Bert性能提升14.8%,MindSpore算子自动生成技术详解
在Bert网络中,通过使用图算融合技术和算子自动生成技术相结合,可以实现整网的14.8%性能提升。想知道具体技术细节吗?快来看看吧~

为什么需要算子自动生成技术?
有过深度学习项目实践经验的同学会有类似的需求:
以计算机视觉为例,我们可能会使用TensorFlow深度学习框架在Nvidia GPU上训练ResNet神经网络来解决图像分类任务。
在这种情况下我们可以使用CUDA和cuDNN库中的函数来完成网络训练在GPU上的部署及加速。然而,很多时候模型的训练和推理工作不一定会在同样的平台进行,最终我们可能需要把模型部署到CPU甚至手机上去,此时CUDA库便不再适用了。
开发者们往往会根据实际情况选择各种各样的深度学习顶层框架训练模型,例如TensorFlow、PyTorch、Keras、Caffe等等,再把训练好的模型部署到各种各样的设备后端上,除了刚才提到的Nvidia GPU外还包括Intel CPU、Intel GPU、ARM CPU、ARM GPU、FPGA及其它新型的AI加速器。
考虑到不同硬件设备的特性千差万别、现有算子库中算子包含范围不同、新型加速器算子库支持不足、非常规的神经网络中存在不常见的layer等等情况,开发者要完成手写算子并保证性能,学习成本和时间成本都变得很高,所以自动算子生成技术的出现变得非常有必要。
深度学习编译器能通过对编译过程的前端、中端、后端的抽象提取,以及相对统一的中间表达IR,使前端框架和后端优化分离开来,相当于把不同前端到不同后端这样一个C_N^2的组合空间大大简化,并通过自动生成技术完成这其中的中间表达IR生成、针对后端特性的优化、优化过的IR给后端的指令。
主流自动生成技术
目前市面上较为主流的带有自动算子生成技术的深度学习编译器有:
-
TVM [2]
-
Facebook研究的Tensor Comprehension (TC) [3]
-
基于PyTorch的Glow [4]
-
Google研发的针对TensorFlow进行优化计算的XLA [5]
-
英特尔开源的NGraph [6]
这些深度学习编译器在架构上一般都分为前端和后端,中间表达(IR)就作为一种程序的抽象化用于优化,high-level IR作用于前端,low-level IR则作用于后端以实现针对硬件的优化、代码生成和编译。
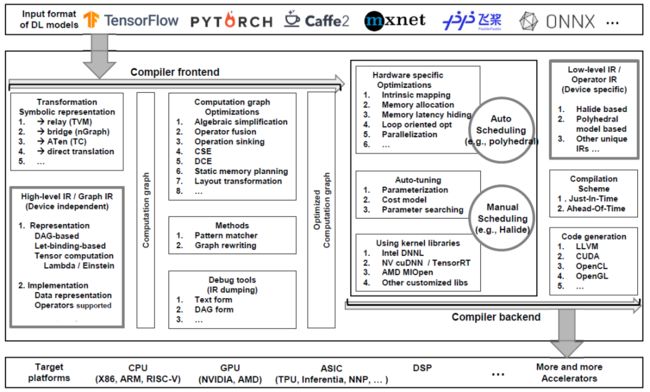
图1:深度学习编译器总览 [1]
大部分深度学习编译器的low-level IR最终都能下沉到LLVM IR这样一种较为标准、成熟且可定制、高模块化的中间表达,如Glow和XLA。Glow的low-level IR包含两种指令性函数,declare和program,来实现对全局内存的声明和对本地区域的分配。XLA也使用自己的HLO IR,但最终都能转换为LLVM IR的形式去完成优化和代码生成。
TVM和TC则使用了另外两类常见的low-level IR。TVM中使用的low-level IR是基于Halide IR的思想,分离算子的定义 (compute) 和调度 (schedule) 过程,并进一步改进形成自己独特的、不依赖LLVM的中间表达,可为不同的硬件结构进行特定优化,实现自动生成。TC在计算阶段也采用了Halide-based IR,同时它还应用了Polyhedral模型中提出的线性编程、仿射变换及其他数学方法实现对深度学习中经常出现的大块循环计算进行优化。
目前来看,TVM的整体维护较好,无论从上层深度学习框架、下层的硬件后端还是可生成的底层语言种类来说,TVM都覆盖得比较全面[1]。
TC在自动生成阶段使用的polyhedral模型,能够实现自动调度(auto-scheduling),是目前效果较好、较为流行的方法。
算子自动生成需解决的问题
自动算子生成需要根据数学表达式自动生成算子,并且要适应不同的硬件特性,能针对特定硬件后端做优化。使算法专家无需关注硬件体系结构、性能优化方面的问题,能专注于AI算法的创新和探索。
在这个过程中算子自动生成就需要解决自动微分、自动并行、深度图优化三个问题。
神经网络训练的后向传递中,通过对每个正向算子求微分形成相应的反向算子来实现梯度下降。自动生成反向算子的技术可以避免开发者手动计算微分,减轻开发者的负担。
在大训练集群的场景下,自动并行可以将网络或tensor拆分执行,充分发挥多个训练节点的算力。如模型并行是将模型中的层切分放到多个节点上执行,数据并行是将数据切分成多块让不同的节点去处理,除了模型和数据的维度,还可以沿tensor的其它维度进行切分,实现更灵活的并行执行。自动算子生成可以自动应对切分后不同形状的算子,降低开发者手动编写的成本。
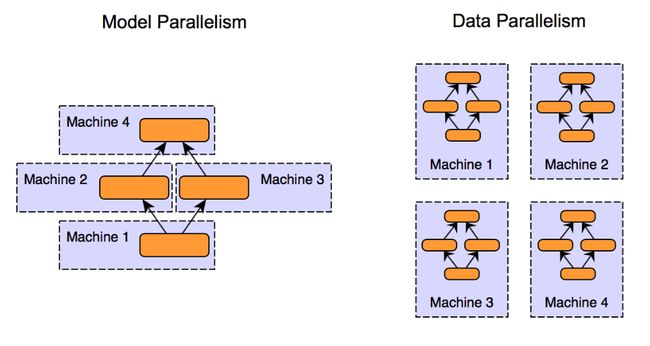
图 2 :模型并行(左)与数据并行(右)
深度图优化是指图层和算子层的融合优化。顶层深度学习框架只能做到图层面的融合,将两个算子的中间计算结果保留在内部缓冲区,节省从外部内存来回搬移数据的成本。而自动算子生成技术可以打破图层和算子层的边界,不仅可以实现传统的自动算子融合,还可以实现自动的算子重组,也就是把不同算子内部的计算进行深度的重组与整合,进一步提高性能。

