Performer:用随机投影将Attention的复杂度线性化

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
Attention 机制的 复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的 Sparse Attention 以及 Google 前几个月搞出来的 Big Bird [1] ,等等;二是走线性化的思路,这部分工作我们之前总结在线性 Attention 的探索:Attention 必须有个 Softmax 吗?中,读者可以翻看一下。
本文则介绍一项新的改进工作 Performer,出自 Google 的文章 Rethinking Attention with Performers,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将 Attention 的复杂度线性化。

论文标题:
Rethinking Attention with Performers
论文链接:
https://arxiv.org/abs/2009.14794
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了 !看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?

Attention
我们知道,Attention 的一般定义为:
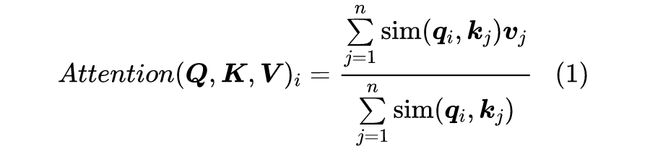
对于标准的 Scaled-Dot Attention 来说, (有时候指数部分还会多个缩放因子,这里我们就不显式写出来了),将整个序列的运算写成矩阵形式就是:
![]()
我们主要关心 Self Attention 场景,所以一般有 。在上式中, 这一步相当于要对 个向量对做内积,得到 个实数,因此不管时间还是空间复杂度都是 的。
而对于线性 Attention 来说, ,其中 是值域非负的激活函数。这样一来,Attention 的核心计算量(式(1)中的分子部分)就变成了:
![]()
上式左端的复杂度依然是 的,由于矩阵乘法满足结合律,我们可以先算后面两个矩阵的乘法,这样复杂度就可以降为 了,详细介绍还是请读者翻看之前的文章线性 Attention 的探索:Attention 必须有个 Softmax 吗?,这里就不过多展开了。

Performer
现在我们就可以进入到 Performer 的介绍了,开头已经说了,Performer 的出发点还是标准的 Attention,所以在它那里还是有 ,然后它希望将复杂度线性化,那就是需要找到新的 ,使得:
![]()
如果找到合理的从 到 的映射方案,便是该思路的最大难度了。
2.1 漂亮的随机映射
Performer 的最大贡献就在于,它找到了一个非常漂亮的映射方案:

我们先分析一下上式究竟说了什么。第一个等号意味着左右两端是恒等的,那也就意味着,只要我们从标准正态分布 中采样无穷无尽的 ,然后算出 的平均,结果就等于 ,写成积分形式就是:
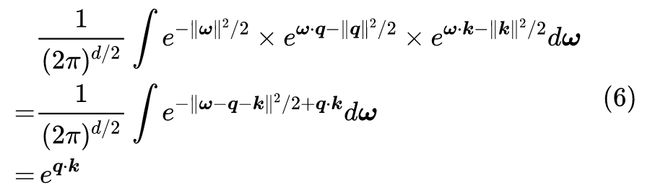
当然实际情况下我们只能采样有限的 m 个,因此就得到了第二个约等号,它正好可以表示为两个 m 维向量的内积的形式,这正是我们需要的 !
所以,借助这个近似,我们就可以将两个 d 维向量的内积的指数,转化为了两个 m 维向量的内积了,从而理论上来说,我们就可以将原来 head_size 为 d 的标准 Attention,转化为 head_size 为 m 的线性 Attention 了,这便是整篇论文的核心思路。
2.2 推导过程讨论
可能有些读者会比较关心式(5)的来源,这里展开讨论一下,当然如果不关心的读者可以直接跳过这一节。尽管直接通过计算积分可以验证式(5)是成立的,但对于任意定义的 ,是否可以找到类似的线性近似?
下面我们将会证明,类似的线性化方案可以通过一个一般化的流程找到,只不过得到的结果可能远远不如式(5)漂亮有效。
具体来说,对于任意的 ,我们可以改写为:
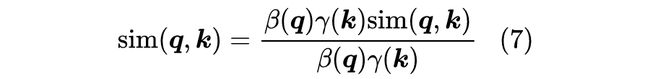
然后我们可以对 做傅立叶变换:
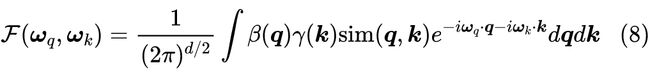
至于为什么要先乘以 ,那是因为直接对 做傅立叶变换的结果可能不好看甚至不存在,乘一个函数之后可能就可以了,比如可以让 ,只要 足够大,就可以让很多 都完成傅立叶变换了。
接着我们执行逆变换,并代回原式,就得到:
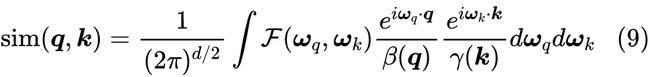
如果我们能算出 并完成归一化,那么它就可以成为一个可以从中采样的分布,从中可以采样出随机向量 来,然后近似转化为 组成的向量序列的内积。
当然,这里的运算可能涉及到虚数,而我们一般只是处理实数,但这问题不大,我们可以用欧拉公式 展开,整个运算过程只保留实部即可,形式不会有太大的变化。
理论上来说,整套流程可以走下来,不会有什么困难,但是相比式(5),存在的问题是:1)现在需要采样两组随机变量 ,会扩大估计的方差;2)最终保留实部后,得到的将会是 的组合形式,其结果无法保证非负性,需要额外的 clip 来处理。
而式(5)的特别之处在于, 可以改写为:
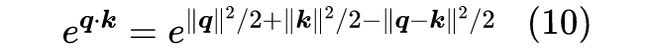
所以只需要转化为单个变量 的问题,而 的傅立叶变换正好是 ,所以做逆变换我们有:
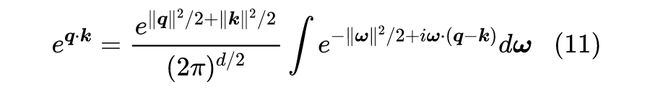
到这里,如果直接取实部展开,得到的也是 的组合,这就是原论文说的 形式的投影方案。不过,有一个更加巧妙的性质可以改变这一切!注意到上式是一个恒等式,所以我们可以左右两边都置换 ,结果是:

