Strengthening IDS against Evasion Attacks with GAN-based Adversarial Samples in SDN-enabled network
CCF none
Qui C P X, Quang D H, Duy P T, et al. Strengthening IDS against Evasion Attacks with GAN-based Adversarial Samples in SDN-enabled network[C]//2021 RIVF International Conference on Computing and Communication Technologies (RIVF). IEEE, 2021: 1-6.
在支持SDN的网络中,使用基于gan的对抗性样本加强IDS以对抗逃避攻击
相关文章: Duy P T, Khoa N H, Nguyen A G T, et al. DIGFuPAS: Deceive IDS with GAN and Function-Preserving on Adversarial Samples in SDN-enabled networks[J]. Computers & Security, 2021, 109: 102367. —Computers & Security是个B
文章目录
-
- 代码
- 启发
- 摘要
- 1 简介
- 2 相关工作
- 3 提出的框架
-
- 3.1 数据预处理
-
- 3.1.1 数据分组
- 3.1.2 数据处理
- 3.2 DIGFuPAS的结构
-
- 3.2.1 Blackbox IDS
- 3.2.2 Generator
- 3.2.3 Discriminator
- 3.3 模型训练过程
- 3.4 自动测试和再训练以加强IDS
- 3.5 SDN体系结构模型
- 4 实验和结果
-
- 评价方法
- 实验环境
- 结果
代码
疑似是 HongQuangDevVN/IDSGAN-on-SDN
启发
特征可分为功能特征和非功能特征。
改变非功能特征产生对抗性的流量,一旦检测成功率下降就利用产生的恶意flow继续训练模型。
设计系统搭建的论文写作可以参考
摘要
基于机器学习的IDS(ML-IDS)已经被探索并仍在开发中。然而,这些系统给出的错误警报率很高,而且很容易被复杂的攻击所欺骗,如含有扰动的变种攻击。因此,有必要通过模拟真实世界网络攻击的变异来不断评估和改进这些系统。
基于生成判别网络(GANs),我们介绍了DIGFuPAS,通过更改flow中的非功能字段以生成恶意的数据流,从真实的攻击流量中变异使IDS无法检测。生成的数据流被用来重新训练ML-IDS,以提高IDS检测复杂攻击的稳健性。实验是通过2个标准进行和评估的。在名为CICIDS2017的公共数据集上,检测率(DR)和F1得分(F1)。 DIGFuPAS一旦被整合为支持SDN的网络的自动化可持续发展测试Pipeline,就可以用来持续测试和评估IDS的能力。
关键词: IDS;对抗样本;WGAN;流量生成
1 简介
目前,软件定义网络(SDN)架构也是一种新的、灵活的网络架构,它被认为是智能城市或5G/6G背景下的转型方向[1]。原因是SDN在集中式控制器上提供网络管理权,而不是单独的网络设备。在互联网上的安全威胁日益多样化和复杂化的情况下,入侵检测系统(IDS)已经成为检测网络攻击的重要工具。IDS监控网络流量,如果发现不安全或恶意的流量,就会发出警报。它是通过将网络流量分类为良性和恶意的记录来实现的。当利用这一优势与SDN控制器连接时,入侵检测系统(IDS)可以通过OpenFlow协议监测大规模网络的流量统计。 在这种网络中,这些安全网络服务功能被部署为虚拟网络功能(VNF)[2]。因此,如果选择这些服务来监测、保护和应对安全威胁,就必须不断评估和加强IDS对多样化攻击变体的鲁棒性,使其不断更新[3][4]。
