深度神经网络在人工智能的应用中,包括语音识别、计算机视觉、自然语言处理等各方面,在取得巨大成功的同时,这些深度神经网络需要巨大的计算开销和内存开销,严重阻碍了资源受限下的使用。模型压缩是对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在受限的硬件环境中。
许多网络结构中,如VGG-16网络,参数数量1亿3千多万,占用500MB空间,需要进行309亿次浮点运算才能完成一次图像识别任务。相关研究表明,并不是所有的参数都在模型中发挥作用,存在着大量冗余地节点,仅仅只有少部分(5-10%)权值参与着主要的计算,也就是说,仅仅训练小部分的权值参数就可以达到和原来网络相近的性能。
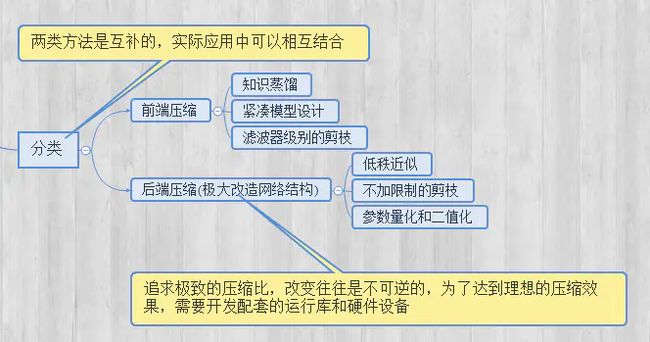
模型压缩方法主要有:
紧凑的模型设计、剪枝(Pruning)、量化(Quantization)、低秩近似/分解(low-rank Approximation/factorization)、知识蒸馏(Knowledge distillation)
| 模型压缩方法 | 描述 | 应用场景 | 方法细节 |
| 紧凑的模型设计 | 设计特别的卷积和来保存参数 | 只有卷积层 | 设计了特殊的结构卷积滤波器来降低存储和计算复杂度,只能从零开始训练 |
| 剪枝(Pruning) | 删除对准确率影响不大的参数 | 卷积和全连接层 | 针对模型参数的冗余性,试图去除冗余和不重要的项,支持从零训练和预训练 |
| 量化(Quantization) | |||
| 低秩近似/分解 (low-rank Approximation/factorization) |
使用矩阵对参数进行分解估计 | 卷积和全连接层 | 使用矩阵/张量分解来估计深度学习模型的信息参数,支持从零训练和预训练 |
| 知识蒸馏(Knowledge distillation) | 训练一个更紧凑的神经网络来从大的模型蒸馏知识 | 卷积和全连接层 | 通过学习一个蒸馏模型,训练一个更紧凑的神经网络来重现一个更大的网络的输出,只能从零开始训练 |
也能把模型压缩分为前端压缩和后端压缩:
紧凑的模型结构设计
轻量网络设计方向的主要代表论文是 MobileNet v1 / v2,ShuffleNet v1 / v2 等,其主要思想是利用 Depthwise Convolution、Pointwise Convolution、Group Convolution 等计算量更小、更分散的卷积操作代替标准卷积。也有将5x5卷积替换为两个3x3卷积、深度可分离卷积(3x3卷积替换为1*1卷积(降维作用)+3*3卷积)等轻量化设计。
分组卷积
分组卷积即将输入的feature maps分成不同的组(沿channel维度进行分组),然后对不同的组分别进行卷积操作,即每一个卷积核至于输入的feature maps的其中一组进行连接,而普通的卷积操作是与所有的feature maps进行连接计算。分组数k越多,卷积操作的总参数量和总计算量就越少(减少k倍)。然而分组卷积有一个致命的缺点就是不同分组的通道间减少了信息流通,即输出的feature maps只考虑了输入特征的部分信息,因此在实际应用的时候会在分组卷积之后进行信息融合操作,接下来主要讲两个比较经典的结构,ShuffleNet[1]和MobileNet[2]结构。
1) ShuffleNet结构:
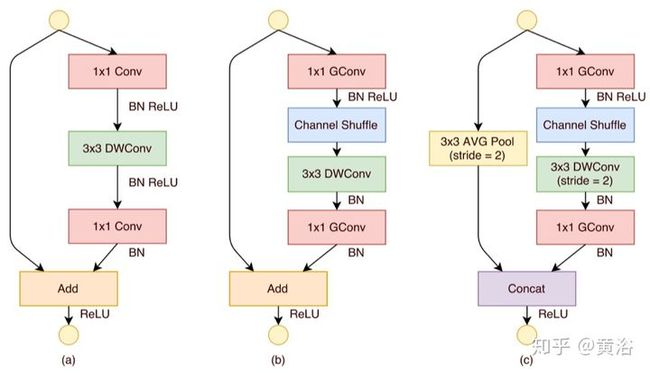
如上图所示,图a是一般的group convolution的实现效果,其造成的问题是,输出通道只和输入的某些通道有关,导致全局信息 流通不畅,网络表达能力不足。图b就是shufflenet结构,即通过均匀排列,把group convolution后的feature map按通道进行均匀混合,这样就可以更好的获取全局信息了。 图c是操作后的等价效果图。在分组卷积的时候,每一个卷积核操作的通道数减少,所以可以大量减少计算量。
2) MobileNet结构:

