手把手教你深度学习和实战-----线性回归+梯度下降法
系列文章目录
第一章 手把手教你深度学习和实战-----线性回归+梯度下降法
第二章 手把手教你深度学习和实战-----逻辑回归算法
第三章 手把手教你深度学习和实战-----全连接神经网络
第四章 手把手教你深度学习和实战-----卷积神经网络
第五章 手把手教你深度学习和实战-----循环神经网络
文章目录
- 系列文章目录
- 前言
- 1、线性回归模型
-
- 1.2、案例1
- 2、最小二乘法
- 3、梯度下降法
-
- 3.2、案例2
- 总结
前言
线性回归算法是机器学习深度学习入门的必学的算法,其算法原理虽然简单,但是却蕴含着机器学习中的一些重要的基本思想。许多功能更为强大的非线性模型可在线性模型的基础上通过引入层级结构或高维映射而得。同时机器学习深度学习的核心思想就是优化求解,不断寻找最合适的参数,特别是理解了怎么利用梯度下降法去求解参数,对后续的神经网络的学习有着很大的帮助。
1、线性回归模型
假设给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) } D=\left\{\left(\boldsymbol{x}_1, y_1\right),\left(\boldsymbol{x}_2, y_2\right), \ldots,\left(\boldsymbol{x}_m, y_m\right)\right\} D={(x1,y1),(x2,y2),…,(xm,ym)},其中 x i = ( x i 1 ; x i 2 ; … ; x i d ) , y i ∈ R \boldsymbol{x}_i=\left(x_{i 1} ; \quad x_{i 2} ; \ldots ; x_{i d}\right), y_i \in \mathbb{R} xi=(xi1;xi2;…;xid),yi∈R,线性回归就是试图学的一个线性模型尽可能的准确的预测实际输出值。
通俗的讲就是求属性和结果之间的线性关系。线性回归模型的函数表达式可以用下面的式子来表达: f ( x ) = w 1 x 1 + w 2 x 2 + ⋯ + w n x n + b f(x)=w_1 x_1+w_2 x_2+\cdots+w_n x_n+b f(x)=w1x1+w2x2+⋯+wnxn+b 当然也可以用向量的形式来表达: f ( x ) = w T x + b f(\boldsymbol{x})=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b f(x)=wTx+b 从上面的式子来,可以得出线性回归模型就是要求得一组最优的 w i \mathcal{w}_i wi和 b b b来确定线性模型,使这个模型无限逼近现有的数据 x i x_i xi和结果 f ( x i ) f\left(x_i\right) f(xi)之间的关系。
当然上面所说的理论对于初学者来说可能比较难以理解,我们先考虑最简单的情况,那就是给定的数据集中的数据特征属性只有一个,那么该模型可以确定为:
f ( x ) = w x + b f(x)=w x+b f(x)=wx+b
1.2、案例1
下面我们来用一个简单的例子来理解回归模型。
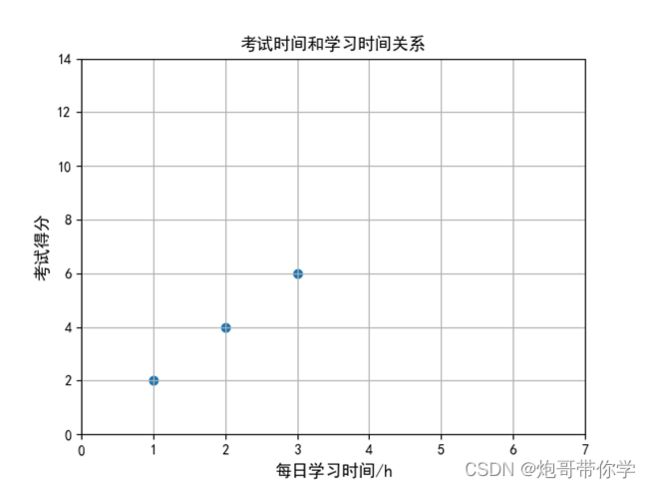
现在假设这样的一个案例,现在有一组这样的数据,是小明每天学习的时间和最后考试的分数的数据。数据如下表所示,同时想知道小明假设学习4个小时最后考试会得多少分?
