Redis持久化机制
Redis为什么数据要持久化?
Redis是内存数据库,如果数据不进行持久化,一旦Redis服务器重启数据会全部丢失。
注意:如果Redis只做缓存,你也可以不使用任何持久化方式。
什么是Redis数据持久化
把数据存储到硬盘中,当服务器开启的时候再读入到内存中去,这就是redis数据的持久化。
Redis提供三种持久化机制:RDB、AOF和Redis 4.0之后推出的混合持久化机制
注意:修改的redis的配置文件,要重启redis才能生效。
RDB(默认机制)
在一段时间内,检测key的变化情况,然后持久化某一个时刻数据(快照)【对性能影响低,推荐使用】
# 900秒修改key 1次,会触发rdb机制
save 900 1
# 300秒修改key 10次,会触发rdb机制
save 300 10
# 60秒修改key 1000次,会触发rdb机制
save 60 10000每次触发save,就会把当前时刻的数据记录到dump.rdb文件(二进制文件,内容看不懂)中。
关闭rdb机制只需要将所有的save保存策略注释掉即可。
rdb机制触发的时机
-
save的规则满足的情况下,会自动触发rdb机制
-
执行flushall命令,也会触发我们的rdb机制,但里面是空的,无意义
-
关闭redis服务器(使用 shutdown指令 ),也会触发我们的rdb机制
-
save/bgsave指令会执行,save用主进程持久化,效率低(同步),不使用,gbsave用子进程持久化(异步)
持久化执行过程
Redis会fork一个子进程进行持久化,先将数据写到临时文件(dump.rdb)中,待持久化过程结束,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
数据恢复
只需要把dump.rdb放在redis的配置文件指定的目录下即可,redis启动时,会自动检查dump.rdb文件,恢复数据。
生产环境我们会对dump.rdb文件进行备份。
rdb文件名称
# The filename where to dump the DB
dbfilename dump.rdbrdb文件位置
# Note that you must specify a directory here, not a file name.
dir ././:代表当前目录下
优点
- 适合大规模的数据恢复。
- 对数据的完整性要求不高。
- 持久化的整个过程中,主进程不进行任何IO操作,确保了极高的性能。
缺点
- fork子进程会占用一定的内存空间。
- redis意外宕机,还没触发save,最后一次修改的数据就没了。
AOF
以日志的方式把所有写的操作都记录到文件中(无限追加写入)
恢复数据时,把这个文件中所有的写操作再执行一遍。
开启aof(默认不开启)
# appendonly no
appendonly yes持久化策略
# appendfsync always # 每一次操作都fsync,性能影响严重
appendfsync everysec # 每秒执行一次fsync,可能会丢失这1s的数据(默认)【推荐】
# appendfsync no # 不执行fsync,这个时候操作系统自己同步数据,速度最快,也更不安全-
每一次修改都同步,文件的完整性更好,性能极差
-
每一秒同步一次,可能会丢失一秒的数据
-
从不同步,效率最高,安全性最差
文件名称
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"aof文件分析
如执行命令set zhuge 666,aof文件里会记录如下数据:
1 *3 # 代表指令的length = 3
2 $3 # 代表关键字参数的长度 lenth(set) = 3
3 set
4 $5 # key字符串长度
5 zhuge
6 $3 # value字符串长度
7 666 redis-check-aof工具
如果aof文件有错误,redis是启动不起来的,我需要修改这个aof文件
redis给我们提供了一个工具redis-check-aof,执行指令来修复aof文件
redis-check-aof --fix appendonly.aofAOF重写
AOF文件里可能有很多没用指令,所以AOF会定期根据内存的最新数据生成aof文件。
例如,执行了如下几条命令:
127.0.0.1:6379> incr readcount
(integer) 1
127.0.0.1:6379> incr readcount
(integer) 2
127.0.0.1:6379> incr readcount
(integer) 3
127.0.0.1:6379> incr readcount
(integer) 4
127.0.0.1:6379> incr readcount
(integer) 5 aof文件中就会有1 - 5的所有记录,但重写后AOF文件里变成只有5
1 *3
2 $3
3 SET
4 $2
5 readcount
6 $1
7 5 如下两个配置可以控制AOF自动重写频率
auto‐aof‐rewrite‐percentage 100 # aof文件自上一次重写后文件大小增长了100% 则再次触发重写
auto‐aof‐rewrite‐min‐size 64mb # aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
# 第一次触发重写文件要达到64M,第二次128M,以此类推
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF。
注意,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多影响。
RDB和AOF的对比
aof文件大小远远大于rdb,修复速度也比rdb慢,aof运行效率比rdb慢
对于大规模恢复数据,且对数据恢复的完整性不是非常敏感,那RDB要比AOF更加高效。
| 指令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
生产环境可以都启用,rdb和aof文件都会生成,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更全一点。
混合持久化【推荐】
Redis 4.0 提供混合持久化方式,权衡rdb 和 aof,使用这种方式建议关闭rdb(注释配置文件的所有save)
重启Redis时,我们很少使用RDB来恢复内存状态,因为会丢失大量数据。我们通常使用AOF 日志重放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在Redis数据很大的情况下,启动需要花费很长的时间。 Redis 4.0 为了解决这个问题,提供一个新的持久化机制 - 混合持久化。
通过如下配置可以开启混合持久化。
aof‐use‐rdb‐preamble yes # 默认这种方式是关闭的,必须先开启aof如果开启了混合持久化,AOF在重写时,将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容(二进制)写入到新的aof文件,写入过程中,如果有新的命令,则会以aof的方式追加到新的aof文件某末尾。新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
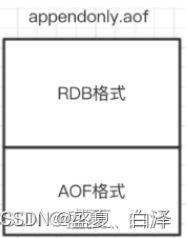
总结:就是把原来aof重写机制修改,其他不变,触发重写机制时把rdb快照数据存到aof文件中,当有新的数据加入,以aof的方式追加到文件末尾(aof格式),每秒记录一次(看aof的配置)编辑。
线上Redis持久化策略一般如何设置
如果对性能要求较高,在Master最好不要做持久化,可以在某个Slave开启AOF备份数据,
策略设置为每秒同步一次即可。(我们一般作为缓存使用,丢一秒数据无所谓)