如上图所示,mobilenet采用了depthwise separable convolutions的思想,采用depthwise (或叫channelwise)和1x1 pointwise的方法进行分解卷积。其中depthwise separable convolutions即对每一个通道进行卷积操作,可以看成是每组只有一个通道的分组卷积,最后使用开销较小的1x1卷积进行通道融合,可以大大减少计算量。
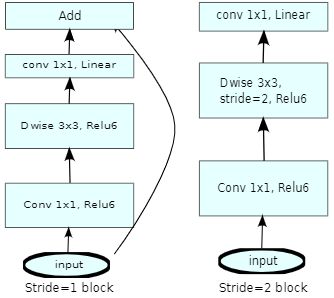
3、MobileNetV2:
随后谷歌提出了一种改进模型称为MobileNet V2,其提高了它在多个任务和基准、不同模型尺寸范围内的性能,并定义了一种称为SSDLite的新框架。其特点是:
- 基于逆残差结构(inverted residual structure),其中薄的瓶颈(bottleneck)层之间设置快捷连接(skip connection)。
- 中间扩展层使用轻型深度卷积来过滤特征作为非线性的来源。
- 另外,去除窄层中的非线性以保持表征能力是很重要的。
- 最后,它允许输入/输出域与变换的表达相分离。
ReLU一定会带来信息损耗,而且这种损耗是没有办法恢复的。可以有两种解决方案:
- 将ReLU替换成线性激活函数;
- 较多的通道数能减少信息损耗,那么使用更多的通道。
ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
分解卷积
分解卷积,即将普通的kxk卷积分解为kx1和1xk卷积,通过这种方式可以在感受野相同的时候大量减少计算量,同时也减少了参数量,在某种程度上可以看成是使用2k个参数模拟k*k个参数的卷积效果,从而造成网络的容量减小,但是可以在较少损失精度的前提下,达到网络加速的效果。
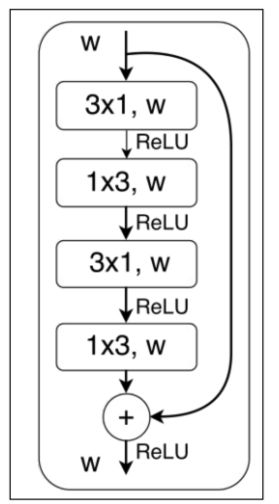
右图是在图像语义分割任务上取得非常好的效果的ERFNet[3]的主要模块,称为NonBottleNeck结构借鉴自ResNet[4]中的Non-Bottleneck结构,相应改进为使用分解卷积替换标准卷积,这样可以减少一定的参数和计算量,使网络更趋近于efficiency。
Bottleneck结构

右图为ENet[5]中的Bottleneck结构,借鉴自ResNet中的Bottleneck结构,主要是通过1x1卷积进行降维和升维,能在一定程度上能够减少计算量和参数量。其中1x1卷积操作的参数量和计算量少,使用其进行网络的降维和升维操作(减少或者增加通道数)的开销比较小,从而能够达到网络加速的目的。
C.ReLU[7]结构
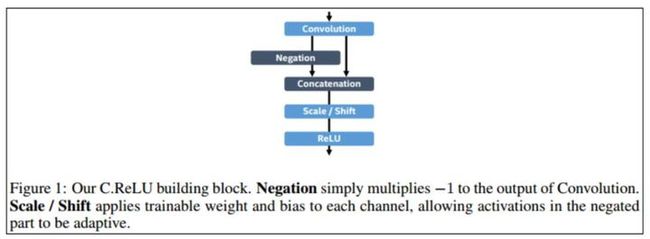
C.ReLU来源于CNNs中间激活模式引发的。输出节点倾向于是"配对的",一个节点激活是另一个节点的相反面,即其中一半通道的特征是可以通过另外一半通道的特征生成的。根据这个观察,C.ReLU减少一半输出通道(output channels)的数量,然后通过其中一半通道的特征生成另一半特征,这里使用 negation使其变成双倍,最后通过scale操作使得每个channel(通道)的斜率和激活阈值与其相反的channel不同。
SqueezeNet[8]结构
SqueezeNet思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是1x1的卷积kernel,数量记为S11;在expand层里面有1x1和3x3的卷积kernel,数量分别记为E11和E33,要求S11 < input map number。expand层之后将 1x1和3x3的卷积output feature maps在channel维度拼接起来。
神经网络搜索[18]
神经结构搜索(Neural Architecture Search,简称NAS)是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
NAS的原理是给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估,可以通过NAS自动搜索出高效率的网络结构。
