CentOS7安装Hadoop3完全分布式
前提条件
拥有CentOS7服务器版环境
集群规划
| 项目 | 服务器node2 | 服务器node3 | 服务器node4 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | DataNode、SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager、NodeManager | NodeManager |
虚拟机准备
通网络
能ping通外网,例如:
ping baidu.com
如果ping不通,修改如下文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将ONBOOT=no改为ONBOOT=yes
重启网络或重启机器
重启网络
systemctl restart network
重启机器
reboot
修改默认主机名
# 查询主机名 [root@localhost ~]# hostname localhost.localdomain # 修改主机名 [root@localhost ~]# hostnamectl set-hostname node1 [root@localhost ~]# hostname node1 # 重启生效 [root@localhost ~]# reboot ... [root@node1 ~]#
新建普通用户
因为root用户权限太高,误操作可能会造成不可挽回的损失,所以我们需要新建一个普通用户来安装操作
添加一个普通用户,用户名例如:hadoop,方法如下:
[root@node1 ~]# adduser hadoop [root@node1 ~]# passwd hadoop Changing password for user hadoop. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: passwd: all authentication tokens updated successfully.
给普通用户添加sudo执行权限,且执行sudo不需要输入密码
[root@node1 ~]# chmod -v u+w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0440 (r--r-----) to 0640 (rw-r-----) [root@node1 ~]# sudo vi /etc/sudoers 在%wheel ALL=(ALL) ALL一行下面添加如下语句: hadoop ALL=(ALL) NOPASSWD: ALL [root@node1 ~]# chmod -v u-w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0640 (rw-r-----) to 0440 (r--r-----)
设置静态IP
查询虚拟机网关
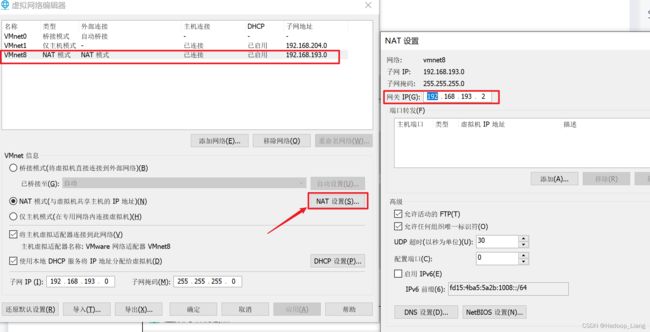
打开VMware-->编辑-->虚拟机网络编辑器

点击VMnet8的NAT模式-->点击NAT设置,查看到网关为:192.168.193.2
设置静态IP
[root@node1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改核心内容如下
BOOTPROTO=static IPADDR=192.168.193.140 GATEWAY=192.168.193.2 DNS1=192.168.193.2
注意:
1.BOOTPROTO设置为static,表示IP为静态的。
2.GATEWAY设置为上一步查询到的实际网关地址。
3.IPADDR设置为网关所在的网段,这里查到的网段为192.168.193网段,最后一位一般设置为128-255之间未被占用的地址。
关闭防火墙
[root@node1 ~]# systemctl stop firewalld
克隆主机
选中一台用来克隆的CentOS7机器,点击 虚拟机-->管理-->克隆,如下图所示:

点击 下一页

点击 下一页

选中创建完整克隆,点击 下一页

填写虚拟机名称CentOS7-node2,选择安装位置,点击完成

用同样的方法克隆出另外两台机器:CentOS7-node3、CentOS7-node4。
修改主机名
在node2上登录普通用户hadoop进行操作
# 修改主机名 [hadoop@node1 ~]$ sudo hostnamectl set-hostname node2 [sudo] password for hadoop: # 查看主机名 [hadoop@node1 ~]$ hostname node2 # 重启机器 [hadoop@node1 ~]$ sudo reboot
同样的方法:
修改node3的主机名为node3
node4的主机名为node4
修改静态ip
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
将BOOTPROTO设置为static,ip地址改为192.168.193.142,核心修改的语句如下:
BOOTPROTO=static IPADDR=192.168.193.142 GATEWAY=192.168.193.2 DNS1=192.168.193.2
重启网络或重启机器生效(可后面一起重启),然后用新ip登录机器。
sudo systemctl retart network.service
同样的方法,修改node3、node4机器的ip
node3 ip设置为 192.168.193.143 node4 ip设置为 192.168.193.144
修改ip与主机名的映射
[hadoop@node2 ~]$ sudo vi /etc/hosts
添加如下内容
192.168.193.142 node2 192.168.193.143 node3 192.168.193.144 node4
重启机器
[hadoop@node2 ~]$ sudo reboot
同样的方法,修改node3、node4机器。
配置机器之间免密登录
在node2机器操作:
ssh-keygen -t rsa
执行命令后,连续敲击三次回车键
拷贝公钥
ssh-copy-id node2 ssh-copy-id node3 ssh-copy-id node4
执行ssh-copy-id命令后,根据提示输入yes,再输入机器登录密码

