GAN网络评估指标:IS、FID、PPL
GAN网络评估指标:IS、FID、PPL
转自:IS、FID、PPL,GAN网络评估指标
另外关于GAN的评价指标,推荐李宏毅老师的视频:【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (三) – 生成器效能評估與條件式生成
0 图形生成指标的要求
众所周知,评价生成模型最基本的要考虑以下两方面
- 生成的图片是否清晰?
- 生成的图片是否多样?即使图片足够清晰,只能生成几种图片的网络(也就是mode collapse)肯定不是好的。
此外可能也要考虑以下几点
- 生成的图片是否和训练数据图片过于相近?比如我设计一个网络,只是简单的拷贝训练数据图片,这样认为也是不好的。
- 生成的图片是否可以平滑的变化?对于从噪声z得到的图片x,如果在z附近取值,应该也是得到近似变化的图片x。
- …
1 Inception Score
1.1 Inception Score的基本思想
基本思想:Inception Score使用图片类别分类器来评估生成图片的质量。其中使用的图片类别分类器为Inception Net-V3。这也是Inception Score名称的由来。
Inception Net-V3 是图片分类器,在ImageNet数据集上训练。ImageNet是由120多万张图片,1000个类别组成的数据集。Inception Net-V3可以对一副图片输出一个1000分类的概率。
清晰度,IS 对于生成的图片 x x x 输入到Inception Net-V3中产生一个1000维的向量 y y y 。其中每一维代表数据某类的概率。对于清晰的图片来说, y y y 的某一维应该接近1,其余维接近0。即对于类别 y y y 来说, p ( y ∣ x ) p(y|x) p(y∣x) 的熵很小(概率比较确定)。
多样性:对于所有的生成图片,应该均匀分布在所有的类别中。比如共生成10000张图片,对于1000类别,每一类应该生成10张图片。即 p ( y ) = ∑ p ( y ∣ x ( i ) ) p(y)=\sum p(y|x^{(i)}) p(y)=∑p(y∣x(i)) 的熵很大,总体分布接近均匀分布。
1.2 Inception Score的公式
直观感受,IS是对生成图片清晰度和多样性的衡量,IS值越大越好。具体公式如下
I S ( G ) = exp ( E x ∼ p g D K L ( p ( y ∣ x ) ∣ ∣ p ( y ) ) ) IS(G)=\exp(\mathbb{E}_{x\sim p_g}D_{KL}(p(y|x)||p(y))) IS(G)=exp(Ex∼pgDKL(p(y∣x)∣∣p(y)))
其中
- exp \exp exp :为了形式更加好看
- E x ∼ p g \mathbb{E}_{x\sim p_g} Ex∼pg :遍历所有的生成样本,求平均值
- D K L D_{KL} DKL :KL散度, D K L ( P ∣ ∣ Q ) D_{KL}(P||Q) DKL(P∣∣Q) 用于衡量分布 P P P 和 Q Q Q 之间的近似程度
- p ( y ∣ x ) p(y|x) p(y∣x) :对于图片 x x x,属于所有类别的概率分布。对于给定图片 x x x,表示为一个1000维数向量。
- p ( y ) p(y) p(y) :边缘概率,具体实现为对于所有的验证图片 x x x,计算得到 p ( y ∣ x ) p(y|x) p(y∣x) ,再求所有向量平均值。
我们希望生成的图片,足够清晰且生成类别多样,所有IS越大越好。并且对于Inception Net-V3由于是1000分类任务,所以 I S ( G ) IS(G) IS(G) 有最大值 I S ( G ) ≤ 1000 IS(G)≤1000 IS(G)≤1000 。
1.3 Inception Score的问题
(1)数据集问题
Inception Score是基于Inception Net-V3得出的,而Inception Net-V3是在ImageNet上1000分类任务。所以生成模型应该也是在ImageNet上训练,生成ImageNet相似图片。
不能生成任意的图片,而直接套用Inception Net-V3。
比如说,使用Inception Net-V3来计算 p ( y ∣ x ) p(y|x) p(y∣x) 的熵,在ImageNet上计算结果为1.97bit。在CIFAR-10上计算结果是4.664bit,在随机噪声图片上计算结果是6.512bit。
可以看出真实的图片数据集CIFAR-10居然和随机噪声图片的结果相近这是不科学的。