总结
本节主要介绍了模型模型设计的思路,同时对模型的加速设计以及相关缺陷进行分析。总的来说,加速网络模型设计主要是探索最优的网络结构,使得较少的参数量和计算量就能达到类似的效果。
低秩近似/分解
这一部分的思路比较简单,如果把原先网络的权值矩阵当作满秩矩阵来看,我们可以使用多种矩阵低秩近似方法,将两个大矩阵的乘法操作拆解为多个小矩阵之间的一系列乘法操作,降低整体的计算量,加速模型的执行速度。
优点:
- 可以降低存储和计算消耗;
- 一般可以压缩2-3倍;
- 精度几乎没有损失;
缺点:
- 利用低秩近似重构参数矩阵不能保证模型的性能 ;
- 随着模型复杂度的提升,搜索空间急剧增大。
在这方面有几篇经典的论文
Jaderberg M, Vedaldi A, Zisserman A. Speeding up convolutional neural networks with low rank expansions[J]. arXiv preprint arXiv:1405.3866, 2014.
这篇文章提出用$k*1+1*k$的卷积核来替代$k*k$的卷积核的方法来进行低秩近似,下图可以很直观的表达作者思想:

该方法在场景文字识别中实验在无精度损失的情况下达到原来的2.5倍速,而达到4.5倍速的同时仅损失1%的accuracy。
2014-Exploiting Linear StructureWithin Convolutional Networks for Efficient Evaluation
2015-NPIS-Structured transforms for small footprint deep learning
2015-Accelerating Very Deep Convolutional Networks for Classification and Detection
2014-Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition||pytorch代码||借鉴博客
2015-Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications||pytorch代码
2017-High performance ultra-low-precision convolutions on mobile devices
存在问题
应该说矩阵分解方法经过过去的发展已经非常成熟了,所以在2017、2018年的工作就只有Tensor Ring和Block Term分解在RNN的应用两篇相关文章了。
那么为什么Low-Rank在这两年不再流行了呢?除了刚才提及的分解方法显而易见、比较容易实现之外,另外一个比较重要的原因是现在越来越多网络中采用1×1的卷积,而这种小的卷积使用矩阵分解的方法很难实现网络加速和压缩。
模型剪枝 (pruning)
深度学习网络模型存在着大量冗余的参数,将权重矩阵中相对“不重要”的权值剔除,从而达到降低计算资源消耗和提高实时性的效果,而对应的技术则被称为模型剪枝。

剪枝步骤:使用L1\L2正则训练一个稀疏模型,进行模型剪裁,再训练,再剪裁...。如果一次剪枝过多,网络可能会损坏,无法恢复。所以在实践中,这是一个迭代执行的步骤。
模型剪枝算法根据粒度的不同,可以粗分为4种粒度:
- 细粒度剪枝(fine-grained):对连接或者神经元进行剪枝,它是粒度最小的剪枝。
- 向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
- 核剪枝(kernel-level):去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
- 滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变。
