《机器学习实战》—— 朴素贝叶斯
文章目录
- 一、朴素贝叶斯
- 二、基于贝叶斯决策理论的分类方法
- 三、数学知识准备
-
- 3.1 条件概率
- 3.2 全概率公式
- 3.3 贝叶斯推断
- 四、使用条件概率来分类
- 五、文本分类
-
- 5.1 从文本中构建词向量
- 5.2 从词向量计算概率
- 5.3 根据现实情况修改分类器
- 六、使用朴素贝叶斯过滤垃圾邮件
-
- 6.1 切分文本
- 6.1 使用朴素贝叶斯进行交叉验证
- 七、总结
一、朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于概率理论的分类算法,以贝叶斯理论为理论基础,通过计算样本归属于不同类别的概率来进行分类,是一种经典的分类算法。朴素贝叶斯是贝叶斯分类器里的一种方法,之所以称它朴素,原因在于它采用了特征条件全部独立的假设。
二、基于贝叶斯决策理论的分类方法
朴素贝叶斯
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。
假设现在有一个数据集,它由两类数据组成(红色和蓝色),数据分布如下图所示。

现在用 p 1 ( x , y ) p1(x,y) p1(x,y)表示数据点 ( x , y ) (x,y) (x,y)属于类别1(图中圆点表示的类别)的概率,用 p 2 ( x , y ) p2(x,y) p2(x,y)表示数据点 ( x , y ) (x,y) (x,y)属于类别2(图中三角形表示的类别)的概率,那么对于一个新的数据的 ( x , y ) (x,y) (x,y),可以用下面的规则来判断它的类别:
- 如果 p 1 ( x , y ) > p 2 ( x , y ) p1(x,y) > p2(x,y) p1(x,y)>p2(x,y),那么类别为1
- 如果 p 1 ( x , y ) < p 2 ( x , y ) p1(x,y) < p2(x,y) p1(x,y)<p2(x,y),那么类别为2
也就是说,会 选择高概率所对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
三、数学知识准备
3.1 条件概率
为了能够计算 p 1 p1 p1与 p 2 p2 p2,有必要讨论一下条件概率。
举个例子来说明,假设现在有一个装了7块石头的罐子,其中3块是灰色的,4块是黑色的。如果从罐子中随机取出一块石头,那么是灰色石头的可能性是多少?
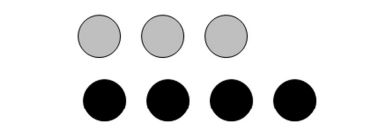
由于取石头有7种可能,其中3种为灰色,所以取出灰色石头的概率为3/7。那么取到黑色石头的概率又是多少呢?很显然,是4/7。我们使用P(gray)来表示取到灰色石头的概率,其概率值可以通过灰色石头数目除以总的石头数目来得到。
如果这7块石头如下图所示放在两个桶中,那么上述概率应该如何计算?
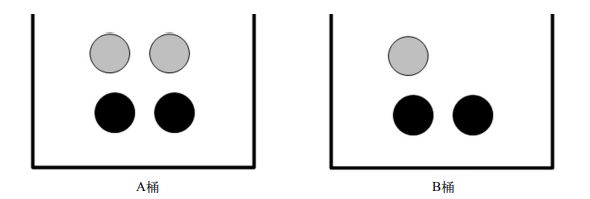
要计算P(gray)或者P(black),事先得知道石头所在桶的信息会不会改变结果?计算从B桶中取到灰色石头的概率,这就是所谓的 条件概率(conditionalprobability)。假定计算的是从B桶取到灰色石头的概率,这个概率可以记作P(gray|bucketB),称之为“在已知石头出自B桶的条件下,取出灰色石头的概率”。不难得到,P(gray|bucketA)值为2/4,P(gray|bucketB) 的值为1/3。
条件概率的计算公式如下所示:
P ( g r a y ∣ b u c k e t B ) = P ( g r a y a n d b u c k e t B ) / P ( b u c k e t B ) P(gray|bucket B) = P(gray and bucket B) / P(bucket B) P(gray∣bucketB)=P(grayandbucketB)/P(bucketB)
- 首先,用B桶中灰色石头的个数除以两个桶中总的石头数,得到P(gray and bucketB) = 1/7。
- 其次,由于B桶中有3块石头,而总石头数为7,于是P(bucketB)就等于3/7。
- 最后,有P(gray|bucketB) = P(gray and bucketB)/P(bucketB) =(1/7) / (3/7) = 1/3。
可以看出,上面的公式是合理的。
这个公式虽然对于这个简单例子来说有点复杂,但当存在更多特征时是非常有效的。用代数方法计算条件概率时,该公式也很有用。
另一种有效计算条件概率的方法称为 贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知P(x|c),要求P(c|x),那么可以使用下面的计算方法:
p ( c ∣ x ) = p ( x ∣ c ) p ( c ) p ( x ) p(c|x) = \frac{p(x|c)p(c)}{p(x)} p(c∣x)=p(x)p(x∣c)p(c)
3.2 全概率公式
除了条件概率以外,在计算 p 1 p1 p1和 p 2 p2 p2的时候,还要用到全概率公式,因此,这里继续讨论一下全概率公式。
设事件 A 1 , A 2 , … , A n A_1,A_2,\ldots,A_n A1,A2,…,An两两互斥,且 p ( A i ) > 0 p(A_i) > 0 p(Ai)>0, 1 ≤ i ≤ n 1 \leq i \leq n 1≤i≤n,又事件B满足:
B = ∪ i = 1 n B A i B = \cup_{i=1}^n BA_i B=∪i=1nBAi
根据条件概率公式可得全概率公式为:
P ( B ) = ∑ i = 1 n P ( A i ) P ( B ∣ A I ) P(B) = \sum_{i=1}^n P(A_i)P(B|A_I) P(B)=i=1∑nP(Ai)P(B∣AI)
