dataframe 切片_python数据分析包|Pandas01之DataFrame&Series
"pythonic生物人"的第52篇分享
 。
。
Pandas数据结构DataFrame和Series的常用方法梳理。本文您将学到什么?
1、pandas简介
2、pandas数据结构之-Series
pandas.Series快速创建
pandas.Series取出所有值:values
pandas.Series取出索引:index
pandas.Series类似于numpy.ndarry的性能
pandas.Series通过索引值取值
pandas.Series类似字典(dict)的性能
3、pandas数据结构之-DataFrame
DataFame创建
pandas.DataFrame中取列操作
pandas.DataFrame中取某一列
pandas.DataFrame中取某几列-方法1
pandas.DataFrame中取某几列-方法2
pandas.DataFrame中取行操作
pandas.DataFrame中取某一行
pandas.DataFrame中取某几行
pandas.DataFrame中按一个条件过滤行
pandas.DataFrame中按多个条件过滤行
pandas.DataFrame中结合map 和lambda函数过滤行
pandas.DataFrame中结合isin过滤行
pandas.DataFrame中取某几行中的某几列
pandas.DataFrame中替换值:where方法
pandas.DataFrame中查找某个位置的值:lookup方法
pandas.DataFrame中末尾新增加列
pandas.DataFrame中指定位置新增加列:insert方法
pandas.DataFrame中删除列:del方法
pandas.DataFrame复制:copy方法
pandas.DataFrame查看前几行和末尾几行:head|tail
Series、pandas.DataFrame中某列唯一值的个数:unique
pandas.DataFrame统计列中每个元素出现的频次:value_counts方法
pandas.DataFrame按照某几列分组并统计:groupby+count
pandas.DataFrame按照某列分组并求和
pandas.DataFrame按照某列分组并取出某个小组:groupby+get_group
pandas.DataFrame排序
pandas.DataFrame按照行标签或者列标签排序:sort_index方法
pandas.DataFrame按照某列值排序:sort_values方法by参数
pandas.DataFrame描述统计
pandas.DataFrame获取行列标签/表头名称
正文开始啦
1、pandas简介
- pandas模块是在numpy的基础上构建的,速度快(层算法都用 Cython优化过)、有大量直接操作每个元素的函数;
- 常常和Matplotlib,seaborn,statsmodels,scikit-learn等包一起使用;
- 相比于numpy,pandas更擅长处理表格型(Tabular data)数据,表格中每列数据类型可以不一致,numpy数组规定数据类型需要一致;
- 主要有两种数据结构:一维Series(类似numpy.ndarray)带行标签,二维DataFrame(比R中data.frame更丰富),同时带行标签和列标签;
- 关于pandas的使用可以在这里搜索,点击戳:https://pandas.pydata.org/pandas-docs/stable/reference/index.html 。
- python社区默认将pandas模块简写为pd,导入模块的时候要一起导入pandas的两种数据结构:Series和DataFrame:
In [8]: import pandas as pd
In [9]: from pandas import Series,DataFrame#导入两种数据结构。2、pandas数据结构1-Series
- Series是一个自带标签的一维数组( one-dimensional labeled array),结构图如下:

- Series具有大量属性和函数:
In [27]: len(dir(Series))
Out[27]: 471#方法多大400多种,详细使用如下:详细使用请戳我哦
pandas.Series快速创建
语法:
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
data:python中的字典、可迭代对象、numpy.ndarry或者标量值
index:可选项,默认为列表[0, ..., len(data) - 1],可以自己传入
dtype:可选项,设置数据类型
In [38]: data = pd.Series([1,2,3,4,5])#不指定索引值,默认索引值为[0, ..., len(data) - 1]
In [39]: data
Out[39]:0 11 22 33 44 5
dtype: int64#pandas.Series自定义索引值
In [47]: data1 = pd.Series([1,2,3,4,5],index=list('abcde'))
In [48]: data1
Out[48]:
a 1
b 2
c 3
d 4
e 5