细粒度剪枝(fine-grained),向量剪枝(vector-level),核剪枝(kernel-level)方法在参数量与模型性能之间取得了一定的平衡,但是网络的拓扑结构本身发生了变化,需要专门的算法设计来支持这种稀疏的运算,被称之为非结构化剪枝。非结构化修剪方法(直接修剪权重)的一个缺点是所得到的权重矩阵是稀疏的,如果没有专用硬件/库,则不能达到压缩和加速的效果。
滤波器剪枝(Filter-level)只改变了网络中的滤波器组和特征通道数目,所获得的模型不需要专门的算法设计就能够运行,被称为结构化剪枝。除此之外还有对整个网络层的剪枝,它可以被看作是滤波器剪枝(Filter-level)的变种,即所有的滤波器都丢弃。
细粒度剪枝(连接剪枝):其中重点在于两个,一个是如何评估一个连接的重要性,另一个是如何在剪枝后恢复模型的性能。
第一步:训练一个基准模型。
第二步:对权重值的幅度进行排序,去掉低于一个预设阈值的连接,得到剪枝后的网络。
第三步:对剪枝后网络进行微调以恢复损失的性能,然后继续进行第二步,依次交替,直到满足终止条件,比如精度下降在一定范围内。
- 优点:保留模型精度
- 缺点:非结构化剪枝,对局部进行调整,依赖于专门的运行库和硬件设备
粗粒度剪枝(通道剪枝):相对于连接权重剪枝,粗粒度剪枝其实更加有用,它可以得到不需要专门的算法支持的精简小模型。
第一个是基于重要性因子,即评估一个通道的有效性,再配合约束一些通道使得模型结构本身具有稀疏性,从而基于此进行剪枝。
第二个是利用重建误差来指导剪枝,间接衡量一个通道对输出的影响。
第三个是基于优化目标的变化来衡量通道的敏感性。
- 优点:模型速度和大小有效提升,保证了通用性
- 缺点:容易造成精度大幅下降,同时模型残留冗余
迭代式剪枝:训练权重-->剪枝-->训练
动态剪枝:剪枝与训练同时进行,一般指稀疏约束的方法,具体做法是在网络的优化目标中加入权重的稀疏正则项,使得训练时网络的部分权重趋向于0,而这些0值正是剪枝对象。
【知乎】模型剪枝技术原理及其发展现状和展望
【CSDN文章】深度学习模型压缩与优化加速
【博客园】深度学习网络模型压缩剪枝详细分析
模型量化
神经网络的参数类型一般是32位浮点型,通过对网络中的浮点值进行量化处理,一来可以降低权重所需的比特数,二来浮点数计算可以转换为位操作(或者小整数计算),不仅能够减少网络的存储,而且能够大幅度进行加速。量化后的权值张量是一个高度稀疏的有很多共享权值的矩阵,对非零参数,我们还可以进行定点压缩,以获得更高的压缩率。常见的量化方法有:二值神经网络、同或网络、三值权重网络、量化神经网络等。最为典型就是二值网络、XNOR网络等。其主要原理就是采用1 bit对网络的输入、权重、响应进行编码。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。但是,如果原始网络结果不够复杂,由于二值网络会较大程度降低模型的表达能力。因此现阶段有相关的论文开始研究n-bit编码方式成为n值网络或者多值网络或者变bit、组合bit量化来克服二值网络表达能力不足的缺点。
优点:模型大小减少8-16倍,模型性能损失很小
缺点:
- 压缩率大时,性能显著下降
- 依赖专门的运行库,通用性较差
Gong et al. 对参数值使用 K-Means 量化。
Vanhoucke et al. 使用了 8 比特参数量化可以在准确率损失极小的同时实现大幅加速。
Han S 提出一套完整的深度网络的压缩流程:首先修剪不重要的连接,重新训练稀疏连接的网络。然后使用权重共享量化连接的权重,再对量化后的权重和码本进行霍夫曼编码,以进一步降低压缩率。如图 2 所示,包含了三阶段的压缩方法:修剪、量化(quantization)和霍夫曼编码。修剪减少了需要编码的权重数量,量化和霍夫曼编码减少了用于对每个权重编码的比特数。对于大部分元素为 0 的矩阵可以使用稀疏表示,进一步降低空间冗余,且这种压缩机制不会带来任何准确率损失。这篇论文获得了 ICLR 2016 的 Best Paper。
二值神经网络
二值神经网络(BNN)要求不仅对权重做二值化,同时也要对网络中间每层的输入值进行二值化,这一操作使得所有参与乘法运算的数据都被强制转换为“-1”、“+1”二值。我们知道计算机的硬件实现采用了二进制方式,而神经网络中处理过的二值数据 恰好与其一致,这样一来就可以考虑从比特位的角度入手优化计算复杂度。
