他人的数据挖掘面试题-经验
关于面京东,感触只有一个,虐的快吐血了。首先说京东分四个板块,有京东商城、京东金融、京东刚收购的拍拍和海外事业部。我这个职位主要是在金融部数据组做数据挖掘和机器学习,还有推荐系统。面试是在周一,本身也没打算正经去面试的,结果被虐了整整一个下午。。。。。。
实话实说,京东在整个互联网行业里待遇基本是最低的,唯独平台好,每天有10亿新的用户行为数据,对于DM而言,再好不过了。教主让我多面试几家,虽然某狗给13k,但是实在顶不住快被虐的吐血的压力,某狗、优x和乐x就在等等吧。
面试经过,好痛苦。。。上来先自我介绍什么的就不说了,接着就是问推荐系统。还好我周末花了两天的时间把项亮老师写的《推荐系统实战》过了一边,于是我就开始扯架构,然后说了说相关算法,比如User协同过滤和Item协同过滤,还有如果遇到冷启动问题该如何处理神马的。说完推荐,就问我编码能力怎么样,我说还行,又问sql怎么样,我说以前做过购物网站,一般的CRUD还凑合,于是就让我写一个sql的嵌套查询来输出一下在一段时间内每个用户最后一次的购买的物品和购买时间,恩。。。没错。。。写坏了。。。limit写成了top,还好我机智,解释说top是sqlserver的,mysql里用limit。最左面的面试官批评我说:“以后不能只写那种简单的,稍微复杂一点的也要多写写,这张纸你拿回去吧,在你数据库里运行试试”,我心想“完了,这就回去了??!!!”不过还好没有。。。接着最右面的面试官(加我qq的那个小leader)说:“你说你以前搞过算法竞赛,你能写写堆排序么?”我一愣,哎呀妈呀,只记得算法过程了。。。好吧,“那你就写个堆排序吧”,于是面试官们就出去了。。。好忐忑啊,手机在旁边就是不敢百度啊,硬着头皮写吧。。。过了一会儿,面试官们回来了,我基本也写完了,然后他们就拿着来回看啊。。。我心里七上八下。。。。。。。不过还好,好像写的没什么问题。接着就问我数据分析处理怎么样,我说跟着老师学过一点DM,参加过天猫大数据竞赛,可惜rank 1300+,相关工具用过Weka,大数据平台hadoop正在自学,我自学能力很强。他们表示无法证明我自学能力强,还好我有准备,这个专业top1在这里放着呢哈哈~。然后就是关于机器学习的问题了。问我会什么,我说分类聚类、分词、关联规则什么的。“那你分类都会什么”,我说k近邻(当时说成了k邻近,其实我到现在都没注意到底是k近邻还是k邻近,反正当时面试官愣了一下,我还不如直接说knn)、朴素贝叶斯、SVM什么的,神经一抽还很脑残地把kmeans说进去了,这明明是无监督的聚类。。。然后问我他们有什么区别,我只说了NB是基于概率统计的算法模型,其他的是基于空间分割的。在SVM方面问的不是很深,万幸没有细问到四个kernal,要不我估计就好pass掉了。一个面试官说,你谢写写NB分类吧,好家伙。。。继续硬着头皮写,写完以后解释了一下算法思想,先验概率和后验概率神马的。最后还有什么不记得了,只记得最最最后,数据组高级项目组长来了,然后又问了我毕业设计爬虫是单线程的么,我说是单进程多线程,还问了问余弦聚类特征向量是如何取的,我说用tf-idf,取前20词,在比较时构成40维的向量,还问堆排序为什么是nlogn的效率,这个我跪了。。。结束后,几个在场的面试官都说可以,问我待遇有什么要求,我说我是应届生,而且我同学做的都是以开发为主,我也不太懂行情,你们看着给吧,于是。。。!!!!就是这么坑!!!!早知道我就多要点了,刘强东一定是把钱都给奶茶妹妹花了!!!不过后来leader说不满意的话周三可以找人力的聊聊,结果我周二下午就去了,人力老大跟我笑着聊了一下午互联网金融,听得我是个晕头转向。邻近下班的时候才说到正题,我重新提了要求,他说他们回去再商量一下,一周内给回复。我心想,你要是不满足我的新要求我就不去了呢!(开玩笑。。。毕竟JD也不小,我更看好这个平台。)
