33.图像定位
目录
1 常见图像处理任务
2 数据集展示
3 训练模型
3.1 导入库
3.2 处理数据集路径
3.3 定义解析xml函数
3.4 创建数据集
3.5 创建模型
3.6 编译模型
3.7 训练模型
3.8 加入tensorboard
3.9 加入检查点
3.10 保存模型
4 预测模型
5 扩展知识
1 常见图像处理任务
我们常见的图像处理任务有下面几种
- 分类任务
给机器一张图,它能知道,这个图是猫的一张图片

- 分类+定位
给机器一张图,它不仅知道这个图片是猫的图片,而且它也知道这个猫在哪

- 图像分割
找到可识别物体的每一个个体的轮廓,并可以分辨出该轮廓是何种物体,下面这张图就是每一类物体使用不同的颜色进行注明
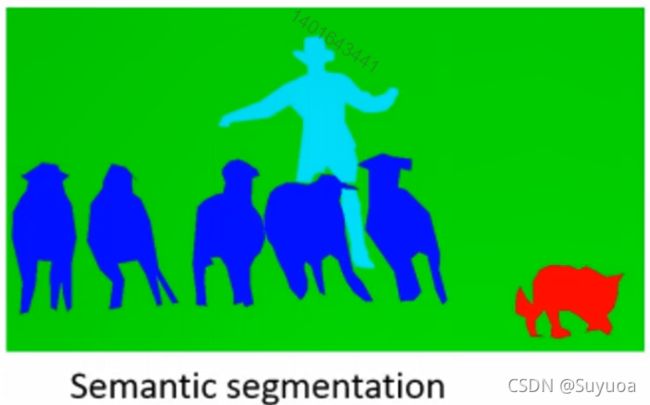
- 目标检测
目标检测和分类+定位是有区别的,分类加定位是图像中只有一种被检测物体,目标检测可以有多种

- 实例分割
目标检测+图像分割

之前我们解决了图像分类问题,下面我们来解决图像定位问题,我们下面使用数据集The Oxford-IIIT Pet Dataset作为例子展示一下定位问题的处理方式
2 数据集展示
我们看一下这个数据集,数据集由两个文件夹构成

annotations是我们的标注文件,如果我们要训练独有的文件,我们需要先对每一张图像进行标注,这个我们放到后面细说,我们这里先提一下。我们此次是任务是定位图像的脸部

主要使用的是xmls文件中的内容
我们可以用浏览器打开xml文件,我们打开第一个文件看一下

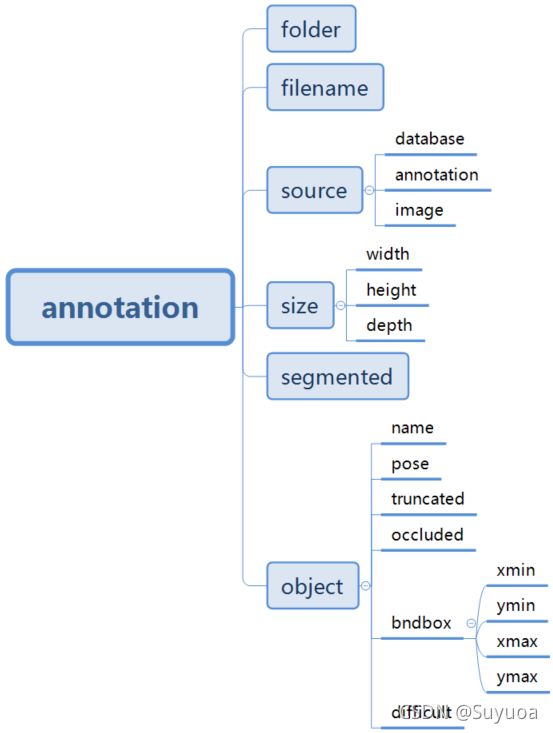
这里面记录了图像的名称(Abyssinian_1.jpg),图像的尺寸(600,400),通道(3),矩形框的左上角点(333,72),矩形框的右下角点(425,158)
那么我们如果解析xml应该这样看,它最高级的目录名称叫annotation,其中有若干个二级目录,比如folder,filename,二级目录中有的包含具体内容,有的还有三级目录,我们解析时应一层一层进行解析
images存放的是图像文件
我们的图片文件一共有7393个,我们的xml文件一共有3686个,也就是说图像与标注文件并不是一一对应的,我们下面再处理这个事情
3 训练模型
3.1 导入库