BNN也正是这样做的:将二值浮点数“-1”、“+1”分别用一个比特“0”、“1”来表示,这样,原本占用32个比特位的浮点数现在只需1个比特位就可存放,稍加处理就可以实现降低神经网络前向过程中内存占用的效果。同时,一对“-1”、“+1”进行乘法运算,得到的结果依然是“-1”、“+1”,通过这一特性就可将原本的浮点数乘法用一个比特的位运算代替,极大的压缩了计算量,进而达到提高速度、降低能耗的目的。然而,大量的实验结果表明,BNN只在小规模数据集上取得了较好的准确性,在大规模数据集上则效果很差。
- 优点:网络体积小,运算速度快,有时可避免部分网络的 overfitting
- 缺点:
- 二值神经网络损失的信息相对于浮点精度是非常大
- 粗糙的二值化近似导致训练时模型收敛速度非常慢
三值神经网络
三值网络主要是指三值权重网络(TWN)。二值网络中精度的损失主要来自于 对数据强置为(-1, +1)时与本身全精度之间产生的误差,而神经网络中训练得到的 权重服从均值为 0 的正态分布,这就意味着绝大部分权重在二值后会产生将近1的误差,这对计算结果造成的影响将是十分巨大的。为了解决这一问题,提高二值网络的正确率,Fengfu Li和 Bo Zhang等人在二值的基础上提出了TWN。
TWN的核心在于计算出量化阈值Δ,将数值大小处于阈值内的数据强置为0,其他值依然强置为-1或+1,对于阈值的计算,作者也给了论证,能够最小三值化误差所带来的精度损失,还能够使神经网络权重稀疏化,减小计算复杂度的同时也能得到更好的准确率和泛化能力。在运行效率上,TWN与BWN相当,但是准确率却有着明显的提升。
知识蒸馏
一个复杂模型可由多个简单模型或者强约束条件训练得到。复杂模型特点是性能好,但其参数量大,计算效率低。小模型特点是计算效率高,但是其性能较差。知识蒸馏是让小模型去拟合大模型,从而让小模型学到与大模型相似的函数映射。使其保持其快速的计算速度前提下,同时拥有复杂模型的性能,达到模型压缩的目的。模型蒸馏的关键在于监督特征的设计,例如使用 Soft Target 所提供的类间相似性作为依据 [9],或使用大模型的中间层特征图 [10] 或 attention map [11] 作为暗示,对小网络进行训练。整体的框架图如图下所示。

卷积算法优化
卷积运算本身有多种算法实现方式,例如滑动窗、im2col + gemm、FFT、Winograd卷积等方式。这些卷积算法在速度上并没有绝对的优劣,因为每种算法的效率都很大程度上取决于卷积运算的尺寸。因此,在优化模型时,我们应该对模型的各个卷积层有针对性的选用效率最高的卷积算法,从而充分利用不同卷积算法的优势。
总体压缩效果评价指标有哪些?
网络压缩评价指标包括运行效率、参数压缩率、准确率。与基准模型比较衡量性能提升时,可以使用提升倍数(speed up)或提升比例(ratio)。
- 准确率:目前,大部分研究工作均会测量 Top-1 准确率,只有在 ImageNet 这类大型数据集上才会只用 Top-5 准确率。
- 参数压缩率:统计网络中所有可训练的参数,根据机器浮点精度转换为字节(byte)量纲,通常保留两位有效数字以作近似估计。
- 运行效率:可以从网络所含浮点运算次数(FLOP)、网络所含乘法运算次数(MULTS)或随机实验测得的网络平均前向传播所需时间这 3 个角度来评价
几种轻量化网络结构对比
| 网络结构 | TOP1 准确率/% | 参数量/M | CPU运行时间/ms |
|---|---|---|---|
| MobileNet V1 | 70.6 | 4.2 | 123 |
| ShuffleNet(1.5) | 69.0 | 2.9 | - |
| ShuffleNet(x2) | 70.9 | 4.4 | - |
| MobileNet V2 | 71.7 | 3.4 | 80 |
| MobileNet V2(1.4) | 74.7 | 6.9 | 149 |
网络压缩未来研究方向有哪些?
