离线数仓搭建_04_zookeeper-flume-kafka框架配置
点击右下方:专栏目录查看全文

文章目录
-
- 4.3 Zookeeper安装(48-49)
-
- 4.3.1 安装ZK
- 4.3.2 ZK集群启动停止脚本
- 4.4 Kafka安装(50-52)
-
- 4.4.1 Kafka集群安装
- 4.4.2 Kafka集群启动停止脚本
- 4.4.3 Kafka常用命令
- 4.4.4 项目经验之Kafka机器数量计算
- 4.4.5 项目经验之Kafka压力测试
- 4.4.6 项目经验值Kafka分区数计算
- 4.5 采集日志Flume(53-56)
-
- 4.5.1 日志采集Flume安装
- 4.5.2 项目经验之Flume组件选型
- 4.5.3 日志采集Flume配置
- 4.5.4 Flume拦截器
- 4.5.5 测试Flume-Kafka通道
- 4.5.6 日志采集Flume启动停止脚本
- 4.6 消费Kafka数据Flume(57-60)
-
- 4.6.1 项目经验之Flume组件选型
- 4.6.2 消费者Flume配置
- 4.6.3 Flume时间戳拦截器
- 4.6.4 消费者Flume启动停止脚本
- 4.6.5 项目经验之Flume内存优化
- 4.7 采集通道启动/停止脚本
上文访问:离线数仓搭建_03_Hadoop的配置与优化测试
下文访问:尽请期待!
4.3 Zookeeper安装(48-49)
4.3.1 安装ZK
内容请参考:小憨皮全套大数据集群环境配置
4.3.2 ZK集群启动停止脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
4.4 Kafka安装(50-52)
4.4.1 Kafka集群安装
关于Kafka的安装这里不做详细叙述:如需获取文档教程可访问:
https://blog.csdn.net/m0_58022371/article/details/126440789
- 1.解压安装包
- 2.在kafka下创建logs文件夹
- 3.修改config/server.properties文件中的相关内容
- 4.配置环境变量,分发Kafka
4.4.2 Kafka集群启动停止脚本
(1)在/home/atguigu/bin目录下创建脚本kf.sh
[atguigu@hadoop102 bin]$ vim kf.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x kf.sh
(3)kf集群启动脚本
[atguigu@hadoop102 module]$ kf.sh start
(4)kf集群停止脚本
[atguigu@hadoop102 module]$ kf.sh stop
4.4.3 Kafka常用命令
1)查看Kafka Topic列表
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
2)创建Kafka Topic
进入到/opt/module/kafka/目录下创建日志主题
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic topic_log
3)删除Kafka Topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --topic topic_log
4)Kafka生产消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
5)Kafka消费消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
–from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
6)查看Kafka Topic详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--describe --topic topic_log
4.4.4 项目经验之Kafka机器数量计算
Kafka机器数量(经验公式)= 2 *(峰值生产速度 * 副本数 / 100)+ 1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
1)峰值生产速度
峰值生产速度可以压测得到。
2)副本数
副本数默认是1个,在企业里面2-3个都有,2个居多。
副本多可以提高可靠性,但是会降低网络传输效率。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 *(50 * 2 / 100)+ 1 = 3台
4.4.5 项目经验之Kafka压力测试
1)Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
Kafka压测时,在硬盘读写速度一定的情况下,可以查看到哪些地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
2)Kafka Producer压力测试
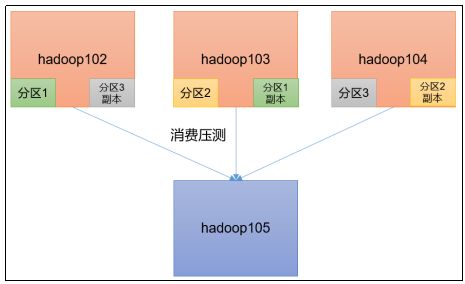
(0)压测环境准备
①hadoop102、hadoop103、hadoop104的网络带宽都设置为100mbps。
②关闭hadoop102主机,并根据hadoop102克隆出hadoop105(修改IP和主机名称)
③hadoop105的带宽不设限
④创建一个test topic,设置为3个分区2个副本
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 2 --partitions 3 --topic test
(1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
说明:
record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量。
(2)Kafka会打印下面的信息
699884 records sent, 139976.8 records/sec (13.35 MB/sec), 1345.6 ms avg latency, 2210.0 ms max latency.
