pandas数据处理简单实例 ——基于jupyter
import pandas as pd
import numpy as np
1 读取数据
data=pd.read_csv('zhihuyonghu.csv')
2 查看数据特点
查看前5个数据:
data[:5]

data.head()#默认前五个数据

查看后5个数据
data[-5:]#data.tail(5)
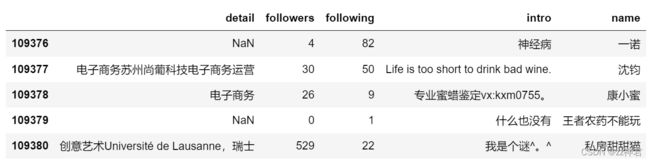
查看长度
data.index
![]()
或者
len(data)
![]()
3 数据预处理
3.1 数据预处理
查看 followers , following , name 各列是否有重复值
data.duplicated(['followers'])

pd.value_counts(data.duplicated(['followers']))

data.duplicated(['following'])
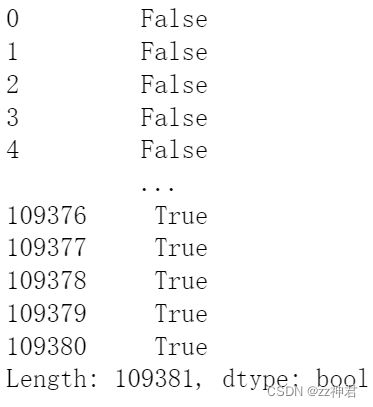
pd.value_counts(data.duplicated(['following']))

data.duplicated(['name'])
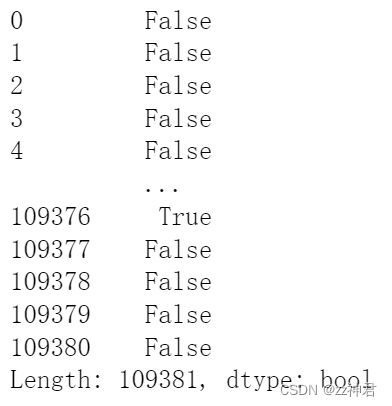
pd.value_counts(data.duplicated(['name']))

统计重复值的个数
pd.value_counts(data.duplicated())

去掉重复值
data.drop_duplicates(inplace=True)
pd.value_counts(data.duplicated())

3.2 去掉name列中值为nan的数据
查看一下data中name的值是否有为null的数据
'NaN'in data.name
False
data[data.name.isnull()]
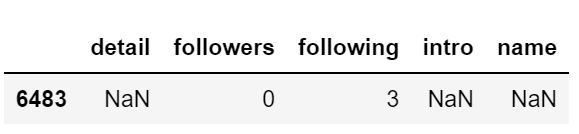
将为null的name数据删除
data.name.dropna()

3.3 数据整理
查看followers的数据类型
data.followers.dtype
![]()
改变followers的数据类型,将其改为int32
data.followers=data.followers.str.replace(',','')
data.followers.astype(np.int32)

3.4 数据分组
目标:想知道在不同区间内,比如0-10,10-100,100-1000,1000-10000,10000-100000等等的following数
bin=[0,10,100,1000,10000,100000]
cats = pd.cut(data.following,bin)
cats

cats.value_counts()

data.following.dtype
![]()
可视化:
import matplotlib.pyplot as plt
%matplotlib inline
pd.cut(data['following'],bin,right=False).value_counts().plot.bar(rot=20)
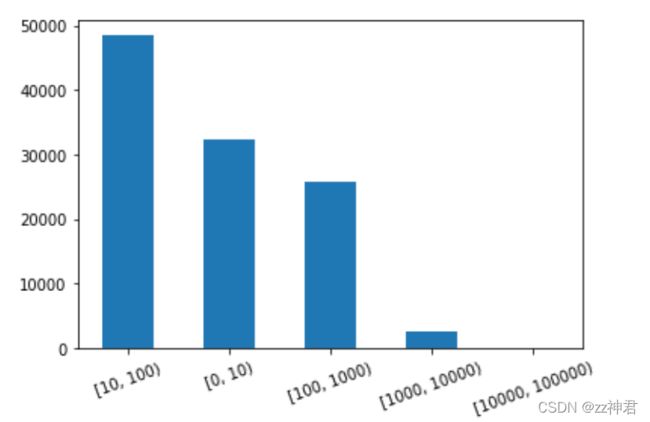
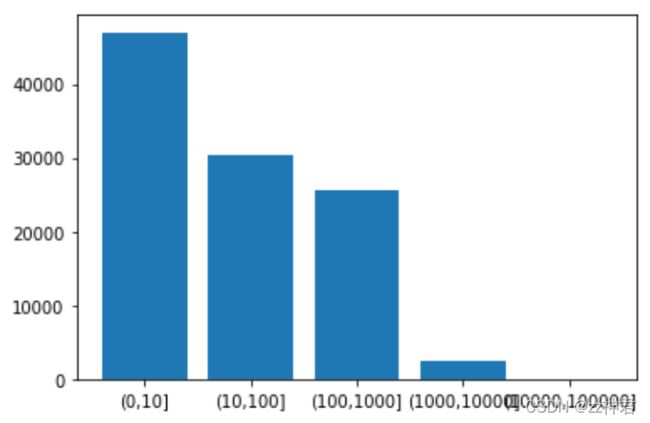
x=['(0,10]','(10,100]','(100,1000]','(1000,10000]','(10000,100000]']
y=cats.value_counts()
plt.bar(x,y)
plt.show()
问题:如果想知道details中有多少人从事互联网相关工作?
data.detail.str.contains('互联网').value_counts()
或者:
sum(data.detail.str.contains('互联网').dropna())

全部代码已上传:https://download.csdn.net/download/weixin_43808138/84995516