dtype: int64pandas.Series取出所有值:values
返回一个数组。
In [49]: data1.values
Out[49]: array([1, 2, 3, 4, 5], dtype=int64)pandas.Series取出索引:index
返回一个数组
In [50]: data1.index
Out[50]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object') pandas.Series类似于numpy.ndarry的性能
属性查看:数据类型(dtype)、形状(shape)、维度(ndim)、元素个数(size)、索引、切片、布尔过滤等。
pandas.Series通过索引值取值
In [58]: data1['a']#取单个值,类似于字典中通过键取值
Out[58]: 1
In [10]: data1[['a','b']]#传入索引值列表取一组值
Out[10]:
a 1
b 2
dtype: int64
等价于
In [14]: data1[0]
Out[14]: 1
In [15]: data1[[0,1]]
Out[15]:
a 1
b 2
dtype: int64pandas.Series类似字典(dict)的性能
In [18]: 'a' in data1#判断pandas.Series索引值成员资格
Out[18]: True
In [17]: 1 in data1.values#判断pandas.Series元素成员资格
Out[17]: True
In [20]: data1['a'] = '1234'#修改pandas.Series元素值
In [21]: data1
Out[21]:
a 1234
b 2
c 3
d 4
e 5
dtype: int643、pandas数据结构2-DataFrame
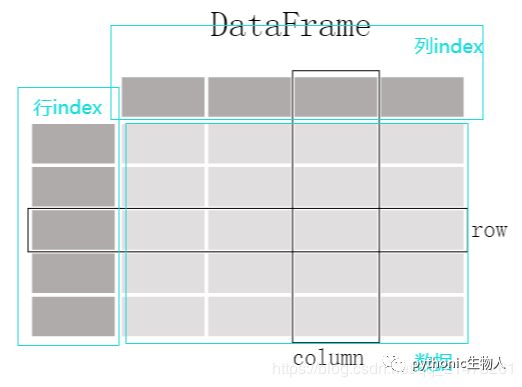
- DataFrame结构如下图,可以理解为一个具有行索引和列索引的表格性结构;
- 每一列都是一个Series对象、每一列的数据类型可以不一样;
- 具有大量属性和函数:详细使用请戳这里额
DataFame创建
- 语法:pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Union[str, numpy.dtype, ExtensionDtype, None] = None, copy: bool = False)
- data
- index:可选项,行标签
- columns:可选项,列标签
- dtype:可选项,元素数据类型
创建方式很多,罗列两种:
#使用字典创建pandas.DataFame
In [40]: d = {'col1': [1, 2], 'col2': [3, 4]}
...: df = pd.DataFrame(d,dtype=np.int8)#dtype指定元素数据类型
In [41]: df
Out[41]:
col1 col20 1 31 2 4
In [42]: df.dtypes#查看数据类型
Out[42]:
col1 int8
col2 int8
dtype: object
In [29]: df
Out[29]:
col1 col20 1 31 2 4#使用二维numpy.ndarry创建pandas.DataFame
In [43]: df2 = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),
...: columns=['a', 'b', 'c'])# columns指定列标签
In [44]: df2
Out[44]:
a b c0 1 2 31 4 5 62 7 8 9pandas.DataFrame中取列操作

#创建实验DataFrame
In [140]: d = {'one': pd.Series([2., 2., 3.,4.], index=['a', 'b', 'c','d']),'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd']),'three': pd.Series([3., 1., 3., 4.], index=['a', 'b', 'c', 'd'])}
In [141]: df = pd.DataFrame(d)
In [142]: df
Out[142]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0pandas.DataFrame中取某一列
In [143]: df['one']
Out[143]:
a 2.0
b 2.0
c 3.0
d 4.0
Name: one, dtype: float64pandas.DataFrame中取某几列-方法1
In [144]: df[['one','three']]#[[]],中括号中放入一个1索引值列表
Out[144]:
one three
a 2.0 3.0
b 2.0 1.0
c 3.0 3.0
d 4.0 4.0pandas.DataFrame中取某几列-方法2
In [76]: df.iloc[:,[0,2]]#df.iloc[行索引, [列索引号]]
Out[76]:
one three
a 2.0 3.0