这便是式(5)。置换 使得上述左边保持不变,并且右边完全脱离虚数还保持了非负性,真的是集众多巧合于一身,“只此一家,别无分号”的感觉~
2.3 正交化降低方差
除了提出式(5)来对标准 Attention 进行线性化外,原论文还做了进一步的增强。在式(5), 是独立重复地从 中采样出来的,而原论文则指出,如果将各个 正交化,能有效地降低估算的方差,提高单次估算的平均精度。
注意,这里的正交化指的是保持 的模长不变,仅仅是对其方向进行施密特正交化。这个操作首先提出在同样是 Google 的论文 The Unreasonable Effectiveness of Structured Random Orthogonal Embeddings [2] 中,而 Performer 在其论文附录里边,足足花了 6 页纸来论证这个事情。这里照搬 6 页证明显然是不适合的,那对于我们来说,该怎么去理解这个策略比较好呢?
其实,这个策略有效的最根本原因,是采样分布 的各向同性,即其概率密度函数 只依赖于 的模长 ,所以它在方向上是均匀的。
而如果我们要降低估算的方差,那么就应该要降低采样的随机性,使得采样的结果更为均匀一些。而各个向量正交化,是方向上均匀的一种实现方式,换句话说,将各个 正交化促进了采样结果的均匀化,从而降低估算的方差。此外,正交化操作一般只对 有效,如果 ,原论文的处理方式是每 d 个向量为一组分别进行正交化。
我们可以联想到,正交化操作只是让采样的方向更加均匀化,如果要做得更加彻底些,可以让采样的模长也均匀化。具体来说,将标准正态分布变换为 d 维球坐标 [3] 得到其概率微元为:
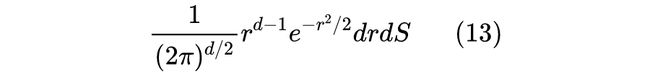
其中 代表在 d 维球面上的积分微元。上式就显示出,标准正态分布在方向是均匀的,模长的概率密度函数正比于 ,我们定义它的累积概率函数:

