用绝对平均误差(mean absolute error)
属性
feature_importances_
接口
apply
fit
predict
score
回归树是如何工作的
交叉验证
交叉验证是用来观察模型稳定性的一种方法
我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确性来评估模型的平均准确度。
训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出平均值,是对模型效果的一个最好的度量
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
#交叉验证
cross_val_score(regressor,boston.data,boston.target,cv=10,
#scoring = “neg_mean_squared_error”
)
#默认返回R平方
cross_val_score(regressor,boston.data,boston.target,cv=10,
#使用负均方误差
scoring= "neg_mean_squared_error"
)
实例:一维回归的图像绘制
创建训练集
#创建一条含有噪声的正弦曲线
#生成随机数种子
rng = np.random.RandomState(1)
#生成80乘1的升序矩阵,升序由axis = 0控制
X = np.sort(5 rng.rand(80,1),axis=1)
#使用ravel降维
y = np.sin(X).ravel()
y[::5] += 3 (0.5 - rng.rand(16))
plt.figure()
plt.scatter(X,y,s=20)
训练模型
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X,y)
regr_2.fit(X,y)
生成测试数据
#使用np.newaxis来增维
#l[:,np.newaxis]把l增维
#l[np.newaxis,:]把l降维
X_test = np.arange(0.0,5.0,0.01)[:,np.newaxis]
X_test.shape
得到预测结果
#predict对每一个X数据求出对应 回归或者分类结果
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
绘制图像
plt.figure()#建立一个画布
plt.scatter(X,y,s = 20,edgecolor = "black",c = "darkorange",label = "data")#画散点图
#化预测结果的折线图
plt.plot(X_test,y_1,label="max_depth=2",linewidth=2)
plt.plot(X_test,y_2,color = "yellowgreen",label="max_depth=5",linewidth=2)
plt.xlabel("data")