713247 records sent, 141545.3 records/sec (13.50 MB/sec), 1577.4 ms avg latency, 3596.0 ms max latency.
773619 records sent, 153862.2 records/sec (14.67 MB/sec), 2326.8 ms avg latency, 4051.0 ms max latency.
773961 records sent, 154206.2 records/sec (15.71 MB/sec), 1964.1 ms avg latency, 2917.0 ms max latency.
776970 records sent, 154559.4 records/sec (15.74 MB/sec), 1960.2 ms avg latency, 2922.0 ms max latency.
776421 records sent, 154727.2 records/sec (15.76 MB/sec), 1960.4 ms avg latency, 2954.0 ms max latency.
参数解析:Kafka的吞吐量15m/s左右是否符合预期呢?
hadoop102、hadoop103、hadoop104三台集群的网络总带宽30m/s左右,由于是两个副本,所以Kafka的吞吐量30m/s ➗ 2(副本) = 15m/s
结论:网络带宽和副本都会影响吞吐量。
(4)调整batch.size
batch.size默认值是16k。
batch.size较小,会降低吞吐量。比如说,批次大小为0则完全禁用批处理,会一条一条发送消息);
batch.size过大,会增加消息发送延迟。比如说,Batch设置为64k,但是要等待5秒钟Batch才凑满了64k,才能发送出去。那这条消息的延迟就是5秒钟。
[atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=500
输出结果
69169 records sent, 13833.8 records/sec (1.32 MB/sec), 2517.6 ms avg latency, 4299.0 ms max latency.
105372 records sent, 21074.4 records/sec (2.01 MB/sec), 6748.4 ms avg latency, 9016.0 ms max latency.
113188 records sent, 22637.6 records/sec (2.16 MB/sec), 11348.0 ms avg latency, 13196.0 ms max latency.
108896 records sent, 21779.2 records/sec (2.08 MB/sec), 12272.6 ms avg latency, 12870.0 ms max latency.
(5)linger.ms
如果设置batch size为64k,但是比如过了10分钟也没有凑够64k,怎么办?
可以设置,linger.ms。比如linger.ms=5ms,那么就是要发送的数据没有到64k,5ms后,数据也会发出去。
(6)总结
同时设置batch.size和 linger.ms,就是哪个条件先满足就都会将消息发送出去
Kafka需要考虑高吞吐量与延时的平衡。
3)Kafka Consumer压力测试
(1)Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[atguigu@hadoop102 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
①参数说明:
--broker-list指定Kafka集群地址
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
②测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2021-08-03 21:17:21:778, 2021-08-03 21:18:19:775, 514.7169, 8.8749, 5397198, 93059.9514
开始测试时间,测试结束数据,共消费数据514.7169MB,吞吐量8.8749MB/s
(2)调整fetch-size
①增加fetch-size值,观察消费吞吐量。
[atguigu@hadoop102 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 100000 --messages 10000000 --threads 1
②测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2021-08-03 21:22:57:671, 2021-08-03 21:23:41:938, 514.7169, 11.6276, 5397198, 121923.7355
(3)总结
吞吐量受网络带宽和fetch-size的影响
4.4.6 项目经验值Kafka分区数计算
(1)创建一个只有1个分区的topic
(2)测试这个topic的producer吞吐量和consumer吞吐量。
(3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
(4)然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)
例如:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;
分区数 = 100 / 20 = 5分区
https://blog.csdn.net/weixin_42641909/article/details/89294698
分区数一般设置为:3-10个
4.5 采集日志Flume(53-56)
4.5.1 日志采集Flume安装
关于Flume的安装这里不做详细叙述:如需获取文档教程可访问:
https://blog.csdn.net/m0_58022371/article/details/126440789

4.5.2 项目经验之Flume组件选型
1)Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。不会丢数据,但是有可能会导致数据重复。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