综上所述,我们提出了DIGFuPAS(用GAN和对抗性样本上的函数保全来欺骗IDS),这是一个基于GAN的框架,用于创建对抗性的恶意流量记录,可以欺骗并避免防御系统的检测。在本文中,我们使用了一个黑盒IDS,它使用机器学习算法来准确模拟IDS在现实世界中的工作方式,当攻击者不知道其内部结构时。我们设计并完善了基于Wasserstein GAN(WGAN)[11]的生成器和判别器,因为它在具有“稳定训练”的特点。
生成器用原始恶意流量创建对抗性攻击。为了确保生成的流量的入侵行为,我们只修改每种攻击类型的非功能特征。鉴别器模仿黑匣子IDS,为生成器的训练提供反馈。这种可以绕过IDS的对抗性流量被用来重新训练ML-IDS,以增强对规避攻击的鲁棒性。
2 相关工作
基于WGAN[11],Zilong Lin等人研究IDSGAN提出了一种产生对抗性攻击流量的机制,可以欺骗机器学习IDS。
Usama等人[10]的研究表明,在改变网络流量的一些功能特征时,IDSGAN存在问题。该研究的作者随后提出了一种机制,以确保在对抗性原型开发过程中,当生成器只对非特定特征进行改变时,功能特性得以保持。但该方案建议使用基本的GAN,它在训练过程中可能面临着难以收敛的问题
Msika等[14]的研究表明,输入大小和多样性会影响GAN的性能
本研究使用非功能特征作为对抗性模型的输入,与使用IDSGAN等噪声相比,可以减少生成数据的多样性。
Usama研究[10]中使用的KDD99数据集只包含旧的流量日志,使得检测新的攻击变得困难。
IDSGAN使用了改进版本的KDD99,名为NSLKDD,但这两个数据集面临着相同的问题[15]。
本实验在CICIDS2017数据集[16]上进行
此外通过将一个IDS实例作为一个虚拟化的网络功能(VNF)进行部署,我们的框架可以用作一个自动和连续的安全评估工具,以评估IDS在SDN中对逃避攻击的健壮性。
3 提出的框架
DIGFuPAS由3个主要部件组成。生成器G、鉴别器D、黑盒IDS(B-IDS)。
这个框架被训练成能够从基于Wassertein GAN的初始攻击模式中生成对抗性攻击数据。
Wassertein GAN是一个GAN变体,旨在克服标准GAN模型中”训练生成器“和“收敛”的困难。本文的目的是逃避B-IDS的检测,使其无法检测到从DIGFuPAS创建的新攻击模式。
3.1 数据预处理
我们使用由加拿大网络安全研究所收集的CICIDS2017数据集[16]。 这个数据集包括常见攻击之前的良性和恶意网络流量。它是通过PCAP文件提供的,其中包含数据收集期间的网络数据包,以及带有分析和标记的网络流的CSV文件。
8个CSV文件中的6个的数据被用来模拟攻击。
3.1.1 数据分组
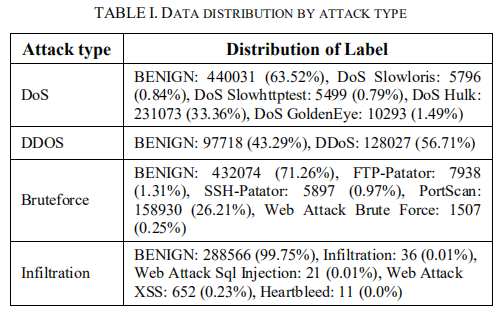
根据所提供数据的属性,将流量记录分为DoS、DDoS、Bruteforce和渗透四个攻击组。
我们使用来自4个主要文件的数据,
- 周三工作时间(1)
- 周五工作时间下午(2)
- 周二工作时间(3)
- 周四工作时间下午渗透(4)
作为每个攻击组的主要数据。为了解决Bruteforce和渗透组在这两次攻击的记录数量太小时时的数据不平衡问题,我们分别使用Friday-WorkingHours-Afternoon-PortScan(raw5)和Thursday-WorkingHours-Morning-WebAttacks(raw6)文件来补充数据。我们只使用了这些文件中的恶意记录。分组过程后,为每个攻击组具有数据信息的数据集,如表I所示。
3.1.2 数据处理
首先,删除列名称中的空格,并将这些名称转换为相应的小写格式。
