【05】Yarn
125_尚硅谷_Hadoop_Yarn_课程介绍

126_尚硅谷_Hadoop_Yarn_基础架构


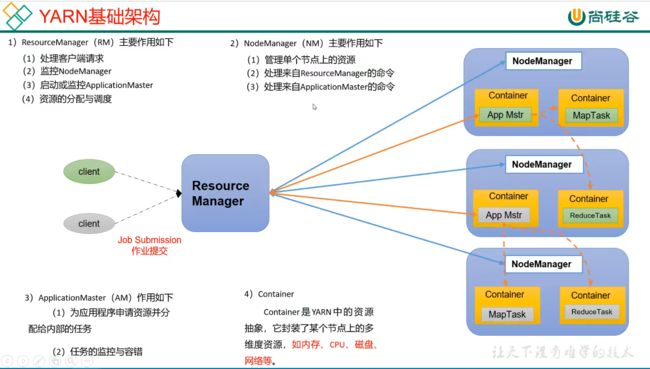
整个集群资源的老大:ResourceManager
单个结点资源的老大:NodeManager
每一个作业任务的老大:ApplicationMaster
相应的容器(相当于一个小电脑):Container
127_尚硅谷_Hadoop_Yarn_工作机制(面试重要)

任何任务的执行都是在容器中执行的(container)
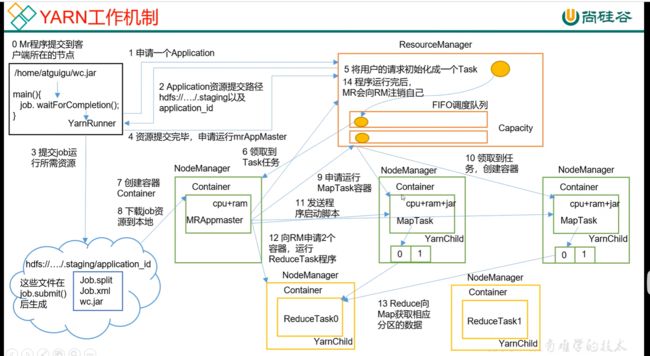
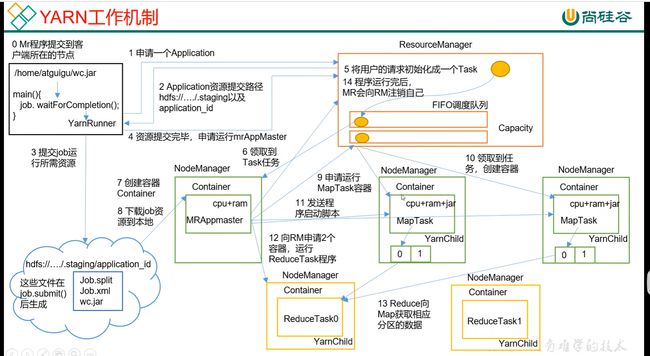
/*
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
*/
NameNode和DataNode是hdfs集群;要注意Hadoop是三大框架的综合体,一个是存储框架,一个是计算框架MR,一个是资源调度框架Yarn
128_尚硅谷_Hadoop_Yarn_全流程作业
管理整个集群资源的是ResourceManager,管理单个结点的资源的是NodeManager

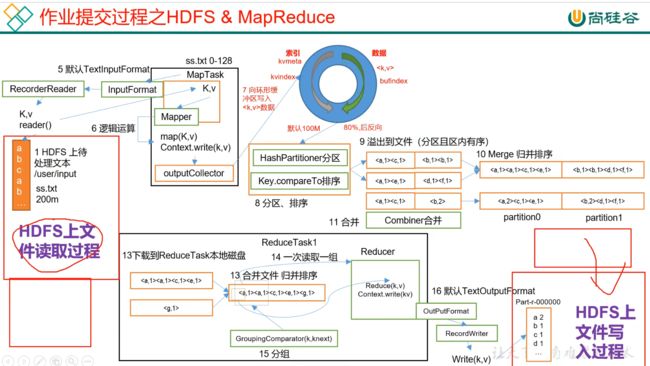
/*
作业提交全过程详解
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
*/
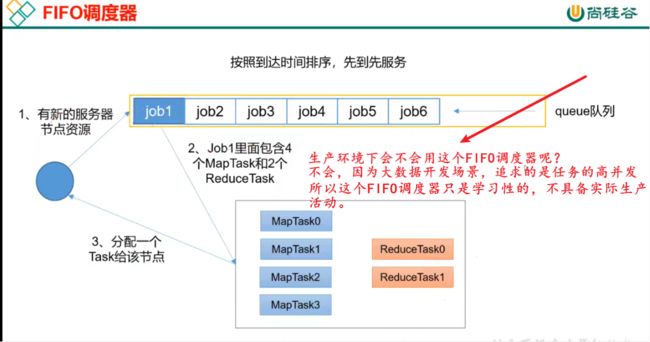
129_尚硅谷_Hadoop_Yarn_FIFO调度器
多个客户端往集群提交任务,任务一多了集群怎么办呢?集群会给它放到任务队列里面,由这个任务队列来管理多个任务。管理的是哪一个任务先执行,还有每个任务分配多少资源以及有多少个任务可以并发执行,都有调度器来解决。

FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
130_尚硅谷_Hadoop_Yarn_容量调度器
优先满足先进来对列的资源,一个对列当中也可启动多个任务。

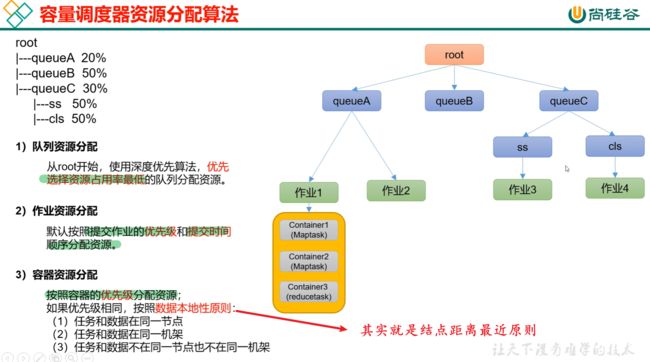
在队列资源分配中,先让耗费最小资源的任务先执行完,然后再重点突击大的任务
131_尚硅谷_Hadoop_Yarin_公平调度器

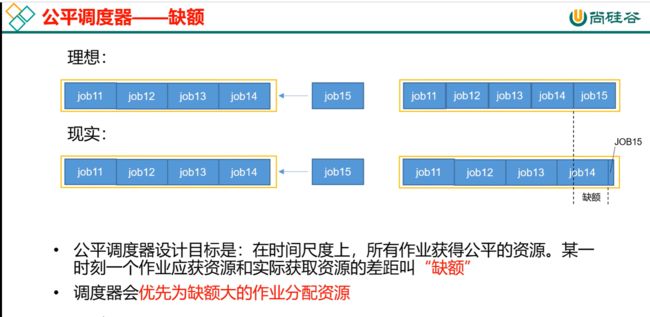
什么是缺额?
job15来了,不能直接给job15分配资源,得给我时间的缓冲,让我把别人的资源抢出来点给你。那在时间上就有个时间差,那这个时间差就叫做差额。

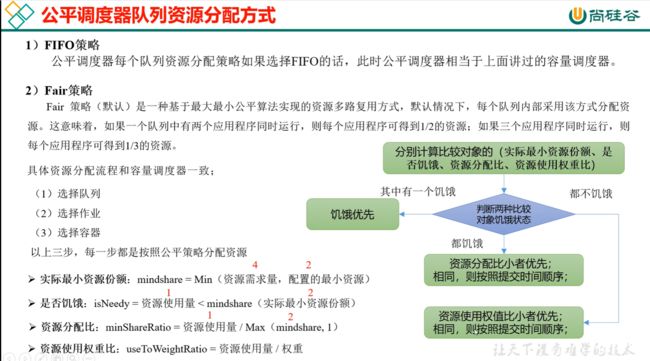
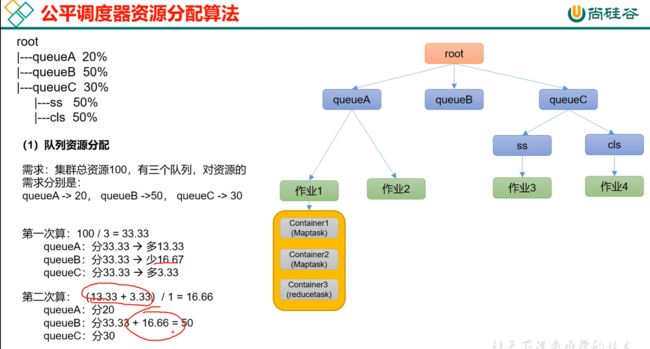
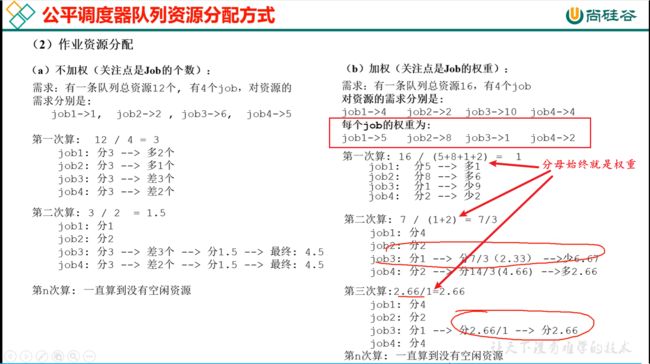
分母始终就是权重

