【哈工大李治军】操作系统课程笔记8:内存管理(分段、分区、分页和换入换出)
1、内存使用与分段
(1)重定位
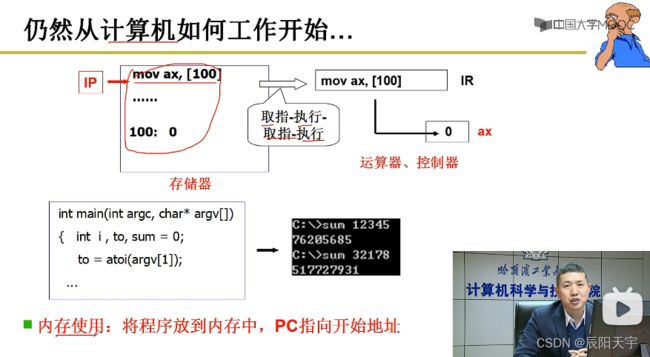

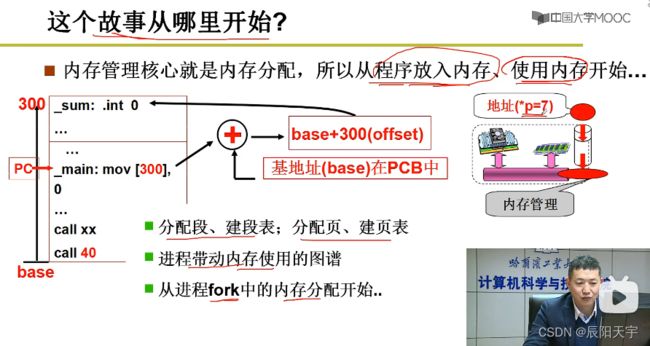
程序从物理地址0地址处开始执行,为了让call 40生效,需要让_main的第一条指令指向物理地址40。但如果所有程序都是放到0地址处开始程序,就会造成冲突。因此,我们为了避免冲突,每次应该从内存中找一段空闲单元,然后将这段程序放进来。
假如从1000地址往后存放这段程序,如果还保持源程序里call 40就不能正确跳到我们需要的位置,因此就需要修改40为1040,这就引出了重定位的概念。
每一段你程序都是从入口函数_entry开始往后,再加上偏移地址,得到这段程序的地址。我们通常把40称为逻辑地址,用来程序位置之间的表示相对关系。
1040称为物理地址,是真实存在的位置。只有程序被存储到真实地址处才可以执行。我们需要通过 重定位 改变程序中的执行地址,然后修改IP指针指向入口执行处,才能执行程序。

什么时候完成重定位呢?
(1)编译时:更适合一次烧入不再变化的系统(例如一些嵌入式系统),如果不是的话,可能会出现虽然在编译时候所选的内存位置为空闲,但在执行过程中可能选取的这段未知会被占用。只有固定好哪段代码一直就会在所规定的区域执行时,才会干扰到别的区域段,可以进行编译时重定位。
- 优点:效率高
- 缺点:只能存放在内存固定位置
(2)载入时:在实际中使用更多的,则是载入时。在载入时,寻找到空闲地址再重定位,更为灵活。
- 优点:相对于来说更慢一些,一旦载入内存,在执行中就不能动了。
- 缺点:灵活性高,
但有的时候来说,我们需要内存里的东西可以变动。
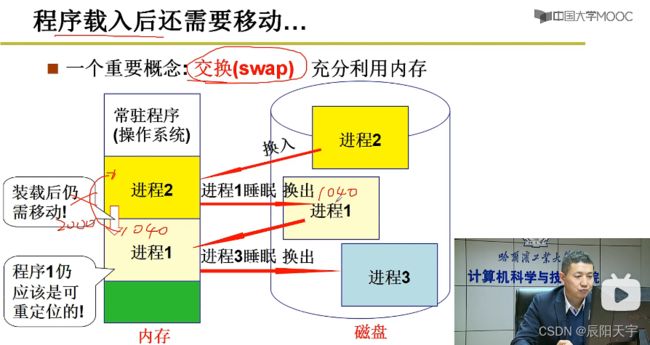
在一段时间内,曾被换入执行过的进程1被换出后,又被换入。但如果两次的位置换入的位置不一样,这时载入时的重定位就不能满足要求。
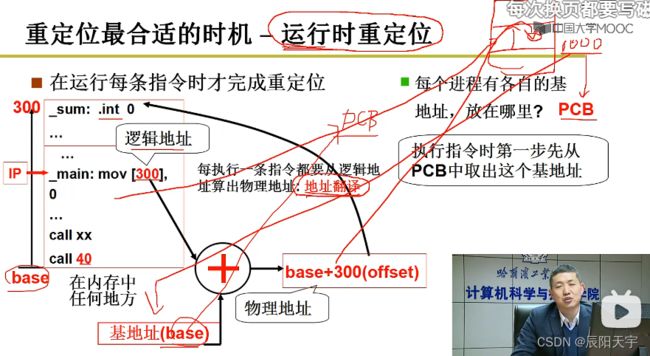
所以,最好的方式应该是运行时进行重定位。执行每一条指令都要从逻辑地址算出物理地址,使用地址翻译:base+offset得到物理地址。
而进程在执行换入换出等过程中base的变化,都放在了PCB里,保证换入换成过程中可正确翻译地址。每次程序执行前,先找到内存中的一段空闲区域,然后将起始地址存入PCB中,再将这个地址作为基地址base来使用,将这段程序存储到所选区域。当在执行指令翻译第一步,先从PCB里取出基地址,然后翻译地址。