总结,计算机工程专业!=计算机专业,要不是我们学校这么坑非要把我们忘软件外包方向推从而提高就业率,很多有志骚年们还是有多种出路的。编码不一定必须搞软件开发,数据挖掘、机器学习、推荐、图形图像处理、云计算都是很好的方向,虽然本科教学过程中一般没有这些,但是大量的课余时间都可以用来自学。一开始我是找王金龙博士了解DM这个方向,然后王导给我推荐了一些书以及相关的资料,不过后来王导忙着出国也不理我了。关于机器学习,《集体编程智慧》、《统计学习方法》是非常好的入门书籍,我很推荐。其实这些入门书籍要是吃透了,尤其是《统计学习方法》里面的数学推导搞懂了,拿ML的offer很轻松。其他方面,数学很重要,除了高数线代概率,还有凸优化,这个数学在本科阶段基本没有讲,《矩阵论》也可以看看。网易斯坦福大学公开课、Coursea的ML课都非常好,讲师都是Andrew Ng(敢不认识他?)。数据挖掘方面,我也不是很深入,我只看过《数据挖掘导论》,浙江大学的那个数据挖掘视频太老了。。。
其他的,编码能力要很好,数据结构算法一定要弄清,尽量都会写;sql语句是硬功夫;多搞算法还是很有好处的。写的很乱,各位将就看。
PS:为什么从开始关注JD股价开始,它就一直跌!!!
写在后面。。刚刚财哥打电话。。说收到offer了!!财哥就是这么霸气有木有!!!!
本文转载自:微信公众账号 - IT面试,版权归原作者所有!
================================================================================
一、简答题(30分)
1、简述数据库操作的步骤(10分)
步骤:建立数据库连接、打开数据库连接、建立数据库命令、运行数据库命令、保存数据库命令、关闭数据库连接。
经萍萍提醒,了解到应该把preparedStatement预处理也考虑在数据库的操作步骤中。此外,对实时性要求不强时,可以使用数据库缓存。
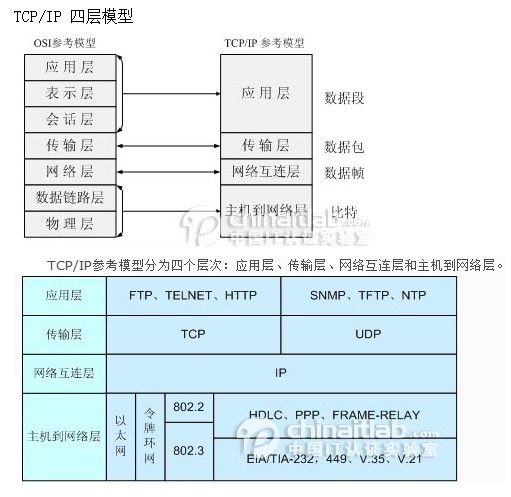
2、TCP/IP的四层结构(10分)
3、什么是MVC结构,简要介绍各层结构的作用(10分)
Model、view、control。
我之前有写过一篇《MVC层次的划分》
二、算法与程序设计(45分)
1、由a-z、0-9组成3位的字符密码,设计一个算法,列出并打印所有可能的密码组合(可用伪代码、C、C++、Java实现)(15分)
把a-z,0-9共(26+10)个字符做成一个数组,然后用三个for循环遍历即可。每一层的遍历都是从数组的第0位开始。
2、实现字符串反转函数(15分)
#include#include <string> using namespace std; void main(){ string s = "abcdefghijklm"; cout << s << endl; int len = s.length(); char temp = 'a'; for(int i = 0; i < len/2; i++){ temp = s[i]; s[i] = s[len - 1 - i]; s[len - 1 - i] = temp; } cout << s; }
3、百度凤巢系统,广告客户购买一系列关键词,数据结构如下:(15分)
User1 手机 智能手机 iphone 台式机 …
User2 手机 iphone 笔记本电脑 三星手机 …
User3 htc 平板电脑 手机 …
(1)根据以上数据结构对关键词进行KMeans聚类,请列出关键词的向量表示、距离公式和KMeans算法的整体步骤
KMeans方法一个很重要的部分就是如何定义距离,而距离又牵扯到特征向量的定义,毕竟距离是对两个特征向量进行衡量。
本题中,我们建立一个table。
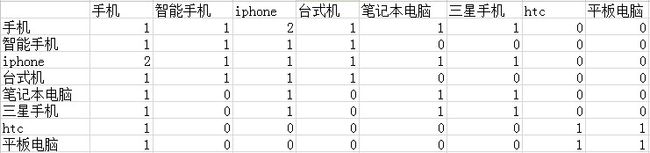
只要两个关键词在同一个user的描述中出现,我们就将它在相应的表格的位置加1.