132_尚硅谷_Hadoop_Yarn_常用命令


hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output1
![]()

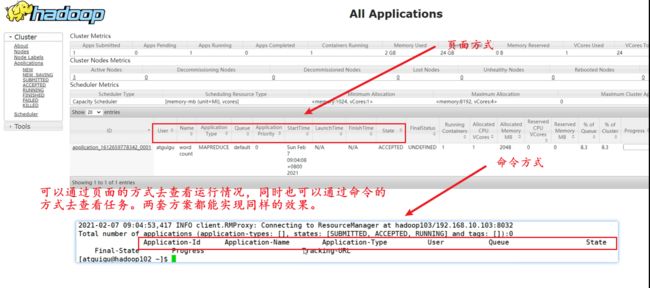
yarn application查看任务:
(1)列出所有Application:
yarn application -list
可以通过页面的方式去查看运行情况,同时也可以通过命令的方式去查看任务。两套方案都能实现同样的效果。
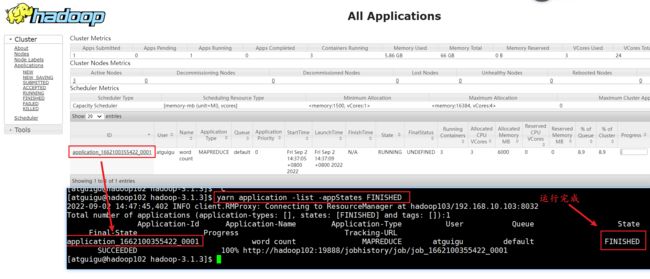
(2)根据Application状态过滤:yarn application -list -appStates (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
yarn application -list -appStates FINISHED

(3)Kill掉Application:
yarn application -kill application_1662100355422_0001
![]()

yarn logs -applicationId application_1662100355422_0001

yarn applicationattempt查看尝试运行的任务
yarn applicationattempt -list application_1662100355422_0001

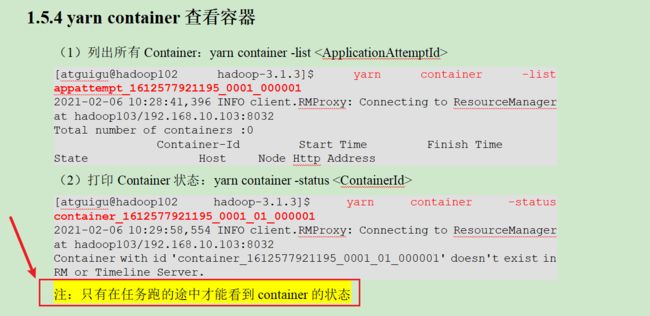
1.5.4 yarn container查看容器(当任务发生异常时,我们可以关注这个container到底发生了什么情况)
yarn applicationattempt -list application_1662100355422_0001 container_1662100355422_0001_01_000001

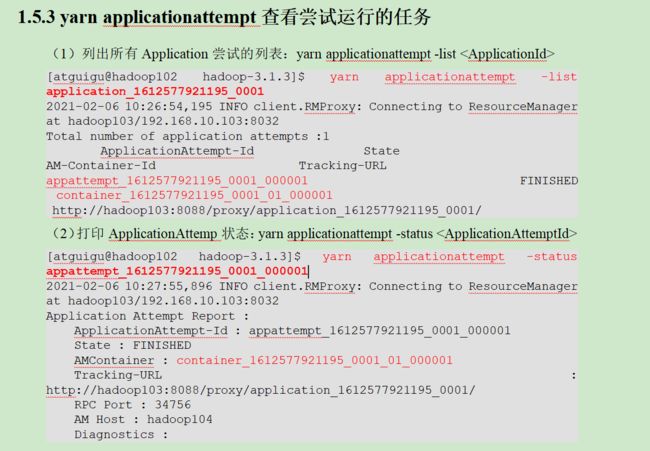
1.5.3 yarn applicationattempt查看尝试运行的任务
(1)列出所有Application尝试的列表:yarn applicationattempt -list
yarn applicationattempt -list application_1662100355422_0001
(2)打印ApplicationAttemp状态:yarn applicationattempt -status
yarn applicationattempt -status appattempt_1662100355422_0001_000001
查看当前这一时刻处于什么状态