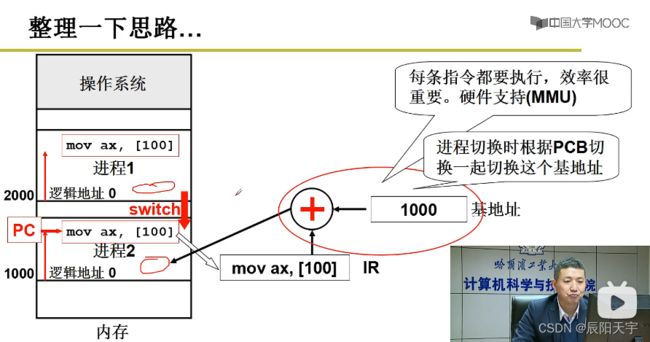
(2)分段
在实际中我们会将整个程序放入到连续的内存中吗?
答:不会

程序员眼中的程序,实际上由若干个部分组成,每个段由各自的特点和用途。因此,用户可独立考虑每个段,进行分而治之。

这样子就会将一个程序,分成各个段,各个段分别放入内存中。如果在执行过程中,内存空间不够时,需要再申请另外一段内存使用。
一旦以段来寻址的话,我们的寻址方法就会发生改变,变为<段号,段内偏移>,使用每个段的基址再加上段内偏移。因此,之前的PCB里只需要放一个段的基址,而现在的PCB里需要放入每个段的基址(CS、DS、SS…),而操作系统(进程0)对应的这个段表就是GDT全局描述符表,而其余进程对应的这个段表就是LDT局部描述符表。

总结:GDT和LDT的作用主要是为了更好的满足 地址翻译 、 程序的换入换出 和 内存资源利用。
2、内存分区与分页

多进程切换的映射表实际上就是LDT
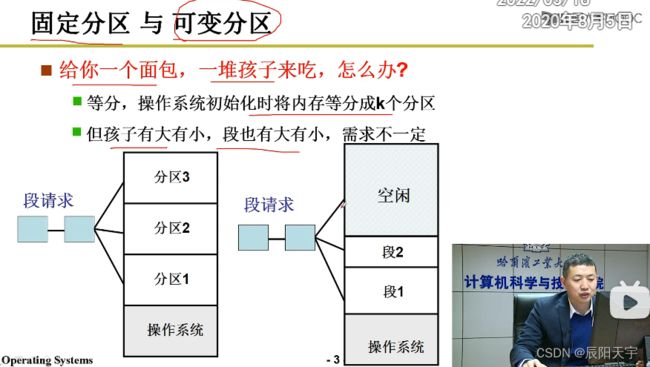
内存分区的方式中有固定分区和可变分区两种,实际中我们用可变分区更多一些。

(1)内存分区
(1)请求分配
通过空闲分区表和已分配分区表来实现请求分配

从空闲分区表中查找可用地址的始址和长度,然后分配地址。
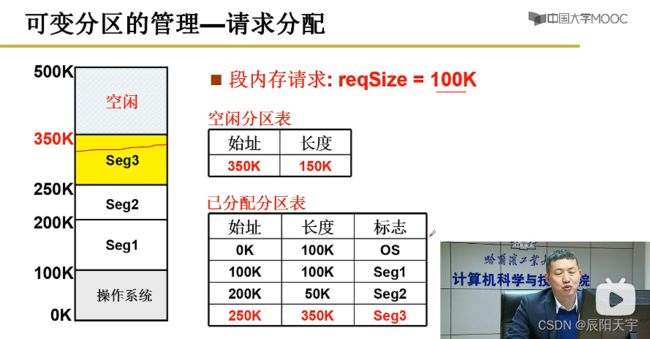
分配完后,更新空闲分区表和已分配分区表。
(2)释放内存
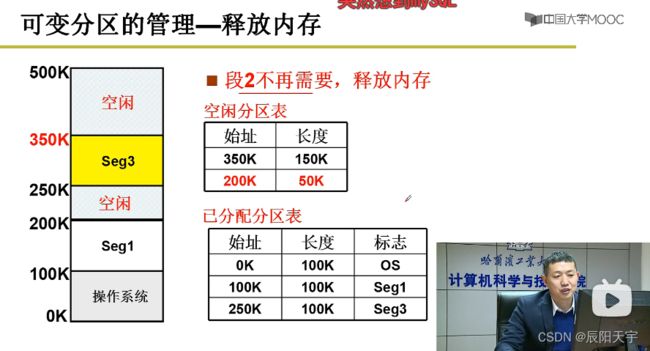
当2段不再使用时,就需要释放内存,更新空闲分区表和已分配分区表。
(3)再次申请
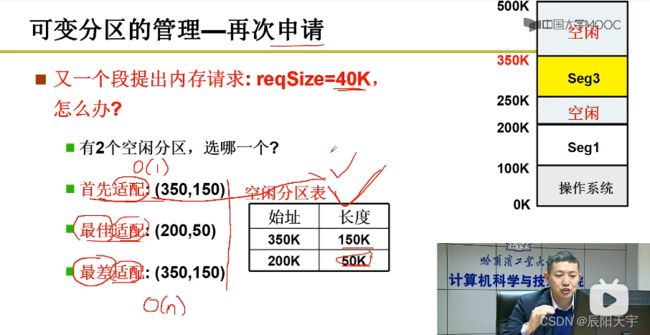
当有一个段提出申请时,空闲分区表中有多个区域可满足申请,这时就需要加入算法来选择最合适的分区策略。
分配方法:
- 首先适配:不考虑长度的大小因素,按表中的顺序分配,是一种随机方式,好处是查表耗时短,时间为 O ( 1 ) O(1) O(1)。
- 最佳适配:分配的分区长度最接近请求长度且满足要求,但容易出现许多“小碎片”,查表时间为 O ( n ) O(n) O(n)。
- 最差适配:每次都把长度最大的分区分配出去,最后易得到长度较为均匀的分区,查表时间为 O ( n ) O(n) O(n)。
所以,只要使用数据结构(空闲分区表和已分配分区表)+ 算法(分区分配策略)就可以完成对内存的分配管理。