| 每日的学习时间 | 考试得分 |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | ? |
这显然是一个回归任务,就是预测一个具体的数值。现在我们来将每日学习的时间和考试的得分用图画出来。貌似从图中可以得出一个规律那就是随着学习时间的增长,那么最后的考试的得分就会越高。
利用上述单特征线性模型来解决这个问题。首先这个数据的输入就一个,就是小明的学习时间。输出是考试的得分。因此该模型可以确定为: f ( x ) = w x + b f(x)=w x+b f(x)=wx+b 但是为了方便后面的理解和计算将该模型化简一下,我们只用一个 w \mathcal{w} w 来表达输入和输出之间的关系(尽管这样不太严谨,仅仅是为了方便后面的计算),因此现在的模型可以简化为:
f ( x ) = w x f(x)=w x f(x)=wx 现在我们的目的就是求一个最优的 w \mathcal{w} w来表达输入和输出之间的关系。但是什么样的 w \mathcal{w} w才叫最优呢?现在想想我们的模型不是要无限逼近学习时间和考试得分之间的关系么?既然是无限逼近,那是应该是确定一 w \mathcal{w} w使得输出的考试得分和真实的考试得分(也可以称为真实值或者标签)之间的差值越小越好,最好是0,如果是0的话那么说明这个 w \mathcal{w} w正确的描述出了输出和输出之间的关系(但是很显然这是不现实的,因为生活中所获取的数据存在噪声,数据之间的关系是存在一定的误差的)。
现在我们用一个公式计算输出和真实值之间的误差: loss = ( f ( x ) − y ) 2 = ( w x − y ) 2 \text { loss }=(f(x)-y)^2=(w x-y)^2 loss =(f(x)−y)2=(wx−y)2 当然我们的数据是有很多的,我们要计算所有数据真实值和输出之间的误差和并计算出平均值,这个函数为均方误差函数,也是线性回归模型的损失函数。 J ( x ) = 1 2 m ∑ i = 1 m ( f ( x i ) − y i ) 2 J(x)=\frac{1}{2 m} \sum_{i=1}^m\left(f\left(x_i\right)-y_i\right)^2 J(x)=2m1i=1∑m(f(xi)−yi)2 这样我们就有一个指标来评价不同 w \mathcal{w} w是否最优了,很显然使这个均方误差越小的 w \mathcal{w} w就越好,当然使均方误差最小(这里最小不一定是0,实际问题中由于数据中存在噪声,那么均方误差就不可能为0)的就是最优的 w \mathcal{w} w。
现在我们需要找到一个方法来帮助我们找到一个合理的 w \mathcal{w} w 。现在我们用一个最笨的方法来进行 w \mathcal{w} w的求解,该方法就是穷举法。我们尝试如下表的 w \mathcal{w} w值来计算均方误差和,很巧的是当 w \mathcal{w} w=2的时候,均方误差的值为0,这正是我们要找的最合理的 。具体计算如下图所示:
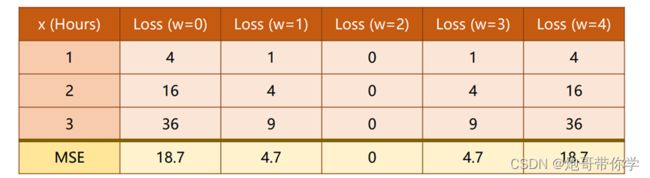