全概率的思想是将事件B分解成几个小事件,通过求小事件的概率,然后相加从而求得事件B的概率,而将事件B进行分割的时候,不是直接对B进行分割,而是先找到样本空间 Ω \Omega Ω的一组划分 A 1 , A 2 , … , A n A_1,A_2,\ldots,A_n A1,A2,…,An,这样事件B就被事件 B A 1 , B A 2 , … , B A n BA_1,BA_2,\dots,BAn BA1,BA2,…,BAn分解成了n个部分,即 B = B A 1 + B A 2 + ⋯ + B A n B=BA_1+BA_2+\dots+BA_n B=BA1+BA2+⋯+BAn, 每个事件 A i A_i Ai发生都可能导致B发生的相应概率是 P ( B ∣ A i ) P(B|A_i) P(B∣Ai)。
其实全概率就是 表示达到某个目的的多种方式各自概率的和。
3.3 贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B) = P(A) \frac{P(B|A)}{P(B)} P(A∣B)=P(A)P(B)P(B∣A)
- P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
- P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估。
- P ( B ∣ A ) P ( B ) \frac{P(B|A)}{P(B)} P(B)P(B∣A)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:后验概率 = 先验概率 x 调整因子
四、使用条件概率来分类
贝叶斯决策理论要求计算两个概率 p 1 ( x , y ) p1(x,y) p1(x,y)和 p 2 ( x , y ) p2(x,y) p2(x,y):
- 如果 p 1 ( x , y ) > p 2 ( x , y ) p1(x,y) > p2(x,y) p1(x,y)>p2(x,y),那么类别为1
- 如果 p 1 ( x , y ) < p 2 ( x , y ) p1(x,y) < p2(x,y) p1(x,y)<p2(x,y),那么类别为2
但这两个准则并不是贝叶斯决策理论的所有内容。使用 p 1 ( x , y ) p1(x,y) p1(x,y)和 p 2 ( x , y ) p2(x,y) p2(x,y)只是为了尽可能简化描述,而真正需要计算和比较的是 p ( c 1 ∣ x , y ) p(c_1|x,y) p(c1∣x,y)和 p ( c 2 ∣ x , y ) p(c_2|x,y) p(c2∣x,y)。这些符号所代表的具体意义是:给定某个由x、y表示的数据点,那么该数据点来自类别 c 1 c_1 c1的概率是多少?数据点来自类别 c 2 c_2 c2的概率又是多少?注意这些概率与刚才给出的概率 p ( x , y ∣ c 1 ) p(x,y|c_1) p(x,y∣c1)并不一样,不过可以使用贝叶斯准则来交换概率中条件与结果。具体地,应用贝叶斯准则得到:
p ( c i ∣ x , y ) = p ( x , y ∣ c i ) p ( c i ) p ( x , y ) p(c_i|x,y) = \frac{p(x,y|c_i)p(c_i)}{p(x,y)} p(ci∣x,y)=p(x,y)p(x,y∣ci)p(ci)
使用这些定义,可以定义贝叶斯分类准则为:
- 如果 P ( c 1 ∣ x , y ) > P ( c 2 ∣ x , y ) P(c_1|x,y) > P(c_2|x,y) P(c1∣x,y)>P(c2∣x,y),那么类别为 c 1 c_1 c1
- 如果 P ( c 1 ∣ x , y ) < P ( c 2 ∣ x , y ) P(c_1|x,y) < P(c_2|x,y) P(c1∣x,y)<P(c2∣x,y),那么类别为 c 2 c_2 c2
使用贝叶斯准则,可以通过已知的三个概率值来计算未知的概率值。
五、文本分类
要从文本中获取特征,需要先拆分文本。这里的特征是来自文本的词条(token),一个词条是字符的任意组合。可以把词条想象为单词,也可以使用非单词词条,如URL、IP地址或者任意其他字符串。然后将每一个文本片段表示为一个词条向量,其中值为1表示词条出现在文档中,0表示词条未出现。
以在线社区的留言板为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标识为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类别:侮辱类和非侮辱类,使用1和0分别表示。
5.1 从文本中构建词向量
把文本看成 单词向量 或者 词条向量,也就是说将句子转换为向量。考虑出现在所有文档中的所有单词,再决定将哪些词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。
'''
Parameters:
无
Returns:
postingList - 实验样本切分的词条
classVec - 类别标签向量
'''
# 函数说明:创建实验样本
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1]#类别标签向量,1代表侮辱性词汇,0代表不是
return postingList,classVec
'''
Parameters:
vocabList - createVocabList返回的列表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词集模型
'''
# 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返回文档向量
'''