网络剪枝、网络精馏和网络分解都能在一定程度上实现网络压缩的目的。回归到深度网络压缩的本质目的上,即提取网络中的有用信息,以下是一些值得研究和探寻的方向。
(1) 权重参数对结果的影响度量.深度网络的最终结果是由全部的权重参数共同作用形成的,目前,关于单个卷积核/卷积核权重的重要性的度量仍然是比较简单的方式,尽管文献[14]中给出了更为细节的分析,但是由于计算难度大,并不实用。因此,如何通过更有效的方式来近似度量单个参数对模型的影响,具有重要意义。
(2) 学生网络结构的构造。学生网络的结构构造目前仍然是由人工指定的,然而,不同的学生网络结构的训练难度不同,最终能够达到的效果也有差异。因此,如何根据教师网络结构设计合理的网络结构在精简模型的条件下获取较高的模型性能,是未来的一个研究重点。
(3) 参数重建的硬件架构支持。通过分解网络可以无损地获取压缩模型,在一些对性能要求高的场景中是非常重要的。然而,参数的重建步骤会拖累预测阶段的时间开销,如何通过硬件的支持加速这一重建过程,将是未来的一个研究方向。
(4) 任务或使用场景层面的压缩。大型网络通常是在量级较大的数据集上训练完成的,比如,在 ImageNet上训练的模型具备对 1 000 类物体的分类,但在一些具体场景的应用中,可能仅需要一个能识别其中几类的小型模型。因此,如何从一个全功能的网络压缩得到部分功能的子网络,能够适应很多实际应用场景的需求。
(5) 网络压缩效用的评价。目前,对各类深度网络压缩算法的评价是比较零碎的,侧重于和被压缩的大型网络在参数量和运行时间上的比较。未来的研究可以从提出更加泛化的压缩评价标准出发,一方面平衡运行速度和模型大小在不同应用场景下的影响;另一方面,可以从模型本身的结构性出发,对压缩后的模型进行评价。
目前有哪些深度学习模型优化加速方法?
模型优化加速方法
模型优化加速能够提升网络的计算效率,具体包括:
- Op-level的快速算法:FFT Conv2d (7x7, 9x9), Winograd Conv2d (3x3, 5x5) 等;
- Layer-level的快速算法:Sparse-block net [1] 等;
- 优化工具与库:TensorRT (Nvidia), Tensor Comprehension (Facebook) 和 Distiller (Intel) 等;
TensorRT加速原理
在计算资源并不丰富的嵌入式设备上,TensorRT之所以能加速神经网络的的推断主要得益于两点:
- TensorRT支持int8和fp16的计算,通过在减少计算量和保持精度之间达到一个理想的trade-off,达到加速推断的目的。
- TensorRT对于网络结构进行了重构和优化,主要体现在一下几个方面。
- TensorRT通过解析网络模型将网络中无用的输出层消除以减小计算。
- 对于网络结构的垂直整合,即将目前主流神经网络的Conv、BN、Relu三个层融合为了一个层,例如将图1所示的常见的Inception结构重构为图2所示的网络结构。
- 对于网络结构的水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,例如图2向图3的转化。

图1
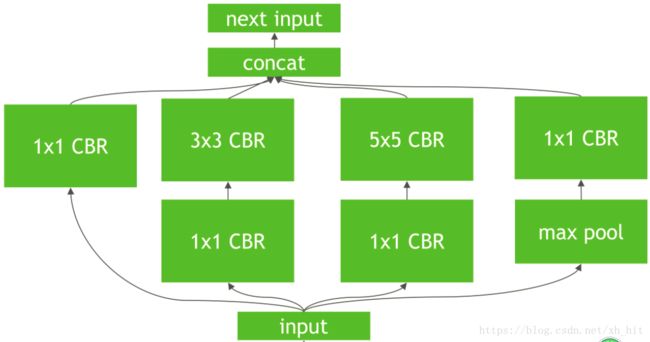
图2
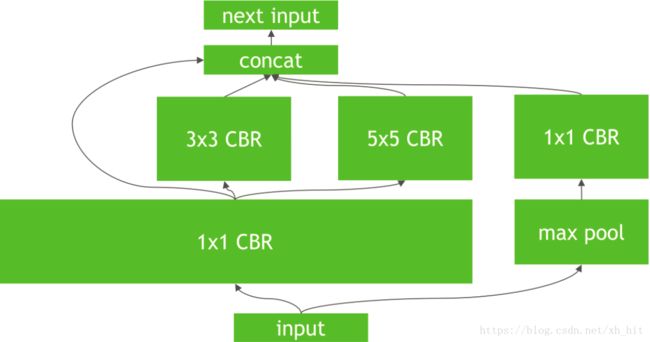
图3
以上3步即是TensorRT对于所部署的深度学习网络的优化和重构,根据其优化和重构策略,第一和第二步适用于所有的网络架构,但是第三步则对于含有Inception结构的神经网络加速效果最为明显。
Tips: 想更好地利用TensorRT加速网络推断,可在基础网络中多采用Inception模型结构,充分发挥TensorRT的优势。
TensorRT如何优化重构模型?