然后,我们删除了数据集中不必要的列,如重复的列。此外,在所有4个攻击组中只包含一个值的列也不会影响训练结果,因此可以忽略它们,包括平均包/批量、平均批量、平均批量率、psh标志、平均字节/批量、平均标志、平均包/批量、平均字节/批量。
此外,这些列表示用于构建数据集的系统的信息也被删除,即流id、源ip、源端口、目标ip、目标端口、协议、时间戳。
在我们的数据集中,删除了1个重复的列和15个单值列,处理完后,每个攻击组数据文件中含有68个特性和1个标签
接下来,我们删除任何列中包含NaN(不是数字/未知)值的不完整记录。
然后,使用Min-Max函数(1)将数据文件中的每个值归一化为[0,1]范围,其中xmin、xmax分别为列的最小值和最大值。
X ′ = X − X min X max − X min X^{\prime}=\frac{X-X_{\min }}{X_{\max }-X_{\min }} X′=Xmax−XminX−Xmin
最后,为了方便训练过程,在每种攻击类型上,将值为良性的标签更改为0,而其余表示攻击类型的标签则映射为1
在数据处理的最后,每个数据文件被扰乱并按4:4:2的比例分成3个子文件,每个文件包含68个特征和标签。两个比例较高的文件称为train1和train2,用于独立训练B-IDS和GAN,另一个文件称为test,用于评估训练结果。
3.2 DIGFuPAS的结构
生成器和判别器是基于Wassertein GAN模型建立的,以提高学习过程的稳定性。生成器将带有噪声的攻击记录作为其输入,以产生对抗性的交通记录。这些记录被送入B-IDS进行标记,然后传递给鉴别器,以便鉴别器能够学习B-IDS如何对流量进行分类。从那里,可以从生成器那里得到关于生成数据质量的反馈。生成器依靠鉴别器的反馈来自我调整和改进其数据生成。DIGFuPAS的工作流程细节显示在图1中。

3.2.1 Blackbox IDS
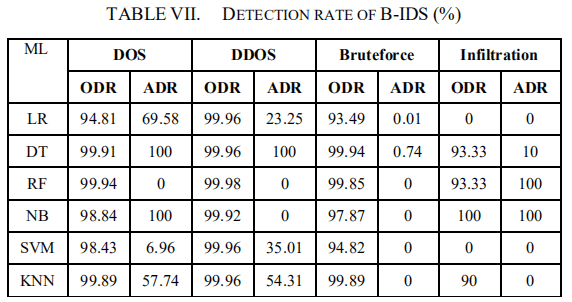
本研究使用基于ML的IDS作为黑盒IDS(B-IDS),它在非对抗性常规数据的攻击检测中表现出显著的性能。正如其名称所示,攻击者对B-IDS内部的检测算法没有任何了解。在这项工作中,我们使用Sklearn库提供的机器学习分类器来构建和模拟B-IDS,但在实际情况下,它可能是一个商业IDS或一个我们想进行渗透测试和增强鲁棒性的自建IDS产品。为了探索DIGFuPAS对基于ML的IDS的有效性,我们针对6个IDS中使用的6种机器学习算法。逻辑回归(LR)、支持向量机(SVM)、高斯朴素贝叶斯(NB)、决策树(DT)、随机森林(RF)、K-近邻(KNN)。
B-IDS需要对68个属性的记录进行预处理。然后,它有责任预测这些记录是良性的还是攻击性的流量,并有很高的准确性。在这项工作中,我们使用0.5的阈值来识别类别。如果σ>=0.5,B-IDS返回值为1(攻击),否则如果σ<0.5,标签为0(良性)。
3.2.2 Generator
生成器负责生成能够欺骗B-IDS的对抗性数据。根据SIGMA[14],我们从预处理流量的68个属性中为每个特定的攻击组选择M个功能特征。这些功能特征需要保持不变,以不影响攻击记录的性质,如表二。

因此,我们使用生成器对剩余的非功能特征进行扰动,以创建能够绕过IDS但保留攻击能力的对抗性数据。生成器由6个神经网络层组成,详细设计如表三所示。
生成器根据来自鉴别器的评价调整权重以改善其数据生成。根据WGAN模型,生成器损失函数(2)被定义为鉴别器对生成器生成的数据的评价分数的算术平均值。
L G = E a ⊂ S ATTACK ,noise D ( G ( a,noise ) ) L_{G}=E_{a \subset S_{\text {ATTACK }} \text {,noise }} D(G(\text { a,noise })) LG=Ea⊂SATTACK ,noise D(G( a,noise ))