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
'''
# 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
if __name__ == '__main__':
postingList, classVec = loadDataSet()
print('postingList:\n',postingList)
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
print('trainMat:\n', trainMat)
>>>
postingList:
[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
myVocabList:
['buying', 'stop', 'help', 'flea', 'licks', 'ate', 'how', 'my', 'please', 'problems', 'I', 'has', 'him', 'stupid', 'not', 'posting', 'maybe', 'so', 'quit', 'take', 'is', 'to', 'steak', 'love', 'dalmation', 'park', 'cute', 'food', 'dog', 'garbage', 'mr', 'worthless']
trainMat:
[[0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1], [0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1]]
从运行结果可以看出:
- postingList 是原始的 词条列表;
- myVocabList 是 词汇表,是所有单词出现的集合,没有重复的元素;
- trainMat 是所有的词条向量组成的列表,它里面存放的是根据 myVocabList 向量化的 词条向量。
词汇表是用来将词条向量化的,一个单词在词汇表中出现过一次,那么就在相应位置记作1,如果没有出现就在相应位置记作0。
5.2 从词向量计算概率
现在已经知道一个词是否出现在一篇文档中,也知道该文档所属的类别。将重写贝叶斯准则,将之前的x、y 替换为w。粗体w表示这是一个向量,即它由多个数值组成。在这个例子中,数值个数与词汇表中的词个数相同。
p ( c i ∣ w ) = p ( w ∣ c i ) p ( c i ) p ( w ) p(c_i|w) = \frac{p(w|c_i)p(c_i)}{p(w)} p(ci∣w)=p(w)p(w∣ci)p(ci)
使用上述公式,对每个类计算该值,然后比较这两个概率值的大小。如何计算呢?首先可以通过类别 i i i(侮辱性留言或非侮辱性留言)中文档数除以总的文档数来计算概率 p ( c i ) p(c_i) p(ci)。接下来计算 p ( w ∣ c i ) p(w|c_i) p(w∣ci)这里就要用到 朴素贝叶斯假设。如果将w展开为一个个独立特征,那么就可以将上述概率写作 p ( w 0 , w 1 , w 2 , … , w N ∣ c i ) p(w_0,w_1,w_2,\dots,w_N|c_i) p(w0,w1,w2,…,wN∣ci)。这里假设所有词都互相独立,该假设也称作条件独立性假设,它意味着可以使用 p ( w 0 ∣ c i ) p ( w 1 ∣ c i ) p ( w 2 ∣ c i ) … p ( w N ∣ c i ) p(w_0|c_i)p(w_1|c_i)p(w_2|c_i)\dots p(w_N|c_i) p(w0∣ci)p(w1∣ci)p(w2∣ci)…p(wN∣ci)来计算上述概率,这就极大地简化了计算的过程。
'''
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
'''
# 函数说明:朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)#创建numpy.zeros数组,词条出现数初始化为0
p0Denom = 0.0; p1Denom = 0.0 #分母初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive#返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
if __name__ == '__main__':
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
print('myVocabList:\n', myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)
>>>
myVocabList:
['stupid', 'worthless', 'maybe', 'dalmation', 'so', 'steak', 'flea', 'ate', 'buying', 'not', 'how', 'food', 'cute', 'help', 'I', 'has', 'is', 'mr', 'love', 'please', 'problems', 'take', 'garbage', 'my', 'quit', 'dog', 'him', 'to', 'stop', 'licks', 'posting', 'park']
p0V:
[0. 0. 0. 0.04166667 0.04166667 0.04166667
0.04166667 0.04166667 0. 0. 0.04166667 0.