b 2.0 1.0
c 3.0 3.0
d 4.0 4.0pandas.DataFrame中取行操作

pandas.DataFrame中取某一行
In [94]: df
Out[94]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [95]: df.loc[['a']]
Out[95]:
one two three
a 2.0 1.0 3.0
In [106]: type(df.loc[['a']])#返回一个DataFrame对象
Out[106]: pandas.core.frame.DataFrame
In [96]: df.loc['a']#使用['a']和[['a']]呈现方式有区别
Out[96]:
one 2.0
two 1.0
three 3.0
In [105]: type(df.loc['a'])#返回一个Series对象
Out[105]: pandas.core.series.Seriespandas.DataFrame中取某几行
In [97]: df.loc[['a','d']]
Out[97]:
one two three
a 2.0 1.0 3.0
d 4.0 4.0 4.0pandas.DataFrame中按一个条件过滤行
此时传入布尔向量辅助过滤。
In [118]: df
Out[118]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [114]: df['two']#取出'two'列
Out[114]:
a 1.0
b 2.0
c 3.0
d 4.0
Name: two, dtype: float64
In [115]: df['two'] > 2#'two'列判断返回布尔型Series对象
Out[115]:
a False
b False
c True
d True
Name: two, dtype: bool
In [116]: df[df['two'] > 2]#取出'two'列中元素值大于2的行
Out[116]:
one two three
c 3.0 3.0 3.0
d 4.0 4.0 4.0pandas.DataFrame中按多个条件过滤行
此时会用到逻辑运算符:
| 或者& 且~ 取反
注意使用括号将每个条件括起来,如下:
In [125]: df[(df['two'] >= 2) & (df['three'] >= 3)]#取'two'列大于等于2且'three'列大于等于3的行
Out[125]:
one two three
c 3.0 3.0 3.0
d 4.0 4.0 4.0pandas.DataFrame中结合map 和lambda函数过滤行
In [136]: df
Out[136]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [137]: fileter_ = df['one'].map(lambda x: str(x).startswith('2'))#取出'one'列中以2开头的字符
In [138]: df[fileter_]
Out[138]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0pandas.DataFrame中结合isin过滤行
In [139]: df
Out[139]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [140]: df['one'].isin([1,2])#取出'one'列中值为1或者2的行
Out[140]:
a True
b True
c False
d False
Name: one, dtype: bool
In [141]: df[df['one'].isin([1,2])]
Out[141]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0pandas.DataFrame中取某几行中的某几列
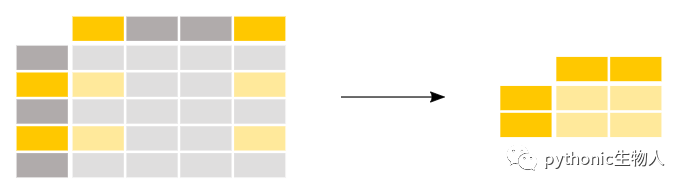
In [101]: df
Out[101]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [102]: df.iloc[[0,3],[0,1]]#取第0行,3行的第1列和第2列
Out[102]:
one two
a 2.0 1.0
d 4.0 4.0pandas.DataFrame中替换值:where方法
where对不满足条件的元素执行操作,不会改变原数据。
In [151]: df
Out[151]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [152]: df.where(df['one'] 3, dfpandas.DataFrame中查找某个位置的值:lookup方法
(个人感觉没什么卵用)
In [166]: df
Out[166]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [167]: df.lookup(['d','a'],['one','three'])#查找坐标为('d','one')和('a','three')的值
Out[167]: array([4., 3.])
