使用ResNet-50实现图像分类任务
摘要:
承接上一篇LeNet网络模型的图像分类实践,本次我们再来认识一个新的网络模型:ResNet-50。不同网络模型之间的主要区别是神经网络层的深度和层与层之间的连接方式,正文内容我们就分析下使用ResNet-50进行图像分类有什么神奇之处,以下操作使用MindSpore框架实现。
1.网络:ResNet-50
对于类似LeNet网络模型深度较小并且参数也较少,训练起来会相对简单,也很难会出现梯度消失或爆炸的情况。但ResNet-50的深度较大,训练起来就会比较困难,所以在加深网络深度的同时提出残差学习的结构来减轻深层网络训练的难度。重新构建了网络以便学习包含推理的残差函数,而不是学习未经过推理的函数。实验结果显示,残差网络更容易优化,并且加深网络层数有助于提高正确率。
- 深度模型的限制
深度卷积网络在图像分类任务上有非常优秀的表现。深度网络依赖于多层端到端的方式,集成了低中高三个层次的特征和分类器,并且这些特征的数量还可以通过堆叠层数来增加。这也展示出了网络深度非常重要。
但是随着网络层数的增加,训练时就会遇到梯度消失或爆炸的情况,这会在一开始就影响收敛。收敛的问题可以通过正则化来得到部分的解决,但也不是通用的方法。并且在深层网络能够收敛的前提下,随着网络深度的增加,正确率开始饱和甚至下降,称之为网络的退化。
图1:56层和20层网络效果图
通过上图1可以发现在不改变网络结构的情况下,仅加深网络深度的56层网络相较于20层在误差上表现都更大。
- ResNet-50的残差结构
对于网络退化现象并不是过拟合造成的。在给定的网络上增加层数就会增大训练误差。这说明不是所有的系统都很容易优化。我们可以先分析一个浅层的网络架构和在它基础上构建的深层网络,如果增加的所有层都是前一层的直接复制(即y=x),这种情况下深层网络的训练误差应该和浅层网络相等。因此,网络退化的根本原因还是优化问题。为了解决优化的难题,大佬们提出了残差网络,在ResNet-50中残差网络结构可分为Identity Block和Conv Block,下面分别介绍下。
Identity Block:在残差网络中,不是让网络直接拟合原先的映射,而是拟合残差映射。意味着后面的特征层的内容会有一部分由前面的某一层线性贡献。假设原始的映射为 H(x),残差网络拟合的映射为:F(x):=H(x)。输入和输出的维度(通道数和Size)是一样的,所以可以串联,它的主要用处是加深网络的深度。

图2:Identity Block结构
如图2中所示,identity mapping会直接跳过中间一些网络层,建立了一些快捷链接,直接恒等映射过去。这样的快捷链接不会增加模型的复杂度和参数。
Conv Block:在Identity Block的残差结构基础上,又增加了Conv的过程。输入和输出的维度(通道数和Size)是不一样的,所以不能进行连续的串联,它的作用是改变网络的维度,所以残差边上新增了卷积。

图3:Conv Block结构
如图3中所示,Conv Block将在残差的通道上经过一轮卷积处理。再将卷积处理后的结果给到后面的网络层中。
Conv Block的具体设置需要看Block的输入和输出,对照通道数和Size的变化,设定符合需求的Conv。
- ResNet-50的整体结构
上面了解完了残差结构和用途,现在我们再带入到ResNet-50中看下整体的结构

图4:ResNet结构图
从左到右依次的分析,图4最左边是ResNet-50的步骤图,后面是将每个步骤再拆解Input stem是正常的输入和处理。Stage1->Stage4就是包含了加深网络深度的Identity Block和Conc Block的模块,同时避免了计算训练困难和网络的退化的问题。
- ResNet-50的调用
MindSpore已上线支持该模型,我们可以直接调用该模型的接口,所以我们在使用过程中传入定义好的超参数和数据即可。
network = resnet50(class_num=10)如果想要了解下更底层的参数设置,可以查看https://gitee.com/mindspore/models/blob/master/official/cv/resnet/config/resnet50_cifar10_config.yaml。
论文链接:https://arxiv.org/pdf/1512.03385.pdf
2.数据集:CIFAR-10
数据集CIFAR-10由10个类的60000个32x32彩**像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
- 数据集结构
CIFAR-10数据集的原文连接中包含三种类型的数据集,这里可以根据自己的需求进行下载。这里我们使用python版本数据集。
Version Size
CIFAR-10 python version 163 MB
CIFAR-10 Matlab version 175 MB
CIFAR-10 binary version (suitable for C programs) 162 MB
数据集中所包含的类别