若训练的网络模型包含TensorRT支持的操作
- 对于Caffe与TensorFlow训练的模型,若包含的操作都是TensorRT支持的,则可以直接由TensorRT优化重构
- 对于MXnet, PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接优化重构;
若训练的网络模型包含TensorRT不支持的操作
- TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点;
- 不支持的操作可通过Plugin API实现自定义并添加进TensorRT计算图;
- 将深度网络划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部则采用其他框架实现,如MXnet或PyTorch
TensorRT加速效果如何?
以下是在TitanX (Pascal)平台上,TensorRT对大型分类网络的优化加速效果:
| Network | Precision | Framework/GPU:TitanXP | Avg.Time(Batch=8,unit:ms) | Top1 Val.Acc.(ImageNet-1k) |
|---|---|---|---|---|
| Resnet50 | fp32 | TensorFlow | 24.1 | 0.7374 |
| Resnet50 | fp32 | MXnet | 15.7 | 0.7374 |
| Resnet50 | fp32 | TRT4.0.1 | 12.1 | 0.7374 |
| Resnet50 | int8 | TRT4.0.1 | 6 | 0.7226 |
| Resnet101 | fp32 | TensorFlow | 36.7 | 0.7612 |
| Resnet101 | fp32 | MXnet | 25.8 | 0.7612 |
| Resnet101 | fp32 | TRT4.0.1 | 19.3 | 0.7612 |
| Resnet101 | int8 | TRT4.0.1 | 9 | 0.7574 |
影响神经网络速度的4个因素(再稍微详细一点)
- FLOPs(FLOPs就是网络执行了多少multiply-adds操作);
- MAC(内存访问成本);
- 并行度(如果网络并行度高,速度明显提升);
- 计算平台(GPU,ARM)
压缩和加速方法如何选择?
1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝方法,特别是二值量化权值和激活、结构化剪枝。其他方法虽然能够有效的压缩模型中的权值参数,但无法减小计算中隐藏的内存大小(如特征图)。
2)如果在应用中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要考虑的方法。相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法。
3)若需要一次性端对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法。
4)一般情况下,参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度。对于需要稳定的模型分类的应用,非结构化剪枝成为首要选择。
5)若采用的数据集较小时,可以考虑知识蒸馏方法。对于小样本的数据集,学生网络能够很好地迁移教师模型的知识,提高学生网络的判别性。
6)主流的5个深度神经网络压缩与加速算法相互之间是正交的,可以结合不同技术进行进一步的压缩与加速。如:韩松等人结合了参数剪枝和参数共享;温伟等人以及Alvarez等人结合了参数剪枝和低秩分解。此外对于特定的应用场景,如目标检测,可以对卷积层和全连接层使用不同的压缩与加速技术分别处理。
参考
【简书】模型压缩总览
【知乎】模型加速概述与模型裁剪算法技术解析
【深度学习大讲堂】【一文看懂】深度神经网络加速和压缩新进展年度报告
【知乎】深度学习模型压缩与加速综述
【CSDN文章】深度学习模型压缩与优化加速 (Model Compression and Acceleration Overview)
【CSDN文章】TensorRT Inference 引擎简介及加速原理简介
【论文】深度神经网络压缩与加速综述
【CSDN】闲话模型压缩之量化(Quantization)篇
【pytorch官方文档】量化
【pytorch官方文档】剪裁教程
【知乎】模型压缩深度学习(李宏毅)(十三)