这样我们就有了每个关键词的特征向量。
例如:
<手机>=(1,1,2,1,1,1,0,0)
<智能手机> = (1,1,1,1,0,0,0,0)
我们使用夹角余弦公式来计算这两个向量的距离。
夹角余弦公式:
设有两个向量a和b,![]() ,
,![]()

所以,cos<手机,智能机>=(1+1+2+1)/(sqrt(7+2^2)*sqrt(4))=0.75
cos<手机,iphone>=(2+1+2+1+1+1)/(sqrt(7+2^2)*sqrt(2^2+5))=0.80
夹角余弦值越大说明两者之间的夹角越小,夹角越小说明相关度越高。
通过夹角余弦值我们可以计算出每两个关键词之间的距离。
特征向量和距离计算公式的选择(还有其他很多种距离计算方式,各有其适应的应用场所)完成后,就可以进入KMeans算法。
KMeans算法有两个主要步骤:1、确定k个中心点;2、计算各个点与中心点的距离,然后贴上类标,然后针对各个类,重新计算其中心点的位置。
初始化时,可以设定k个中心点的位置为随机值,也可以全赋值为0。
KMeans的实现代码有很多,这里就不写了。
不过值得一提的是MapReduce模型并不适合计算KMeans这类递归型的算法,MR最拿手的还是流水型的算法。KMeans可以使用MPI模型很方便的计算(庆幸的是YARN中似乎开始支持MPI模型了),所以hadoop上现在也可以方便的写高效算法了(但是要是MRv2哦)。
(2)计算给定关键词与客户关键词的文字相关性,请列出关键词与客户的表达符号和计算公式
这边的文字相关性不知道是不是指非语义的相关性,而只是词频统计上的相关性?如果是语义相关的,可能还需要引入topic model来做辅助(可以看一下百度搜索研发部官方博客的这篇【语义主题计算】)……
如果是指词频统计的话,个人认为可以使用Jaccard系数来计算。
通过第一问中的表格,我们可以知道某个关键词的向量,现在将这个向量做一个简单的变化:如果某个分量不为0则记为1,表示包含这个分量元素,这样某个关键词就可以变成一些词语的集合,记为A。
客户输入的关键词列表也可以表示为一个集合,记为B
Jaccard系数的计算方法是:
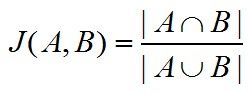
所以,假设某个用户userX的关键词表达为:{三星手机,手机,平板电脑}
那么,关键词“手机”与userX的关键词之间的相关性为:
J("手机",“userX关键词”)=|{三星手机,手机,平板电脑}|/|{手机,智能手机,iphone,台式机,笔记本电脑,三星手机,HTC,平板电脑}| = 3/8
关键词“三星手机”与用户userX的关键词之间的相关性为:
J("三星手机",“userX关键词”)=|{手机,三星手机}|/|{手机,三星手机,iphone,笔记本电脑,平板电脑}| = 2/5
三、系统设计题(25分)
一维数据的拟合,给定数据集{xi,yi}(i=1,…,n),xi是训练数据,yi是对应的预期值。拟使用线性、二次、高次等函数进行拟合
线性:f(x)=ax+b
二次:f(x)=ax^2+bx+c
三次:f(x)=ax^3+bx^2+cx+d
(1)请依次列出线性、二次、三次拟合的误差函数表达式(2分)