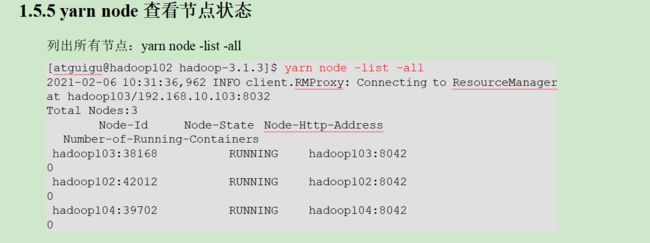

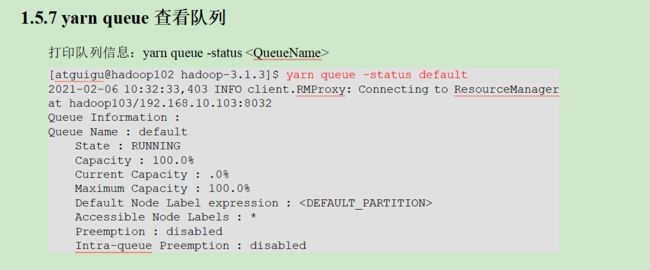
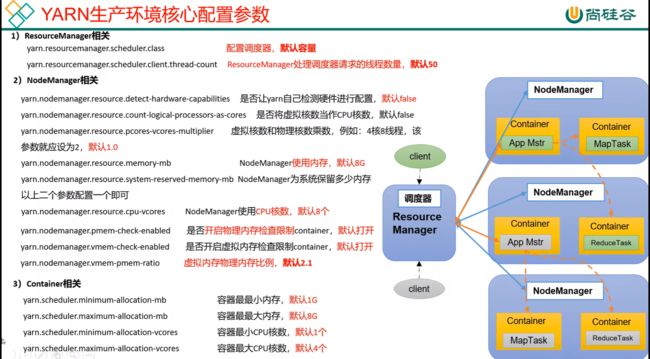
133_尚硅谷_Hadoop_Yarn_生产环境核心参数配置
134_尚硅谷_Hadoop_Yarn_Linux集群快照
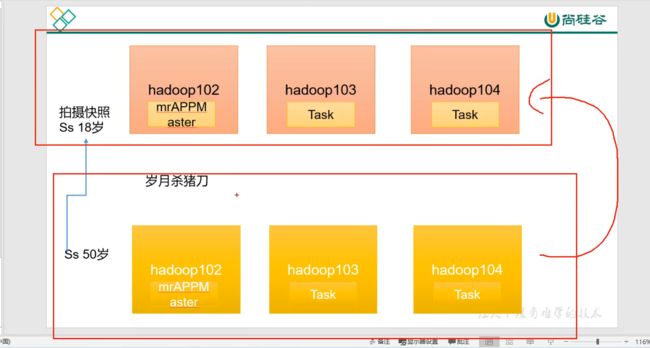
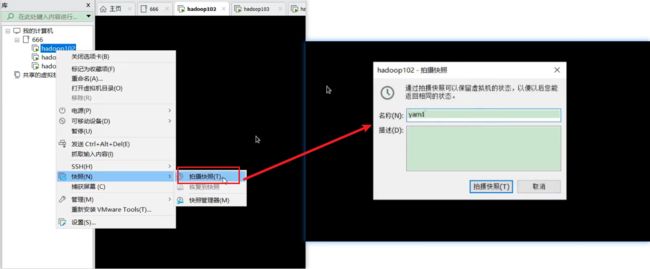
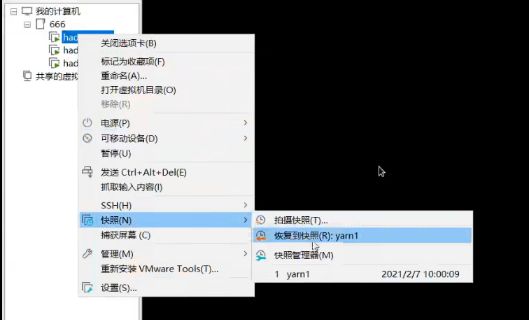
快照要叫备份也可以。如果想恢复到当前这一时刻,可以恢复快照就可以
135_尚硅谷_Hadoop_Yarn_生产环境核心参数配置案例
2.2 容量调度器多队列提交案例
1)在生产环境怎么创建队列?
(1)调度器默认就1个default队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
(3)按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
2)创建多队列的好处?
(1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
(2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。11.11 6.18
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
136_尚硅谷_Hadoop_Yarn_生产环境多队列创建&好处
略
137_尚硅谷_Hadoop_Yarn_容量调度器多队列案例
略
138_尚硅谷_Hadoop_Yarn_容量调度器任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn将所有任务的优先级限制为0,若想使用任务的优先级功能,须开放该限制。
139_尚硅谷_Hadoop_Yarn_公平调度器案例
略
140_尚硅谷_Hadoop_Yarn_Tool接口案例环境准备
略
141_尚硅谷_Hadoop_Yarn_Tool接口案例完成
略
142_尚硅谷_Hadoop_Yarn_课程总结