总结:不能使用在一个数据集上训练分类模型,评估在另一个数据集上训练的生成模型
(2)Inception Score敏感性问题
使用pytorch、tensorflow、keras等不同框架下的Inception Net权值,在同样的分类精度下,计算同一个数据集的IS。IS的差别很大,仅仅由于使用的框架不同,IS分值可以相差11.5%。
总结:神经网络中权值的细节改变可能很大的影响IS分数
(3)Inception Score高的图片不一定真实
由于Inception Score是根据分类器进行给分,我们可以根据分类器的结果来进行刷分。刷分的关键是全体图片的类别要多样,其中具体一副图片,分类器计算出的熵要比较低。
比如我现有数据集50000张,取第1张图片,使用Inception Net-V3计算分类概率,要使图片第1类概率达到最大。使用梯度下降,对图片进行更新,直到第一类概率极大。如此对第2图片强行调整至符合第2类…遍历所有的图片之后,在1000类中,每一类有10张图片,且每张图片的分类概率都很明确。但这样生成的图片大概率是不真实的
(4)Inception Score低的图片不一定差
如果我给出一张真实的图片,但并不属于Inception Net-V3的1000分类中的任何一类。分类器无法判别,那么Inception Score分数不高,但图像是真实的。
(6)Inception Score的多样性检验有局限性
Inception Score检测生成图片是否多样,是根据生成的类别进行检验判断。如果我的模型输出图片,类别是平均分配的。但每一类中,图片都一样,也就是mode collapse。这种情况Inception Score是无法检测的
(6)Inception Score不能反映过拟合
如果我的神经网络只是单纯的拷贝训练集的图片,那么Inception Score肯定是很高的,但这样的生成模型是没有意义的。
总结:Inception Score得分过于依赖分类器,是一种间接的对图片质量评估的方法,没有考虑真实数据与生成数据的具体差异。Inception Score是基于ImageNet得到的,在IS看来,凡是不像ImageNet的数据,都是不真实的。
2 Fréchet Inception Distance
2.1 Fréchet Inception Distance的基本思想
基本思想:直接考虑生成数据和真实数据在feature层次的距离,不再额外的借助分类器。因此来衡量生成图片和真实图片的距离。
众所周知,预训练好的神经网络在高层可以提取图片的抽象特征。FID使用Inception Net-V3全连接前的2048维向量作为图片的feature。
2.2 Fréchet Inception Distance的公式
直观感受,**FID是反应生成图片和真实图片的距离,数据越小越好。**专业来说,FID是衡量两个多元正态分布的距离,其公式如下:
F I D = ∣ ∣ μ r − μ g ∣ ∣ 2 + T r ( Σ r + Σ g − 2 ( Σ r Σ g ) 1 / 2 ) FID=||\mu_r−\mu_g||^2+Tr(\Sigma_r+\Sigma_g−2(\Sigma_r\Sigma_g)^{1/2}) FID=∣∣μr−μg∣∣2+Tr(Σr+Σg−2(ΣrΣg)1/2)
其中
- μ r \mu_r μr :真实图片的特征均值
- μ g \mu_g μg :生成图片的特征均值
- Σ r \Sigma_r Σr :真实图片的协方差矩阵
- Σ g \Sigma_g Σg :生成图片的协方差矩阵
- T r Tr Tr :迹
2.3 Fréchet Inception Distance的优缺点
(1)Fréchet Inception Distance优点
- 生成模型的训练集可以和Inception Net-V3不同
- 刷分不会导致生成图片质量变差
(2)Fréchet Inception Distance的缺点
- FID是衡量多元正态分布之间的距离,但提取的图片特征不一定是符合多元正态分布的
- 无法解决过拟合问题,如果生成模型只能生成和训练集一模一样的数据无法检测
3 Perceptual Path Length
对生成图片除了要求清晰、多样之外。我们还希望生成模型可以结合不同的训练图片的特征。比如说我取一个人的发型,取另一个人的脸型,然后结合生成一张图片。
也就是生成器能否很好的把不同图片的特征分离出来,论文StyleGAN提出了Perceptual Path Length(PPL)用来评估这个指标。
如何理解生成器把不同图片的特征分离开呢?