很显然穷举法是可以帮忙我们找到最优的 w \mathcal{w} w ,但是我们现实当中处理问题是很复杂的,往往输入的特征也是多个的,那么就意味着有多个 w \mathcal{w} w来表达输入和输出之间的关系,多一个 w \mathcal{w} w那么就意味着多一个维度,利用穷举法寻找合理的 w \mathcal{w} w难度就上升一个维度(这就是我为什么不加入b计算的原因,这里的b计算出来最后也是0,当然这是我先前知道答案的原因,在处理实际任务的时候尽量不要舍去参数b),因此利用穷举法是可以找到最优的 w \mathcal{w} w ,但是在多特征输入的问题上是不现实的。那么有别的方法来帮助找到最佳的 w \mathcal{w} w么?很显然是有的,该方法就叫梯度下降法。
2、最小二乘法
在讲梯度下降法之前,我们先思考一个问题,loss值的函数是一个关于 的二次函数,很显然2次函数的的图像图下图所示:
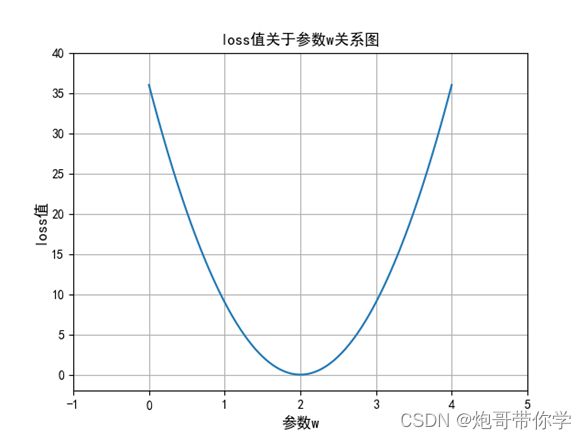
这个二次函数显然是有一个最小值点的,同时就是该函数的极值点。那么我们可不可以利用求导然后令导数为0来计算其极值点,然后使导数为0的 点不就是我们一直要找的最优 w \mathcal{w} w么?下面来尝试一下求损失函数的导数。
损失函数为: J ( x ) = 1 2 m ∑ i = 1 m ( f ( x i ) − y i ) 2 J(x)=\frac{1}{2 m} \sum_{i=1}^m\left(f\left(x_i\right)-y_i\right)^2 J(x)=2m1i=1∑m(f(xi)−yi)2 求损失函数关于 的导数: ∂ J ( w ) ∂ w = ∂ 1 2 m ∑ i = 1 m ( w x i − y i ) 2 ∂ w = 1 2 m ∑ i = 1 m ∂ ( w x i − y i ) 2 ∂ w = 1 2 m ∑ i = 1 m × 2 ( w x i − y i ) × ∂ ( w x i − y i ) ∂ w = 1 m ∑ i = 1 m ( w x i − y i ) x i \begin{aligned} &\frac{\partial J(w)}{\partial w}=\frac{\partial \frac{1}{2 m} \sum_{i=1}^m\left(w x_i-y_i\right)^2}{\partial w} \\ &=\frac{1}{2 m} \sum_{i=1}^m \frac{\partial\left(w x_i-y_i\right)^2}{\partial w} \\ &=\frac{1}{2 m} \sum_{i=1}^m \times 2\left(w x_i-y_i\right) \times \frac{\partial\left(w x_i-y_i\right)}{\partial w} \\ &=\frac{1}{m} \sum_{i=1}^m\left(w x_i-y_i\right) x_i \end{aligned} ∂w∂J(w)=∂w∂2m1∑i=1m(wxi−yi)2=2m1i=1∑m∂w∂(wxi−yi)2=2m1i=1∑m×2(wxi−yi)×∂w∂(wxi−yi)=m1i=1∑m(wxi−yi)xi 令损失函数的导数为0,求解得: w = 1 m ∑ i = 1 m y i x i w=\frac{1}{m} \sum_{i=1}^m \frac{y_i}{x_i} w=m1i=1∑mxiyi 按如上的求导并求得使得损失函数最小的 w \mathcal{w} w的表达式。并且通过现有的数据进行计算最终也可以得到 的值为2,很显然这样的方法比穷举法要好的多,不需要盲目的去在一个范围里面猜。导致最后结果的不确定性。既然是这样的话,那么我们为什么还要梯度下降法来求一个最优的 w \mathcal{w} w值呢,这个最小二乘法难道不是最好的吗?答案显然是否定的。
