Tensorflow.js||使用 CNN 识别手写数字
Tensorflow官方的tesorflow.js实操课程
链接为:link
使用 CNN 识别手写数字
文章目录
- 使用 CNN 识别手写数字
-
- 1. 简介
- 2. 设置操作
- 3. 加载数据
- 4. 定义模型架构
- 5. 训练模型
- 6. 评估模型
1. 简介
构建一个 TensorFlow.js 模型,以使用卷积神经网络识别手写数字。首先,我们将通过让分类器“观察”数千个手写数字图片及其标签来训练分类器。然后,我们会使用模型从未见过的测试数据来评估该分类器的准确性。该任务被视为分类任务,因为我们会训练模型以将类别(出现在图片中的数字)分配给输入图片。我们将通过显示输入的多个示例和正确的输出来训练模型。这称为监督式学习。
实验环境
- win10 + tensorflow 2.1.0 + CUDA 10.1
- Chrome 95
- VScode + liveerver
2. 设置操作
配置相关环境以保证程序的正常运行。
- 创建 HTML 网页并添加 JavaScript
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorialtitle>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js">script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tfjs-vis.umd.min.js">script>
<script src="data.js" type="module">script>
<script src="script.js" type="module">script>
head>
<body>
body>
html>
- 为数据和代码创建 JavaScript 文件
在上述 HTML 文件所在的文件夹中,创建一个名为 data.js 的文件,并将此链接中的内容复制到该文件中。(MNIST数据文件)
tf 是对 TensorFlow.js 库的引用,tfvis 是对 tfjs-vis 库的引用
在与第 1 步相同的文件夹中,创建一个名为 script.js 的文件,并将以下代码放入其中。
console.log('Hello TensorFlow');
开始测试
用浏览器打开Html文件,如果在开发者模式的console中显示出
“Hello TensorFlow”。说明成功,那么可以继续执行下一步操作。
如下图所示:

报错指南
- Cross origin requests are only supported for protocol schemes
Chrome浏览器跨域报错。
Access to script at‘…’from origin ‘null’ has been blocked by CORS policy: Cross origin requests are only supported for protocol schemes: http, data, chrome,chrome-extension, https.
主要是由于Chrome91之后,出于安全性的更新,更新了一些安全协议,导致的跨域问题。
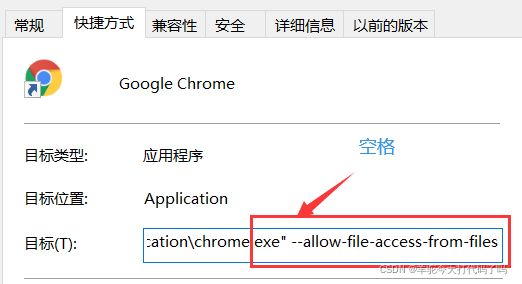
解决方案1 ---- 增加目标选项
对于windows来说,找到chrome的快捷方式,在属性–>目标里面添加
–allow-file-access-from-files就可以了。
注意:要有一个空格,allow前面是两个减号。“ -”
解决方案2 ---- 另起一个服务
网上关于这方面的方法有很多,我这里选择借助VScode中的 liveServer 插件。
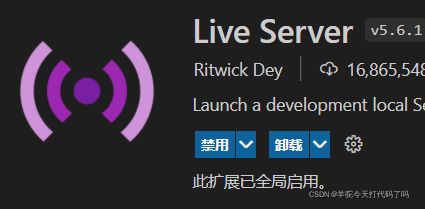
下载安装之后,在编写的HTML里面,右键“open with liveServer” 就成功啦。
- 如果不幸遇到 MIME type的问题
Failed to load module script: Expected a JavaScript module script but the server responded with a MIME type of “”. Strict MIME type checking is enforced for module scripts per HTML spec.
这里我是使用的nginx,更改了nginx.conf的MIME type信息,将默认的更改为了指向性更明确的 application/javascript 。如果是win10的SSL,需要改为 application/x-javascript。