- Exec source:适用于监控一个实时追加的文件,不能实现断点续传
- Spooldir Source :适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步
- Taildir Source:适合用于监听多个实时追加的文件,并且能够实现断点续传。
2)Channel
采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
4.5.3 日志采集Flume配置
1)Flume配置分析
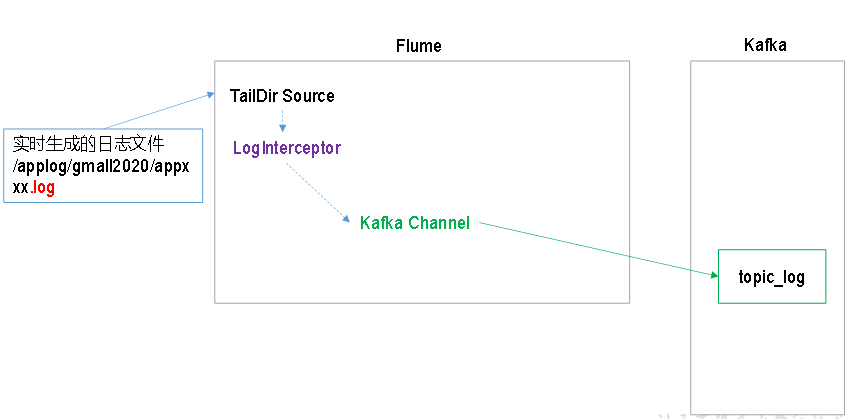
Flume直接读log日志的数据,log日志的格式是app.yyyy-mm-dd.log。
2)Flume的具体配置如下:
(1)在/opt/module/flume/conf目录下创建file-flume-kafka.conf文件
[atguigu@hadoop102 conf]$ vim file-flume-kafka.conf
在文件配置如下内容
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.* #监控文件名称
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json #断点续传
a1.sources.r1.interceptors = i1 #配置拦截器
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder# 配置拦截器类型
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel #类型
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092 #连接
a1.channels.c1.kafka.topic = topic_log #数据发送到kafkatopic_log
a1.channels.c1.parseAsFlumeEvent = false #将传输的数据截去头留下身体
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1
4.5.4 Flume拦截器
1)创建Maven工程flume-interceptor
2)创建包名:com.atguigu.flume.interceptor
3)在pom.xml文件中添加如下配置
org.apache.flume
flume-ng-core
1.9.0
provided
com.alibaba
fastjson
1.2.62
maven-compiler-plugin
2.3.2
1.8
1.8
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
注意:scope中provided的含义是编译时用该jar包。打包时不用。因为集群上已经存在flume的jar包。只是本地编译时用一下。
4)在com.atguigu.flume.interceptor包下创建JSONUtils类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
public static boolean isJSONValidate(String log){
try {
JSON.parse(log);
return true;
}catch (JSONException e){
return false;
}
}
}
5)在com.atguigu.flume.interceptor包下创建LogInterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
6)打包

7)需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
[atguigu@hadoop102 lib]$ ls | grep interceptor
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
8)分发Flume到hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync flume/
9)分别在hadoop102、hadoop103上启动Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
[atguigu@hadoop103 flume]$ bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
4.5.5 测试Flume-Kafka通道
(1)生成日志
[atguigu@hadoop102 ~]$ lg.sh
(2)消费Kafka数据,观察控制台是否有数据获取到
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
说明:如果获取不到数据,先检查Kafka、Flume、Zookeeper是否都正确启动。再检查Flume的拦截器代码是否正常。
4.5.6 日志采集Flume启动停止脚本
(1)在/home/atguigu/bin目录下创建脚本f1.sh
[atguigu@hadoop102 bin]$ vim f1.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
说明1:nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
说明2:awk 默认分隔符为空格
说明3:$2是在“”双引号内部会被解析为脚本的第二个参数,但是这里面想表达的含义是awk的第二个值,所以需要将他转义,用\$2表示。
说明4:xargs 表示取出前面命令运行的结果,作为后面命令的输入参数。
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x f1.sh
(3)f1集群启动脚本
[atguigu@hadoop102 module]$ f1.sh start
(4)f1集群停止脚本
[atguigu@hadoop102 module]$ f1.sh stop
4.6 消费Kafka数据Flume(57-60)
4.6.1 项目经验之Flume组件选型
