大数据随记 —— WordCount 案例
大数据系列文章: 目录

文章目录
- 一、WordCount 案例简介
- 二、WordCount 实现
- 1、WordCount 实现分析
- Ⅰ、Map 阶段
- Ⅱ、Reduce 阶段
- 2、WordCount 代码实现
- Ⅰ、Maven 依赖配置
- Ⅱ、WordCount 代码实现
- a、map 函数
- b、reduce 函数
- c、main 函数
- ① Configuration 类
- ② Job 类
- ③ 设置 map/reduce 的 key/value
- ④ 设置 Job 的输入输出路径
- ⑤ 提交代码
- Ⅲ、所有代码
- Ⅳ、打包运行
- ① 打包
- ② 运行
文章目录
-
- 一、WordCount 案例简介
- 二、WordCount 实现
-
- 1、WordCount 实现分析
-
- Ⅰ、Map 阶段
- Ⅱ、Reduce 阶段
- 2、WordCount 代码实现
-
- Ⅰ、Maven 依赖配置
- Ⅱ、WordCount 代码实现
-
- a、map 函数
- b、reduce 函数
- c、main 函数
-
- ① Configuration 类
- ② Job 类
- ③ 设置 map/reduce 的 key/value
- ④ 设置 Job 的输入输出路径
- ⑤ 提交代码
- Ⅲ、所有代码
- Ⅳ、打包运行
-
- ① 打包
- ② 运行
一、WordCount 案例简介
从 MapReduce 的命名可以看出,MapReduce 主要由两个阶段组成:Map 与 Reduce。通过编写 map() 函数与 reduce() 函数,就可以使用 MapReduce 完成分布式程序的设计。
M a p R e d u c e { M a p ⇒ m a p ( ) 函数 R e d u c e ⇒ r e d u c e ( ) 函数 MapReduce \left\{ \begin{aligned} &Map &&\Rightarrow map() 函数 \\\\ &Reduce &&\Rightarrow reduce() 函数 \end{aligned} \right . MapReduce⎩ ⎨ ⎧MapReduce⇒map()函数⇒reduce()函数
最简单的 MapReduce 程序应该包括 Map 函数、Reduce 函数来实现 MapReduce 的两个阶段,并用一个 main 函数(有的地方也被称为 driver)对以上两个函数的输入输出进行操作。
而这里所介绍的 WordCount 案例就类似于 MapReduce 中的 “Hello World”,通过分析大量的文本,来统计文本中所出现的单词的个数。
二、WordCount 实现
假设我们有一个文本文件,并需要统计其中的锁板喊的单词的个数。
Hello World Hadoop
Hello Hadoop World Hello
Hello World Hadoop Bye
Bye Hadoop World

1、WordCount 实现分析
Map 阶段主要是通过读取文本,并将其中的单词组成 map,变成
Ⅰ、Map 阶段
在这里,一共读取了以下四行:
① 读取第一行 Hello World Hadoop,并分割该行单词形成 map:
② 读取第二行 Hello Hadoop World Hello,并分割该行单词形成 map:
③ 读取第三行 Hello World Hadoop Bye,并分割该行单词形成 map:
④ 读取第四行 Bye Hadoop World,并分割该行单词形成 map:
Ⅱ、Reduce 阶段
① 根据 Map 阶段的结果将相同 key 组合成
② 遍历 key 中的 value[] 数组,分别统计每个单词出现的次数,合并成
2、WordCount 代码实现
Ⅰ、Maven 依赖配置
新建 Maven 工程,并配置以下内容到 pom.xml。
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.2version>
dependency>
Ⅱ、WordCount 代码实现
a、map 函数
public void map(Object key, Text value, Context context)
创建 Map 类继承 Mapper 类,并实现 map 方法。map 方法里有三个参数,前两个参数 (Object key, Text value) 即是输入所需的 key 与 value,第三个参数(Context context)则记录了 map 执行的上下文,用来记录 job 运行时的一些信息。
b、reduce 函数
public void reduce(Text key, Iterable<IntWritable> values, Context context)
创建 Reduce 类继承 Reducer 类,并实现 reduce 方法。reduce 方法中也有三个参数,前两个参数 (Text key, Iterable 对应着 map 方法对 key 与 value,第三个参数 (Context context) 与 map 的 context 的作用相同。
c、main 函数
大部分 MapReduce 程序的 main 函数都是差不多的,主要都包含以下部分:
① Configuration 类
Configuration conf = new Configuration();
MapReduce 程序都需要初始化 Configuration,以此来读取 MapReduce 的系统配置信息。