In [168]: df.lookup(['a','d'],['one','three'])
Out[168]: array([2., 4.])pandas.DataFrame中末尾新增加列
会直接修改原始数据,慎重使用。
In [169]: df1
Out[169]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [170]: df1['five'] = -df1['three']#默认在末尾添加以列
In [171]: df1
Out[171]:
one two three five
a 2.0 1.0 3.0 -3.0
b 2.0 2.0 1.0 -1.0
c 3.0 3.0 3.0 -3.0
d 4.0 4.0 4.0 -4.0pandas.DataFrame中指定位置新增加列:insert方法
In [186]: df.insert(1, 'new_one', df['one'])#在第一列后新增加列
In [187]: df
Out[187]:
one new_one two three
a 2.0 2.0 1.0 3.0
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0pandas.DataFrame中删除列:del方法
会直接修改原始数据,慎重使用。
In [177]: del df1['five']
In [178]: df1
Out[178]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0pandas.DataFrame复制:copy方法
可以避免del,insert这种方法直接修改原始数据。
In [189]: df1 = df.copy()
In [190]: df1
Out[190]:
one new_one two three
a 2.0 2.0 1.0 3.0
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0
In [192]: del df1['new_one']
In [193]: df1#df1被修改
Out[193]:
one two three
a 2.0 1.0 3.0
b 2.0 2.0 1.0
c 3.0 3.0 3.0
d 4.0 4.0 4.0
In [194]: df#df未被修改
Out[194]:
one new_one two three
a 2.0 2.0 1.0 3.0
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0pandas.DataFrame查看前几行和末尾几行:head|tail
In [199]: df
Out[199]:
one new_one two three
a 2.0 2.0 1.0 3.0
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0
In [200]: df.head(3)#查看前三行
Out[200]:
one new_one two three
a 2.0 2.0 1.0 3.0
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
In [201]: df.tail(3)#查看末尾三行
Out[201]:
one new_one two three
b 2.0 2.0 2.0 1.0
c 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0Series、pandas.DataFrame中某列唯一值的个数:unique
In [68]: pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c' , 'c']).unique()
Out[68]: array(['c', 'a', 'd', 'b'], dtype=object)pandas.DataFrame统计列中每个元素出现的频次:value_counts方法
In [251]: df1
Out[251]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 NaN
d NaN 4.0
In [252]: df1['one'].value_counts()
Out[252]:3.0 12.0 11.0 1
Name: one, dtype: int64
In [253]: df1['one'].value_counts(dropna=False)#不跳过缺省值
...:
Out[253]:
NaN 13.0 12.0 11.0 1
Name: one, dtype: int64pandas.DataFrame按照某几列分组并统计:groupby+count
In [5]: df = pd.DataFrame([('bird', 'Falconiformes', 389.0),
...: ('bird', 'Psittaciformes', 24.0),
...: ('mammal', 'Carnivora', 80.2),
...: ('mammal', 'Primates', np.nan),
...: ('mammal', 'Carnivora', 58)],
...: index=['falcon', 'parrot', 'lion', 'monkey', 'leopard'],
...: columns=('class', 'order', 'max_speed'))
In [6]: df
Out[6]: class order max_speedfalcon bird Falconiformes 389.0parrot bird Psittaciformes 24.0lion mammal Carnivora 80.2monkey mammal Primates NaNleopard mammal Carnivora 58.0In [7]: df.groupby(['class','order']).count()
Out[7]:
max_speedclass order bird Falconiformes 1Psittaciformes 1mammal Carnivora 2Primates 0pandas.DataFrame按照某列分组并求和:
In [17]: df2 = pd.DataFrame({'X': ['B', 'B', 'A', 'A'], 'Y': [1, 2, 3, 4]})
In [18]: df2
Out[18]:
X Y0 B 11 B 22 A 33 A 4