0.04166667 0.04166667 0.04166667 0.04166667 0.04166667 0.04166667
0.04166667 0.04166667 0.04166667 0. 0. 0.125
0. 0.04166667 0.08333333 0.04166667 0.04166667 0.04166667
0. 0. ]
p1V:
[0.15789474 0.10526316 0.05263158 0. 0. 0.
0. 0. 0.05263158 0.05263158 0. 0.05263158
0. 0. 0. 0. 0. 0.
0. 0. 0. 0.05263158 0.05263158 0.
0.05263158 0.10526316 0.05263158 0.05263158 0.05263158 0.
0.05263158 0.05263158]
classVec:
[0, 1, 0, 1, 0, 1]
pAb:
0.5
运行结果如下,p0V存放的是属于类别0的单词的概率,也就是非侮辱类词汇的概率。比如p0V的正数第5个概率,就是love这个单词属于非侮辱类的概率为0.04166667,换算成百分比,也就是4.17%。同理,p1V的正数第5个概率,就是love这个单词属于侮辱类的概率为0。简单的单词love,大家都知道是属于非侮辱类的,这么看,分类还是比较准确的。pAb是所有侮辱类的样本占所有样本的概率,从classVec中可以看出,一用有3个侮辱类,3个非侮辱类。所以侮辱类的概率是0.5。
因此,p0V和p1V存放的就是myVocabList中单词的条件概率,而pAb就是先验概率。
5.3 根据现实情况修改分类器
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算:
p ( w 0 ∣ 1 ) p ( w 1 ∣ 1 ) p ( w 2 ∣ 1 ) p(w_0|1)p(w_1|1)p(w_2|1) p(w0∣1)p(w1∣1)p(w2∣1)
如果其中一个概率值为0,那么最后的乘积也为0。为降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做 拉普拉斯平滑(Laplace Smoothing) 又被称为 加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。
除了这个问题之外,另一个遇到的问题是下溢出, 这是由于太多很小的数相乘造成的。当计算乘积:
p ( w 0 ∣ c i ) p ( w 1 ∣ c i ) p ( w 2 ∣ c i ) … p ( w N ∣ c i ) p(w_0|c_i)p(w_1|c_i)p(w_2|c_i)\dots p(w_N|c_i) p(w0∣ci)p(w1∣ci)p(w2∣ci)…p(wN∣ci)
由于大部分因子都非常小,所以程序会下溢出或者得到不正确的答案。一种解决办法是对乘积取 自然对数。在代数中有 l n ( a ∗ b ) = l n ( a ) + l n ( b ) ln(a * b) = ln(a) + ln(b) ln(a∗b)=ln(a)+ln(b),于是通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用 自然对数 进行处理不会有任何损失。
下图给出函数 f ( x ) f(x) f(x)与 l n ( f ( x ) ) ln(f(x)) ln(f(x))的曲线:

检查这两条曲线,就会发现它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
'''
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
'''
# 函数说明:朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords)#创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1:#统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom) #取对数,防止下溢出
p0Vect = np.log(p0Num/p0Denom)
#返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
return p0Vect,p1Vect,pAbusive
if __name__ == '__main__':
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
print('myVocabList:\n', myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)
>>>
myVocabList:
['is', 'has', 'love', 'how', 'garbage', 'stop', 'take', 'maybe', 'flea', 'park', 'my', 'so', 'not', 'quit', 'posting', 'buying', 'stupid', 'dalmation', 'please', 'ate', 'steak', 'worthless', 'food', 'cute', 'I', 'dog', 'licks', 'mr', 'help', 'to', 'him', 'problems']
p0V:
[-2.56494936 -2.56494936 -2.56494936 -2.56494936 -3.25809654 -2.56494936
-3.25809654 -3.25809654 -2.56494936 -3.25809654 -1.87180218 -2.56494936
-3.25809654 -3.25809654 -3.25809654 -3.25809654 -3.25809654 -2.56494936
-2.56494936 -2.56494936 -2.56494936 -3.25809654 -3.25809654 -2.56494936
-2.56494936 -2.56494936 -2.56494936 -2.56494936 -2.56494936 -2.56494936
-2.15948425 -2.56494936]
p1V:
[-3.04452244 -3.04452244 -3.04452244 -3.04452244 -2.35137526 -2.35137526
-2.35137526 -2.35137526 -3.04452244 -2.35137526 -3.04452244 -3.04452244
-2.35137526 -2.35137526 -2.35137526 -2.35137526 -1.65822808 -3.04452244
-3.04452244 -3.04452244 -3.04452244 -1.94591015 -2.35137526 -3.04452244
-3.04452244 -1.94591015 -3.04452244 -3.04452244 -3.04452244 -2.35137526
-2.35137526 -3.04452244]
classVec:
[0, 1, 0, 1, 0, 1]
pAb:
0.5
没有0概率了,完美的解决了。
增加一个测试函数,对我们的分类器进行测试。
'''
Parameters:
vec2Classify - 待分类的词条数组
p0Vec - 侮辱类的条件概率数组
p1Vec -非侮辱类的条件概率数组
pClass1 - 文档属于侮辱类的概率
Returns:
0 - 属于非侮辱类
1 - 属于侮辱类
'''
# 函数说明:朴素贝叶斯分类器分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
# 函数说明:朴素贝叶斯分类器测试函数
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(np.array(trainMat),np.array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
if __name__ == '__main__':
testingNB()
>>>
['love', 'my', 'dalmation'] classified as: 0
['stupid', 'garbage'] classified as: 1
[‘love’, ‘my’, ‘dalmation’]这三个确实没有侮辱性,也就是0;但是[‘stupid’, ‘garbage’]这两个确实是侮辱性词汇,也就是1。
六、使用朴素贝叶斯过滤垃圾邮件
使用朴素贝叶斯对电子邮件进行分类
(1) 收集数据:提供文本文件。
(2) 准备数据:将文本文件解析成词条向量。
(3) 分析数据:检查词条确保解析的正确性。
(4) 训练算法:使用我们之前建立的trainNB0()函数。
(5) 测试算法:使用classifyNB(),并且构建一个新的测试函数来计算文档集的错误率。
(6) 使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上。
6.1 切分文本
对于英文文本,可以以非字母、非数字作为符号进行切分,使用split函数即可。
import re
# 函数说明:接收一个大字符串并将其解析为字符串列表
def textParse(bigString): #将字符串转换为字符列表
#将特殊符号作为切分标志进行字符串切分,即非字母、非数字
listOfTokens = re.split(r'\W+', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]#除了单个字母,例如大写的I,其它单词变成小写
'''
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
'''
# 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
if __name__ == '__main__':
docList = []; classList = []
for i in range(1, 26): #遍历25个txt文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())#读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
classList.append(1) #标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
classList.append(0) #标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) #创建词汇表,不重复
print(vocabList)
>>>
['done', 'book', 'party', 'discussions', 'http', 'comment', 'thailand', 'pick', 'drunk', 'code', 'runs', 'message', 'dusty', 'hours', 'group', '100m', 'tickets', 'email', 'magazine', 'trip', 'going', 'prices', 'docs', 'chapter', 'web', 'online', 'reservation', 'mandarin', 'cuda', 'doggy', 'source', 'who', 'leaves', 'linkedin', 'pricing', 'made', 'bathroom', 'windows', 'grounds', 'been', 'features', 'where', 'that', 'file', 'concise', 'window', 'past', 'get', '2011', 'cca', 'serial', 'try', 'name', 'foaming', 'father', 'automatically', 'members', 'improving', 'functionalities', 'thanks', 'page', 'scifinance', 'good', '86152', 'than', 'some', 'chinese', 'exhibit', 'store', 'hope', 'stepp', 'sliding', 'cats', 'invitation', 'important', 'retirement', 'shape', 'should', 'fundamental', 'launch', 'individual', 'advocate', 'help', 'aged', 'china', 'york', '2010', 'lists', 'mathematician', 'zach', 'forward', 'girl', 'place', 'holiday', 'the', 'bad', 'jocelyn', 'plane', 'from', 'site', 'reply', 'logged', 'designed', 'derivatives', 'vivek', 'welcome', 'but', 'sure', 'wednesday', 'since', 'these', 'will', 'generation', 'dozen', 'another', 'please', 'scenic', 'here', 'use', 'care', 'way', 'located', 'mba', 'jose', 'incoming', 'meet', 'enabled', 'parallel', 'com', 'can', 'cold', 'through', 'focusing', 'could', 'service', 'check', 'copy', 'then', 'support', 'top', 'looking', 'add', 'strategy', 'information', 'yay', '174623', 'address', 'contact', 'mathematics', 'decision', 'went', 'rain', 'files', 'winter', 'because', 'wasn', 'school', 'while', 'plugin', 'style', 'extended', '300x', 'and', 'modelling', 'held', 'kerry', 'perhaps', 'supporting', 'february', 'about', 'germany', 'door', 'lunch', 'art', 'insights', 'knew', 'thirumalai', 'hamm', 'his', 'turd', 'cat', 'release', 'connection', 'borders', 'storedetailview_98', 'would', 'jay', 'number', 'featured', 'sent', 'are', 'eugene', 'jar', 'expertise', 