3.2.3 Discriminator
在训练期间,鉴别器接收来自B-IDS的标记数据,并试图遵循(模仿)B-IDS的工作方式。鉴别器学会使用Wasserstein Distance算法[11]来评估对抗性攻击数据和原始攻击数据之间的差异。我们使用表四所示的鉴别器的设计。

鉴别器的学习结果被用来评估生成器生成的数据,并反馈给生成器,帮助其改进数据生成。对于自我改进的区分,判别器损失函数(3)被定义为攻击标记数据的平均得分与标记数据的得分平均值之差为正常。在(3)中,a和n分别代表攻击和正常数据的子集(或批次)中的一条记录。
L D = E a ⊂ B A T T A C K D ( a ) − E n ⊂ B N O R M A L D ( n ) L_{D}=E_{a \subset B_{A T T A C K}} D(a)-E_{n \subset B_{N O R M A L}} D(n) LD=Ea⊂BATTACKD(a)−En⊂BNORMALD(n)
3.3 模型训练过程
在开始训练GAN的过程之前,每个B-IDS都要用每个攻击组的文件train1中的数据进行独立预训练。
训练结束后,B-IDS能够以较高的精度区分攻击或正常流量。
接下来,我们使用train2中的数据同时训练生成器和鉴别器。生成器将把带有噪声的攻击流量的非功能特征作为输入。它的输出将与未改变的功能特征结合起来,形成完整的对抗性攻击流量。生成的对抗性样本与正常样本混合,放入B-IDS中进行标记。标记后的数据作为判别器的输入,用于训练判别器学习如何评估被B-IDS标记为攻击和正常的流量之间的区别。
生成的数据流被发送到判别器进行评估,其反馈信息随后被用来改进数据生成能力。当大量的对抗性样本被标记为正常时,训练过程是成功的,这意味着生成器可以创建能够欺骗B-IDS的数据。为了确保模型在实际数据集上仍能很好地工作,只包含IDS和DIGFuPAS的未知数据的测试数据文件被用来评估训练结果。
3.4 自动测试和再训练以加强IDS
在部署时,IDS需要不断测试和更新,以适应新的攻击。为了创建一个自动和连续的IDS入侵测试机制,将使用训练有素的DIGFuPAS框架来建立该机制。DIGFuPAS采用传统的攻击数据来产生对抗性的流量,然后将其送入IDS进行检测测试。一旦对抗性流量能够以较高的速度通过IDS,即IDS的检测能力下降,这些对抗性流量就会被用来进行再训练。这个过程可以自动和持续地进行。
具体来说,在用独立的测试数据文件进行测试以检查IDS的检测能力是否降低后(结果见表七),我们收集对抗性样本进行再训练。对于train1(IDS训练数据文件)中的每个本地攻击流量,我们通过添加随机噪声向量来生成5个对抗性流量。产生的对抗性流量被视为新的攻击流量(标记为1),然后添加到train1中,形成新的数据集进行再训练。然后,重新训练IDS的过程就可以进行了。
3.5 SDN体系结构模型
我们使用Floodlight[17]作为控制器,使用Containernet[18]用OpenVSwitch和Docker主机来模拟SDN网络系统。DIGFuPAS的生成器、B-IDS模型和CICFlowMeter提取器被构建在一个Docker容器中,并在模拟系统中作为IDS主机工作。 这个IDS主机捕捉整个网络的数据,保存为PCAP文件。CICFlowMeter提取器读取PCAP文件,并将特征提取到CSV文件中,其结构类似于用于训练的CICIDS-2017数据集中的文件。
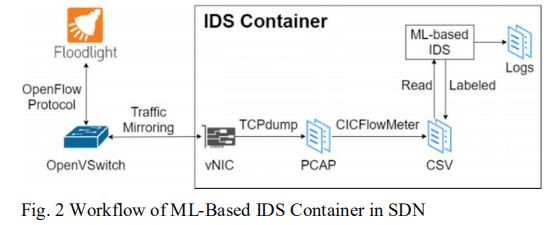