验证
从node2发起ssh登录到node3,过程中不需要登录密码为配置成功。使用exit退出免密登录。
[hadoop@node2 ~]$ ssh node3 Last login: Fri Apr 1 09:21:02 2022 from 192.168.193.1 [hadoop@node3 ~]$ exit logout Connection to node3 closed.
同样的方法,在node3、node4机器上操作。
编写分发脚本
安装rsync命令
[hadoop@node2 ~]$ rsync --help -bash: rsync: command not found [hadoop@node2 ~]$ sudo yum install rsync -y
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
在主目录创建bin目录
[hadoop@node2 ~]$ mkdir ~/bin
创建分发脚本文件xsync
[hadoop@node2 ~]$ nano ~/bin/xsync
内容如下
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in node2 node3 node4
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done修改权限
[hadoop@node2 ~]$ chmod +x ~/bin/xsync
测试
分别在node3、node4机器安装xsync命令
sudo yum install rsync -y
把xsync命令发送到node3、node4
xsync /home/hadoop/bin

将脚本复制到/bin目录,方便root用户调用(三台机器都执行)
在node2机器执行:
[hadoop@node2 ~]$ sudo cp ~/bin/xsync /bin/
在node3机器执行:
[hadoop@node3 soft]$ sudo cp ~/bin/xsync /bin/ [sudo] password for hadoop: [hadoop@node3 soft]$ source /etc/profile
在node4机器执行:
[hadoop@node4 ~]$ sudo cp ~/bin/xsync /bin/ [sudo] password for hadoop: [hadoop@node4 ~]$ source /etc/profile
下载JDK和Hadoop
官方下载jdk和hadoop,下载版本名称如下:
jdk-8u212-linux-x64.tar.gz
hadoop-3.1.3.tar.gz
上传到Linux虚拟机(node2、node3、node4 3台机器都需要),上传到linux的存放安装包的目录下/home/hadoop/installfile(如果目录不存在,需要用mkdir ~/installfile命令先创建出来)

安装JDK
在node2机器上操作:
新建软件安装目录
在~目录下,新建一个soft目录,当作安装的软件。
[hadoop@node2 ~]$ mkdir soft
解压JDK到soft目录
[hadoop@node2 ~]$ cd ~/installfile/ [hadoop@node2 installfile]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C ~/soft
配置环境变量
sudo nano /etc/profile.d/my_env.sh
内容如下:
#JAVA_HOME export JAVA_HOME=/home/hadoop/soft/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
让环境变量生效
source /etc/profile
验证
java -version

看到版本号输出,说明jdk配置成功。
同样的方法,在node3、nod4执行安装jdk。
安装Hadoop
在node2机器上操作:
解压hadoop
[hadoop@node2 ~]$ cd installfile/ [hadoop@node2 installfile]$ tar -zxvf hadoop-3.1.3.tar.gz -C ~/soft
配置环境变量
sudo nano /etc/profile.d/my_env.sh
添加如下内容
#HADOOP_HOME export HADOOP_HOME=/home/hadoop/soft/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
让配置生效
source /etc/profile
验证
hadoop version