误差函数的计算公式为:

系数1/2只是为了之后求导的时候方便约掉而已。
那分别将线性、二次、三次函数带入至公式中f(xi)的位置,就可以得到它们的误差函数表达式了。
(2)按照梯度下降法进行拟合,请给出具体的推导过程。(7分)
假设我们样本集的大小为m,每个样本的特征向量为X1=(x11,x12, ..., x1n)。
那么整个样本集可以表示为一个矩阵:
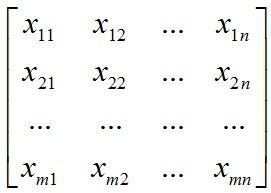 其中每一行为一个样本向量。
其中每一行为一个样本向量。
我们假设系数为θ,则有系数向量:

对于第 i 个样本,我们定义误差变量为

我们可以计算cost function:
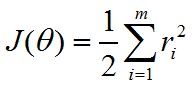
由于θ是一个n维向量,所以对每一个分量求偏导:
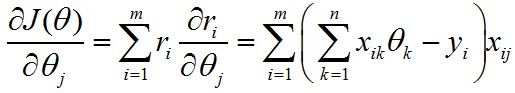
梯度下降的精华就在于下面这个式子:
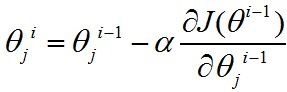
这个式子是什么意思呢?是将系数减去导数(导数前的系数先暂时不用理会),为什么是减去导数?我们看一个二维的例子。
假设有一个曲线如图所示:
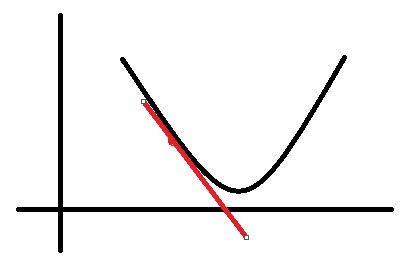
假设我们处在红色的点上,那么得到的导数是个负值。此时,我在当前位置(x轴)的基础上减去一个负值,就相当于加上了一个正值,那么就朝导数为0的位置移动了一些。
如果当前所处的位置是在最低点的右边,那么就是减去一个正值(导数为正),相当于往左移动了一些距离,也是朝着导数为0的位置移动了一些。
这就是梯度下降最本质的思想。
那么到底一次该移动多少呢?就是又导数前面的系数α来决定的。
现在我们再来看梯度下降的式子,如果写成矩阵计算的形式(使用隐式循环来实现),那么就有:
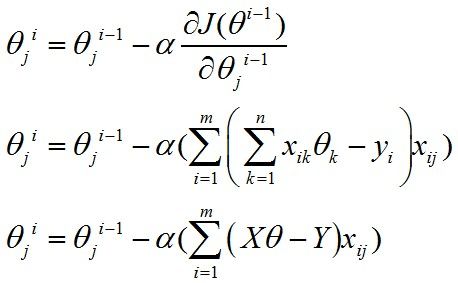
这边会有点棘手,因为j确定时,xij为一个数值(即,样本的第j个分量),Xθ-Y为一个m*1维的列向量(暂时称作“误差向量”)。
括号里面的部分就相当于:
第1个样本第j个分量*误差向量 + 第2个样本第j个分量*误差向量 + ... + 第m个样本第j个分量*误差向量
我们来考察一下式子中各个部分的矩阵形式。
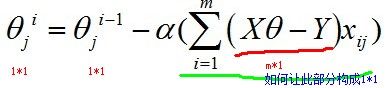
当j固定时,相当于对样本空间做了一个纵向切片,即:

那么此时的xij就是m*1向量,所以为了得到1*1的形式,我们需要拼凑 (1*m)*(m*1)的矩阵运算,因此有:
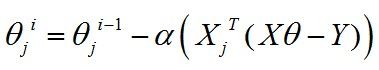
如果把θ向量的每个分量统一考虑,则有:
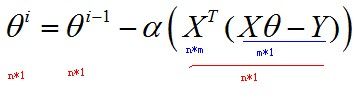
关于θ向量的不断更新的终止条件,一般以误差范围(如95%)或者迭代次数(如5000次)进行设定。
梯度下降的有点是:
不像矩阵解法那么需要空间(因为矩阵解法需要求矩阵的逆)
缺点是:如果遇上非凸函数,可能会陷入局部最优解中。对于这种情况,可以尝试几次随机的初始θ,看最后convergence时,得到的向量是否是相似的。