AKG是 Auto Kernel Generator的简称。正如名字所示,AKG是在深度学习框架中的自动算子生成优化器。我们将按照AKG自动生成目标硬件代码的流程,介绍盘点AKG中主要的技术要点以及如何实现自动生成算子中的主要需求。
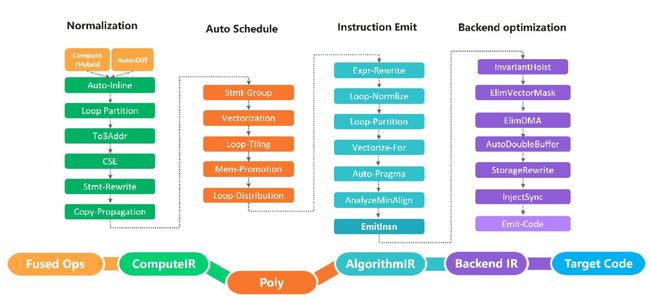
图3 AKG主要流程图
图3展示了AKG自动生成的几大主要流程和部分优化PASS。
概括来讲,AKG主要流程可以分为用户算子表示、程序规范化、自动调度、后端生成和优化等部分。通过近百个pass的处理变换,AKG可以将类似于数学公式的计算定义一步一步转化为指定的后端代码,如华为公司DaVinCi芯片的CCE代码。这无疑为用户提供了灵活定义计算,无需关注指令细节并生成高性能算子的可能性。
-
用户算子表示
用户基于TVM Compute DSL或Hybrid进行计算的定义和编写。这部分只需要利用类numpy的数学定义式代码即可完成对算子计算细节的描述。值得一提的是,AKG的自动微分技术可以通过算子计算信息自动求导生成其反向微分算子, 以供训练时使用。
-
程序规范化
规范化操作是自动调度的基础,通过运算符inline,循环拆分等操作,IR将被规范为适用于自动调度的形式,为自动调度中主要用到的Polyhedral技术提供前提准备。
-
自动调度
基于Polyhedral多面体编译技术,实现了自动向量化,自动切分,数据搬移,依赖分析以及自动多核等功能。在后面的部分将进一步对Polyhedral技术做进一步的介绍。
-
后端生成和优化
经过自动调度之后我们可以得到一个包括调度、优化等信息的IR, 在此基础上经过指令映射,同步策略生成和内存复用等功能生成指定的后端代码。