'tool', 'with', 'download', 'update', 'fractal', 'glimpse', 'mailing', 'risk', 'far', 'you', 'model', 'starting', 'come', 'sorry', 'this', 'fine', 'doors', 'job', 'notification', 'was', 'talked', 'generates', 'only', 'below', 'much', 'requested', 'carlo', 'automatic', 'definitely', 'attaching', 'link', 'uses', 'monte', 'coast', 'received', 'assigning', 'museum', 'think', 'town', 'whybrew', 'pictures', 'website', 'also', 'hold', 'doing', 'them', 'sounds', 'butt', 'does', 'upload', 'want', 'car', 'each', 'back', 'troy', 'create', 'what', 'possible', 'just', 'signed', 'having', 'how', 'computer', 'articles', 'focus', 'easily', 'level', 'ready', 'issues', 'train', 'jpgs', 'cheers', 'like', 'same', 'they', 'management', 'things', 'example', 'storage', 'fermi', 'google', 'sophisticated', 'more', 'ideas', 'favorite', 'instead', 'pretty', 'core', 'follow', 'brained', 'away', 'required', 'enjoy', 'tour', 'network', 'such', 'any', 'team', 'class', 'both', 'tokyo', 'fbi', 'must', 'keep', 'enough', 'edit', '1924', 'got', 'nature', 'inconvenience', 'nvidia', 'item', 'python', 'too', 'owner', '90563', 'had', 'those', 'need', 'peter', 'saw', 'roofer', 'groups', 'has', 'significantly', 'guy', 'blue', 'game', 'all', 'inside', 'high', 'interesting', 'said', 'phone', 'color', 'julius', 'approach', 'your', 'share', 'status', 'thing', 'mandatory', 'right', 'used', 'pls', 'often', 'today', 'day', 'mom', 'placed', 'mandelbrot', 'hotel', 'using', 'may', 'mail', 'assistance', 'inspired', 'for', 'two', 'yeah', 'work', 'least', 'products', 'faster', 'changing', 'hotels', 'programming', 'out', 'running', 'encourage', 'have', 'riding', 'you抮e', 'being', 'quantitative', 'wilmott', 'yesterday', 'www', 'behind', 'might', 'arvind', 'thank', 'there', 'survive', 'selected', 'hangzhou', 'customized', 'view', 'told', 'design', 'time', 'pavilion', 'died', 'huge', 'stuff', 'announcement', 'creation', 'rent', 'couple', 'regards', 'thought', 'giants', '66343', 'jqplot', 'listed', 'october', 'know', 'night', 'thread', 'don', 'commented', 'answer', 'year', 'one', 'program', 'professional', 'prepared', 'others', 'not', 'gas', 'john', 'cannot', '14th', 'came', 'province', 'includes', 'differ', 'heard', 'hommies', 'well', 'wrote', 'close', 'creative', 'bike', 'haloney', 'tent', 'benoit', 'capabilities', 'when', 'inform', 'bin', 'tesla', 'prototype', 'access', 'computing', 'fans', 'working', 'development', 'ones', 'horn', '50092', 'gpu', 'specifications', 'once', 'writing', 'accept', 'now', 'longer', 'ferguson', 'changes', 'sites', 'either', 'finance', 'suggest', 'free', 'items', 'lined', 'forum', 'series', 'note', 'jquery', 'call', 'questions', 'station', 'specifically', 'sky', 'let', 'hello', 'food', 'ryan', 'location', 'strategic', 'pages', 'see', 'take', 'latest', 'expo', 'new', 'spaying']
6.1 使用朴素贝叶斯进行交叉验证
根据词汇表就可以将每个文本向量化。首先将数据集分为训练集和测试集,使用 交叉验证 的方式测试朴素贝叶斯分类器的准确性。
import numpy as np
import random
import re
'''
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
'''
# 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
'''
Parameters:
vocabList - createVocabList返回的列表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词集模型
'''
# 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返回文档向量
'''
Parameters:
vocabList - createVocabList返回的列表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词袋模型
'''