② Job 类
Job job = Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
通过 Job 类中的 getInstance() 函数,可以得到系统当前已经实例化的该类对象。getInstance() 的第一个参数是 conf,第二个参数是 job 的名称。第三行与第四行用来指定 map 函数与 reduce 函数的实现类。
③ 设置 map/reduce 的 key/value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
这里用来指定 key 与 value 的类型。
④ 设置 Job 的输入输出路径
// String InputPATH = "hdfs://master:8020/Input";
// String OutputPATH = "hdfs://master:8020/Output";
String InputPATH = args[0];
String OutputPATH = args[1];
FileInputFormat.addInputPath(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
这里用来设置 Job 的输入输出路径,可以直接在代码中指定输入输出路径,也可以使用命令行传输传入参数。
⑤ 提交代码
job.waitForCompletion(true);
最后这行代码用来程序结束后提交代码。
Ⅲ、所有代码
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.StringTokenizer;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text,Text,LongWritable>{
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String string = value.toString();
String[] spilts = string.split(" ");
for(String spilt:spilts){
context.write(new Text(spilt),new LongWritable(1L));
}
}
}
public static class Reduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(LongWritable val:values){
sum += val.get();
}
context.write(key,new LongWritable(sum));
}
}
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
//String InputPATH = args[0];
//String OutputPATH = args[1];
String InputPATH = "hdfs://master:8020/Input";
String OutputPATH = "hdfs://master:8020/Output";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(InputPATH),conf);
if(fileSystem.exists(new Path(OutputPATH))){
fileSystem.delete(new Path(OutputPATH),true);
}
Job job = Job.getInstance(conf,"WordCount");
// 指定 Jar 文件
job.setJarByClass(WordCount.class);
// 设置 map
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置 reduce
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置 input format
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(InputPATH);
FileInputFormat.addInputPath(job,inputPath);
// 设置 output format
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(OutputPATH);
FileOutputFormat.setOutputPath(job,outputPath);
// 提交 job
System.exit(job.waitForCompletion(true)?0:1);
}
}
Ⅳ、打包运行
① 打包
使用 IDEA 的 Maven 打包,并通过 XShell 放到相应文件夹下
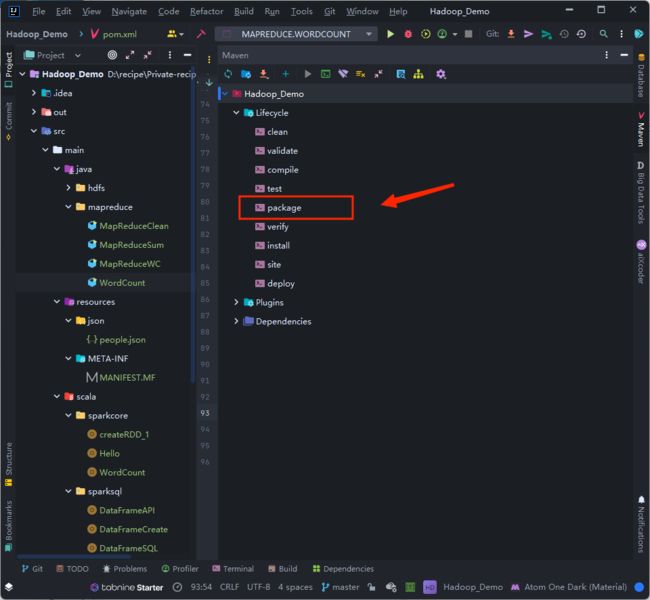
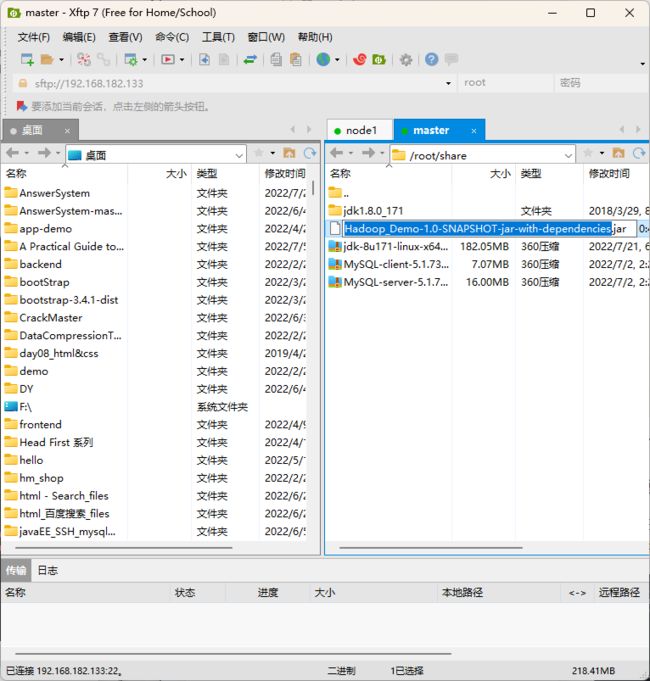
② 运行
hadoop jar Hadoop_Demo-1.0-SNAPSHOT-jar-with-dependencies.jar mapreduce.WordCount /input /output
注意:我这里 input 目录是由数据的
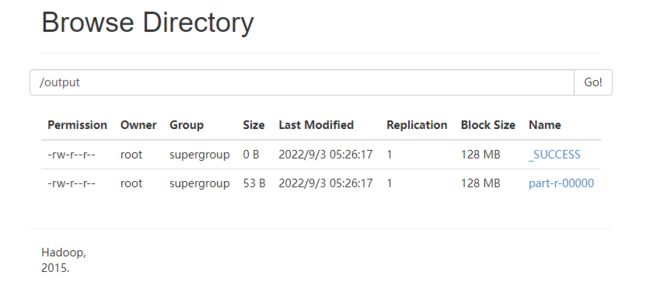
可以看到内容输出。