图4 CCE代码自动生成流程
以Davinci芯片和CCE代码为例,图4为我们展示了算法IR到CCE代码生成的流程。从流程图可以看出,后端代码生成中依照指定硬件和指令的特点,自动将经过自动调度生成的IR映射为指令IR,在保证计算正确性的基础上最大程度上对计算并行度和存储分配等进行优化从而保证了计算效率。
以上就是AKG如何从计算定义自动生成后端代码的主要流程,更多的技术细节和实现大家可以通过源码[7]深入了解,也期待在开源社区中与各位进行互动交流, 一起学习。

Polyhedral 编译技术的理论基础Presburger算术,可以追溯到计算机发明之前。1929年,波兰天才数学家Presburger提出了该算术系统,那年他才25岁,可惜天妒英才,这样一位优秀的数学家在纳粹大屠杀中逝世了,年仅39岁。
Presburger算术系统的特点是只包含加法、不包含乘法。大家一定不知道这样一个不能做乘法的代数系统有什么作用,这里需要提到哥德尔不完备性定理:任何包含整数四则运算的代数系统,都不能是既一致又完备的。哥德尔不完备性定理和图灵的停机问题本质上是一个问题,也就是有些问题没有办法在有限的时间内求解。
Presburger算术通过只允许加法,就同时做到了一致性、完备性和可判定性,也就是说任给一个命题,我们都能在有限的时间内判定它是正确还是错误。
为什么需要多面体技术
Polyhedral编译技术历史悠久,从大型机时代开始,程序自动并行问题就是程序语言领域的研究热点。程序自动并行化,就是用户使用串行的方法编写程序,编译器自动将其转换成一个并行程序。
图灵奖得主 Richard Karp 在 1967 年提出了向量程序的依赖分析理论,另一位图灵奖得主 Leslie Lamport 在 1974 年提出了仿射循环变换方法,以解决向量程序的自动并行问题。
20世纪80年代,程序自动并行化的研究掀起一股热浪。作为Polyhedral调度理论的奠基人之一, Paul Feautrier在90年代初提出了第一个通用的程序自动向量化算法,Feautrier算法。2008年,Uday提出了第一个适用于现代并行体系结构的Polyhedral调度算法,称为Pluto算法。

图5 Polyhedral编译技术简史
Polyhedral编译技术通常采用迭代空间(Domain)、访存映射(Write and Read)、依赖关系(Dependence),读写关系(Read/Write)和调度(Schedule)等集合和映射关系来表示程序的语义。
深度学习和高性能计算以矩阵和张量计算为主,程序一般是静态控制流,数据访问一般是线性映射关系,容易使用Polyhedral建模。同时GPU和基于DSA架构的深度学习处理器对循环变换、切分、数据搬移等优化有很强的需求,手动优化,难以满足深度学习网络的飞速发展。
因此,业界主流深度学习框架,比如Google的MLIR、Facebook的TC,陈天奇的TVM,都引入了Polyhedral编译技术,来实现自动的程序优化。
Polyhedral技术通过精确的分析程序的迭代空间、以及程序所读写的多面体范围,可以精确的进行各种程序变换的分析和判断。下面我们更详细的向大家介绍,如何利用多面体技术,在基于DSA架构的深度学习芯片上,进行auto schedule。
自动向量化
现代并行体系结构中不仅需要考虑到程序的并行性,还需要考虑程序的数据局部性,以充分利用层次化的缓存、内存结构、以及程序的向量化,这样便于批量操作一定数量的连续数据,以充分利用现代并行体系结构中向量化指令。
利用Polyhedral技术来实现程序的自动向量化,其目标就是提高程序的并行性和程序的数据局部性。所谓提高并行性,就是让程序可以让尽可能多的线程并行处理。而提高数据局部性,是为了减少缓冲区域外存之间的数据搬移。
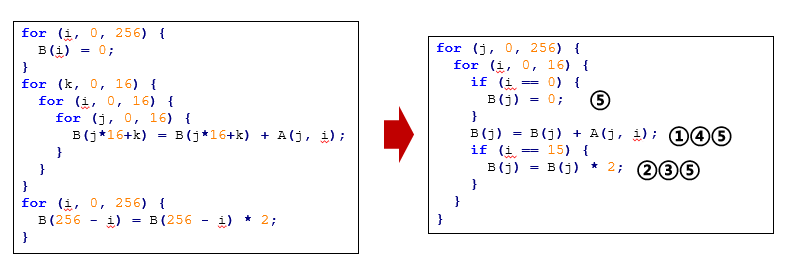
图6 自动向量化示例
自动向量化的本质是通过一系列的循环变换实现的。向量化所需的常见循环变换,包括:
-
循环轴重排:将多层循环内外层的循环轴交换顺序
-
循环轴偏移:将循环轴增加某一偏移量
-
循环轴倒置:将循环轴由递增改为递减
-
循环轴合并:将多个循环轴合并成一个循环轴
-
循环融合:将多个循环融合成一个循环
| 优化目标 |
目的 |
优化方法 |
| 最大化并行性 |
充分利用并行计算单元 |
尽可能循环融合 |
| 最大化数据局部性 |
减少数据搬移 |
数据依赖距离之和最短 |
表1 自动向量化优化目标
如表1所示,设置了两个优化目标,优化了循环变换结果。为了最大化的提升程序的并行性,我们会尽可能的进行循环融合,最小化数据依赖距离之和,使数据的局部性最大化。
自动切分
切分的目的,主要是为了减小数据内存的大小,提升数据的局部性。