我们唯一没有使用过的库是lxml,这个库是我们用来解析上面提到的xml文件的
Rectangle是matplotlib中绘制矩形框的方法
我们先解析一个xml文件看一下,我们首先读取Abyssinian_1.xml这个文件
![]()
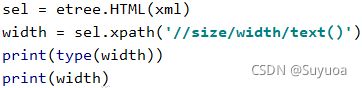
之后我们提取照片的宽度试一下,首先建立选择器,之后使用xpath的方法提取size中的width的内容
![]()
- 如果我们要提取的目录是唯一的目录,我们就可以使用//直接进行检索,如果没有我们就要从其他唯一的目录开始检索

发现会返回一个列表,列表中有宽度信息600,其余信息的提取方法也和width相同
这样我们就可以获取矩形框的两个角点坐标,我们把矩形框画在图像上看一下
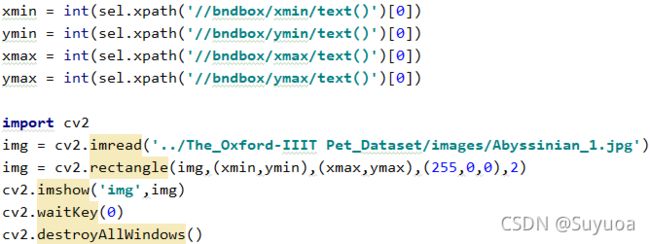

- 我们也可以使用plt进行绘制矩形框
上面是一张图的绘制方式,我们可以通过数据集看到,我们每一张的图片大小是不相等的,但我们训练时是需要图片大小相等的,图像尺寸的改变势必要对框的位置也进行改变,所以我们要按比例改变xmin,ymin,xmax,ymax这四个数值,计算方法如下
我们将
四个数值的新值命名为 new_xmin,new_ymin,new_xmax,new_ymax
原图像的宽与高命名为 width,height
新图像的宽与高命名为 new_width,new_height
- new_xmin = (xmin/width)*new_width
- new_ymin = (ymin/height)*new_height
- new_xmax = (xmax/width)*new_width
- new_ymax = (ymax/height)*new_height
3.2 处理数据集路径
我们先获取所有的图片文件与xml文件的路径
![]()
我们上面提到xml文件与image文件并不是一一对应的,所以我们现在要提取xml的文件名之后再去筛选出对应的标注图像文件,我们先获取图片的名称
![]()
之后我们判定,如果图像中的文件名存在于names中则加入,否则什么都不做

这样我们就得到了train_images与xmls两个列表,我们现在要保证让其一一对应,我们可以利用其相同的文件名进行排序
![]()
这样就一定一致了,sort的返回值是None,我们不要进行赋值
3.3 定义解析xml函数
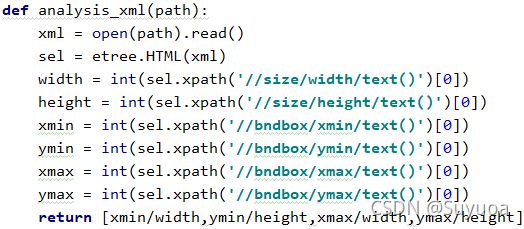
之后对xmls中的所有文件进行解析
![]()
我们看一下labels中的前三个
![]()
![]()
发现是一个列表中有四个浮点数值,这个和我们的期望是一样的,我们在训练的时候需要xmin,ymin,xmax,ymax四个列表,因此我们要将labels进行拆解
![]()
这样我们就得到了四个独立的列表,之后我们将四个列表转换为numpy

3.4 创建数据集
首先我们创建标签数据集
![]()
之后定义加载图像函数
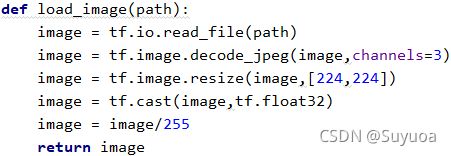
然后创建图像数据集
![]()
之后把这两个数据集组合到一起
![]()
之后我们区分训练集与测试集
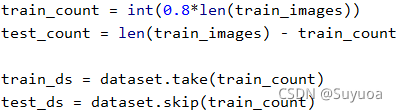
然后我们分别对训练集与测试集进行乱序,设置批次与循环
![]()
我们可以把dataset中的图像画出来,然后画上矩形框,看一下我们的dataset有没有问题