(3)下图给出了线性、二次和七次拟合的效果图。请说明进行数据拟合时,需要考虑哪些问题。在本例中,你选择哪种拟合函数。(8分)
因为是在网上找的题目,没有看到图片是长什么样。大致可能有如下几种情况。
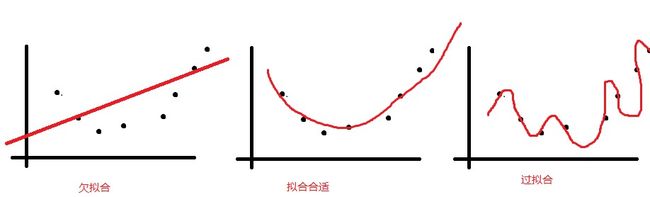
如果是如上三幅图的话,当然是选择中间的模型。
欠拟合的发生一般是因为假设的模型过于简单。而过拟合的原因则是模型过于复杂且训练数据量太少。
对于欠拟合,可以增加模型的复杂性,例如引入更多的特征向量,或者高次方模型。
对于过拟合,可以增加训练的数据,又或者增加一个L2 penalty,用以约束变量的系数以实现降低模型复杂度的目的。
L2 penalty就是:
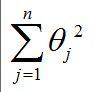 (注意不要把常数项系数也包括进来,这里假设常数项是θ0)
(注意不要把常数项系数也包括进来,这里假设常数项是θ0)
另外常见的penalty还有L1型的:
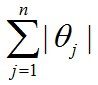 (L1型的主要是做稀疏化,即sparsity)
(L1型的主要是做稀疏化,即sparsity)
两者为什么会有这样作用上的区别可以找一下【统计之都】上的相关文章看一下。我也还没弄懂底层的原因是什么。
(4)给出实验方案(8分)
2013网易实习生招聘 岗位:数据挖掘工程师
一、问答题
a) 欠拟合和过拟合的原因分别有哪些?如何避免?
欠拟合:模型过于简单;过拟合:模型过于复杂,且训练数据太少。
b) 决策树的父节点和子节点的熵的大小?请解释原因。
父节点的熵>子节点的熵
c) 衡量分类算法的准确率,召回率,F1值。


d) 举例序列模式挖掘算法有哪些?以及他们的应用场景。
DTW(动态事件规整算法):语音识别领域,判断两端序列是否是同一个单词。
Holt-Winters(三次指数平滑法):对时间序列进行预测。时间序列的趋势、季节性。
Apriori
Generalized Sequential Pattern(广义序贯模式)
PrefixSpan
二、计算题
1) 给你一组向量a,b
a) 计算二者欧氏距离
(a-b)(a-b)T
即: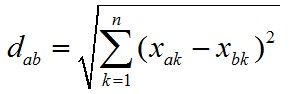
b) 计算二者曼哈顿距离

2) 给你一组向量a,b,c,d
a) 计算a,b的Jaccard相似系数
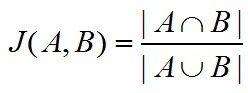
b) 计算c,d的向量空间余弦相似度
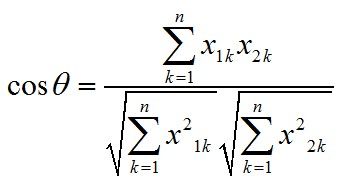
c) 计算c、d的皮尔森相关系数
即线性相关系数。

或者
三、(题目记得不是很清楚)
一个文档-词矩阵,给你一个变换公式tfij’=tfij*log(m/dfi);其中tfij代表单词i在文档f中的频率,m代表文档数,dfi含有单词i的文档频率。
1) 只有一个单词只存在文档中,转换的结果?(具体问题忘记)
2) 有多个单词存在在多个文档中,转换的结果?(具体问题忘记)
3) 公式变换的目的?