图7 切分示例
如图7所示,对于一个大小为500*200*300的张量input_1,如果不做任何切分(500, 200, 300),就需要分配一个特别大的片上内存,我们可能需要将整个input_1的数据在内存中存下来,再来进行计算,最后再将结果从片上内存中搬出来,而常见的深度学习芯片不可能支持这种计算。
假如,我们给定一组切分(1,1,300),也就是ax0被切成500份,每次只做ax0中的第一点,k0被切成200份,k1被切成一份,即一次将其作为。这样一次仅需要做1x1x300这样大的一块内存。因此不同的切分大小,会对应程序不同的缓冲区内存大小。
基于Polyhedral技术,我们除了可以实现程序的切分外,还可以分析各切分块之间是否具有循环依赖,以判断切分的合法性。
为了简化切分过程,在AKG中,我们还实现了自动切分算法。自动切分,即给定一段程序,我们会自动的分析这段程序,根据自动向量化的结果来给出一个较优的切分。我们将切分轴分为三种区域:单切域、多切域和整切域。
-
单切域:该循环轴的切分值为1
-
多切域:该循环轴的切分值为区间(1, extent)中间的某一个值
-
整切域:该循环轴的切分值为extent
自动切分有两个主要的关键点:确定合适的多切域和确定多切域内每个轴的切分值。
如何确定合适的多切域呢?
首先要充分利用内存,即域内每个轴单切占用内存 小于实际内存,而实际内存要小于每个轴整切占用内存;
然后在保证切分后循环轴满足对齐、或特定切分值限定。
如何确定多切域内每个轴的切分值呢?
我们需要在满足对齐和取值限定前提下,逼近内存最充分的利用。通常来说,内存利用越充分,意味着指令并行度越高。
自动数据搬移
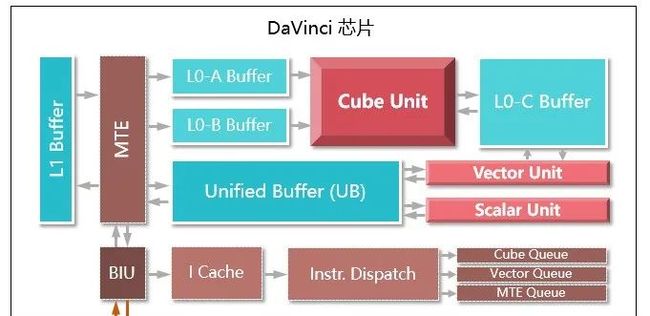
图8 DaVinci芯片架构图[8]
图8是Davinci芯片的架构图,由cube、vector、scalar三个计算单元,其中L0-A/B/C专用于cube计算单元,UB、L1作为两级通用缓冲区,3条并行MTE线路在外部内存、各数据缓冲区间搬移数据,同时进行数据格式转换。
我们看到数据从最外面进来,先到L1 Buffer,再到L0 Buffer,经过计算单元,到L0C Buffer,再到Unified Buffer,最后出来。这是一个非常复杂的过程,需要应用程序手写来完成,无法自动化。
由于Davinci芯片有多个缓冲区,我们需要先对程序进行数据流分析,决定什么数据放在什么类型的缓冲区,以及数据在缓冲区间的搬移顺序。
在自动数据流分析之后,我们需要进行自动内存管理。简单的讲,自动内存管理做的事情就是在一个大数组中根据切分规则,划分出一个小数组。与此同时,我们需要知道小数组中的点和原始数据的中对应关系。这样我们在做计算的时候,就不在使用原来的地址做计算,而是使用小数组,即缓冲区中的数据。