由于有时候需要很大的内存块, 若使用最差适配,则大内存块可能被切割,导致内存中没有很大的内存块,因此C不合适。
而最先适配没有考虑内存块的大小特点,有时候会很大有时候会很小,因此A不适合。
而C最佳适配,即使会出现碎片,但有时候仅需要很小的内存,那么碎片也可以被利用起来。因此,C最好。

在实际中,并不适用分区的方式去解决内存分配的问题,而是使用分页。
(2)内存分页

在分区过程中会产生内存碎片,导致虽然空闲区域加起来可能可以满足请求分区大小,可因为是一个个的碎片,导致没有一个连续完整的区域可供分区。
使用了内存紧缩来解决此问题,但消耗时间会较多,而且在内存紧缩的过程中,上层所启用的用户程序都暂时不能使用,呈现“死机”的状态。随着内存的增大,需要耗费的时间会更多。
因分区效率不高,所以引入分页技术。

分页就类似于“面包切成片”,将内存以页为单位进行划分。先分段再分页,将每个段等分成一页一页。在操作系统一初始化的时候(mem_map()每4K为一页),物理内存就分成了一页一页的。
每个段内存请求时,会需要计算这个段需要几页,然后根据mem_map(),系统将内存分配它。使用此方式不需要再内存紧缩,一个段只会最多会浪费一页(4k)。
分页相当于是对分区的更小一级的内存划分,将一个段再划分成一个一个的页,只不过这次的划分使用了固定的长度,好处是便于分配。在划分的过程中,如果划分的单位太大会导致出现冗余浪费过多,划分的过小会导致计算消耗过大。Linux0.11采用的是以4k为一页进行划分。
总结:
我们先对一个程序按非固定大小划分成一个一个的段,便于用户编写程序和便于内存的换入换出,从而提供内存利用率。然后,为了进一步更好的适应物理内存的分配,提高利用率,便将一个段按固定大小再划分成一个一个的页,存储到物理内存当中。操作系统既支持段,又支持页,段页应该合在一起。
从物理内存的角度来说,更喜欢分页,这样子可以浪费少。而从用户的角度来说,更喜欢分段,这样子可以便于编写。
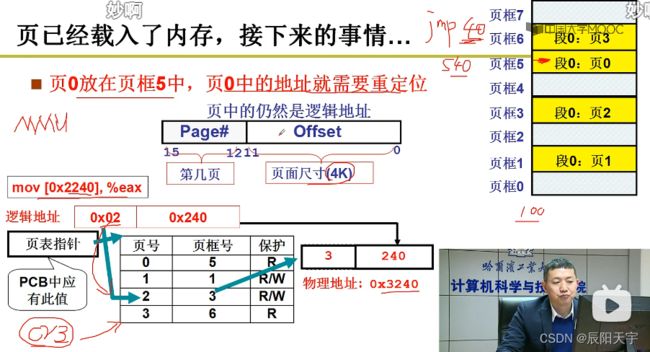
物理内存地址按页框来划分,从页框0开始。段从第0页开始,页框大小=页大小。
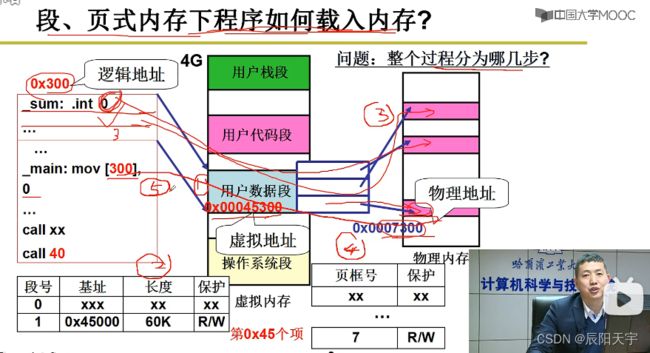
在执行命令语句时,就需要根据逻辑地址、页框和页号,通过CR3页表寄存器来获取物理地址,跳到目标地址处来执行。而为了实现这一地址翻译过程,就需要引入页表这个数据结构并和PCB关联。
(1)获取页框号: 每页长度为4k,就需要逻辑地址0x2240除以4K,也就是右移12位后得到0x0002,那么我们的目标页号就是2,而页内的偏移地址则为0x0240。
(2)计算物理地址: 使用MMU通过页号来找到对应的页框号(物理地址),将这个页框号左移12位,再和0x0240拼接得到物理地址0x3240。
3、多级页表和快表
(1)多级页表