1)FileChannel和MemoryChannel区别
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
选型:
金融类公司、对钱要求非常准确的公司通常会选择FileChannel
传输的是普通日志信息(京东内部一天丢100万-200万条,这是非常正常的),通常选择MemoryChannel。
2)FileChannel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据。
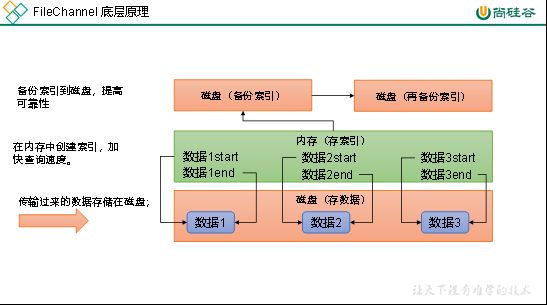
3)Sink:HDFS Sink
(1)HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
(2)HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下:
①文件在达到128M时会滚动生成新文件
②文件创建超3600秒时会滚动生成新文件
4.6.2 消费者Flume配置
1)Flume配置分析
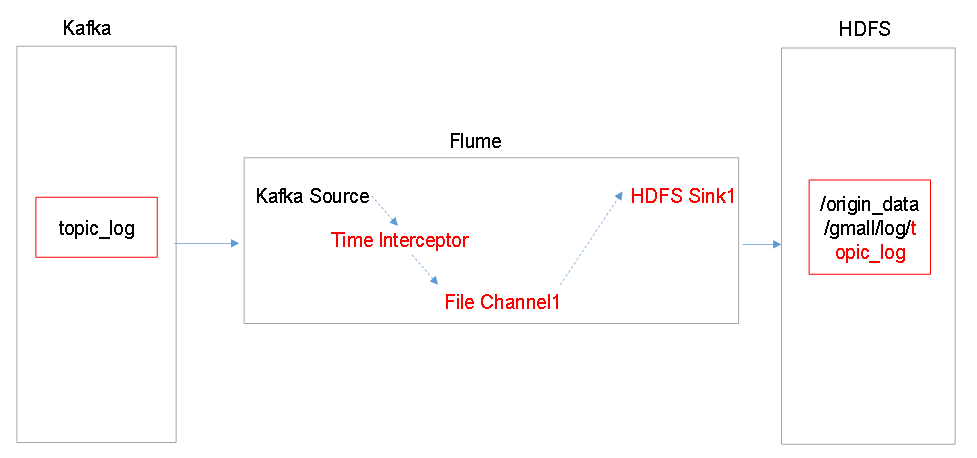
2)Flume的具体配置如下:
(1)在hadoop104的/opt/module/flume/conf目录下创建kafka-flume-hdfs.conf文件
[atguigu@hadoop104 conf]$ vim kafka-flume-hdfs.conf
在文件配置如下内容:
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
4.6.3 Flume时间戳拦截器
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
1)在com.atguigu.flume.interceptor包下创建TimeStampInterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
2)重新打包

3)需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
[atguigu@hadoop102 lib]$ ls | grep interceptor
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
4)分发Flume到hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync flume/
4.6.4 消费者Flume启动停止脚本
(1)在/home/atguigu/bin目录下创建脚本f2.sh
[atguigu@hadoop102 bin]$ vim f2.sh
(1)在/home/atguigu/bin目录下创建脚本f2.sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop104
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop104
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
};;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x f2.sh
(3)f2集群启动脚本
[atguigu@hadoop102 module]$ f2.sh start
(4)f2集群停止脚本
[atguigu@hadoop102 module]$ f2.sh stop
4.6.5 项目经验之Flume内存优化
1)问题描述:如果启动消费Flume抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
2)解决方案步骤
(1)在hadoop102服务器的/opt/module/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到hadoop103、hadoop104服务器
[atguigu@hadoop102 conf]$ xsync flume-env.sh
3)Flume内存参数设置及优化
JVM heap一般设置为4G或更高
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按 需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
4.7 采集通道启动/停止脚本
(1)在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim cluster.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动 Flume采集集群
f1.sh start
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Flume消费集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x cluster.sh
(3)cluster集群启动脚本
[atguigu@hadoop102 module]$ cluster.sh start
(4)cluster集群停止脚本
[atguigu@hadoop102 module]$ cluster.sh stop
常见问题与解决方案:
1)问题描述
访问2NN页面http://hadoop104:9868,看不到详细信息
2)解决办法
(1)在浏览器上按F12,查看问题原因。定位bug在61行
(2)找到要修改的文件
[atguigu@hadoop102 static]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/hdfs/webapps/static
[atguigu@hadoop102 static]$ vim dfs-dust.js
:set nu
修改61行
return new Date(Number(v)).toLocaleString();
(3)分发dfs-dust.js
[atguigu@hadoop102 static]$ xsync dfs-dust.js
(4)在http://hadoop104:9868/status.html 页面强制刷新