# 函数说明:根据vocabList词汇表,构建词袋模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果词条存在于词汇表中,则计数加一
returnVec[vocabList.index(word)] += 1
return returnVec #返回词袋模型
'''
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
'''
# 函数说明:朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords)#创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,
#即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,
#即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom) #取对数,防止下溢出
p0Vect = np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive#返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
'''
Parameters:
vec2Classify - 待分类的词条数组
p0Vec - 侮辱类的条件概率数组
p1Vec -非侮辱类的条件概率数组
pClass1 - 文档属于侮辱类的概率
Returns:
0 - 属于非侮辱类
1 - 属于侮辱类
'''
# 函数说明:朴素贝叶斯分类器分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #对应元素相乘。logA * B = logA + logB,
#所以这里加上log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
'''
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
'''
# 函数说明:朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,
#即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,
#即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom) #取对数,防止下溢出
p0Vect = np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive#返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
# 函数说明:接收一个大字符串并将其解析为字符串列表
def textParse(bigString): #将字符串转换为字符列表
listOfTokens = re.split(r'\W+', bigString) #将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2]#除了单个字母,例如大写的I,其它单词变成小写
# 函数说明:测试朴素贝叶斯分类器
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26): #遍历25个txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read())#读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1) #标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0) #标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) #创建词汇表,不重复
trainingSet = list(range(50)); testSet = [] #创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10):#从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) #随机选取索索引值
testSet.append(trainingSet[randIndex]) #添加测试集的索引值
del(trainingSet[randIndex]) #在训练集列表中删除添加到测试集的索引值
trainMat = []; trainClasses = [] #创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: #遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) #将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))#训练朴素贝叶斯模型
errorCount = 0 #错误分类计数
for docIndex in testSet: #遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) #测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:#如果分类错误
errorCount += 1 #错误计数加1
print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
if __name__ == '__main__':
spamTest()
分类错误的测试集: ['yay', 'you', 'both', 'doing', 'fine', 'working', 'mba', 'design', 'strategy', 'cca', 'top', 'art', 'school', 'new', 'program', 'focusing', 'more', 'right', 'brained', 'creative', 'and', 'strategic', 'approach', 'management', 'the', 'way', 'done', 'today']
分类错误的测试集: ['home', 'based', 'business', 'opportunity', 'knocking', 'your', 'door', 'don抰', 'rude', 'and', 'let', 'this', 'chance', 'you', 'can', 'earn', 'great', 'income', 'and', 'find', 'your', 'financial', 'life', 'transformed', 'learn', 'more', 'here', 'your', 'success', 'work', 'from', 'home', 'finder', 'experts']
错误率:20.00%
函数spamTest()会输出在10封随机选择的电子邮件上的分类错误概率。所以存在误判的情况,将垃圾邮件误判为正常邮件要比将正常邮件归为垃圾邮件好。
七、总结
对于分类而言,使用 概率 有时要比使用 硬规则 更为有效。贝叶斯概率及贝叶斯准则提供了一种利用已知值来估计未知概率的有效方法。可以通过 特征之间的条件独立性假设,降低对数据量的需求。独立性假设是指一个词的出现概率并不依赖于文档中的其他词。当然我们也知道这个假设过于简单。这就是之所以称为 朴素贝叶斯 的原因。尽管条件独立性假设并不正确,但是朴素贝叶斯仍然是一种有效的分类器。