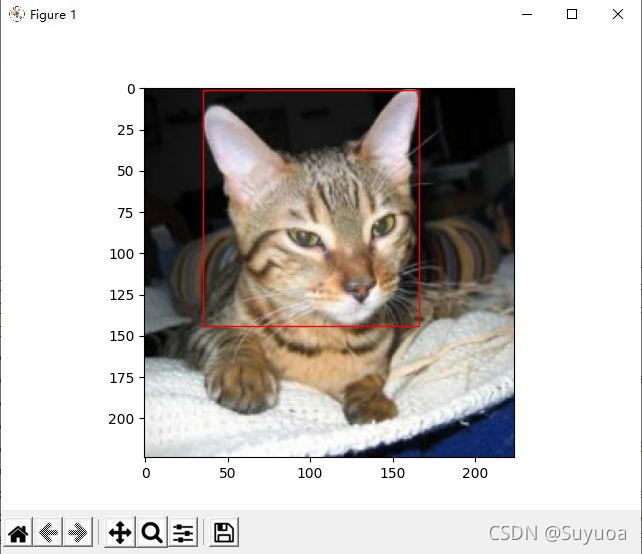
我们发现是没有什么问题的
3.5 创建模型
我们使用预训练模型xception进行训练,我们使用函数式API创建多分类问题

3.6 编译模型

由于我们这四个输出都是回归问题,所以我们loss都使用mse(均方差)就可以了
我们第一次使用到mae这个指标,这个指标的意思是平均绝对误差,它的计算方式如下,我们认为这个值越接近于0,模型训练的效果越好
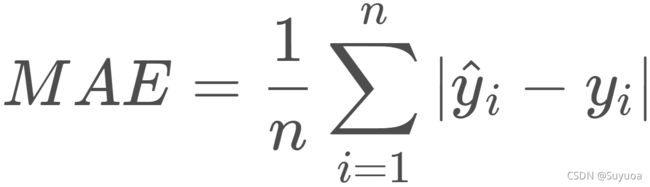
3.7 训练模型
![]()
3.8 加入tensorboard
我们加入tensorboard记录一下各种指标的变化情况
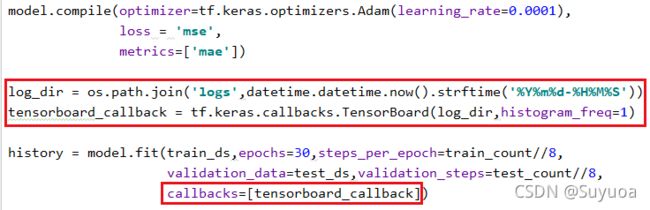
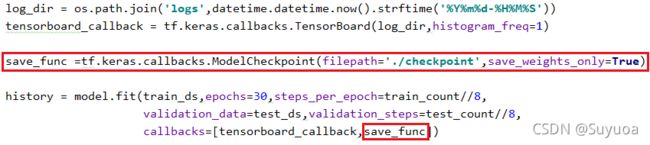
3.9 加入检查点
像这种需要长时间训练的模型,我们需要加入检查点以应对意外情况
3.10 保存模型
![]()
4 预测模型
预测之前我们先看一下tensorboard,一共有这些指标,我们挑几个看一下
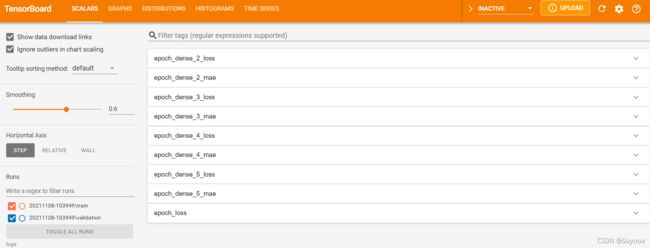
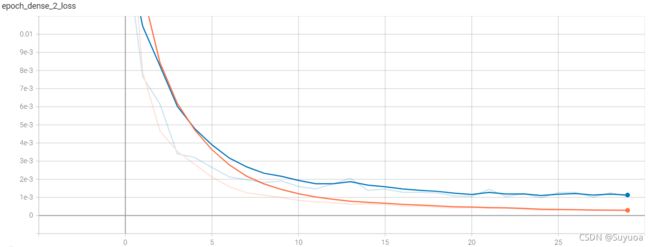
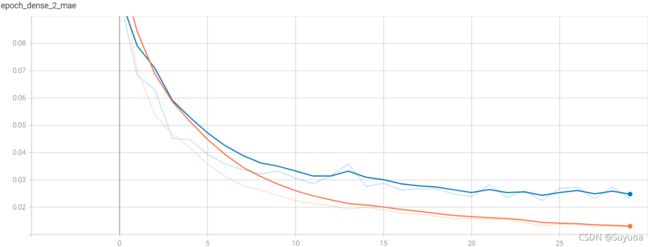
其余三个值和上面的loss和mae差不多,我们最后看一下总loss
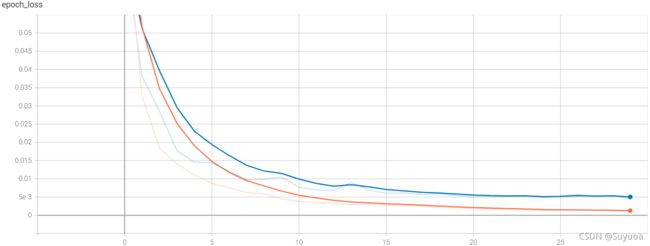
已经降到了很低的值,我们之后可以使用数据集外的图像进行预测
之后我们确认一下模型是否保存

