Android资源管理框架:编译和打包
在一个APK文件中,除了有代码文件之外,还有很多资源文件。这些资源文件是通过Android资源打包工具aapt(Android Asset Package Tool)打包到APK文件里面的。在打包之前,大部分文本格式的XML资源文件还会被编译成二进制格式的XML资源文件。只有那些类型为res/animator、res/anim、res/color、res/drawable(非Bitmap文件,即非.png、.9.png、.jpg、.gif文件)、res/layout、res/menu、res/values和res/xml的资源文件均会从文本格式的XML文件编译成二进制格式的XML文件,如图所示:

这些XML资源文件之所要从文本格式编译成二进制格式,是因为:
- 二进制格式的XML文件占用空间更小。这是由于所有XML元素的标签、属性名称、属性值和内容所涉及到的字符串都会被统一收集到一个字符串资源池中去,并且会去重。有了这个字符串资源池,原来使用字符串的地方就会被替换成一个索引到字符串资源池的整数值,从而可以减少文件的大小。
- 二进制格式的XML文件解析速度更快。这是由于二进制格式的XML元素里面不再包含有字符串值,因此就避免了进行字符串解析,从而提高速度。
为了使得一个应用程序能够在运行时同时支持不同的大小和密度的屏幕,以及支持国际化,即支持不同的国家地区和语言,Android应用程序资源的组织方式有18个维度,每一个维度都代表一个配置信息,从而可以使得应用程序能够根据设备的当前配置信息来找到最匹配的资源来展现在UI上,从而提高用户体验。
由于Android应用程序资源的组织方式可以达到18个维度,因此就要求Android资源管理框架能够快速定位最匹配设备当前配置信息的资源来展现在UI上,否则的话,就会影响用户体验。为了支持Android资源管理框架快速定位最匹配资源,Android资源打包工具aapt在编译和打包资源的过程中,会执行以下两个额外的操作:
- 赋予每一个非assets资源一个ID值,这些ID值以常量的形式定义在一个R.java文件中。
- 生成一个resources.arsc文件,用来描述那些具有ID值的资源的配置信息,它的内容就相当于是一个资源索引表。
有了资源ID以及资源索引表之后,Android资源管理框架就可以迅速将根据设备当前配置信息来定位最匹配的资源了。
Android资源打包工具在编译应用程序资源之前,会创建一个资源表。这个资源表使用一个ResourceTable对象来描述,当应用程序资源编译完成之后,它就会包含所有资源的信息。有了这个资源表之后, Android资源打包工具就可以根据它的内容来生成资源索引表文件resources.arsc了。
先大概了解资源表里面都有些什么东西:

ResourceTable类用来总体描述一个资源表,它的重要成员变量的含义如下所示:
- mAssetsPackage:表示当前正在编译的资源的包名称。
- mPackages:表示当前正在编译的资源包,每一个包都用一个Package对象来描述。例如,一般我们在编译应用程序资源时,都会引用系统预先编译好的资源包,这样当前正在编译的资源包除了目标应用程序资源包之外,就还有预先编译好的系统资源包。
- mOrderedPackages:和mPackages一样,也是表示当前正在编译的资源包,不过它们是以Package ID从小到大的顺序保存在一个Vector里面的,而mPackages是一个以Package Name为Key的DefaultKeyedVector。
- mAssets:表示当前编译的资源目录,它指向的是一个AaptAssets对象。
Package类用来描述一个包,这个包可以是一个被引用的包,即一个预先编译好的包,也可以是一个正在编译的包,它的重要成员变量的含义如下所示:
- mName:表示包的名称。
- mTypes:表示包含的资源的类型,每一个类型都用一个Type对象来描述。资源的类型就是指animimator、anim、color、drawable、layout、menu和values等。
- mOrderedTypes:和mTypes一样,也是表示包含的资源的类型,不过它们是Type ID从小到大的顺序保存在一个Vector里面的,而mTypes是一个以Type Name为Key的DefaultKeyedVector。
Type类用来描述一个资源类型,它的重要成员变量的含义如下所示:
- mName:表示资源类型名称。
- mConfigs:表示包含的资源配置项列表,每一个配置项列表都包含了一系列同名的资源,使用一个ConfigList来描述。例如,假设有main.xml和sub.xml两个layout类型的资源,那么main.xml和sub.xml都分别对应有一个ConfigList。
- mOrderedConfigs:和mConfigs一样,也是表示包含的资源配置项,不过它们是以Entry ID从小到大的顺序保存在一个Vector里面的,而mConfigs是以Entry Name来Key的DefaultKeyedVector。
- mUniqueConfigs:表示包含的不同资源配置信息的个数。我们可以将mConfigs和mOrderedConfigs看作是按照名称的不同来划分资源项,而将mUniqueConfigs看作是按照配置信息的不同来划分资源项。
ConfigList用来描述一个资源配置项列表,它的重要成员变量的含义如下所示:
- mName:表示资源项名称,也称为Entry Name。
- mEntries:表示包含的资源项,每一个资源项都用一个Entry对象来描述,并且以一个对应的ConfigDescription为Key保存在一个DefaultKeyedVector中。例如,假设有一个名称为icon.png的drawable资源,有三种不同的配置,分别是ldpi、mdpi和hdpi,那么以icon.png为名称的资源就对应有三个项。
Entry类用来描述一个资源项,它的重要成员变量的含义如下所示:
- mName:表示资源名称。
- mItem:表示资源数据,用一个Item对象来描述。
Item类用来描述一个资源项数据,它的重要成员变量的含义如下所示:
- value:表示资源项的原始值,它是一个字符串。
- parsedValue:表示资源项原始值经过解析后得到的结构化的资源值,使用一个Res_Value对象来描述。例如,一个整数类型的资源项的原始值为“12345”,经过解析后,就得到一个大小为12345的整数类型的资源项。
ConfigDescription类是从ResTable_config类继承下来的,用来描述一个资源配置信息。ResTable_config类的成员变量imsi、locale、screenType、input、screenSize、version和screenConfig对应的实际上就是18个资源维度。
当前正在编译的资源目录是使用一个AaptAssets对象来描述的:

AaptAssets类的重要成员变量的含义如下所示:
- mPackage:表示当前正在编译的资源的包名称。
- mRes:表示所包含的资源类型集,每一个资源类型都使用一个ResourceTypeSet来描述,并且以Type Name为Key保存在一个KeyedVector中。
- mHaveIncludedAssets:表示是否有引用包。
- mIncludedAssets:指向的是一个AssetManager,用来解析引用包。引用包都是一些预编译好的资源包,它们需要通过AssetManager来解析。事实上,Android应用程序在运行的过程中,也是通过AssetManager来解析资源的。
- mOverlay:表示当前正在编译的资源的重叠包。重叠包是什么概念呢?假设我们正在编译的是Package-1,这时候我们可以设置另外一个Package-2,用来告诉aapt,如果Package-2定义有和Package-1一样的资源,那么就用定义在Package-2的资源来替换掉定义在Package-1的资源。通过这种Overlay机制,我们就可以对资源进行定制,而又不失一般性。
ResourceTypeSet类实际上描述的是一个类型为AaptGroup的KeyedVector,并且这个KeyedVector是以AaptGroup Name为Key的。
AaptGroup类描述的是一组同名的资源,类似于前面所描述的ConfigList,它有一个重要的成员变量mFiles,里面保存的就是一系列同名的资源文件。每一个资源文件都是用一个AaptFile对象来描述的,并且以一个AaptGroupEntry为Key保存在一个DefaultKeyedVector中。
AaptFile类的重要成员变量的含义如下所示:
- mPath:表示资源文件路径。
- mGroupEntry:表示资源文件对应的配置信息,使用一个AaptGroupEntry对象来描述。
- mResourceType:表示资源类型名称。
- mData:表示资源文件编译后得到的二进制数据。
- mDataSize:表示资源文件编译后得到的二进制数据的大小。
AaptGroupEntry类的作用类似前面所描述的ResTable_config,它的成员变量mcc、mnc、locale、vendor、screenLayoutSize、screenLayoutLong、orientation、uiModeType、uiModeNight、density、tounscreen、keysHidden、keyboard、navHidden、navigation、screenSize和version对应的实际上就是18个资源维度。
了解了ResourceTable类和AaptAssets类的实现之后,我们就可以开始分析Android资源打包工具的执行过程了:

假设我们当前要编译的应用程序资源目录结构如下所示:
project
--AndroidManifest.xml
--res
--drawable-ldpi
--icon.png
--drawable-mdpi
--icon.png
--drawable-hdpi
--icon.png
--layout
--main.xml
--sub.xml
--values
--strings.xml
一、解析AndroidManifest.xml
解析AndroidManifest.xml是为了获得要编译资源的应用程序的包名称。我们知道,在AndroidManifest.xml文件中,manifest标签的package属性的值描述的就是应用程序的包名称。有了这个包名称之后,就可以创建资源表了,即创建一个ResourceTable对象。
二、添加被引用资源包
Android系统定义了一套通用资源,这些资源可以被应用程序引用。例如,我们在XML布局文件中指定一个LinearLayout的android:orientation属性的值为“vertical”时,这个“vertical”实际上就是在系统资源包里面定义的一个值。
我们在编译一个Android应用程序的资源的时候,至少会涉及到两个包,其中一个被引用的系统资源包,另外一个就是当前正在编译的应用程序资源包。每一个包都可以定义自己的资源,同时它也可以引用其它包的资源。
那么,一个包是通过什么方式来引用其它包的资源的呢?这就是我们熟悉的资源ID了。资源ID是一个4字节的无符号整数,其中,最高字节表示Package ID,次高字节表示Type ID,最低两字节表示Entry ID。
Package ID相当于是一个命名空间,限定资源的来源。Android系统当前定义了两个资源命令空间,其中一个系统资源命令空间,它的Package ID等于0x01,另外一个是应用程序资源命令空间,它的Package ID等于0x7f。
Type ID是指资源的类型ID。资源的类型有animator、anim、color、drawable、layout、menu、raw、string和xml等等若干种,每一种都会被赋予一个ID。
Entry ID是指每一个资源在其所属的资源类型中所出现的次序。注意,不同类型的资源的Entry ID有可能是相同的,但是由于它们的类型不同,我们仍然可以通过其资源ID来区别开来。
三、收集资源文件
在编译应用程序资源之前,Android资源打包工具aapt会创建一个AaptAssets对象,用来收集当前需要编译的资源文件。这些需要编译的资源文件就保存在AaptAssets类的成员变量mRes中。
AaptAssets类的成员变量mRes是一个类型为ResourceTypeSet的KeyedVector,这个KeyedVector的Key就是资源的类型名称。由此就可知,收集到资源文件是按照类型来保存的。例如,对于我们在这篇文章中要用到的例子,一共有三种类型的资源,分别是drawable、layout和values,于是,就对应有三个ResourceTypeSet。
ResourceTypeSet类本身描述的也是一个KeyedVector,不过它里面保存的是一系列有着相同文件名的AaptGroup。例如,对于我们在这篇文章中要用到的例子:
- 类型为drawable的ResourceTypeSet只有一个AaptGroup,它的名称为icon.png。这个AaptGroup包含了三个文件,分别是res/drawable-ldpi/icon.png、res/drawable-mdpi/icon.png和res/drawable-hdpi/icon.png。每一个文件都用一个AaptFile来描述,并且都对应有一个AaptGroupEntry。每一个AaptGroupEntry描述的都是不同的资源配置信息,即它们所描述的屏幕密度分别是ldpi、mdpi和hdpi。
- 类型为layout的ResourceTypeSet有两个AaptGroup,它们的名称分别为main.xml和sub.xml。这两个AaptGroup都是只包含了一个AaptFile,分别是res/layout/main.xml和res/layout/sub.xml。这两个AaptFile同样是分别对应有一个AaptGroupEntry,不过这两个AaptGroupEntry描述的资源配置信息都是属于default的。
- 类型为values的ResourceTypeSet只有一个AaptGroup,它的名称为strings.xml。这个AaptGroup只包含了一个AaptFile,即res/values/strings.xml。这个AaptFile也对应有一个AaptGroupEntry,这个AaptGroupEntry描述的资源配置信息也是属于default的。
四、将收集到的资源增加到资源表
前面收集到的资源只是保存在一个AaptAssets对象中,这一步需要将这些资源同时增加到一个资源表中去,即增加到前面所创建的一个ResourceTable对象中去,因为最后我们需要根据这个ResourceTable来生成资源索引表,即生成resources.arsc文件。
注意,这一步收集到资源表的资源是不包括values类型的资源的。类型为values的资源比较特殊,它们要经过编译之后,才会添加到资源表中去。
在ResourceTable类中,每一个资源都是分别用一个Entry对象来描述的,这些Entry分别按照Pacakge、Type和ConfigList来分类保存。例如,对于我们在这篇文章中要用到的例子,假设它的包名为“shy.luo.activity”,那么在ResourceTable类的成员变量mPackages和mOrderedPackages中,就会分别保存有一个名称为“shy.luo.activity”的Package。
在这个名称为“shy.luo.activity”的Package中,分别包含有drawable和layout两种类型的资源,每一种类型使用一个Type对象来描述,其中:
- 类型为drawable的Type包含有一个ConfigList。这个ConfigList的名称为icon.png,包含有三个Entry,分别为res/drawable-ldip/icon.png、res/drawable-mdip/icon.png和res/drawable-hdip/icon.png。每一个Entry都对应有一个ConfigDescription,用来描述不同的资源配置信息,即分别用来描述ldpi、mdpi和hdpi三种不同的屏幕密度。
- 类型为layout的Type包含有两个ConfigList。这两个ConfigList的名称分别为main.xml和sub.xml。名称为main.xml的ConfigList包含有一个Entry,即res/layout/main.xml。名称为sub.xml的ConfigList包含有一个Entry,即res/layout/sub/xml。
上述得到的五个Entry分别对应有五个Item,它们的对应关系以及内容如下图所示:
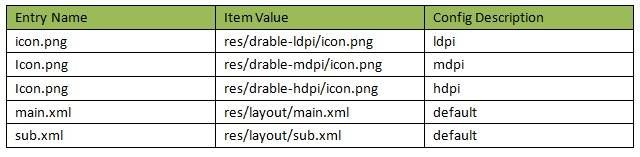
五、编译values类资源
类型为values的资源描述的都是一些简单的值,如数组、颜色、尺寸、字符串和样式值等,这些资源是在编译的过程中进行收集的。
在这篇文章中要用到的例子中,包含有一个strings.xml的文件,它的内容如下所示:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<string name="app_name">Activity</string>
<string name="sub_activity">Sub Activity</string>
<string name="start_in_process">Start sub-activity in process</string>
<string name="start_in_new_process">Start sub-activity in new process</string>
<string name="finish">Finish activity</string>
</resources>
这个文件经过编译之后,资源表就多了一个名称为string的Type,这个Type有五个ConfigList。这五个ConfigList的名称分别为“app_name”、“sub_activity”、“start_in_process”、“start_in_new_process”和“finish”,每一个ConfigList又分别含有一个Entry。
上述得到的五个Entry分别对应有五个Item,它们的对应关系以及内容如图所示:

六、给Bag资源分配ID
类型为values的资源除了是string之外,还有其它很多类型的资源,其中有一些比较特殊,如bag、style、plurals和array类的资源。这些资源会给自己定义一些专用的值,这些带有专用值的资源就统称为Bag资源。
例如,Android系统提供的android:orientation属性的取值范围为{“vertical”、“horizontal”},就相当于是定义了vertical和horizontal两个Bag。
在继续编译其它非values的资源之前,我们需要给之前收集到的Bag资源分配资源ID,因为它们可能会被其它非values类资源引用到。假设在res/values目录下,有一个attrs.xml文件,它的内容如下所示:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<attr name="custom_orientation">
<enum name="custom_vertical" value="0" />
<enum name="custom_horizontal" value="1" />
</attr>
</resources>
这个文件定义了一个名称为“custom_orientation”的属性,它是一个枚举类型的属性,可以取值为“custom_vertical”或者“custom_horizontal”。Android资源打包工具aapt在编译这个文件的时候,就会生成以下三个Entry,如图所示:

上述三个Entry均为Bag资源项,其中,custom_vertical(id类型资源)和custom_horizontal( id类型资源)是custom_orientation(attr类型资源)的两个bag,我们可以将custom_vertical和custom_horizontal看成是custom_orientation的两个元数据,用来描述custom_orientation的取值范围。
实际上,custom_orientation还有一个内部元数据,用来描述它的类型。这个内部元数据也是通过一个bag来表示的,这个bag的名称和值分别为“type”和TYPE_ENUM,用来表示它描述的是一个枚举类型的属性。注意,所有名称以“^”开头的bag都是表示一个内部元数据。
对于Bag资源来说,这一步需要给它们的元数据项分配资源ID,也就是给它们的bag分配资源ID。例如,对于上述的custom_orientation来说,我们需要给它的type、custom_vertical和custom_horizontal分配资源ID,其中,^type分配到的是attr类型的资源ID,而custom_vertical和custom_horizontal分配到的是id类型的资源ID。
七、编译Xml资源文件
除了values类型的资源文件,其它所有的Xml资源文件都需要编译。这里我们只挑layout类型的资源文件来说明Xml资源文件的编译过程,也就是这篇文章中要用到的例子中的main.xml文件,它的内容如下所示:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:orientation="vertical"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:gravity="center">
<Button
android:id="@+id/button_start_in_process"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:gravity="center"
android:text="@string/start_in_process" >
</Button>
<Button
android:id="@+id/button_start_in_new_process"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:gravity="center"
android:text="@string/start_in_new_process" >
</Button>
</LinearLayout>
Xml资源文件main.xml的编译过程如图所示:

1、解析Xml文件
解析Xml文件是为了可以在内存中用一系列树形结构的XMLNode来表示它。每一个XMLNode都表示一个Xml元素,其中:
- mElementName,表示Xml元素标签。
- mChars,表示Xml元素的文本内容。
- mAttributes,表示Xml元素的属性列表。
- mChildren,表示Xml元素的子元素。
Xml文件解析完成之后,就可以得到一个用来描述根节点的XMLNode,接下来就可以通过这个根节点来完成其它的编译操作。
2、赋予属性名称资源ID
这一步实际上就是给每一个Xml元素的属性名称都赋予资源ID。例如,对于main.xml文件的根节点LinearLayout来说,就是要分别给它的属性名称“android:orientation”、“android:layout_width”、“android:layout_height”和“android:gravity”赋予一个资源ID。注意,上述这些属性都是在系统资源包里面定义的,因此,Android资源打包工具首先是要在系统资源包里面找到这些名称所对应的资源ID,然后才能赋给main.xml文件的根节点LinearLayout。
对于系统资包来说,“android:orientation”、“android:layout_width”、“android:layout_height”和“android:gravity”等这些属性名称是它定义的一系列Bag资源,在它被编译的时候,就已经分配好资源ID了,就如上面的第六步操作所示。
每一个Xml文件都是从根节点开始给属性名称赋予资源ID,然后再给递归给每一个子节点的属性名称赋予资源ID,直到每一个节点的属性名称都获得了资源ID为止。
3、解析属性值
上一步是对Xml元素的属性的名称进行解析,这一步是对Xml元素的属性的值进行解析。例如,对于对于main.xml文件的根节点LinearLayout来说,前面我们已经给它的属性android:orientation的名称赋予了一个资源ID,这里就要给它的值“vertical”进行解析。
前面提到,android:orientation是在系统资源包定义的一个Bag资源,这个Bag资源分配有资源ID,而且会指定有元数据,也就是它可以取哪些值。对于android:orientation来说,它的合法取值就为“horizontal”或者“vertical”。在系统资源包中,“horizontal”或者“vertical”也同样是一个Bag资源,它们的值分别被定义为0和1。
Android资源打包工具是如何找到main.xml文件的根节点LinearLayout的属性android:orientation的字符串值“vertical”所对应的整数值1的呢?假设在上一步中,从系统资源包找到“android:orientation”的资源ID为0x010100c4,那么Android资源打包工具就会通过这个资源ID找到它的元数据,也就是两个名称分别为“horizontal”和“vertical”的bag,接着就根据字符串匹配到名称“vertical”的bag,最后就可以将这个bag的值1作为解析结果了。
注意,对于引用类型的属性值,要进行一些额外的处理。例如,对于main.xml文件的第一个Button节点的android:id属性值“@+id/button_start_in_process”,其中,“@”表示后面描述的属性是引用类型的,“+”表示如果该引用不存在,那么就新建一个,“id”表示引用的资源类型是id,“button_start_in_process”表示引用的名称。实际上,在"id"前面,还可以指定一个包名,例如,将main.xml文件的第一个Button节点的android:id属性值指定为“@+[package:]id/button_start_in_process” 。如果没有指定包名的话,那么就会默认在当前编译的包里面查找button_start_in_process这个引用。由于前面指有“+”符号,因此,如果在指定的包里面找不到button_start_in_process这个引用的话,那么就会在该包里面创建一个新的。无论button_start_in_process在指定的包里面原来就存在的,还是新建的,最终Android资源打包工具都是将它的资源ID作为解析结果。
在我们这个情景中,在解析main.xml文件的两个Button节点的android:id属性值“@+id/button_start_in_process”和“@+id/button_start_in_new_process”时,当前正在编译的资源包没有包含有相应的引用的,因此,Android资源打包工具就会在当前正在编译的资源包里面增加两个类型为id的Entry,如图所示:

此外,对于main.xml文件的两个Button节点的android:text属性值“@string/start_in_process”和“@string/start_in_new_process”,它们分别表示引用的是当前正在编译的资源包的名称分别为“start_in_process”和“start_in_new_process”的string资源。这两个string资源在前面的第五步操作中已经编译过了,因此,这里就可以直接获得它们的资源ID。
注意,一个资源项一旦创建之后,要获得它的资源ID是很容易的,因为它的Package ID、Type ID和Entry ID都是已知的。
4、压平Xml文件
接下来就可以对Xml文件的内容进行扁平化处理了,实际上就是将Xml文件从文本格式转换为二进制格式,这个过程如图所示:

Step 1. 收集有资源ID的属性的名称字符串
这一步除了收集那些具有资源ID的Xml元素属性的名称字符串之外,还会将对应的资源ID收集起来放在一个数组中。这里收集到的属性名称字符串保存在一个字符串资源池中,它们与收集到的资源ID数组是一一对应的。
对于main.xml文件来说,具有资源ID的Xml元素属性的名称字符串有“orientation”、“layout_width”、“layout_height”、“gravity”、“id”和“text”,假设它们对应的资源ID分别为0x010100c4、0x010100f4、0x010100f5、0x010100af、0x010100d0和0x0101014f,那么最终得到的字符串资源池的前6个位置和资源ID数组的对应关系如图所示:

Step 2. 收集其它字符串
这一步收集的是Xml文件中的其它所有字符串。由于在前面的Step 1中,那些具有资源ID的Xml元素属性的名称字符串已经被收集过了,因此,它们在一步中不会被重复收集。对于main.xml文件来说,这一步收集到的字符串如图所示:

其中,“android”是android命名空间前缀,“http://schemas.android.com/apk/res/android”
是android命名空间uri,“LinearLayout”是LinearLayout元素的标签,“Button”是Button元素的标签。
Step 3. 写入Xml文件头
最终编译出来的Xml二进制文件是一系列的chunk组成的,每一个chunk都有一个头部,用来描述chunk的元信息。同时,整个Xml二进制文件又可以看成一块总的chunk,它有一个类型为ResXMLTree_header的头部。
ResXMLTree_header内嵌有一个类型为ResChunk_header的头部。事实上,每一种头部类型都会内嵌有一个类型为ResChunk_header的基础头部,并且这个ResChunk_header都是作为第一个成员变量出现的。这样在解析二进制Xml文件的时候,只需要读出前面大小为sizeof(ResChunk_header)的数据块,并且通过识别其中的type值,就可以知道实际正在处理的chunk的具体类型。
对于ResXMLTree_header头部来说,内嵌在它里面的ResChunk_header的成员变量的值如下所示:
- type:等于RES_XML_TYPE,描述这是一个Xml文件头部。
- headerSize:等于sizeof(ResXMLTree_header),表示头部的大小。
- size:等于整个二进制Xml文件的大小,包括头部headerSize的大小。
Step 4. 写入字符串资源池
原来定义在Xml文件中的字符串已经在Step 1和Step 2中收集完毕,因此,这里就可以将它们写入到最终收集到二进制格式的Xml文件中去。注意,写入的字符串是严格按照它们在字符串资源池中的顺序写入的。例如,对于main.xml来说,依次写入的字符串为“orientation”、“layout_width”、“layout_height”、“gravity”、“id”、“text”、“android”、“http://schemas.android.com/apk/res/android” 、“LinearLayout”和“Button”。之所以要严格按照这个顺序来写入,是因为接下来要将前面Step 1收集到的资源ID数组也写入到二进制格式的Xml文件中去,并且要保持这个资源ID数组与字符串资源池前六个字符串的对应关系。
写入的字符串池chunk同样也是具有一个头部的,这个头部的类型为ResStringPool_header。内嵌在ResStringPool_header里面的ResChunk_header的成员变量的值如下所示:
- type:等于RES_STRING_POOL_TYPE,描述这是一个字符串资源池。
- headerSize:等于sizeof(ResStringPool_header),表示头部的大小。
- size:整个字符串chunk的大小,包括头部headerSize的大小。
ResStringPool_header的其余成员变量的值如下所示:
- stringCount:等于字符串的数量。
- styleCount:等于字符串的样式的数量。
- flags:等于0、SORTED_FLAG、UTF8_FLAG或者它们的组合值,用来描述字符串资源串的属性,例如,SORTED_FLAG位等于1表示字符串是经过排序的,而UTF8_FLAG位等于1表示字符串是使用UTF8编码的,否则就是UTF16编码的。
- stringsStart:等于字符串内容块相对于其头部的距离。
- stylesStart:等于字符串样式块相对于其头部的距离。
无论是UTF8,还是UTF16的字符串编码,每一个字符串的前面都有2个字节表示其长度,而且后面以一个NULL字符结束。对于UTF8编码的字符串来说,NULL字符使用一个字节的0x00来表示,而对于UTF16编码的字符串来说,NULL字符使用两个字节的0x0000来表示。
如果一个字符串的长度超过32767,那么就会使用更多的字节来表示。假设字符串的长度超过32767,那么前两个字节的最高位就会等于0,表示接下来的两个字节仍然是用来表示字符串长度的,并且前两个字表示高16位,而后两个字节表示低16位。
除了ResStringPool_header头部、字符串内容块和字符串样式内容块之外,还有两个偏移数组,分别是字符串偏移数组和字符串样式偏移数组,这两个偏移数组的大小就分别等于字符串的数量stringCount和styleCount的值,而每一个元素都是一个无符号整数。整个字符中资源池的组成就如图所示:
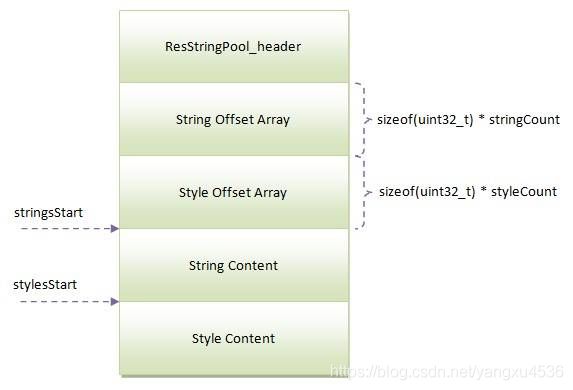
注意,字符串偏移数组和字符串样式偏移数组的值分别是相对于stringStart和styleStart而言的。在解析二进制Xml文件的时候,通过这两个偏移数组以及stringsStart和stylesStart的值就可以迅速地定位到第i个字符串。
接下来,我们就重点说说什么是字符串样式。假设有一个字符串资源池,它有五个字符串,分别是"apple"、“banana”、“orange”、“mango”和“pear”。注意到第四个字符串“mango”,它实际表示的是一个字符串“mango”,不过它的前三个字符“man”通过b标签来描述为粗体的,而后两个字符通过i标签来描述为斜体的。这样实际上在整个字符串资源池中,包含了七个字符串,分别是"apple"、“banana”、“orange”、“mango”、“pear”、“b”和“i”,其中,第四个字符串“mango”来有两个sytle,第一个style表示第1到第3个字符是粗体的,第二个style表示第4到第5个字符是斜体的。
字符串与其样式描述是一一对应的,也就是说,如果第i个字符串是带有样式描述的,那么它的样式描述就位于样式内容块第i个位置上。以上面的字符串资源池为例,由于第4个字符中带有样式描述,为了保持字符串与样式描述的一一对应关系,那么也需要假设前面3个字符串也带有样式描述的,不过需要将这3个字符串的样式描述的个数设置为0。也就是说,在这种情况下,字符串的个数等于7,而样式描述的个数等于4,其中,第1到第3个字符串的样式描述的个数等于0,而第4个字符串的样式描述的个数等于2。
假设一个字符串有N个样式描述,那么它在样式内容块中,就对应有N个ResStringPool_span,以及一个ResStringPool_ref,其中,N个ResStringPool_span位于前面,用来描述每一个样式,而ResStringPool_ref表示一个结束占位符。例如,对于上述的“mango”字符串来说,它就对应有2个ResStringPool_span,以及1个ResStringPool_ref,而对于"apple"、“banana”和“orange”这三个字符串来说,它们对应有0个ResStringPool_span,但是对应有1个ResStringPool_ref,最后三个字符串“pear”、“b”和"i"对应有0个ResStringPool_span和0个ResStringPool_ref。
由于ResStringPool_ref在这里出现的作用就是充当样式描述结束占位符,因此,它唯一的成员变量index的取值就固定为ResStringPool_span::END。
再来看ResStringPool_span是如何表示一个样式描述的。以字符串“mango”的第一个样式描述为例,对应的ResStringPool_span的各个成员变量的取值为:
- name:等于字符串“b”在字符串资源池中的位置。
- firstChar:等于0,即指向字符“m”。
- lastChar:等于2,即指向字符"n"。
综合起来就是表示字符串“man”是粗体的。
再以字符串“mango”的第二个样式描述为例,对应的ResStringPool_span的各个成员变量的取值为:
- name:等于字符串“i”在字符串资源池中的位置。
- firstChar:等于3,即指向字符“g”。
- lastChar:等于4,即指向字符“o”。
综合起来就是表示字符串“go”是斜体的。
另外有一个地方需要注意的是,字符串样式内容的最后会有8个字节,每4个字节都被填充为ResStringPool_span::END,用来表达字符串样式内容结束符。这个结束符可以在解析过程中用作错误验证。
Step 5. 写入资源ID
在前面的Step 1中,我们把属性的资源ID都收集起来了。这些收集起来的资源ID会作为一个单独的chunk写入到最终的二进制Xml文件中去。这个chunk位于字符串资源池的后面,它的头部使用ResChunk_header来描述。这个ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_RESOURCE_MAP_TYPE,表示这是一个从字符串资源池到资源ID的映射头部。
- headerSize:等于sizeof(ResChunk_header),表示头部大小。
- size:等于headerSize的大小再加上sizeof(uint32_t) * count,其中,count为收集到的资源ID的个数。
以main.xml为例,字符串资源池的第一个字符串为“orientation”,而在资源ID这个chunk中记录的第一个数据为0x010100c4,那么就表示属性名称字符串“orientation”对应的资源ID为0x010100c4。
Step 6. 压平Xml文件
压平Xml文件其实就是指将里面的各个Xml元素中的字符串都替换掉。这些字符串要么是被替换成到字符串资源池的一个索引,要么是替换成一个具有类型的其它值。我们以main.xml为例来说这个压平的过程。
首先被压平的是一个表示命名空间的Xml Node。这个Xml Node用两个ResXMLTree_node和两个ResXMLTree_namespaceExt来表示,如图所示:

对于main.xml文件来说,在它的命名空间chunk中,内嵌在第一个ResXMLTree_node里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_START_NAMESPACE_TYPE,表示命名空间开始标签的头部。
- headerSize:等于sizeof(ResXMLTree_node),表示头部的大小。
- size:等于sizeof(ResXMLTree_node) + sizeof(ResXMLTree_namespaceExt)。
第一个ResXMLTree_node的其余成员变量的取值如下所示:
- lineNumber:等于命名空间开始标签在原来文本格式的Xml文件出现的行号。
- comment:等于命名空间的注释在字符池资源池的索引。
内嵌在第二个ResXMLTree_node里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_END_NAMESPACE_TYPE,表示命名空间结束标签的头部。
- headerSize:等于sizeof(ResXMLTree_node),表示头部的大小。
- size:等于sizeof(ResXMLTree_node) + sizeof(ResXMLTree_namespaceExt)。
第二个ResXMLTree_node的其余成员变量的取值如下所示:
- lineNumber:等于命名空间结束标签在原来文本格式的Xml文件出现的行号。
- comment:等于0xffffffff,即-1。
两个ResXMLTree_namespaceExt的内容都是一样的,它们的成员变量的取值如下所示:
- prefix:等于字符串“android”在字符串资源池中的索引。
- uri:等于字符串“http://schemas.android.com/apk/res/android” 在字符串资源池中的索引。
接下来被压平的是标签为LinearLayout的Xml Node。这个Xml Node由两个ResXMLTree_node、一个ResXMLTree_attrExt、一个ResXMLTree_endElementExt和四个ResXMLTree_attribute来表示,如图所示:

内嵌在第一个ResXMLTree_node里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_START_ELEMENT_TYPE,表示LinearLayout开始标签的头部。
- headerSize:等于sizeof(ResXMLTree_node),表示头部的大小。
- size:等于sizeof(ResXMLTree_node) + sizeof(ResXMLTree_attrExt) + sizeof(ResXMLTree_attribute) * 4。
第一个ResXMLTree_node的其余成员变量的取值如下所示:
- lineNumber:等于LinearLayout开始标签在原来文本格式的Xml文件出现的行号。
- comment:等于LinearLayout标签的注释在字符池资源池的索引。
ResXMLTree_attrExt的各个成员变量的取值如下所示:
- ns:等于LinearLayout元素的命令空间在字符池资源池的索引,没有指定则等于-1。
- name:等于字符串“LinearLayout”在字符池资源池的索引。
- attributeStart:等于sizeof(ResXMLTree_attrExt),表示LinearLayout的属性chunk相对type值为RES_XML_START_ELEMENT_TYPE的ResXMLTree_node头部的位置。
- attributeSize:等于sizeof(ResXMLTree_attribute),表示每一个属性占据的chunk大小。
- attributeCount:等于4,表示有4个属性chunk。
- idIndex:如果LinearLayout元素有一个名称为“id”的属性,那么就将它出现在属性列表中的位置再加上1的值记录在idIndex中,否则的话,idIndex的值就等于0。
- classIndex:如果LinearLayout元素有一个名称为“class”的属性,那么就将它出现在属性列表中的位置再加上1的值记录在classIndex中,否则的话,classIndex的值就等于0。
- styleIndex:如果LinearLayout元素有一个名称为“style”的属性,那么就将它出现在属性列表中的位置再加上1的值记录在styleIndex中,否则的话,styleIndex的值就等于0。
LinearLayout元素有四个属性,每一个属性都对应一个ResXMLTree_attribute,接下来我们就以名称为“orientation”的属性为例,来说明它的各个成员变量的取值,如下所示:
- ns:等于属性orientation的命令空间在字符池资源池的索引,没有指定则等于-1。
- name:等于属性名称字符串“orientation”在字符池资源池的索引。
- rawValue:等于属性orientation的原始值“vertical”在字符池资源池的索引,这是可选的,如果不用保留,它的值就等于-1。
名称为“orientation”的ResXMLTree_attribute的成员变量typedValue是一个Res_value,一个属性的值经过解析之后,也就是经过前面编译Xml资源的第3个操作之后,就用一个Res_value来表示。 例如,对于名称为“orientation”的属性的值“vertical”来说,经过解析之后,它就会用一个Res_value来表示,这个Res_value的各个成员变量的值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留给以后用。
- dataType:等于TYPE_INT_DEC,表示数据类型,即这是一个十进制形式的整数值。
- data:等于1,参考前面编译Xml资源的第3个操作。
更多的数据类型,请参考Res_value定义里面的注释。从这里我们就可以看出,在解析二进制格式的Xml文件的过程中,当我们知道一个属性的名称在字符串资源池的索引之后,就可以通过这个索引在字符串资源池中找到对应的属性名称字符中,同时,通过这个索引还可以在资源ID的那块chunk中找到对应的属性资源ID,而有了这个属性资源ID之后,我们就可以进一步地验证该属性的取值是否正确等操作。
内嵌在第二个ResXMLTree_node里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_END_ELEMENT_TYPE,表示LinearLayout结束标签的头部。
- headerSize:等于sizeof(ResXMLTree_node),表示头部的大小。
- size:等于sizeof(ResXMLTree_node) + sizeof(ResXMLTree_endElementExt) 。
第二个ResXMLTree_node的其余成员变量的取值如下所示:
- lineNumber:等于LinearLayout结束标签在原来文本格式的Xml文件出现的行号。
- comment:等于-1。
ResXMLTree_endElementExt的各个成员变量的取值如下所示:
- ns:等于LinearLayout元素的命令空间在字符池资源池的索引,没有指定则等于-1。
- name:等于字符串“LinearLayout”在字符池资源池的索引。
注意,位于名称为“gravity”的ResXMLTree_attribute和第二个ResXMLTree_node之间的chunk是用来写入LinearLayout元素的两个子元素Button的内容的。这两个Button与LinearLayout一样,都是以相同的结构递归写入到最终的二进制Xml文件中去的,区别只在于结构内容的不同,以及属性个数的不同。例如,对于第一个Button的属性id来说,它所对应的ResXMLTree_attribute的成员变量typedValue所指向的一个Res_value的各个成员变量的值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留给以后用。
- dataType:等于TYPE_REFERENCE,表示数据类型,即这是一个引用值。
- data:等于分配给名称为“button_start_in_process”的ID的资源ID值,它的Package ID等于0x7f,而Type ID等于0x04,Entry ID取决于它的出现次序。
又如,对于第一个Button的属性text来说,它所对应的ResXMLTree_attribute的成员变量typedValue所指向的一个Res_value的各个成员变量的值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留给以后用。
- dataType:等于TYPE_REFERENCE,表示数据类型,即这是一个引用值。
- data:等于分配给名称“start_in_process”的字符串的资源ID值,它的Package ID等于0x7f,而Type ID等于0x05,Entry ID取决于它的出现次序。
对于一个Xml文件来说,它除了有命名空间和普通标签类型的Node之外,还有一些称为CDATA类型的Node,例如,假设一个Xml文件,它的一个Item标签的内容如下所示:
......
<Item>This is a normal text</Item>
......
那么字符串“This is a normal text”就称为一个CDATA,它在二进制Xml文件中用一个ResXMLTree_node和一个ResXMLTree_cdataExt来描述,如图所示:

内嵌在上面的ResXMLTree_node的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_XML_CDATA_TYPE,表示CDATA头部。
- headerSize:等于sizeof(ResXMLTree_node),表示头部的大小。
- size:等于sizeof(ResXMLTree_node) + sizeof(ResXMLTree_cdataExt) 。
上面的ResXMLTree_node的其余成员变量的取值如下所示:
- lineNumber:等于字符串“This is a normal text”在原来文本格式的Xml文件出现的行号。
- comment:等于字符串“This is a normal text”的注释,如果没有则等于-1。
下面的ResXMLTree_cdataExt的成员变量data等于字符串“This is a normal text”在字符串资源池的索引,另外一个成员变量typedData所指向的一个Res_value的各个成员变量的值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留给以后用。
- dataType:等于TYPE_NULL,表示没有包含数据,数据已经包含在ResXMLTree_cdataExt的成员变量data中。
- data:等于0,由于dataType等于TYPE_NULL,这个值是没有意义的。
当所有的Xml文件都编译完成之后,接下来就开始生成资源符号了。
八、生成资源符号
这里生成资源符号为后面生成R.java文件做好准备的。从前面的操作可以知道,所有收集到的资源项都按照类型来保存在一个资源表中,即保存在一个ResourceTable对象。因此,Android资源打包工具aapt只要遍历每一个Package里面的每一个Type,然后取出每一个Entry的名称,并且根据这个Entry在自己的Type里面出现的次序来计算得到它的资源ID,那么就可以生成一个资源符号了,这个资源符号由名称以及资源ID所组成。
例如,对于strings.xml文件中名称为“start_in_process”的Entry来说,它是一个类型为string的资源项,假设它出现的次序为第3,那么它的资源符号就等于R.string.start_in_process,对应的资源ID就为0x7f050002,其中,高字节0x7f表示Package ID,次高字节0x05表示string的Type ID,而低两字节0x02就表示“start_in_process”是第三个出现的字符串。
九、生成资源索引表
经过上述八个操作之后,所获得的资源列表如图所示:

有了这些资源项之后,Android资源打包工具aapt就可以按照下面的流程来生成资源索引表resources.arsc了,如图所示:

1、收集类型字符串
在收集到的资源项中,一共有4种类型的资源,分别是drawable、layout、string和id,于是对应的类型字符串就为“drawable”、“layout”、“string”和“id”。
注意,这些字符串是按Package来收集的,也就是说,当前被编译的应用程序资源有几个Package,就有几组对应的类型字符串,每一个组类型字符串都保存在其所属的Package中。
2、收集资源项名称字符串
在收集到的资源项中,一共有12个资源项,每一个资源项的名称分别为“icon”、“icon”、“icon”、“main”、“sub”、“app_name”、“sub_activity”、“start_in_process”、“start_in_new_process”、“finish”、“button_start_in_process”和“button_start_in_new_process”,于是收集到的资源项名称字符串就为“icon”、“main”、“sub”、“app_name”、“sub_activity”、“start_in_process”、“start_in_new_process”、“finish”、“button_start_in_process”和“button_start_in_new_process”。
注意,这些字符串同样是按Package来收集的,也就是说,当前被编译的应用程序资源有几个Package,就有几组对应的资源项名称字符串,每一个组资源项名称字符串都保存在其所属的Package中。
3、收集资源项值字符串
在收集到的资源项中,一共有12个资源项,但是只有10项是具有值字符串的,它们分别是“res/drawable-ldpi/icon.png”、“res/drawable-mdpi/icon.png”、“res/drawable-hdpi/icon.png”、“res/layout/main.xml”、“res/layout/sub.xml”、“Activity”、“Sub Activity”、“Start sub-activity in process”、“Start sub-activity in new process”和“Finish activity”。
注意,这些字符串不是按Package来收集的,也就是说,当前所有参与编译的Package的资源项值字符串都会被统一收集在一起。
4、生成Package数据块
参与编译的每一个Package的资源项元信息都写在一块独立的数据上,这个数据块使用一个类型为ResTable_package的头部来描述。每一个Package的资源项元信息数据块的生成过程如图所示:
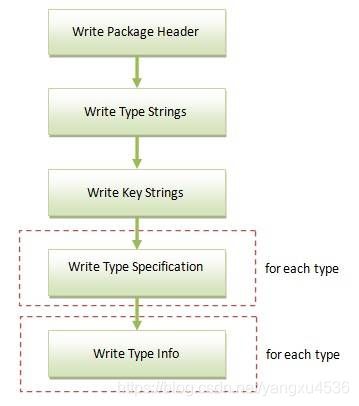
Step 1. 写入Package资源项元信息数据块头部
Package资源项元信息数据块头部是用一个ResTable_package来定义的。嵌入在ResTable_package内部的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_TABLE_PACKAGE_TYPE,表示这是一个Package资源项元信息数据块头部。
- headerSize:等于sizeof(ResTable_package),表示头部大小。
- size:等于sizeof(ResTable_package) + 类型字符串资源池大小 + 资源项名称字符串资源池大小 + 类型规范数据块大小 + 数据项信息数据块大小。
ResTable_package的其它成员变量的取值如下所示:
- id:等于Package ID。
- name:等于Package Name。
- typeStrings:等于类型字符串资源池相对头部的偏移位置。
- lastPublicType:等于最后一个导出的Public类型字符串在类型字符串资源池中的索引,目前这个值设置为类型字符串资源池的大小。
- keyStrings:等于资源项名称字符串相对头部的偏移位置。
- lastPublicKey:等于最后一个导出的Public资源项名称字符串在资源项名称字符串资源池中的索引,目前这个值设置为资源项名称字符串资源池的大小。
我们可以通过下图来清楚地看到一个Package资源项元信息数据块的结构:

在Android资源中,有一种资源类型称为Public,它们一般是定义在res/values/public.xml文件中,形式如下所示:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<public type="string" name="string3" id="0x7f040001" />
</resources>
这个public.xml用来告诉Android资源打包工具aapt,将类型为string的资源string3的ID固定为0x7f040001。为什么需要将某一个资源项的ID固定下来呢?一般来说,当我们将自己定义的资源导出来给第三方应用程序使用时,为了保证以后修改这些导出资源时,仍然保证第三方应用程序的兼容性,就需要给那些导出资源一个固定的资源ID。
每当Android资源打包工具aapt重新编译被修改过的资源时,都会重新给这些资源赋予ID,这就可能会造成同一个资源项在两次不同的编译中被赋予不同的ID。这种情况就会给第三方应用程序程序带来麻烦,因为后者一般是假设一个ID对应的永远是同一个资源的。因此,当我们将自己定义的资源导出来给第三方应用程序使用时,就需要通过public.xml文件将导出来的资源的ID固定下来。
注意,我们在开发应用程序时,一般是不需要用到public.xml文件的,因为我们的资源基本上都是在内部使用的,不会导出来给第三方应用程序使用。只在内部使用的资源,不管它的ID如何变化,我们都可以通过R.java文件定义的常量来正确地引用它们。只有系统定义的资源包才会使用到public.xml文件,因为它定义的资源是需要提供给第三方应用程序使用的。
Step 2. 写入类型字符串资源池
在前面的第1个操作中,我们已经将每一个Package用到的类型字符串收集起来了,因此,这里就可以直接将它们写入到Package资源项元信息数据块头部后面的那个数据块去。
Step 3. 写入资源项名称字符串资源池
在前面的第2个操作中,我们已经将每一个Package用到的资源项名称字符串收集起来了,这里就可以直接将它们写入到类型字符串资源池后面的那个数据块去。
Step 4. 写入类型规范数据块
类型规范数据块用来描述资源项的配置差异性。通过这个差异性描述,我们就可以知道每一个资源项的配置状况。知道了一个资源项的配置状况之后,Android资源管理框架在检测到设备的配置信息发生变化之后,就可以知道是否需要重新加载该资源项。类型规范数据块是按照类型来组织的,也就是说,每一种类型都对应有一个类型规范数据块。
类型规范数据块的头部是用一个ResTable_typeSpec来定义的。嵌入在ResTable_typeSpec里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_TABLE_TYPE_SPEC_TYPE,用来描述一个类型规范头部。
- headerSize:等于sizeof(ResTable_typeSpec),表示头部的大小。
- size:等于sizeof(ResTable_typeSpec) + sizeof(uint32_t) * entryCount,其中,entryCount表示本类型的资源项个数。
ResTable_typeSpec的其它成员变量的取值如下所示:
- id:表示资源的Type ID。
- res0:等于0,保留以后使用。
- res1:等于0,保留以后使用。
- entryCount:等于本类型的资源项个数,注意,这里是指名称相同的资源项的个数。
ResTable_typeSpec后面紧跟着的是一个大小为entryCount的uint32_t数组,每一个数组元数,即每一个uint32_t,都是用来描述一个资源项的配置差异性的。例如,名称为icon的drawable资源项有三种不同的屏幕配置ldpi、mdpi和hdpi,于是用来描述它的配置差异性的uint32_t的第CONFIG_DENSITY位就等于1,而其余位都等于0。又如,名称为main的layout资源项只有一种配置default,于是用来描述它的配置差异性的uint32_t的值就等于0。此外,如果一个资源项是导出的,即它的资源ID是通过public.xml来固定的,那么用来描述它的配置差异性的uint32_t的第ResTable_typeSpec::SPEC_PUBLIC位也会被设置为1。
类型为drawable的规范数据块:

类型为layout的规范数据块:
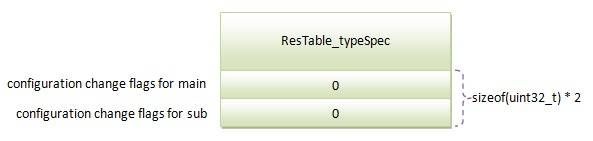
类型为string的规范数据块:

类型为id的规范数据块:

类型为drawable的资源项icon在设备的屏幕密度发生变化之后,Android资源管理框架需要重新对它进行加载,以便获得更合适的资源项,而其它资源项无论设备配置信息发生何种变化,它们都不需要重新加载,因为它们只有一种配置。
Step 5. 写入类型资源项数据块
类型资源项数据块用来描述资源项的具体信息, 这样我们就可以知道每一个资源项名称、值和配置等信息。类型资源项数据同样是按照类型和配置来组织的,也就是说,一个具有N个配置的类型一共对应有N个类型资源项数据块。
类型资源项数据块的头部是用一个ResTable_type来定义的。嵌入在ResTable_type里面的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_TABLE_TYPE_TYPE,用来描述一个类型资源项头部。
- headerSize:等于sizeof(ResTable_type),表示头部的大小。
- size:等于sizeof(ResTable_type) + sizeof(uint32_t) * entryCount,其中,entryCount表示本类型的资源项个数。
ResTable_type的其它成员变量的取值如下所示:
- id:表示资源的Type ID。
- res0:等于0,保留以后使用。
- res1:等于0,保留以后使用。
- entryCount:等于本类型的资源项个数,注意,这里是指名称相同的资源项的个数。
- entriesStart:等于资源项数据块相对头部的偏移值。
- config:指向一个ResTable_config,用来描述配置信息。
ResTable_type紧跟着的是一个大小为entryCount的uint32_t数组,每一个数组元数,即每一个uint32_t,都是用来描述一个资源项数据块的偏移位置。紧跟在这个uint32_t数组后面的是一个大小为entryCount的ResTable_entry数组,每一个数组元素,即每一个ResTable_entry,都是用来描述一个资源项的具体信息。
在本文的例子中,一共有4种不同类型的资源项,其中,类型为drawable的资源有1个资源项以及3种不同的配置,类型为layout的资源有2个资源项以及1种配置,类型为string的资源有5个资源项以及1种配置,类型为id的资源有2个资源项以及1种配置,这样一共就对应有3 + 1 + 1 + 1个类型资源项数据块。
类型为drawable和配置为ldpi的资源项数据块:

类型为drawable和配置为mdpi的资源项数据块:

类型为drawable和配置为hdpi的资源项数据块:

类型为layout和配置为default的资源项数据块:

类型为string和配置为default的资源项数据块:

类型为id和配置为default的资源项数据块:

注意,ResTable_type后面的uint32_t数组和ResTable_entry数组的大小不一定是相等的,考虑下面的资源目录:
--res
--drawable-ldpi
--icon.png
--drawable-mdpi
--icon.png
--logo.png
--drawable-hdpi
--logo.png
那么最终得到类型为drawable和配置为ldpi的资源项数据块如图所示:

由于不存在类型为drawable、配置为ldpi,并且名称为logo的资源项,因此,ResTable_type后面的uint32_t数组和ResTable_entry数组的大小是不相等的,并且没有相应的ResTable_entry的uint32_t数组元素的值会被设置为ResTable_type::NO_ENTRY。
每一个资源项数据都是通过一个ResTable_entry来定义的。ResTable_entry的各个成员变量的取值如下所示:
- size:等于sizeof(ResTable_entry),表示资源项头部大小。
- flags:资源项标志位。如果是一个Bag资源项,那么FLAG_COMPLEX位就等于1,并且在ResTable_entry后面跟有一个ResTable_map数组,否则的话,在ResTable_entry后面跟的是一个Res_value。如果是一个可以被引用的资源项,那么FLAG_PUBLIC位就等于1。
- key:资源项名称在资源项名称字符串资源池的索引。
接下来我们就分两种情况来讨论资源项信息写入到资源索引表的过程。首先看一个普通的资源项,即一个非Bag资源项的写入过程。每一个资源项的数据都是用一个Item来描述的。在这个Item中,有一个类型为Res_value的成员变量parsedValue,它表示一个资源项经过解析后得到值。前面在分析Xml资源文件的编译过程时,我们已经介绍过Res_value的定义了。假设当前要写入的资源项是类型为layout的main,它的值是一个字符串“res/layout/main.xml”。字符串“res/layout/main.xml”在前面的第3步中已经被写入到一个资源项值字符串池中去了,我们假设它被写入在第3个位置上,那么用来描述资源项main的Res_value的各个成员变量的取值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留以后使用。
- dataType:等于TYPE_STRING。
- data:等于0x3。
普通资源项写入到资源索引表的数据块结构:

接着看一个Bag资源项的写入过程。以Bag资源项custom_orientation为例,它有本个bag,分别是type、custom_vertical和custom_horizontal,其中,custom_vertical和custom_horizontal是两个自定义的bag,它们的值分别等于0x0和0x1,而type是一个系统内部定义的bag,它的值固定为0x10000。 注意,^type、custom_vertical和custom_horizontal均是类型为id的资源,假设它们分配的资源ID分别为0x1000000、0x7f040000和7f040001。
Bag资源项写入到资源索引表的数据块结构:

紧跟在ResTable_entry后面的是一个ResTable_map_entry,用来描述后面要写入到的ResTable_map的信息。假设一个Bag资源项有N个bag,那么在ResTable_map_entry就有N个ResTable_map。
ResTable_map_entry是从ResTable_entry继承下来的,我们首先看ResTable_entry的各个成员变量的取值:
- size:等于sizeof(ResTable_map_entry)。
- flags:由于在紧跟在ResTable_map_entry前面的ResTable_entry的成员变量flags已经描述过资源项的标志位了,因此,这里的flags就不用再设置了,它的值等于0。
- key:由于在紧跟在ResTable_map_entry前面的ResTable_entry的成员变量key已经描述过资源项的名称了,因此,这里的key就不用再设置了,它的值等于0。
ResTable_map_entry的各个成员变量的取值如下所示:
- parent:指向父ResTable_map_entry的资源ID,如果没有父ResTable_map_entry,则等于0。
- count:等于bag项的个数。
Bag资源项的每一个bag都用一个ResTable_map来表示。ResTable_map只有两个成员变量,其中:
- name:等于bag的资源项ID。
- value:等于bag的资源项值。
例如,对于custom_vertical来说,用来描述它的ResTable_map的成员变量name的值就等于0x7f040000,而成员变量value所指向的一个Res_value的各个成员变量的值如下所示:
- size:等于sizeof(Res_value)。
- res0:等于0,保留以后使用。
- dataType:等于TYPE_INT_DEC,表示data是一个十进制的整数。
- data:等于0。
我们可以依此类推,分别得到用来描述^type和custom_horizontal这两个bag的ResTable_map的值。
5、写入资源索引表头部
资源索引表头部使用一个ResTable_header来表示。嵌入在ResTable_header内部的ResChunk_header的各个成员变量的取值如下所示:
- type:等于RES_TABLE_TYPE,表示这是一个资源索引表头部。
- headerSize:等于sizeof(ResTable_header),表示头部的大小。
- size:等于整个resources.arsc文件的大小。
ResTable_header的其它成员变量的取值如下所示:
- packageCount:等于被编译的资源包的个数。
6、写入资源项的值字符串资源池
在前面的第3步中,我们已经将所有的资源项的值字符串都收集起来了,因此,这里直接它们写入到资源索引表去就可以了。注意,这个字符串资源池包含了在所有的资源包里面所定义的资源项的值字符串,并且是紧跟在资源索引表头部的后面。
7、写入Package数据块
在前面的第4步中,我们已经所有的Package数据块都收集起来了,因此,这里直接将它们写入到资源索引表去就可以了。这些Package数据块是依次写入到资源索引表去的,并且是紧跟在资源项的值字符串资源池的后面。
至此,资源项索引表的生成好了。
十、编译AndroidManifest.xml文件
经过前面的九个步骤之后,应用程序的所有资源项就编译完成了,这时候就开始将应用程序的配置文件AndroidManifest.xml也编译成二进制格式的Xml文件。之所以要在应用程序的所有资源项都编译完成之后,再编译应用程序的配置文件,是因为后者可能会引用到前者。
应用程序配置文件AndroidManifest.xml的编译过程与其它的Xml资源文件的编译过程是一样的,可以参考前面的第七步。注意,应用程序配置文件AndroidManifest.xml编译完成之后,Android资源打包工具appt还会验证它的完整性和正确性,例如,验证AndroidManifest.xml的根节点mainfest必须定义有android:package属性。
十一、生成R.java文件
在前面的第八步中,我们已经将所有的资源项及其所对应的资源ID都收集起来了,因此,这里只要将直接将它们写入到指定的R.java文件去就可以了。例如,假设分配给类型为layout的资源项main和sub的ID为0x7f030000和0x7f030001,那么在R.java文件,就会分别有两个以main和sub为名称的常量,如下所示:
public final class R {
......
public static final class layout {
public static final int main=0x7f030000;
public static final int sub=0x7f030001;
}
......
}
注意,每一个资源类型在R.java文件中,都有一个对应的内部类,例如,类型为layout的资源项在R.java文件中对应的内部类为layout,而类型为string的资源项在R.java文件中对应的内部类就为string。
十二、打包APK文件
所有资源文件都编译以及生成完成之后,就可以将它们打包到APK文件去了,包括:
- assets目录。
- res目录,但是不包括res/values目录, 这是因为res/values目录下的资源文件的内容经过编译之后,都直接写入到资源项索引表去了。
- 资源项索引文件resources.arsc。
当然,除了这些资源文件外,应用程序的配置文件AndroidManifest.xml以及应用程序代码文件classes.dex,还有用来描述应用程序的签名信息的文件,也会一并被打包到APK文件中去,这个APK文件可以直接拿到模拟器或者设备上去安装。
至此,我们就分析完成Android应用程序资源的编译和打包过程了。