页表项就有4M,而每个进程都有自己的地址空间,也就是每个进程都要保存4M的页表关系。如果进程多的话,就需要很大一笔空间开销。我们就会想,有没有一种方法来减小开销呢?
因为实际中大部分逻辑地址都不会用到(总空间为0到4G),所以看起来并不需要4M的页表。对于不用的页号我们能否不再记录,从页表中去掉,减小内存开销。

我们的第一种想法就是只存放用到的页,但此时的页表中的页号并不连续,如果需要查找页号的话,使用顺序查找时间复杂度太高。同时,每执行一条指令都需要从页表中上往下比较,消耗的时间太多。使用折半查找的话,虽然时间复杂度降低了,但也需要额外的访问页表多次才行。
CPU花费最大的时间其实就是访问内存的时间。所以,还是必须要存储连续页表才行,否则性能下降太大。使用连续地址,可以通过只访问一次页表就可以获取页框号。但这样子做的话,又回到最初了,还是会存放大量的页表很大,占用大量的内存空间。
怎么样既保持连续,又可以使页表占用内存少呢?
这样子就引入了多级页表机制。

使用页目录+页表来表示多级页表。内存中只存放含有对应有页目录表一级的表项,没有使用的不在内存中存放。而对于页表一级需要按顺序全部存放,来便于映射查找。
每一个页的大小为4K( 2 12 2^{12} 212),页表大小为1K( 2 10 2^{10} 210),一个页目录号对应一个页表,那么一个页目录项便对应一个4M大小的页。页目录表最大的大小为1K( 2 10 2^{10} 210),所以整个页目录表可表示4G大小的内存。其中,页目录表的大小可变,页表和页的大小固定。
多级页表实际上就是“页的合”,我们之前为了提高内存利用率我们将段切分为页,而为了减少页表所占的空间大小并使其快速访问页表,又将页合为页表。多级页表既保持了内存地址空间的连续可以快速查找到页框号,又可以节省存储空间,来减少页表项的存储。
但多级页表在空间上提高了效率,既保持了连续,又缩小了存储空间。但在时间上,由于多了一级的查询,就会多访问内存一次,时间开销又加大了,但相对于折半查找来说,速度已经是大幅度提升了。
(2)快表
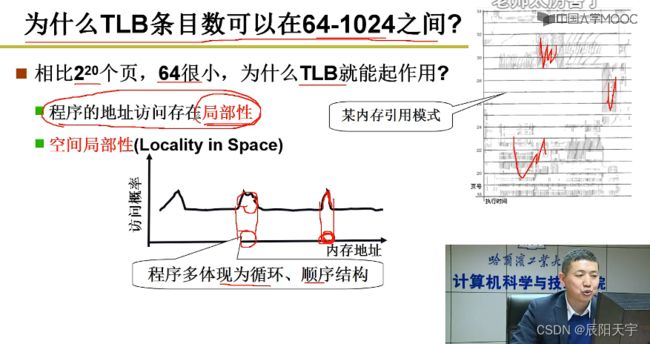
由于每多增加一级,就会多访问一次内存,当为64G的时候,可能会增加到五六级的页表,因此为了减少内存访问次数,便引入了快表。

根据程序局部性原理,引入TLB快表,每次访问格局地址获取页表时,先去快表中查找,根据页号再查找页框号,通过页框号和偏移量拼接出物理地址。如果没有在TLB中找到(未命中),则从多级页表中查找。
最近经常使用的页表存储到TLB中,首先从页表中找,找不到再从多级页表中找。多级页表中由于在页表项内保持连续存储,所以也可以相对快速的查找到页框号并且保持相对较少的空间使用。但我们在大部分情况下,都可以在快表中找到我们想要的页框号。这样子,既保持查快表时非常快,也保持查多级页表时不太慢。