我们之后创建一个文件夹test,文件夹中有狗的图片与猫的图片

这些图片都是不在数据集之内的,我们当前的模型只能识别图中的一个猫头或者狗头,识别单个目标在实际生活中也有应用,比如人脸识别的门禁,只需要识别一个人的脸就可以
代码部分首先我们导入库
之后读取模型
![]()
之后我们获取我们要测试的所有图片路径
![]()
之后我们定义加载图像函数,与训练时不同的是,由于训练时有batch,我们现在是一张一张预测的,所以我们要将图像升维
之后我们定义预测函数,首先我们加载图像,之后预测出四个值,然后我们使用opencv读取图像,之后获取图像的高与宽,再与得到的四个值对应相乘,得到预测的角点,之后再通过两个角点绘制出矩形框,然后显示出来

之后我们遍历测试图片路径,然后每个都预测一下
有的图片预测的还行
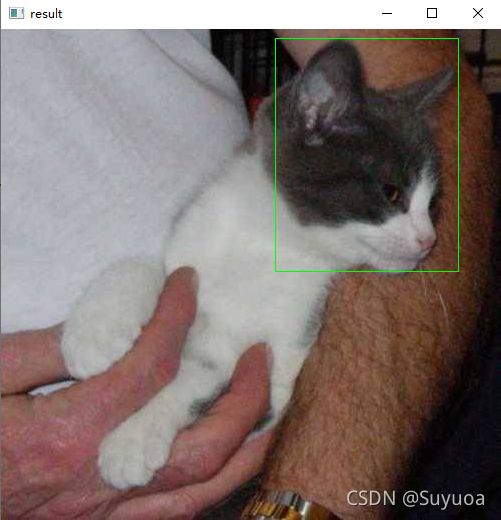
有的就不行,有可能是训练数据中没有低头的样本

有的精度稍差些


我们通过tensorboard的图像可以看到训练后期loss已经趋于平缓,如果再增加epoch也不会有更好的效果,我们的learning_rate设置的并不高,模型使用的也是预训练模型,这个时候如果我们想继续增大精度,我们就需要增加数据量了,我们当前只有3686个数据
5 扩展知识
我们在图像定位中也可以使用IoU来评估定位的精准度
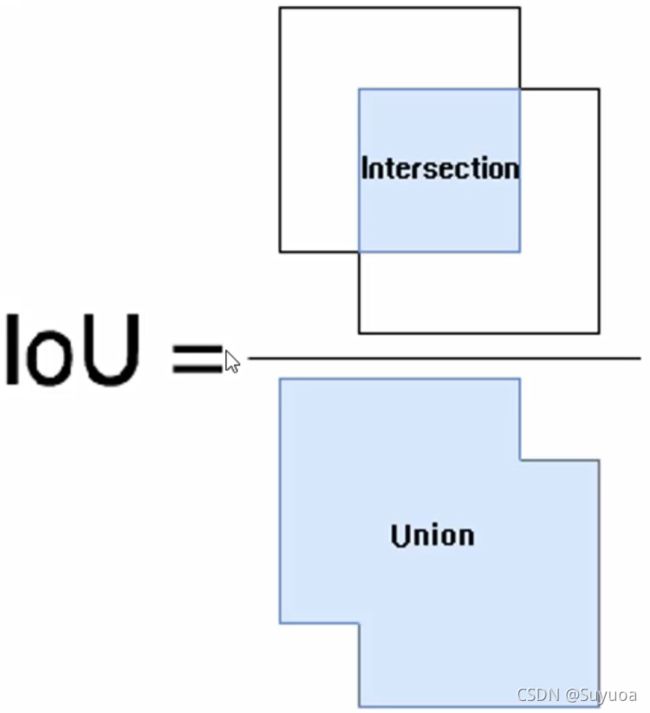
我们当前有两个矩形框,一个是预测的,一个是实际的,我们使用两个矩形框的交集除两个矩形框的并集
在图像定位问题中,不仅可以预测矩形框的四个点,也可以应用于人体检测,预测多个点