IDS模型处理和分析获得的CSV文件以检测攻击。这些文件中的数据是由IDS标记的。在工作中,IDS创建的日志包含描述流量是否为攻击的一般信息。图2显示了SDN网络上IDS容器的流程。IDS的工作流程由两个主要的平行和独立的进程组成,如表五和表六所示。在现实世界的场景中,我们还将DIGFuPAS作为一个测试工具与部署在系统中的IDS整合在一起,以评估和提高检测器的鲁棒性。这意味着IDS的流量预测日志可以被DIGFuPAS访问。


4 实验和结果
评价方法
我们根据2个标准来评估研究成果。 检测率(DR)和F1分数(F1)。攻击检测率由(4)定义为IDS检测到的攻击流的数量与总测试攻击数据的比率。我们考虑用数据集的原始攻击数据(原始检测率-ODR)和由DIGFuPAS的生成器生成的对抗性攻击数据(对抗性检测率-ADR)来计算DR。 F1得分,如(5)所示,是精确得分和召回率这两个量的调和平均值。F1分数评估IDS覆盖假阳性和阴性案例的能力。我们用这个指标来评估在再培训中使用对抗性数据的影响。
调和平均数(英语:harmonic mean),是求一组数值的平均数的方法中的一种,一般是在计算平均速率时使用。
调和平均数是将所有数值取倒数并求其算术平均数后,再将此算术平均数取倒数而得,其结果等于数值的个数除以数值倒数的总和。一组正数 x 1 , x 2 . . . x n x_1, x_2 ... x_n x1,x2...xn的调和平均数H其计算公式为:
H = n 1 x 1 + 1 x 2 + … + 1 x n H=\frac{n}{\frac{1}{x_{1}}+\frac{1}{x_{2}}+\ldots+\frac{1}{x_{n}}} H=x11+x21+…+xn1n
——定义来自Wikipidia
D R = Num of Detected Attack Num of all Attack ∗ 100 F 1 = 2 ∗ Precision ∗ Recall Precision + Recall \begin{gathered} D R=\frac{\text { Num of Detected Attack }}{\text { Num of all Attack }} * 100 \\ F 1=\frac{2 * \text { Precision } * \text { Recall }}{\text { Precision }+\text { Recall }} \end{gathered} DR= Num of all Attack Num of Detected Attack ∗100F1= Precision + Recall 2∗ Precision ∗ Recall
实验环境
DIGFuPAS框架是在运行Ubuntu 20.04的VPS上建立和测试的,该VPS有16核英特尔至强E5-2660 CPU 2.0 GHz,16GB内存,60GB存储,没有GPU。DIGFuPAS的源代码是用Python 3编程的,使用的库包括Numpy、Pandas、Sklearn、PyTorch等。 我们使用内置的Sklearn分类模型构建B-IDS。 对于生成器和判别器,我们使用PyTorch库以获得高性能。我们参考了WGAN模型的推荐参数[19],然后测试并选择0.0005作为学习率,512作为批次大小,使用RMSprop优化算法,判别器的训练速度比生成器快5倍。我们的框架训练了50个epochs。
SDN环境是在Ubuntu服务器20.04上使用Floodlight控制器和Containernet以及Docker的支持建立的,4个英特尔Cores i5 10210U CPU最高4.2GHz,4GB内存,100GB存储,没有GPU。我们的SDN包含一个控制器和3台攻击者、网络服务器、IDS的主机。
结果
- DIGFuPAS的性能
- 再训练以增强IDS的鲁棒性
- 在SDN中部署IDS
。。。