我们通常会把TLB设置在 [64, 1024]
4、段页结合的实际内存管理


从虚拟内存空间中分割区域得到各个段,再将虚拟内存的空间中的段映射到实际物理内存当中的页。
通过引入虚拟内存实现了既支持段,又支持页的效果。
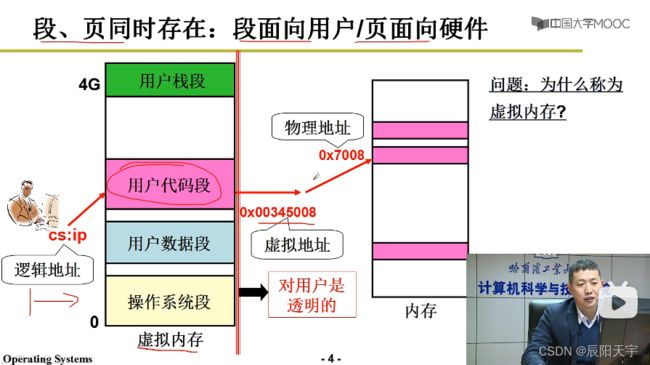
用户在编程时,只会感知到段的存在。通过在虚拟地址上划分出段,通过一种映射机制,将一个段映射到实际物理地址上的一个个页,而这种映射过程对用户来说是透明看不见的。
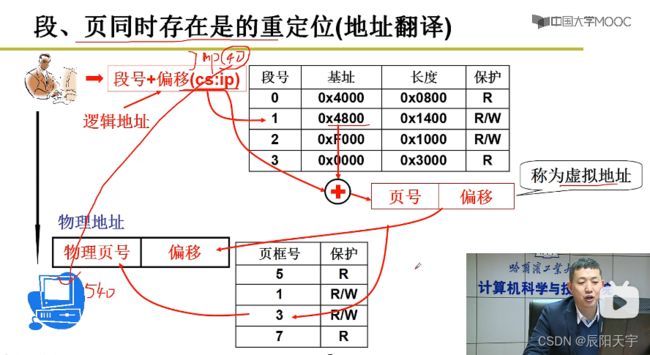
段号+偏移经过重定位(地址翻译)后得到虚拟地址,然后根据虚拟地址得到虚拟页表中的页号和页内偏移,然后根据虚拟页和物理页的映射关系找到实际的物理页。
首先,要将用户的段和虚拟内存的区域关联起来,将虚拟内存区域分割出一段给用户的段来使用,分割方式可使用分区算法来实现(逻辑上实现,实际中使用段表来表示这个逻辑结果)。然后,再将这片区域分割成一段段的页放到物理内存中的页框里,将页框和虚拟内存中的段关联起来(建立页表来记录,然后就可以用磁盘度写实现真正的存储)。
使用段表来记录段和虚拟内存区域是如何对应的,经过地址翻译后,得到虚拟页号+页内偏移,然后再使用页表来记录虚拟页表和物理内存中的页框是如何对应的。
(1)copy_men建立段表

从copy_men()中设置段表,nr*4000000对虚拟内存进行分割(0号进程是0-64M,1号进程是64-128M…),将分割后的内存基址放置对应的段,ldt[1]设置代码段,ldt[2]设置数据段。

每个进程占64M虚拟地址空间,互不重叠。这样子的好处是可以不需要再切换页,实现了一个简化了分页切换机制。
(2)copy_page_tables建立页表

因为fork()出的子进程会复制父进程的信息,实际中子进程会共用父进程的页,从而不需要再分配内存给子进程,但需要对子进程建立页表,因为父子进程指向的页式相同的,所以页表只需要拷贝父进程的页表即可。
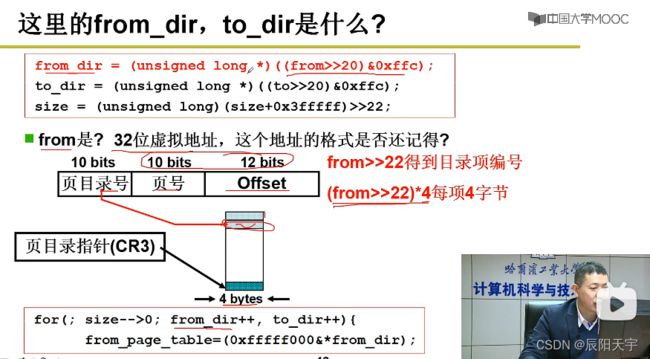
from_dir是32位虚拟地址,首先将这个地址右移20位(实际上是(from>>2)*4得到的效果(移除页目录号再乘上4bytes页的大小)),然后和0xffc取交集,可得到页目录号,而to_dir代表子进程的页目录号。
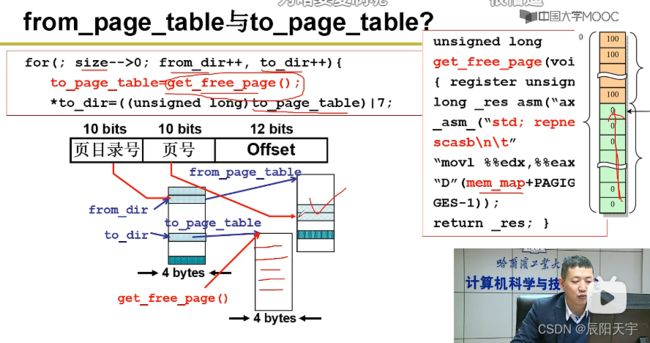
使用get_free_page()分配实际的页框作为子进程的页表给to_dir,建立映射关系。而get_free_page()的实现方式,实际上就是从mem_map中找到空闲的0。
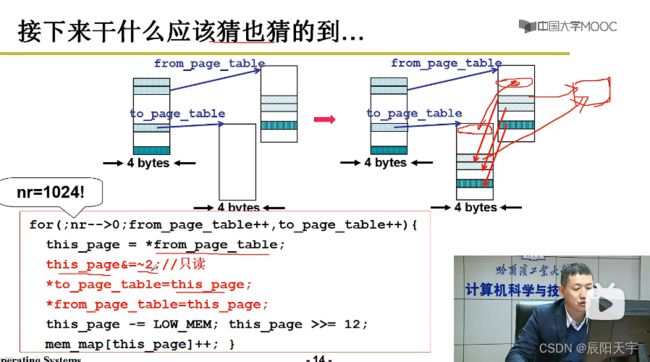
将from_page_table里边的内容拷贝到to_page_table当中。使用this_page指向from_page_table,然后让to_page_table指向this_page。
然后,再让父子进程指向同一页。让from_page_table指向this_page(子进程也指向着this_page)。
因为这一页已经被共享了,所以mem_map应该累加。