我们前面已经讲了线性回归模型的向量表达式是如下式所示: f ( x ) = w T x + b f(\boldsymbol{x})=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b f(x)=wTx+b为了方便理解原理的同时也方便计算,我们将参数b纳入到矩阵w中,此时数据特征矩阵x则为: X = ( x 11 x 12 … x 1 d 1 x 21 x 22 … x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 … x m d 1 ) \mathbf{X}=\left(\begin{array}{ccccc} x_{11} & x_{12} & \ldots & x_{1 d} & 1 \\ x_{21} & x_{22} & \ldots & x_{2 d} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m 1} & x_{m 2} & \ldots & x_{m d} & 1 \end{array}\right) X=⎝ ⎛x11x21⋮xm1x12x22⋮xm2……⋱…x1dx2d⋮xmd11⋮1⎠ ⎞ 矩阵w为: w = ( w 1 w 2 w 3 ⋮ w m b ) w=\left(\begin{array}{c} w_1 \\ w_2 \\ w_3 \\ \vdots \\ w_m \\ b \end{array}\right) w=⎝ ⎛w1w2w3⋮wmb⎠ ⎞ 得到线性回归模型的向量表达式如下式所示: f ( X ) = X w f(\boldsymbol{X})=\boldsymbol{X} \boldsymbol{w} f(X)=Xw 很显然 X \boldsymbol{X} X和W都是一个矩阵,利用最小二乘法对这个矩阵求最优的W矩阵参数。计算的步骤如下所示: J ( w ) = 1 2 ( J ( w ) − Y ) 2 = 1 2 ( X w − Y ) 2 = 1 2 ( X w − Y ) ⊤ ( X w − Y ) = 1 2 ( w ⊤ X ⊤ − Y ⊤ ) ( X w − Y ) = 1 2 ( w ⊤ X ⊤ X w − Y ⊤ X w − w ⊤ X ⊤ Y + Y ⊤ Y ) \begin{aligned} J(w) &=\frac{1}{2}(J(w)-Y)^2 \\ &=\frac{1}{2}(X w-Y)^2 \\ &=\frac{1}{2}(X w-Y)^{\top}(X w-Y) \\ &=\frac{1}{2}\left(w^{\top} X^{\top}-Y^{\top}\right)(X w-Y) \\ &=\frac{1}{2}\left(w^{\top} X^{\top} X w-Y^{\top} X w-w^{\top} X^{\top} Y+Y^{\top} Y\right) \end{aligned} J(w)=21(J(w)−Y)2=21(Xw−Y)2=21(Xw−Y)⊤(Xw−Y)=21(w⊤X⊤−Y⊤)(Xw−Y)=21(w⊤X⊤Xw−Y⊤Xw−w⊤X⊤Y+Y⊤Y) 现在针对J(w)求导数,首先要知道如下的知识点: ∂ A B ∂ B = A T , ∂ A T B ∂ A = B , ∂ X