看到hadoop版本号输出,说明环境变量配置成功。
配置hadoop
进入hadoop配置目录
cd $HADOOP_HOME/etc/hadoop
配置core-site.xml
nano core-site.xml
注意:1.nano为编辑命令,可以用vi命令代替;2如果没有nano命令,可以用yum install nano -y来安装。
在之间添加如下内容:
fs.defaultFS
hdfs://node2:9820
hadoop.tmp.dir
/home/hadoop/soft/hadoop-3.1.3/data
hadoop.http.staticuser.user
hadoop
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
hadoop.proxyuser.hadoop.groups
*
配置hdfs-site.xml
nano hdfs-site.xml
在之间添加如下内容:
dfs.namenode.http-address
node2:9870
dfs.namenode.secondary.http-address
node4:9868
配置yarn-site.xml
nano yarn-site.xml
在之间添加如下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node3
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
2048
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
配置mapred-site.xml
nano mapred-site.xml
在之间添加如下内容:
mapreduce.framework.name
yarn
配置workers
nano workers
把原有的内容替换成如下内容:
node2 node3 node4
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
配置历史服务器
修改mapred-site.xml
nano mapred-site.xml
添加如下配置
mapreduce.jobhistory.address
node2:10020
mapreduce.jobhistory.webapp.address
node2:19888
配置日志聚集
修改yarn-site.xml
nano yarn-site.xml
添加如下配置
yarn.log-aggregation-enable
true
yarn.log.server.url
http://node2:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
分发hadoop安装文件
把hadoop安装文件从node2机器分发到node3、node4机器
[hadoop@node2 ~]$ xsync ~/soft/hadoop-3.1.3
查看node3和node4机器
[hadoop@node3 soft]$ ls hadoop-3.1.3 jdk1.8.0_212 [hadoop@node4 ~]$ ls soft/ hadoop-3.1.3 jdk1.8.0_212
修改环境变量
修改node3、node4环境变量,分别在node3、node4机器上操作
sudo nano /etc/profile.d/my_env.sh
添加如下内容:
#HADOOP_HOME export HADOOP_HOME=/home/hadoop/soft/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
让环境变量生效
source /etc/profile
验证
hadoop version
输出看到hadoop版本号为配置成功。
格式化文件系统
在node2机器执行格式化hdfs
[hadoop@node2 ~]$ hdfs namenode -format
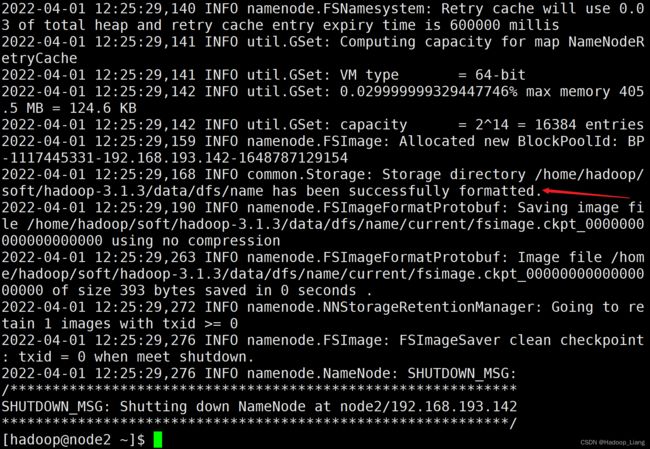
看到successfully formatted为格式化成功。
注意:格式化成功后,以后就不能再次格式化了。
启动hdfs
在node2机器上执行启动hdfs命令
start-dfs.sh

启动yarn
在node3机器上执行启动yarn命令
start-yarn.sh

验证
进程验证
分别在不同机器执行jps命令
[hadoop@node2 ~]$ jps 3062 Jps 2506 NameNode 2666 DataNode 2958 NodeManager
[hadoop@node3 ~]$ jps 2210 DataNode 2850 Jps 2700 NodeManager 2383 ResourceManager
[hadoop@node4 ~]$ jps 2240 DataNode 2562 Jps 2360 SecondaryNameNode 2456 NodeManager
浏览器验证
修改windows下的C:\Windows\System32\drivers\etc\hosts文件,添加如下映射语句
192.168.193.142 node2 192.168.193.143 node3 192.168.193.144 node4
浏览器访问
node2:9870

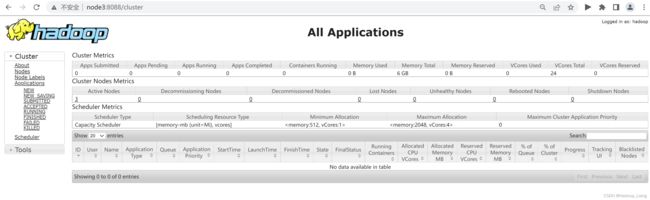
浏览器访问
node3:8088
参考:尚硅谷hadoop教程资料。
完成!enjoy it!