首先回顾最初的GAN网络,给定隐空间中的噪声 z ∈ Z z\in Z z∈Z ,通过生成器,可以得到一副图 x = G ( z ) x=G(z) x=G(z) 。优秀的生成器,应该可以把 Z Z Z 空间进行良好划分。
比如说对于生成人脸的生成器,对于任意的噪声向量 z z z 来说,我们希望第一个分量 z 1 z_1 z1 控制人的头发,改变 z 1 z_1 z1 的大小仅仅改变生成图片的头发,希望第二个分离 z 2 z_2 z2 控制人的眉毛形状…那么这个生成器就把隐空间中不同的部分和不同的特征分离开了。
3.1 Perceptual Path Length基本思想
基本思想:给出两个随机噪声 z 1 , z 2 z_1,z_2 z1,z2 ,为求得两点的感知路径长度PPL,采用微分的思想。把两噪声点插值路径细分成多个小段,求每个小段的长度,再求平均
3.2 Perceptual Path Length公式
直观来说,PPL评估利用生成器从一个图片变道另一个图片的距离,越小越好。公式如下
P P L = E [ 1 ϵ 2 d ( G ( s l e r p ( z 1 , z 2 ; t ) ) , G ( s l e r p ( z 1 , z 2 ; t + ϵ ) ) ) ] PPL=\mathbb{E}[\frac{1}{\epsilon^2}d(G(slerp(z_1,z_2;t)),G(slerp(z_1,z_2;t+ϵ)))] PPL=E[ϵ21d(G(slerp(z1,z2;t)),G(slerp(z1,z2;t+ϵ)))]
其中
- ϵ \epsilon ϵ :细分小段,用1e-4代替
- d ( ⋅ , ⋅ ) d(⋅,⋅) d(⋅,⋅) :perceptual distance,使用预训练的VGG来衡量
- G G G :图片生成器
- s l e r p slerp slerp :spherical linear interpolation球面线性插值,一种插值方式
- t ∼ U ( 0 , 1 ) t\sim U(0,1) t∼U(0,1) ,插值参数,服从均匀分布
3.3 理解Perceptual Path Length
具有良好perceptual变化的优秀的GAN网络应该什么样子的?
perceptual是比较抽象的人理解的概念,我们希望GAN网络可以让在欧几里得空间中相近的噪声点,得到的图片也是相近的。如下图
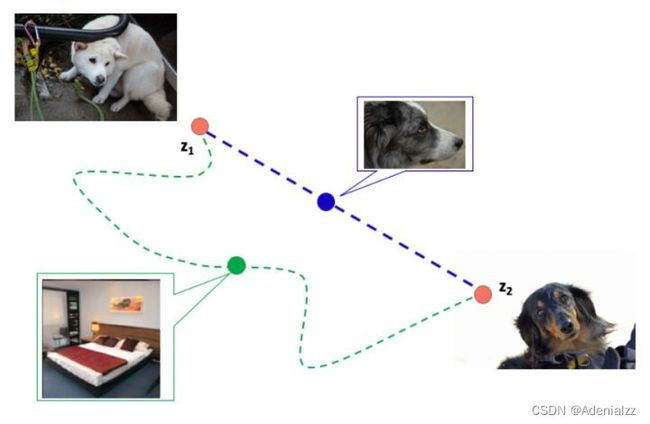
假设上图表示perceptual距离空间。 z 1 z_1 z1 可以生成一张白色的狗, z 2 z_2 z2 可以生成一张黑色的狗。那么我们在 z 1 z_1 z1 和 z 2 z_2 z2 的欧式最短路径上,移动蓝色的点。在优秀的GAN网络中,得到的结果应该是perceptual距离也是最短的(也就是蓝色的线,最短距离)。
绿色的线是比较差的GAN网络,在从白狗向黑狗变化的过程中,变化perceptual过大,出现了卧室。
而PPL就是通过类似曲线积分的方法,计算出perceptual path的长度。比如下图,在两个不同的网络中。 P P L ( t + ϵ 1 ) < P P L ( t + ϵ 2 ) PPL(t+\epsilon_1)
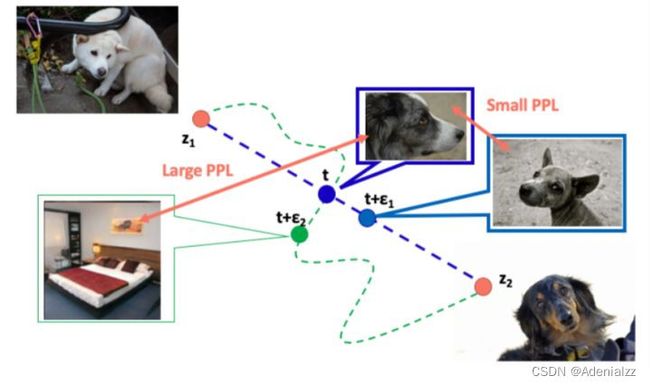
( t + ϵ 1 t+\epsilon_1 t+ϵ1 和 t + ϵ 2 t+\epsilon_2 t+ϵ2 在欧式空间 Z Z Z 中是向一个方向移动,但在perceptual距离空间下,不同的GAN网络可能会向不同的方向移动。)
参考资料
A Note on the Inception Score (arxiv.org)
Inception Score 的原理和局限性 - 知乎 (zhihu.com)
Fréchet Inception Distance (FID) - 知乎 (zhihu.com)
From GAN basic to StyleGAN2. This post describes GAN basic… | by Akihiro FUJII | Analytics Vidhya | Medium