T A X ∂ X = 2 A X 4 \frac{\partial A B}{\partial B}=A^T, \quad \frac{\partial A^T B}{\partial A}=B, \quad \frac{\partial X^T A X}{\partial X}=2 A X^4 ∂B∂AB=AT,∂A∂ATB=B,∂X∂XTAX=2AX4 按这个规律对函数进行求导: ∂ J ( w ) ∂ w = 1 2 ( ∂ w ⊤ X ⊤ X w ∂ w − ∂ Y ⊤ X w ∂ w − ∂ w ⊤ X ⊤ Y ∂ w ) = 1 2 [ 2 X ⊤ x w − ( Y ⊤ X ) ⊤ − ( X ⊤ Y ) ] = 1 2 [ 2 X ⊤ × w − 2 ( X ⊤ Y ) ] = X ⊤ X w − X ⊤ Y \begin{aligned} \frac{\partial J(w)}{\partial w} &=\frac{1}{2}\left(\frac{\partial w^{\top} X^{\top} X w}{\partial w}-\frac{\partial Y^{\top} X w}{\partial w}-\frac{\partial w^{\top} X^{\top} Y}{\partial w}\right) \\ &=\frac{1}{2}\left[2 X^{\top} x w-\left(Y^{\top} X\right)^{\top}-\left(X^{\top} Y\right)\right] \\ &=\frac{1}{2}\left[2 X^{\top} \times w-2\left(X^{\top} Y\right)\right] \\ &=X^{\top} X w-X^{\top} Y \end{aligned} ∂w∂J(w)=21(∂w∂w⊤X⊤Xw−∂w∂Y⊤Xw−∂w∂w⊤X⊤Y)=21[2X⊤xw−(Y⊤X)⊤−(X⊤Y)]=21[2X⊤×w−2(X⊤Y)]=X⊤Xw−X⊤Y令导数为 ∂ J ( w ) ∂ w = 0 \frac{\partial J(w)}{\partial w}=0 ∂w∂J(w)=0,解得: X ⊤ X w − X ⊤ Y = 0 X ⊤ X = X ⊤ Y W = ( X ⊤ X ) − 1 X ⊤ Y \begin{aligned} X^{\top} X w-X^{\top} Y &=0 \\ X \top X &=X^{\top} Y \\ W &=\left(X^{\top} X\right)^{-1} X^{\top} Y \end{aligned} X⊤Xw−X⊤YX⊤XW=0=X⊤Y=(X⊤X)−1X⊤Y 很显然,利用最小二乘法也是可以将最优0求解出来的,但是在现实的任务中 X ⊤ X X^{\top} X X⊤X往往不是满秩矩阵,这就意味着 X ⊤ X X^{\top} X X⊤X不可逆。那么最小二乘法就不可以帮助我们求得最优参数,因此最小二乘法不能适用于所有的模型。
事实上,不管是机器学习还是深度我们都希望模型是不断的从数据样本中学到有用的东西,而不是一步求解,这是不符合人工智能的初衷的,因此下面来看看现在目前在深度学习神经网络参数求解中应用最多的方法—梯度下降法。
3、梯度下降法
前面已经对最小二乘法进行了讲解,其中发现最小二乘法并不能在任何场景下求出最优的w。因此我们引入了一个新的方法,梯度下降法来进行最优w的求解。