图9 原始数据与缓冲区数据的地址映射关系
自动数据搬移需要插入什么样的语句呢。主要包括了数据的搬入语句和数据的搬出语句。如下图所示,左边是内存提升后的中间表达,右边是插入数据搬移语句后的中间表达。

图10 自动数据搬移示例
第一条语句是数据搬入语句,将原始数据input_1,搬入到input_1_local_UB的片上缓冲区中,然后插入一条数据搬出语句,将数据的计算结果,从片上缓冲区搬出到外部缓冲区。至此,我们完成了自动搬移语句的生成。

以ResNet-50的算子在Ascend910上的性能数据为例。我们可以看一下多面体技术优化前后算子性能的对比,这里的Original表述按照CPU上类C语言的方式生成算子,Optimized表示Polyhedral技术优化后生成的算子。
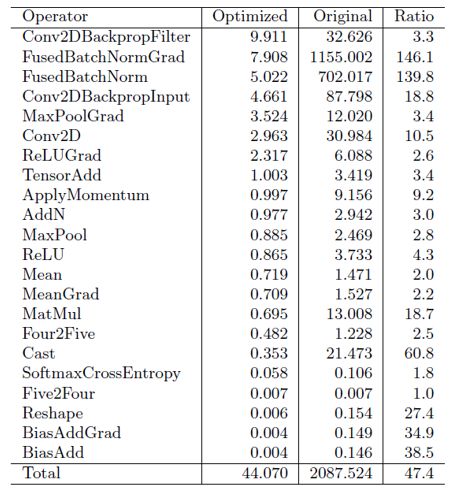
图11 ResNet50算子性能示例
另外,在Bert网络中,通过使用图算融合技术[9]和算子自动生成技术相结合,可以实现整网的14.8%性能提升。
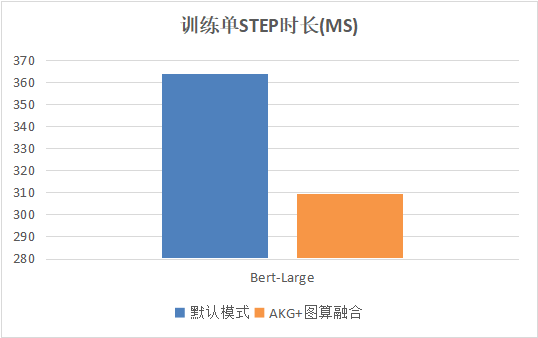
图12 Bert整网性能示例

算子自动生成技术是自动微分、自动并行、深度图优化三大图层优化问题的技术基础。在MindSpore 0.5版本,我们通过将算子自动生成技术与图算融合技术相结合,实现了Bert整网14.8%的性能提升。
在下一阶段,我们将持续在算子泛化,支持不同的硬件后端等方面进一步优化和增强。欢迎社区的小伙伴参与进来,共同见证MindSpore社区的成长和发展。
参考文献
[1] Li M, Liu Y, Liu X, et al. The Deep Learning Compiler: A Comprehensive Survey[J]. arXiv preprint arXiv:2002.03794, 2020.
[2] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated end-to-end optimizing compiler for deep learning. In 13th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 18). 578–594.
[3]Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. 2018. Tensor comprehensions: Framework-agnostic high performance machine learning abstractions. arXiv preprint arXiv:1802.04730 (2018).
[4] Nadav Rotem ,Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein, et al. 2018. Glow: Graph lowering compiler techniques for neural networks. arXiv preprint arXiv:1805.00907 (2018).
[5] Chris Leary and Todd Wang. 2017. XLA: TensorFlow, compiled. TensorFlow Dev Summit (2017).
[6] Scott Cyphers, Arjun K Bansal, Anahita Bhiwandiwalla, Jayaram Bobba, Matthew Brookhart, Avijit Chakraborty, Will Constable, Christian Convey, Leona Cook, Omar Kanawi, et al. 2018. Intel ngraph: An intermediate representation, compiler, and executor for deep learning. arXiv preprint arXiv:1801.08058 (2018).
[7] Auto Kernel Generator: https://gitee.com/mindspore/akg
[8] 梁晓峣. 2019. 昇腾AI处理器架构与编程, 清华大学出版社
[9]MindSpore图算融合官方教程文档 : https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/graph_kernel_fusion.html