In [19]: df2.groupby(['X']).sum()
Out[19]:
Y
X
A 7
B 3
In [20]: df2.groupby(['X'],sort=False).sum()
Out[20]:
Y
X
B 3
A 7pandas.DataFrame按照某列分组并取出某个小组:groupby+get_group
In [27]: df2.groupby(['X']).get_group('A')
Out[27]:
X Y2 A 33 A 4#统计groupby分组的组数
In [28]: len(df2.groupby(['X'],sort=False).get_group('A'))
Out[28]: 2pandas.DataFrame排序
pandas.DataFrame按照行标签或者列标签排序:sort_index方法
默认为升序,ascending可设置排序方式。
In [31]: frame = pd.DataFrame(np.arange(8).reshape((2, 4)), index=['three', 'one'], columns=['d', 'a', 'b', 'c'])
In [32]: frame
Out[32]:
d a b c
three 0 1 2 3
one 4 5 6 7
In [36]: frame
Out[36]:
d a b c
three 0 1 2 3
one 4 5 6 7
In [37]: frame.sort_index()#行索引排序
Out[37]:
d a b c
one 4 5 6 7
three 0 1 2 3
In [38]: frame.sort_index(axis=1)#列索引排序
Out[38]:
a b c d
three 1 2 3 0
one 5 6 7 4
In [39]: frame.sort_index(axis=1, ascending=False)#列索引排序,ascending设置升序还是降序排序
Out[39]:
d c b a
three 0 3 2 1
one 4 7 6 5pandas.DataFrame按照某列值排序:sort_values方法by参数
In [41]: frame.sort_values(by='d')#按照d列值排序,默认是升序
Out[41]:
d a b c
three 0 1 2 3
one 4 5 6 7
In [42]: frame.sort_values(by='d',ascending=False)#ascending设置降序排序
Out[42]:
d a b c
one 4 5 6 7
three 0 1 2 3
In [43]: frame.sort_values(by=['c','d'],ascending=False)#按照c,d的值排序,即先按c列值排序,c列值相同时再按d列值排序
Out[43]:
d a b c
one 4 5 6 7
three 0 1 2 3pandas.DataFrame描述统计
Pandas中描述和汇总统计常用函数
方法 说明
count 非 NA 值的数量
describe 针对 Series 或 DataFrame 的列计算汇总统计,对于数值和字符返回结构不一样
min , max 最小值和最大值
argmin , argmax 最小值和最大值的索引位置(整数)
idxmin , idxmax 最小值和最大值的索引值
quantile 样本分位数(0 到 1)
sum 求和
mean 均值
median 中位数
mad 根据均值计算平均绝对离差
var 方差
std 标准差
skew 样本值的偏度(三阶矩)
kurt 样本值的峰度(四阶矩)
cumsum 样本值的累计和
cummin , cummax 样本值的累计最大值和累计最小值
cumprod 样本值的累计积
diff 计算一阶差分(对时间序列很有用)
pct_change 计算百分数变化In [44]: df = DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=['a','b','c','d'],columns=['one','two'])
In [45]: df
Out[45]:
one two
a 1.40 NaN
b 7.10 -4.5
c NaN NaN
d 0.75 -1.3
In [46]: df.sum()#默认求每列的和
Out[46]:
one 9.25
two -5.80
dtype: float64
In [47]: df.sum(axis = 1)#传入参数axis,求每行的和
Out[47]:
a 1.40
b 2.60
c 0.00
d -0.55
dtype: float64
In [48]: df.describe()#输出每列值的多个统计指标,对于NaN值直接跳过
Out[48]:
one two
count 3.000000 2.000000
mean 3.083333 -2.900000
std 3.493685 2.262742
min 0.750000 -4.50000025% 1.075000 -3.70000050% 1.400000 -2.90000075% 4.250000 -2.100000
max 7.100000 -1.300000
In [53]: pd.Series(['a', 'a', 'b', 'c']).describe()
Out[53]:
count 4
unique 3#字符去重后的个数
top a
freq 2
dtype: objectpandas.DataFrame获取行列标签/表头名称
In [75]: df
Out[75]:
one two
a 1.40 NaN
b 7.10 -4.5
c NaN NaN
d 0.75 -1.3
In [76]: list(df.columns.values)#列标签
Out[76]: ['one', 'two']
In [77]: list(df.index.values)#行标签
Out[77]: ['a', 'b', 'c', 'd']参考资料
同系列文章https://pandas.pydata.org/pandas-docs/stable/index.html[Python for Data Analysis, 2nd Edition]
(https://pandas.pydata.org/pandas-docs/stable/index.html)
Python数据科学手册
python3基础12详解模块和包(库)|构建|使用 python数据分析包|NumPy-01 python数据分析包|NumPy-02
原创不易"点赞"、"在看"鼓 励下呗
励下呗
 !
!