3. 加载数据
添加下面的代码到 scrip.js文件中。
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
刷新页面,应该看到下图所示数字图片。数据文件正常加载。
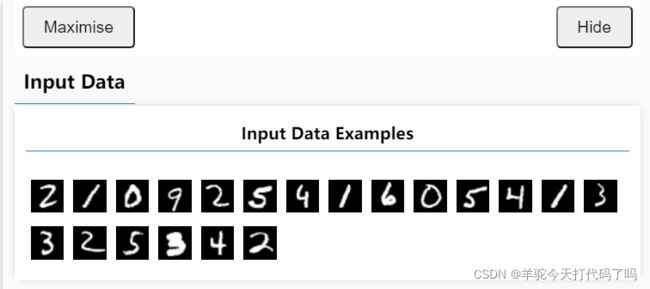
目标是训练一个模型,该模型会获取一张图片,然后学习预测图片可能所属的 10 个类中每个类的得分(数字 0-9)。
每张图片的尺寸为 28x28 像素,并具有 1 个颜色通道,因为这是灰度图片。因此,每张图片的形状为 [28, 28, 1]。
4. 定义模型架构
模型架构其实就是“模型在执行时会运行的函数”,或者“我们的模型将用于计算答案的算法”的另一种说法。
将下面代码添加到 script.js 文件中。
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
代码讲解
卷积
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
使用顺序模型,conv2d层而不是密集层。
con2d 的主要参数:
-
inputShape。将流入模型第一层的数据的形状。
在本例中,我们的 MNIST 示例是 28x28 像素的黑白图片。图片数据的规范格式为 [row, column, depth],因此在这里我们需要配置以下形状:[28, 28, 1]。各个维度的像素数量为 28 行和 28 列,深度为 1,因为我们的图片只有一个颜色通道。
注意:我们不会在输入形状中指定批次大小。层设计为与批次大小无关,因此在推理期间,您可以传入任何批次大小的张量。 -
kernelSize。要应用于输入数据的滑动卷积过滤器窗口的尺寸。
在本例中,我们将 5 设为 kernelSize,以指定方形的 5x5 卷积窗口。 -
filters。要应用于输入数据的尺寸为 kernelSize 的过滤器窗口数量。
在本例中,我们将对数据应用 8 个过滤器。 -
strides。滑动窗口的“步长”,即每次移动图片时过滤器都会移动多少像素。我们指定步长为 1,表示过滤器将以 1 像素为步长在图片上滑动。
activation。卷积完成后应用于数据的激活函数。
在本例中,我们将应用修正线性单元 (ReLU) 函数,这是机器学习模型中非常常见的激活函数。 -
kernelInitializer。用于随机初始化模型权重的方法,这对于训练动态非常重要。我们在这里不详细介绍初始化,但此处使用的 VarianceScaling 通常是一种很好的初始化程序选择。
展平数据表示法
model.add(tf.layers.flatten());
图片是高维数据,而卷积运算往往会增大传入其中的数据的大小。在将数据传递到最终分类层之前,我们需要将数据展平为一个长数组。密集层(我们会用作最终层)只需要采用 tensor1d,因而此步骤在许多分类任务中很常见。展平层中没有权重。它只是将其输入展开为一个长数组。
计算最终概率分布
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
我们将使用具有 softmax 激活的密集层计算 10 个可能的类的概率分布。得分最高的类将是预测的数字。
选择优化器和损失函数
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
我们编译了模型,以指定要跟踪的优化程序、损失函数和指标。
这里使用 categoricalCrossentropy 作为损失函数。顾名思义,当模型的输出为概率分布时,就会使用此函数。categoricalCrossentropy 会衡量模型的最后一层生成的概率分布与真实标签提供的概率分布之间的误差。
例如,如果我们的数字实际上代表 7,那么结果可能如下所示

分类交叉熵会生成一个数字,指示预测向量与真实标签向量的相似程度。
此处用于标签的数据表示法称为独热编码,在分类问题中很常见。对于每个示例,每个类都有相关联的概率。如果我们确切地知道应该如何进行设置,就可以将这种概率设为 1,而将其他值设为 0。
我们监控的另一个指标是 accuracy,对于分类问题,这是正确预测在所有预测中所占的百分比。
5. 训练模型
将以下函数复制到 script.js 文件中
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
将以下代码复制到 scrip.js 文件的 run 函数中
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
页面刷新等待几秒后,应该发现如下监控数据:


代码详解
监控指标
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
确定要监控的指标。我们将监控训练集的损失和准确率,以及验证集的损失和准确率(val_loss 和 acc_acc)。
准备作为张量的数据
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
在这里,我们创建了两个数据集:一个用于训练模型的训练集,一个用于在每个周期结束时测试模型的验证集。不过,在训练过程中,验证集中的数据绝不会向模型展示。
我们提供的数据类可让您轻松从图片数据中获取张量。但是,我们仍然会将这些张量重塑为模型所需的形状 ([num_examples, image_width, image_height, channels]),然后才能将其提供给模型。对于每个数据集,我们都有输入 (X) 和标签 (Y)。
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
调用 model.fit 来启动训练循环。我们还会传递 validationData 属性,以指明模型在每个周期后使用哪些数据来测试本身(但不用于训练)。
如果我们在使用训练数据时的表现良好,但在使用验证数据时表现不佳,则意味着模型很可能与训练数据过拟合,并且对从未出现过的输入泛化效果不佳。
6. 评估模型
将下面代码添加到 script.js 文件中。
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
代码讲解
做出预测
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
首先,我们需要进行一些预测。我们将拍摄 500 张图片并预测其中包含的数字。argmax 函数为我们提供概率最高的类的索引。注意,模型会输出每个类的概率。我们会找出最高概率,并指定将其用作预测。
显示每个类的准确率
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
借助一组预测和标签,我们可以计算每个类的准确率。
显示混淆矩阵
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
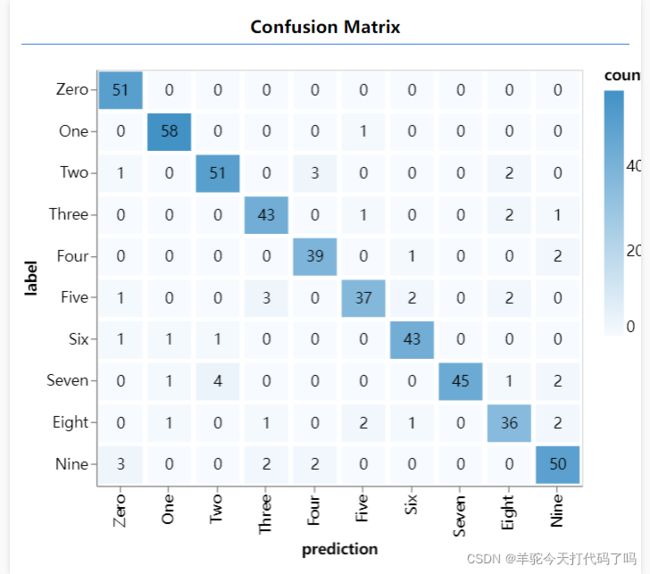
混淆矩阵与每个类的准确率相似,但会进一步细分以显示错误分类的模式。
显示评估
将下面代码添加到 script.js文件的 run 函数中
await showAccuracy(model, data);
await showConfusion(model, data);
刷新页面,等待评估结束,将会看到如下结果:

完整代码