图5:CIFAR-10类别图
- 数据加载和处理
数据加载:下载完成后将数据集放在一个文件目录下,将目录传入到数据的加载过程中。
cifar_ds = ds.Cifar10Dataset(data_home)数据增强:是对数据进行归一化和丰富数据样本数量。常见的数据增强方式包括裁剪、翻转、色彩变化等等。MindSpore通过调用map方法在图片上执行增强操作。
resize_height = 224
resize_width = 224
rescale = 1.0 / 255.0
shift = 0.0
# define map operations
random_crop_op = C.RandomCrop((32, 32), (4, 4, 4, 4)) # padding_mode default CONSTANT
random_horizontal_op = C.RandomHorizontalFlip()
resize_op = C.Resize((resize_height, resize_width)) # interpolation default BILINEAR
rescale_op = C.Rescale(rescale, shift)
normalize_op = C.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
changeswap_op = C.HWC2CHW()
type_cast_op = C2.TypeCast(mstype.int32)
c_trans = []
if training:
c_trans = [random_crop_op, random_horizontal_op]
c_trans += [resize_op, rescale_op, normalize_op, changeswap_op]
# apply map operations on images
cifar_ds = cifar_ds.map(operations=type_cast_op, input_columns="label")
cifar_ds = cifar_ds.map(operations=c_trans, input_columns="image")最后通过数据混洗(shuffle)随机打乱数据的顺序,并按batch读取数据,进行模型训练。
# apply shuffle operations
cifar_ds = cifar_ds.shuffle(buffer_size=10)
# apply batch operations
cifar_ds = cifar_ds.batch(batch_size=args_opt.batch_size, drop_remainder=True)
# apply repeat operations
cifar_ds = cifar_ds.repeat(repeat_num)3.损失函数:SoftmaxCrossEntropyWithLogits
本次训练调用的损失函数是:SoftmaxCrossEntropyWithLogits。那为什么是SoftmaxCrossEntropyWithLogits损失函数呢?
- 损失函数的选择
我们上面提到,为什么是使用SoftmaxCrossEntropyWithLogits损失函数呢,这要从我们本次的实验目的分析。
本次项目的:实现CIFAR-10图像数据集的分类。既然是分类,那么分类中的损失函数是怎么计算的,它是计算logits和标签之间的softmax交叉熵。使用交叉熵损失测量输入概率(使用softmax函数计算)与类别互斥(只有一个类别为正)的目标之间的分布误差,具体公式可以表示成

图6:SoftmaxCrossEntropyWithLogits表达式
- 损失函数参数分析
- logits (Tensor) - Tensor of shape (N, C). Data type must be float16 or float32.
- labels (Tensor) - Tensor of shape (N, ). If sparse is True, The type of labels is int32 or int64. Otherwise, the type of labels is the same as the type of logits.
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes;第二个参数labels:实际的标签,大小同上。
- 损失函数的使用
#在主函数处调用如下
if __name__ == '__main__':
ls = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
model = Model(loss_fn=ls)更详细的使用请参考SoftmaxCrossEntropyWithLogits API链接:https://mindspore.cn/docs/api/zh-CN/master/api_python/nn/mindspore.nn.SoftmaxCrossEntropyWithLogits.html#mindspore.nn.SoftmaxCrossEntropyWithLogits
4.优化器:Momentum
本次训练中我们使用的是Momentum,也叫动量优化器。为什么是它?下面我们了解下它的计算原理。
- 优化器的计算
图7:Momentum表达式
上面表达式中的grad、lr、p、v 和 u 分别表示梯度、learning_rate、参数、矩和动量。其中的梯度是通过损失函数求导得出的,在训练过程中得到的Loss是一个连续值,那么它就有梯度可求,并反向传播给每个参数。Momentum优化器的主要思想就是利用了类似移动指数加权平均的方法来对网络的参数进行平滑处理的,让梯度的摆动幅度变得更小。
- 优化器的使用
#在主函数处调用如下
if __name__ == '__main__':
opt = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), 0.01, 0.9)
model = Model(optimizer=opt)更详细的使用请参考Momentum API链接:https://mindspore.cn/docs/api/zh-CN/master/api_python/nn/mindspore.nn.Momentum.html#mindspore.nn.Momentum
5.评价指标:Accuracy
损失函数的值虽然可以反应网络的性能,但对于图片分类的任务,使用精度可以更加准确的表示最终的分类结果。
- 精度指标的选择
基于分类任务的考虑,我们使用简单的`分类正确数量/总数量`来表示,也就是Accuracy。精度表达式比较简单,也好理解。
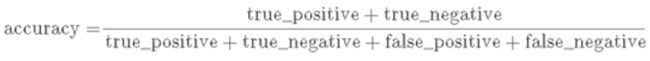
图8:Accuracy达式
- 精度的使用
#在主函数处调用即可
if __name__ == '__main__':
model = Model(metrics={'acc'})更详细的使用请参考Accuracy API链接:https://mindspore.cn/docs/api/zh-CN/master/api_python/nn/mindspore.nn.Accuracy.html#mindspore.nn.Accuracy
总结:
本次内容是以图像分类任务为例,首先要了解下我们本次使用的模型结构以及要完成的目标,本次内容和LeNet网络图像分类的区别是使用网络和数据集的不同,所以可重点对照下两种网络结构。然后是选择设置失函数、优化器和精度这几部分,构成完整的训练。谢谢赏阅。