此时已为fork()后的子进程创建了段表和页表,可以时间将程序放入实际的物理内存当中。
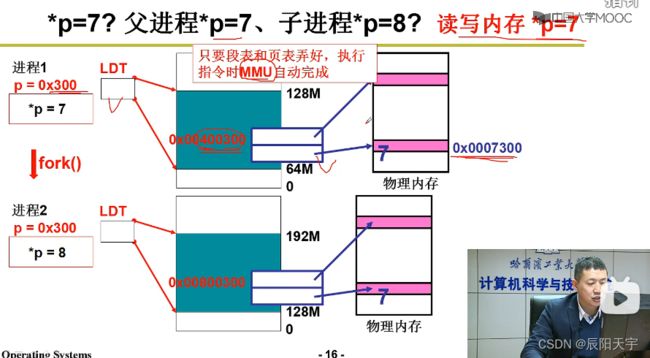
操作系统做出段表和页表后,在执行指令时,MMU(内存管理单元)会自动实现从逻辑地址算出虚拟地址,然后再从虚拟地址算出物理地址,然后将算出的物理地址(0x0007300)打到物理总线上,再将7存储在给0x0007300的位置上,从而真正的在物理内存上实现了*p=7。
当子进程执行*p=8时,查询段表和页表方式与父进程相同,但此时子进程对于0x0007300仅有读权限没有写权限,所以系统就会再重新分配一个内存页(0x0008300),构建页表和新页框的映射关系,从而实现了地址的分离。然后,将会把这个新地址传到地址总线上,再将8存储到这个地址上,从而实现了子进程中的*p=8。
5、内存换入:请求调页

操作系统的换入和换出核心上是完成段到页的映射。

虚拟内存为4G,实际物理内存为1G。我们的目标是如何让用户在使用实际1G物理内存的过程中,能体验到使用4G内存的感觉。
最初的想法是使用哪一段(比如0-1G、3-4G)就把这段虚拟内存的内容映射到物理内存上,从磁盘上读数据将这段内容换入到物理内存中,数据有更新且要持久化存储的时候,就把数据再换出到磁盘上进行存储。
用现实生活中物品店来举例。 虚拟内存相当于是购买清单(客户的购买清单),在虚拟地址上规划好想要用到的数据;物理内存相当于是货架(放在货架上售卖的物品),放置真正在物理内存上被用户所使用的数据;磁盘相当于是仓库(存储全部商品),存储全部的数据。
当用户(客户)想要使用某一数据(购买某一商品)时,会根据虚拟内存上的段表(购买清单)来查询虚拟页表,查看物理内存上(货架上)是否有所需要用到的数据(想要购买的商品),如果没有则系统(商家)从磁盘上(仓库中)调入到物理内存上(货架上)。
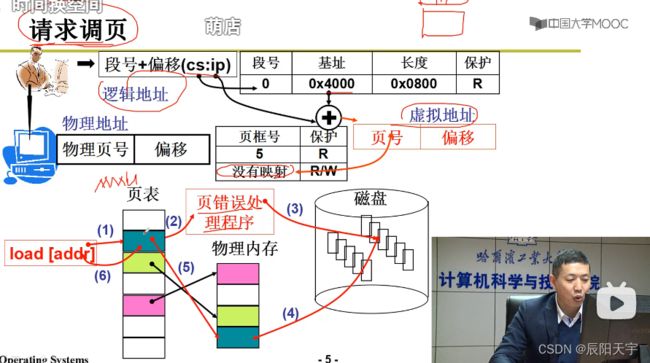
首先,根据逻辑地址的段号+偏移查询段表中的信息,找到虚拟地址上对应的虚拟页号,然后根据页号+偏移使用MMU通过虚拟页表来查找页框,如果不存在(缺页)就需要先发出中断,再执行中断处理程序进行请求调页,从磁盘上找出内容后,在内存中找到一段空闲页调入,最后完成虚拟页表和页框的映射关系,便完成了缺页中断处理。然后,再继续执行刚才发生中断没有执行下去的执行命令,即读取目标页。