如果要采样 m 个样本,那么让 ,从中解出 m 个 作为模长就行了。

性能与效果
理论的介绍就到这里了,其实已经展开得都多了,一般来说只要对线性 Attention 有所了解的话,那么只要看到式(5),就能很快理解 Performer 的要点了,剩下的都是锦上添花的内容,不影响全文的主线。接下来我们就主要看对 Performer 的评测。
3.1 原论文的评测
我们先来看看原论文的评测,其实它的评测还是很丰富的,但是有点乱,对于主要关心 NLP 的读者来说可能还有点莫名其妙。
一开始是速度上的评测,这个不意外,反正就是序列长了之后 Performer 比标准的 Transformer 有明显优势:
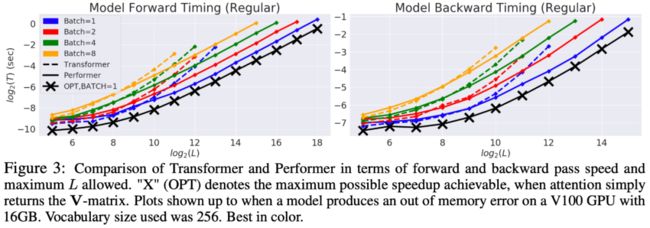
▲ Performer与标准Transformer的速度对比(实线:Performer,虚线:标准Transformer)
接着,是近似程度的比较,说明了采样正交化的有效性,以及所提的式(5)相比旧的基于 函数的形式的精确性:
 ▲ 左图:比较采样向量正交化的有效性;有图:比较Performer所用的近似与旧的基于三角函数的近似的精确性
▲ 左图:比较采样向量正交化的有效性;有图:比较Performer所用的近似与旧的基于三角函数的近似的精确性
那能不能达到我们一开始的预期目标——不用重新训练已训练好的模型呢?很遗憾,不行,原论文做了两个实验,显示 Performer 直接加载 Transformer 的权重不能恢复已有的结果,但经过 finetune 后可以迅速恢复回复。至于为什么一开始没有很好地回复,论文没有做展开分析。
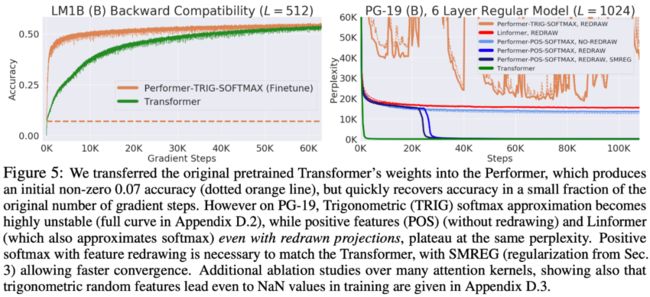
▲ Performer加载已训练好的Transformer权重实验
最后,论文还做了蛋白质序列和图像的实验,证明 Performer 对于长序列是很有效的,特别地,至少比 Reformer 有效,全文的实验差不多就是这样,内容很多,但有点找不到北的感觉。
3.2 其他论文的评测
也许是自己的同事都看不下去了,后来 Google 又出了两篇论文 Efficient Transformers: A Survey [4] 和 Long Range Arena: A Benchmark for Efficient Transformers [5] ,系统地评测和比较了已有的一些改进 Transformer 效率的方法,其中就包含了 Performer。
相比之下,这两篇论文给出的结果就直观多了,简单几个图表,就把各个模型的位置给表达清楚了。
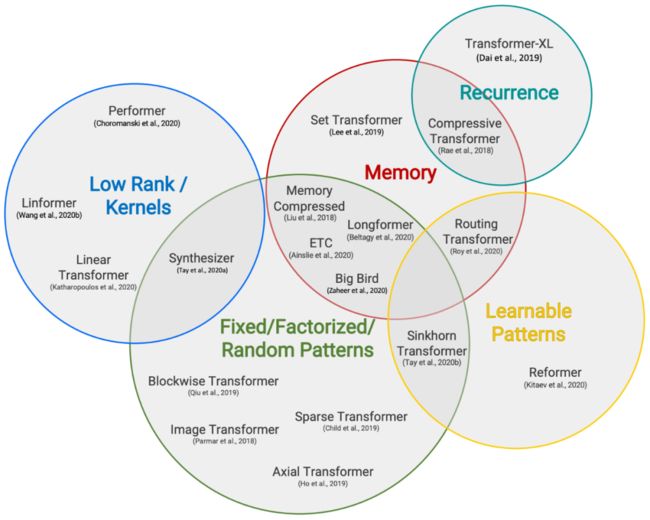
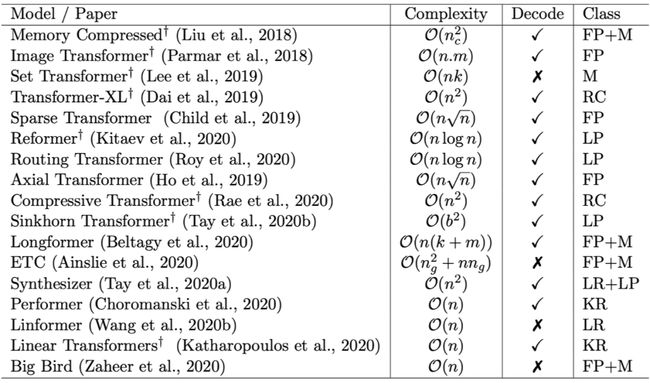
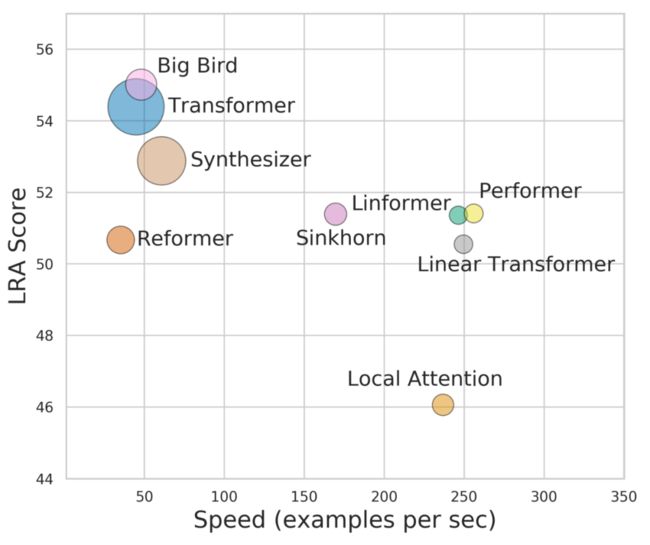 ▲ 各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
▲ 各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
更详细的评测信息,大家自行去看这两篇论文就好。