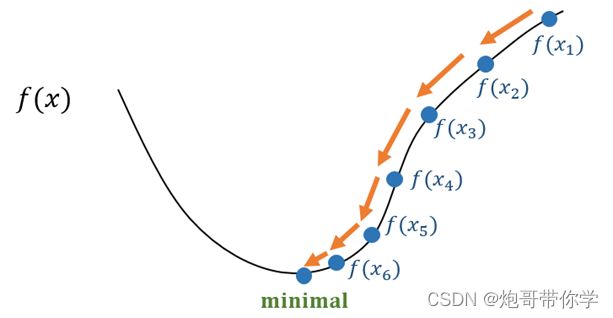
现在我们来假设有这样的一个场景,在一个漆黑的夜晚,一个人要下山,但是他完全看不到周围的环境,只能通过手去感知。因此这个人就想到一个办法,朝着自己的四周去摸山体的坡度,如果摸到一个方法的坡度是向下的并且也是最陡峭的,那么就走到这个手摸到的位置,就是通过这样的方法不断一步一步的走,这个人终于走到了山底。具体可以想象成下图,那个黑点就是人。
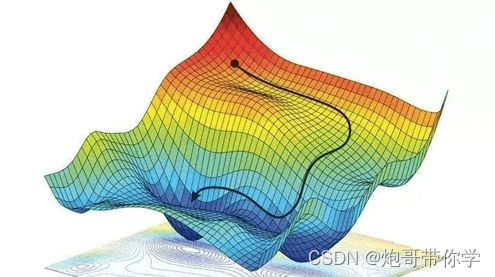
上面的场景可以很形象的描述梯度下降法去寻找最优参数的过程。
首先损失函数要是一个可微分的函数,我们目标是找到这个可微分函数的最小值的参数。
同时在刚刚的场景中有一个很重要的方法就是找到坡度向下同时也是最陡峭的方向;在可微分函数中微分就是这个函数的梯度,而梯度是一个向量,梯度的方向就是指向函数上升最快的方向,那么很显然,梯度的反方向就是函数下降最快的方向。
场景中还有一个很重要的信息是这个人每次下山的距离是平时走路一步的距离,试想一下,假设这个人一步可以跨的很大,大到可以从这个山头跨到那个山头,那么这个人就永远不能下山,一直在两个山头反复横跳。
因此在利用梯度下降法进行参数求解的时候,梯度更新的步伐不能太大,太大可能会导致跳过使损失函数最小的参数值,梯度更新的步伐同样也不能太小,太小的话,寻找最优参数的速度会变慢,同时也消耗计算机的计算资源。这个参数寻找的步伐我们称之为学习率。因此梯度下降法参数更新的计算公式就如下所示: w = w − a ∂ J ( w ) ∂ w w=w-a \frac{\partial J(w)}{\partial w} w=w−a∂w∂J(w) 其中上式中 w为模型的参数,a 为学习率。具体的寻找最优参数的过程就如下图,通过求梯度不断的逼近损失函数的最小值,从而找到最优参数。
下面我们就用一个实际的例子来看看参数是怎么更新的。
3.2、案例2
现在假设有一个损失函数为下式: J ( w ) = 4 w 2 J(w)=4 w^2 J(w)=4w2 首先需要随机初始化w,假设w=4,同时设定学习率为0.1。损失函数的导数如下式所示: w 0 = 4 , a = 0.1 , ∂ J ( w ) ∂ w = 8 w w_0=4, a=0.1, \frac{\partial J(w)}{\partial w}=8 w w0=4,a=0.1,∂w∂J(w)=8w 第一次w更新的过程如下式计算: w 1 = w 0 − 0.1 × ∂ J ( ω ) ∂ w = 4 − 0.1 × 8 × 4 = 0.8 \begin{aligned} w_1 &=w_0-0.1 \times \frac{\partial J(\omega)}{\partial w} \\ &=4-0.1 \times 8 \times 4 \\ &=0.8 \end{aligned} w1=w0−0.1×∂w∂J(ω)=4−0.1×8×4=0.8 后续w更新的过程如下式: W 2 = 0.8 − 0.1 × 8 × 0.8 = 0.16 W 2 = 0.16 − 0.1 × 8 × 0.16 = 0.032 W 4 = 0.032 − 0.1 × 8 × 0.032 = 0.0064 \begin{aligned} &W_2=0.8-0.1 \times 8 \times 0.8=0.16 \\ &W_2=0.16-0.1 \times 8 \times 0.16=0.032 \\ &W_4=0.032-0.1 \times 8 \times 0.032=0.0064 \end{aligned} W2=0.8−0.1×8×0.8=0.16W2=0.16−0.1×8×0.16=0.032W4=0.032−0.1×8×0.032=0.0064 很显然这个学习率计算出来的值已经越来越和最优值差别越远了,因此在学习率设置的时候一定要小心,这里有一个经验值就是学习率往往设置为0.01或0.001。
