Django的select_related 和 prefetch_related 函数优化查询
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能。本文通过一个简单的例子详解这两个函数的作用。虽然QuerySet的文档中已经详细说明了,但本文试图从QuerySet触发的SQL语句来分析工作方式,从而进一步了解Django具体的运作方式。
1. 实例的背景说明
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
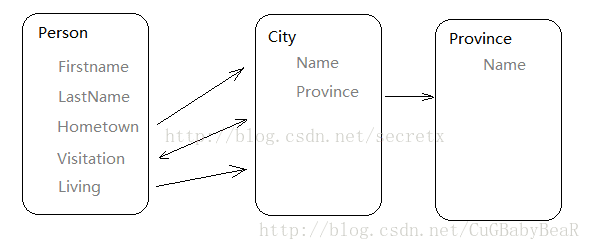
Models.py 内容如下:
from django.db import models
class Province(models.Model):
name = models.CharField(max_length=10)
def __unicode__(self):
return self.name
class City(models.Model):
name = models.CharField(max_length=5)
province = models.ForeignKey(Province)
def __unicode__(self):
return self.name
class Person(models.Model):
firstname = models.CharField(max_length=10)
lastname = models.CharField(max_length=10)
visitation = models.ManyToManyField(City, related_name = "visitor")
hometown = models.ForeignKey(City, related_name = "birth")
living = models.ForeignKey(City, related_name = "citizen")
def __unicode__(self):
return self.firstname + self.lastname注1:创建的app名为“QSOptimize”
注2:为了简化起见,`qsoptimize_province` 表中只有2条数据:湖北省和广东省,`qsoptimize_city`表中只有三条数据:武汉市、十堰市和广州市
2. select_related()
对于一对一字段(OneToOneField)和外键字段(ForeignKey),可以使用select_related 来对QuerySet进行优化
作用和方法
在对QuerySet使用select_related()函数后,Django会获取相应外键对应的对象,从而在之后需要的时候不必再查询数据库了。以上例说明,如果我们需要打印数据库中的所有市及其所属省份,最直接的做法是:
>>> citys = City.objects.all()
>>> for c in citys:
... print c.province
...这样会导致线性的SQL查询,如果对象数量n太多,每个对象中有k个外键字段的话,就会导致n*k+1次SQL查询。在本例中,因为有3个city对象就导致了4次SQL查询:
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` = 1 ;
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` = 2 ;
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` = 1 ;如果我们使用select_related()函数:
>>> citys = City.objects.select_related().all()
>>> for c in citys:
... print c.province
...就只有一次SQL查询,显然大大减少了SQL查询的次数:
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`,
`QSOptimize_city`.`province_id`, `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM`QSOptimize_city`
INNER JOIN `QSOptimize_province` ON (`QSOptimize_city`.`province_id` = `QSOptimize_province`.`id`) ;这里我们可以看到,Django使用了INNER JOIN来获得省份的信息。顺便一提这条SQL查询得到的结果如下:
+----+-----------+-------------+----+-----------+
| id | name | province_id | id | name |
+----+-----------+-------------+----+-----------+
| 1 | 武汉市 | 1 | 1 | 湖北省 |
| 2 | 广州市 | 2 | 2 | 广东省 |
| 3 | 十堰市 | 1 | 1 | 湖北省 |
+----+-----------+-------------+----+-----------+
3 rows in set (0.00 sec)使用方法
*fields 参数
select_related() 接受可变长参数,每个参数是需要获取的外键(父表的内容)的字段名,以及外键的外键的字段名、外键的外键的外键…。若要选择外键的外键需要使用两个下划线“__”来连接。
例如我们要获得张三的现居省份,可以用如下方式:
>>> zhangs = Person.objects.select_related('living__province').get(firstname=u"张",lastname=u"三")
>>> zhangs.living.province触发的SQL查询如下:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,
`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`,
`QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`, `QSOptimize_province`.`id`,
`QSOptimize_province`.`name`
FROM `QSOptimize_person`
INNER JOIN `QSOptimize_city` ON (`QSOptimize_person`.`living_id` = `QSOptimize_city`.`id`)
INNER JOIN `QSOptimize_province` ON (`QSOptimize_city`.`province_id` = `QSOptimize_province`.`id`)
WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张' );可以看到,Django使用了2次 INNER JOIN 来完成请求,获得了city表和province表的内容并添加到结果表的相应列,这样在调用 zhangs.living的时候也不必再次进行SQL查询。
+----+-----------+----------+-------------+-----------+----+-----------+-------------+----+-----------+
| id | firstname | lastname | hometown_id | living_id | id | name | province_id | id | name |
+----+-----------+----------+-------------+-----------+----+-----------+-------------+----+-----------+
| 1 | 张 | 三 | 3 | 1 | 1 | 武汉市 | 1 | 1 | 湖北省 |
+----+-----------+----------+-------------+-----------+----+-----------+-------------+----+-----------+
1 row in set (0.00 sec)然而,未指定的外键则不会被添加到结果中。这时候如果需要获取张三的故乡就会进行SQL查询了:
>>> zhangs.hometown.province
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`,
`QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
WHERE `QSOptimize_city`.`id` = 3 ;
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` = 1同时,如果不指定外键,就会进行两次查询。如果深度更深,查询的次数更多。
值得一提的是,从Django 1.7开始,select_related()函数的作用方式改变了。在本例中,如果要同时获得张三的故乡和现居地的省份,在1.7以前你只能这样做:
>>> zhangs = Person.objects.select_related('hometown__province','living__province').get(firstname=u"张",lastname=u"三")
>>> zhangs.hometown.province
>>> zhangs.living.province但是1.7及以上版本,你可以像和queryset的其他函数一样进行链式操作:
>>> zhangs = Person.objects.select_related('hometown__province').select_related('living__province').get(firstname=u"张",lastname=u"三")
>>> zhangs.hometown.province
>>> zhangs.living.province如果你在1.7以下版本这样做了,你只会获得最后一个操作的结果,在本例中就是只有现居地而没有故乡。在你打印故乡省份的时候就会造成两次SQL查询。
depth 参数
select_related() 接受depth参数,depth参数可以确定select_related的深度。Django会递归遍历指定深度内的所有的OneToOneField和ForeignKey。以本例说明:
>>> zhangs = Person.objects.select_related(depth = d)d=1 相当于 select_related(‘hometown’,'living’)
d=2 相当于 select_related(‘hometown__province’,'living__province’)
无参数
select_related() 也可以不加参数,这样表示要求Django尽可能深的select_related。例如:zhangs = Person.objects.select_related().get(firstname=u”张”,lastname=u”三”)。但要注意两点:
1.Django本身内置一个上限,对于特别复杂的表关系,Django可能在你不知道的某处跳出递归,从而与你想的做法不一样。具体限制是怎么工作的我表示不清楚。
2.Django并不知道你实际要用的字段有哪些,所以会把所有的字段都抓进来,从而会造成不必要的浪费而影响性能。
小结
1.select_related主要针一对一和多对一关系进行优化。
2.select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
3.可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
4.也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
5.也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
6.Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个。
3. prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。或许你会说,没有一个叫OneToManyField的东西啊。实际上 ,ForeignKey就是一个多对一的字段,而被ForeignKey关联的字段就是一对多字段了。
作用和方法
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。继续以上边的例子进行说明,如果我们要获得张三所有去过的城市,使用prefetch_related()应该是这么做:
>>> zhangs = Person.objects.prefetch_related('visitation').get(firstname=u"张",lastname=u"三")
>>> for city in zhangs.visitation.all() :
... print city
...上述代码触发的SQL查询如下:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,
`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张');
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1);第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`QSOptimize_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表。
+----+-----------+----------+-------------+-----------+
| id | firstname | lastname | hometown_id | living_id |
+----+-----------+----------+-------------+-----------+
| 1 | 张 | 三 | 3 | 1 |
+----+-----------+----------+-------------+-----------+
1 row in set (0.00 sec)
+-----------------------+----+-----------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+-----------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+-----------+-------------+
3 rows in set (0.00 sec)显然张三武汉、广州、十堰都去过。
又或者,我们要获得湖北的所有城市名,可以这样:
>>> hb = Province.objects.prefetch_related('city_set').get(name__iexact=u"湖北省")
>>> for city in hb.city_set.all():
... city.name
...SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`name` LIKE '湖北省' ;
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
WHERE `QSOptimize_city`.`province_id` IN (1);+----+-----------+
| id | name |
+----+-----------+
| 1 | 湖北省 |
+----+-----------+
1 row in set (0.00 sec)
+----+-----------+-------------+
| id | name | province_id |
+----+-----------+-------------+
| 1 | 武汉市 | 1 |
| 3 | 十堰市 | 1 |
+----+-----------+-------------+
2 rows in set (0.00 sec)使用方法
*lookups 参数
prefetch_related()在Django < 1.7 只有这一种用法。和select_related()一样,prefetch_related()也支持深度查询,例如要获得所有姓张的人去过的省:
>>> zhangs = Person.objects.prefetch_related('visitation__province').filter(firstname__iexact=u'张')
>>> for i in zhangs:
... for city in i.visitation.all():
... print city.province
...SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,
`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE `QSOptimize_person`.`firstname` LIKE '张' ;
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 4);
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` IN (1, 2);+----+-----------+----------+-------------+-----------+
| id | firstname | lastname | hometown_id | living_id |
+----+-----------+----------+-------------+-----------+
| 1 | 张 | 三 | 3 | 1 |
| 4 | 张 | 六 | 2 | 2 |
+----+-----------+----------+-------------+-----------+
2 rows in set (0.00 sec)
+-----------------------+----+-----------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+-----------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 4 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+-----------+-------------+
4 rows in set (0.00 sec)
+----+-----------+
| id | name |
+----+-----------+
| 1 | 湖北省 |
| 2 | 广东省 |
+----+-----------+
2 rows in set (0.00 sec)要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
举个例子,要获取所有人访问过的城市中带有“市”字的城市,这样做会导致大量的SQL查询:
plist =Person.objects.prefetch_related('visitation')
[p.visitation.filter(name__icontains=u"市")for p in plist]SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,
`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`;
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 2, 3, 4);
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE(`QSOptimize_person_visitation`.`person_id` = 1 AND `QSOptimize_city`.`name` LIKE '%市%' );
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE (`QSOptimize_person_visitation`.`person_id` = 2 AND `QSOptimize_city`.`name` LIKE '%市%' );
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE (`QSOptimize_person_visitation`.`person_id` = 3 AND `QSOptimize_city`.`name` LIKE '%市%' );
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE (`QSOptimize_person_visitation`.`person_id` = 4 AND `QSOptimize_city`.`name` LIKE '%市%' );众所周知,QuerySet是lazy的,要用的时候才会去访问数据库。运行到第二行Python代码时,for循环将plist看做iterator,这会触发数据库查询。最初的两次SQL查询就是prefetch_related导致的。
虽然已经查询结果中包含所有所需的city的信息,但因为在循环体中对Person.visitation进行了filter操作,这显然改变了数据库请求。因此这些操作会忽略掉之前缓存到的数据,重新进行SQL查询。
但是如果有这样的需求了应该怎么办呢?在Django >= 1.7,可以通过下一节的Prefetch对象来实现,如果你的环境是Django < 1.7,可以在Python中完成这部分操作。
plist = Person.objects.prefetch_related('visitation')
[[city for city in p.visitation.all() if u"市" in city.name] for p in plist]Prefetch对象
在Django >= 1.7,可以用Prefetch对象来控制prefetch_related函数的行为。1.一个Prefetch对象只能指定一项prefetch操作。
2.Prefetch对象对字段指定的方式和prefetch_related中的参数相同,都是通过双下划线连接的字段名完成的。
3.可以通过 queryset 参数手动指定prefetch使用的QuerySet。
4.可以通过 to_attr 参数指定prefetch到的属性名。
5.Prefetch对象和字符串形式指定的lookups参数可以混用。
4. 最佳实践
1.prefetch_related主要针一对多和多对多关系进行优化。
2.prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
3.可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
4.在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
5.作为prefetch_related的参数,Prefetch对象和字符串可以混用。
6.prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
7.可以通过传入None来清空之前的prefetch_related。
选择哪个函数
>>> hb = Province.objects.get(name__iexact=u"湖北省")
>>> people = []
>>> for city in hb.city_set.all():
... people.extend(city.birth.all())
...
>>> hb = Province.objects.prefetch_related("city_set__birth").objects.get(name__iexact=u"湖北省")
>>> people = []
>>> for city in hb.city_set.all():
... people.extend(city.birth.all())
...因为是一个深度为2的prefetch,所以会导致3次SQL查询:
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`name` LIKE '湖北省' ;
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
WHERE `QSOptimize_city`.`province_id` IN (1);
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,
`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE `QSOptimize_person`.`hometown_id` IN (1, 3);嗯…看上去不错,但是3次查询么?倒过来查询可能会更简单?