(1)14号中断处理
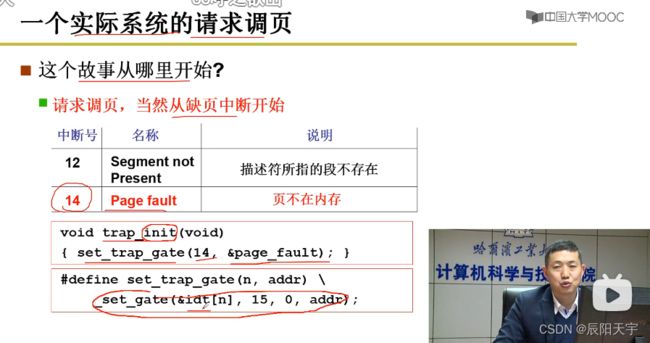
处理缺页中断的终端号是14。

cr2寄存器存放页错误线性地址,存放到段中再压入栈中。
(2)do_no_page请求调页
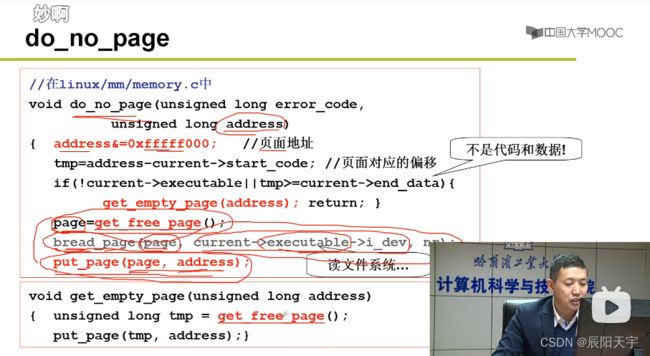
正确完成后,调用do_no_page()请求调页。
(1)首先使用address &= 0xfffff000 得到虚拟页号,使用tmp = address - current->start_code 得到页面对应的偏移
(2)再使用page=get_free_page() 得到空闲页。
(3)然后,使用bread_page()(block read)从磁盘上把数据(current->executable->i_dev当前进程对应的可执行文件)读到空闲页上。
(4)最后,使用put_page(page,address)建立物理页和虚拟地址的映射关系。
(3)put_page建立虚拟页表和物理页的映射关系
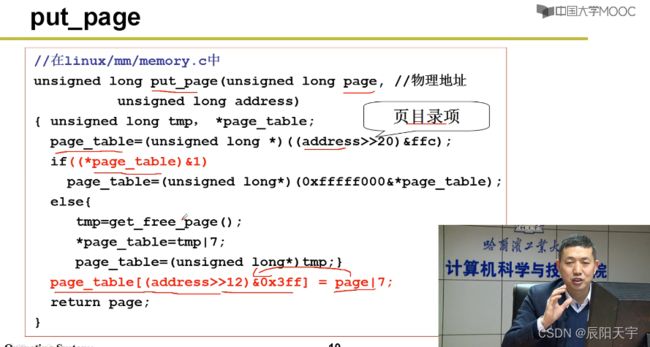
使用put_page建立虚拟页到物理页的映射就是修改页表。
(1)根据((address>>20)&ffc)找到页目录项。
(2)根据然后再找到页表项(address>>12)&0x3ff,完成物理页到虚拟页的映射关系page_table[(address>>12)&0x3ff] = page|7。
6、内存换出

因内存有限,就需要有选择性的换出页面到磁盘上,腾出位置。而换出的方法有FIFO先进先出、MIN最最优置换算法和LRU最近最少使用。
对于一个页面置换算法的评价准则是 缺页次数
(1)FIFO先进先出算法

先来先服务是最简单的一种实现方式,将其看做一个队列,最先被使用的最先被换出。但这种方式虽然简单,但并不太合理,可能会把未来会经常使用的页面给换出。
(2)MIN最优置换
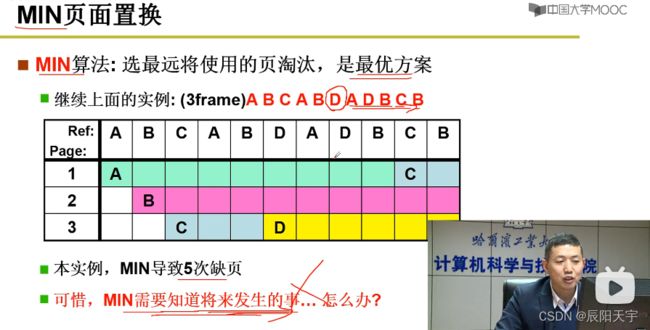
MIN算法:每次选最远将使用的页淘汰,是最优方案。但这只是一种理想方案,想要真正实现它太过困难。不过,它也具有很好的研究意义,以这个最优方案为标准找到一个折中可实现的方案。
(3)LRU页面置换
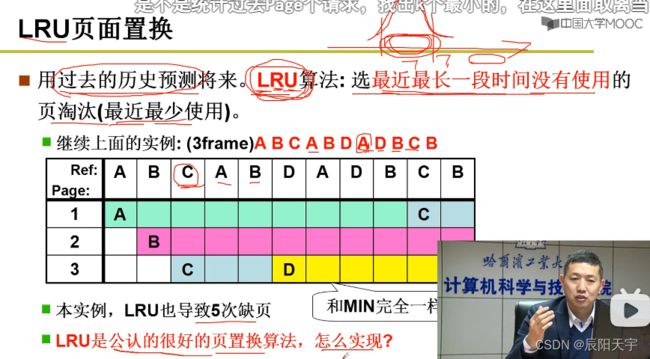
根据页面序列的特性,它会满足程序局部性原理,即最近所使用的页面在未来的一段时间内会有较大概率被使用。那么,我们其实就近似的用过去预测了未来,可使用简化版的MIN,即LRU最近最久未使用,将最近最长一段时间没有使用的页面淘汰。
LRU在实际中用的少,因为实现起来代价太大。
(1)时间戳方法