问题与思考
看起来 Performer 是挺不错的,那是不是说我们就可以用它来替代 Transformer 了?并不是,纵然 Performer 有诸多可取之处,但仍然存在一些无法解决的问题。
首先,为了更好地近似标准 Transformer,Performer 的 m 必须取得比较大,至少是 m > d,一般是 d 的几倍,这也就是说,Performer 的 head_size 要比标准 Transformer 要明显大。虽然理论上来说,不管 m 多大,只要它固定了,那么 Performer 关于序列长度的复杂度是线性的,但是 m 变大了,在序列长度比较短时计算量是明显增加的。
换句话说,短序列用 Performer 性能应该是下降的,根据笔者的估计,只有序列长度在 5000 以上,Performer 才会有比较明显的优势。
其次,目前看来 Performer(包括其他的线性 Attention)跟相对位置编码是不兼容的,因为相对位置编码是直接加在 Attention 矩阵里边的,Performer 连 Attention 矩阵都没有,自然是加不了的。此外,像 UniLM 这种特殊的 Seq2Seq 做法也做不到了,不过普通的单向语言模型还是可以做到的。
总之, 的 Attention 矩阵实际上也带来了很大的灵活性,而线性 Attention 放弃了这个 Attention 矩阵,也就放弃了这种灵活性了。
最后,也是笔者觉得最大的问题,就是 Performer 的思想是将标准的 Attention 线性化,所以为什么不干脆直接训练一个线性 Attention 模型,而是要想标准 Attention 靠齐呢?
从前面的最后一张图来看,Performer 并没有比 Linear Transformer 有大的优势(而且笔者觉得最后一张图的比较可能有问题,Performer 效果可能比 Linear Transformer 要好,但是速度怎么可能还超过了 Linear Transformer?Performer 也是转化为 Linear Transformer 的,多了转化这一步,速度怎能更快?),因此 Performer 的价值就要打上个问号了,毕竟线性 Attention 的实现容易得多,而且是通用于长序列/短序列,Performer 实现起来则麻烦得多,只适用于长序列。

全文的总结
本文主要介绍了 Google 的新模型 Performer,这是一个通过随机投影将标准 Attention 的复杂度线性化的工作,里边有不少值得我们学习的地方,最后汇总了一下各个改进版 Transformer 的评测结果,以及分享了笔者对 Performer 的思考。
参考文献
[1] https://arxiv.org/abs/2007.14062
[2] https://arxiv.org/abs/1703.00864
[3] https://en.wikipedia.org/wiki/N-sphere
[4] https://arxiv.org/abs/2009.06732
[5] https://arxiv.org/abs/2011.04006
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