四、推导朴素贝叶斯分类P(c|d),文档d(由若干word组成),求该文档属于类别c的概率,
并说明公式中哪些概率可以利用训练集计算得到。
五、给你五张人脸图片。
可以抽取哪些特征?按照列出的特征,写出第一个和最后一个用户的特征向量。
六、考查ID3算法,根据天气分类outlook/temperature/humidity/windy。(给你一张离散型
的图表数据,一般学过ID3的应该都知道)
a) 哪一个属性作为第一个分类属性?
b) 画出二层决策树。
七、购物篮事物(关联规则)
一个表格:事物ID/购买项。
1) 提取出关联规则的最大数量是多少?(包括0支持度的规则)
2) 提取的频繁项集的最大长度(最小支持>0)
3) 找出能提取出4-项集的最大数量表达式
4) 找出一个具有最大支持度的项集(长度为2或更大)
5) 找出一对项a,b,使得{a}->{b}和{b}->{a}有相同置信度。
八、一个发布优惠劵的网站,如何给用户做出合适的推荐?有哪些方法?设计一个合适的系
统(线下数据处理,存放,线上如何查询?)
机器学习方面的面试主要分成三个部分: 1. 算法和理论基础 2. 工程实现能力与编码水平 3. 业务理解和思考深度
1. 理论方面,我推荐最经典的一本书《统计学习方法》,这书可能不是最全的,但是讲得最精髓,薄薄一本,适合面试前突击准备。 我认为一些要点是:统计学习的核心步骤:模型、策略、算法,你应当对logistic、SVM、决策树、KNN及各种聚类方法有深刻的理解。能够随手写出这些算法的核心递归步的伪代码以及他们优化的函数表达式和对偶问题形式。 非统计学习我不太懂,做过复杂网络,但是这个比较深,面试可能很难考到。 数学知识方面,你应当深刻理解矩阵的各种变换,尤其是特征值相关的知识。 算法方面:你应当深刻理解常用的优化方法:梯度下降、牛顿法、各种随机搜索算法(基因、蚁群等等),深刻理解的意思是你要知道梯度下降是用平面来逼近局部,牛顿法是用曲面逼近局部等等。
2. 工程实现能力与编码水平机器学习从工程实现一般来讲都是某种数据结构上的搜索问题。 你应当深刻理解在1中列出的各种算法对应应该采用的数据结构和对应的搜索方法。比如KNN对应的KD树、如何给图结构设计数据结构?如何将算法map-red化等等。 一般来说要么你会写C,而且会用MPI,要么你懂Hadoop,工程上基本都是在这两个平台实现。实在不济你也学个python吧。
3. 非常令人失望地告诉你尽管机器学习主要会考察1和2 但是实际工作中,算法的先进性对真正业务结果的影响,大概不到30%。当然算法必须要足够快,离线算法最好能在4小时内完成,实时算法我没搞过,要求大概更高。 机器学习大多数场景是搜索、广告、垃圾过滤、安全、推荐系统等等。对业务有深刻的理解对你做出来的系统的结果影响超过70%。这里你没做过实际的项目,是完全不可能有任何体会的,我做过一个推荐系统,没有什么算法上的高大上的改进,主要是业务逻辑的创新,直接就提高了很明显的一个CTR(具体数目不太方便透露,总之很明显就是了)。如果你做过实际的项目,一定要主动说出来,主动让面试官知道,这才是最大最大的加分项目。 最后举个例子,阿里内部机器学习挑战赛,无数碾压答主10000倍的大神参赛。最后冠军没有用任何高大上的算法而是基于对数据和业务的深刻理解和极其细致的特征调优利用非常基本的一个算法夺冠。所以啥都不如真正的实操撸几个生产项目啊。