现在我们回到文章开头的小明学习成绩和学习时间关系的例子中来,看看怎么通过梯度下降法来进行最优w的求解,这里还要注意的是,这里每次计算的梯度,是所有的数据的对应的梯度的平均值,计算公式如下所示: J ( w ) ∂ w = 1 m ∂ ∑ i = 1 m ( f ( x i ) − y i ) 2 ∂ w \frac{J(w)}{\partial w}=\frac{1}{m} \frac{\partial \sum_{i=1}^m\left(f\left(x_i\right)-y_i\right)^2}{\partial w} ∂wJ(w)=m1∂w∂∑i=1m(f(xi)−yi)2 按照这个公式去计算的话,假设初始w=4,同时设定学习率为0.01 w 0 = 4 w 1 = 4 − 0.01 × 1 m ∂ J ( w ) ∂ w = 3.813 w 2 = 3.644 w 3 = 3.490 ⋮ w 99 = 2.000111 \begin{aligned} &w_0=4 \\ &w_1=4-0.01 \times \frac{1}{m} \frac{\partial J(w)}{\partial w}=3.813 \\ &w_2=3.644 \\ &w_3=3.490 \\ &\vdots \\ &w_{99}=2.000111 \end{aligned} w0=4w1=4−0.01×m1∂w∂J(w)=3.813w2=3.644w3=3.490⋮w99=2.000111
从上面的计算可以看到,经过100轮的不断的梯度更新,w已经及其接近最优值2了,很显然这样的结果已经很满足我们的需要了,同时求解的过程如下图所示,可以看到结果不断的逼近损失为0的方向,而红色点的位置也正是最优参数的位置。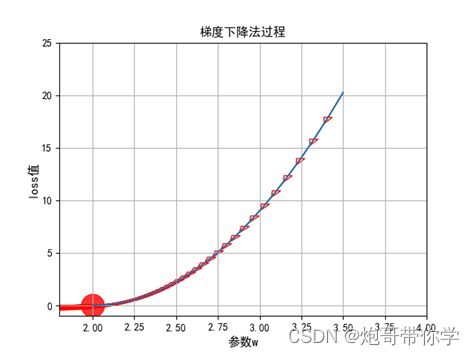
因此梯度下降法可以通过不断的计算梯度从而帮助找到使损失最小的参数,上述举例都是在特征只有一个的情况下,当我们的数据的特征有2个或者以上的时候还可以用梯度下降法去求得最优参数么,答案是肯定的,如下图(当参数大于2的时候维度就超过3维了,就画不出图了)所示,是求两个参数权重最优解,具体方法和一个参数一样,就是求损失函数关于该参数的偏导数,然后利用梯度下降法的公式不断迭代求解,最终在损失函数趋于平稳不再下降为止。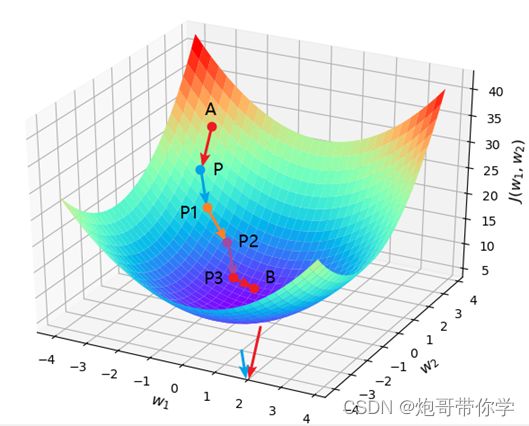
总结
最后来总结一下梯度下降法和最小二乘法的特点:
梯度下降法的适用范围比较广泛,在后续的深度学习神经网络的参数求解的时候就是利用梯度下降法对其求解,并且神经网络的参数往往都是几千上万的参数;但是梯度下降法对于较小的数据量来说它的速度并没有优势。
最小二乘法在数据比较少同时特征比较少的情况下速度往往更快,但是当数量级达到一定的时候,还是梯度下降法更快,因为正规方程中需要对矩阵求逆,而求逆的时间复杂的是n的3次方。
最后再重申一遍,线性回归是一个很具有代表性的算法,将其学好对于后续的深度学习的学习有着很大的帮助,特别是梯度下降法是后续深度学习的核心所在。