使用时间戳来实现LRU,每次换入一个页就给该对应页的位置上打上时间戳,时间戳从1开始每次换入一次加一,每次选择时间戳最小的页面淘汰。
因为每执行一条指令时,都会通过MMU查到对应地址处的页表,然后需要修改维护时间戳表里的时间戳信息。由于每次执行指令都需要修改时间戳表,这样子实现起来代价太大,不可行。
(2)页码栈

使用一个栈来实现,依次入栈,当再次使用栈中已有元素时,把该元素浮上来,栈顶始终为最近所使用的元素。淘汰时,总是淘汰栈底元素。
但是每次执行一条指令访问地址时,都需要修改栈指针(需修改10次左右栈指针),实现代价仍然太大。
(4)LRU近似实现:Clock算法
(1)只有选择淘汰页指针

不去做时间戳,而是将时间计数变为0和1。用0和1来近似LRU最近最少使用算法。每个页加一个引用位(reference bit),每访问一次硬件就主动将该设置位为1。把页面的这个位在逻辑上组织成队列形式,选择淘汰页时,会依次扫描该位,是1时清0,并继续扫描;是0时淘汰该页。
Clock算法虽然实现起来效率很高,但是对LRU的近似不好。因程序局部性原理的存在,一般情况下缺页可能会很少。在Clock算法里,就很少从1置成0,那么就有可能出现里面的R全是1,大纲一旦里面缺页的话,就会挨个扫描一遍把1变成0后,再把第一个由1变成0的页换出。那么这样子反而退化成为了FIFO,一旦退化为了FIFO那么就没有体现LRU的特性了。
(2)选择淘汰页指针 + 扫描指针

究其原因,是这里的标志位记录了太长的历史信息,一旦出现全1的情况(可能会经常出现),那么就会退化为FIFO。为了解决这个问题,就要去消除一些历史信息,使用一个扫描指针定时的清除R位,将1设置为0。那么当进行扫描时,就会多出一些0,从而可以近似LRU最近最少使用的特性。
注: 扫描指针的速度要快,选择淘汰页指针的速度要慢。

给进程分配页框数量也要适当,分配的多那么请求调页带来的内存高效利用效果就会减少。分配的少,就会出现“颠簸”现象。
从图中可以看到,当多道程序的数量到达一定程度时,CPU利用率会急剧下降。这是因为当进程太多时,给每个进程分配的页就会变少,从而导致缺页率增加,缺页会导致调页启动磁盘,磁盘一被启动,CPU就会一直等待,导致CPU的利用率降低。这一现象称为“颠簸”。
7、总结
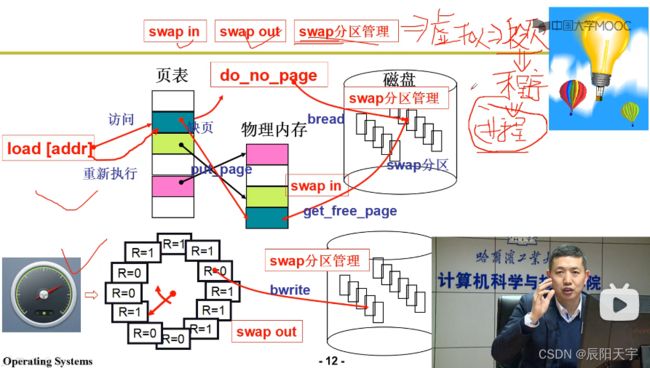
访问虚拟地址映射至物理内存时,发现缺页就会进行缺页中断,便从磁盘上读一个页进来放到物理内存中。当发现可分配页面不够时,就会使用改良后的Clock算法选择一个页面换出一个页的内容(swap out),写到磁盘上。然后,再将待读页面读到选择的页上(swap in)。所以,一个swap 分区就是既有换入swap in,又有换出swap out。
结合我们上面所学的,我们选择得到的图像就是一张以进程带动的多进程推进的,同时内存开始有效工作的一张图。