>>> people = list(Person.objects.select_related("hometown__province").filter(hometown__province__name__iexact=u"湖北省"))SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,
`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`, `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_person`
INNER JOIN `QSOptimize_city` ON (`QSOptimize_person`.`hometown_id` = `QSOptimize_city`.`id`)
INNER JOIN `QSOptimize_province` ON (`QSOptimize_city`.`province_id` = `QSOptimize_province`.`id`)
WHERE `QSOptimize_province`.`name` LIKE '湖北省';+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
| id | firstname | lastname | hometown_id | living_id | id | name | province_id | id | name |
+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
| 1 | 张 | 三 | 3 | 1 | 3 | 十堰市 | 1 | 1 | 湖北省 |
| 2 | 李 | 四 | 1 | 3 | 1 | 武汉市 | 1 | 1 | 湖北省 |
| 3 | 王 | 麻子 | 3 | 2 | 3 | 十堰市 | 1 | 1 | 湖北省 |
+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
3 rows in set (0.00 sec)
class Order(models.Model):
customer = models.ForeignKey(Person)
orderinfo = models.CharField(max_length=50)
time = models.DateTimeField(auto_now_add = True)
def __unicode__(self):
return self.orderinfo如果我们拿到了一个订单的id 我们要知道这个订单的客户去过的省份。因为有ManyToManyField显然必须要用prefetch_related()。如果只用prefetch_related()会怎样呢?
>>> plist = Order.objects.prefetch_related('customer__visitation__province').get(id=1)
>>> for city in plist.customer.visitation.all():
... print city.province.name
...显然,关系到了4个表:Order、Person、City、Province,根据prefetch_related()的特性就得有4次SQL查询
SELECT `QSOptimize_order`.`id`, `QSOptimize_order`.`customer_id`, `QSOptimize_order`.`orderinfo`, `QSOptimize_order`.`time`
FROM `QSOptimize_order`
WHERE `QSOptimize_order`.`id` = 1 ;
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE `QSOptimize_person`.`id` IN (1);
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` IN (1, 2);+----+-------------+---------------+---------------------+
| id | customer_id | orderinfo | time |
+----+-------------+---------------+---------------------+
| 1 | 1 | Info of Order | 2014-08-10 17:05:48 |
+----+-------------+---------------+---------------------+
1 row in set (0.00 sec)
+----+-----------+----------+-------------+-----------+
| id | firstname | lastname | hometown_id | living_id |
+----+-----------+----------+-------------+-----------+
| 1 | 张 | 三 | 3 | 1 |
+----+-----------+----------+-------------+-----------+
1 row in set (0.00 sec)
+-----------------------+----+--------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+--------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+--------+-------------+
3 rows in set (0.00 sec)
+----+--------+
| id | name |
+----+--------+
| 1 | 湖北省 |
| 2 | 广东省 |
+----+--------+
2 rows in set (0.00 sec)更好的办法是先调用一次select_related()再调用prefetch_related(),最后再select_related()后面的表
>>> plist = Order.objects.select_related('customer').prefetch_related('customer__visitation__province').get(id=1)
>>> for city in plist.customer.visitation.all():
... print city.province.name
...这样只会有3次SQL查询,Django会先做select_related,之后prefetch_related的时候会利用之前缓存的数据,从而避免了1次额外的SQL查询:
SELECT `QSOptimize_order`.`id`, `QSOptimize_order`.`customer_id`, `QSOptimize_order`.`orderinfo`,
`QSOptimize_order`.`time`, `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,
`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_order`
INNER JOIN `QSOptimize_person` ON (`QSOptimize_order`.`customer_id` = `QSOptimize_person`.`id`)
WHERE `QSOptimize_order`.`id` = 1 ;
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` IN (1, 2);+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
| id | customer_id | orderinfo | time | id | firstname | lastname | hometown_id | living_id |
+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
| 1 | 1 | Info of Order | 2014-08-10 17:05:48 | 1 | 张 | 三 | 3 | 1 |
+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
1 row in set (0.00 sec)
+-----------------------+----+--------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+--------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+--------+-------------+
3 rows in set (0.00 sec)
+----+--------+
| id | name |
+----+--------+
| 1 | 湖北省 |
| 2 | 广东省 |
+----+--------+
2 rows in set (0.00 sec)值得注意的是,可以在调用prefetch_related之前调用select_related,并且Django会按照你想的去做:先select_related,然后利用缓存到的数据prefetch_related。然而一旦prefetch_related已经调用,select_related将不起作用。
小结
- 因为select_related()总是在单次SQL查询中解决问题,而prefetch_related()会对每个相关表进行SQL查询,因此select_related()的效率通常比后者高。
- 鉴于第一条,尽可能的用select_related()解决问题。只有在select_related()不能解决问题的时候再去想prefetch_related()。
- 你可以在一个QuerySet中同时使用select_related()和prefetch_related(),从而减少SQL查询的次数。
- 只有prefetch_related()之前的select_related()是有效的,之后的将会被无视掉。