Android-IO底层原理看序列化
文章目录
- 底层原理看序列化
-
- 技术点
- 序列化
底层原理看序列化
技术点
1.序列化概念与目的
2.序列化协议与特性
3.API提供的序列化方案
4.java的序列化步骤与数据结构分析
5.Parcelable与Serializable的性能比较
6.面试相关问题
序列化
1.什么是序列化
本质:协议,一套标准
目的:数据传输
java有自己的一些独有的数据结构class,想要让他能够通用,不单单我自己的程序可以用,还可以给别人用,还可以持久化保存下来,本质上讲,对象可以转换成为底层的一组字节数据010101,而序列化就是大家定义一套将我们的特殊数据转换成一组基本的二进制字节数据的过程,这个过程叫做序列化。反序列化就是把这组字节数据恢复成特定数据的实现。
2.序列化协议特性
通用性
技术层面,序列化协议是否支持跨平台,跨语言,如果不支持,在技术层面上的通用性就大大降低了。
流行程度,序列化和反序列化需要多方参与,很少人使用的协议就意味着昂贵的学习成本,另一方面流行度低,往往缺乏稳定而成熟的跨语言,跨平台的公共包。
强健性/鲁棒性
成熟度不够
语言/平添的不公平性
可调试性/可读性
支持不到位
访问限制
性能
性能包括两个方面,时间复杂度和空间复杂度
空间开销,序列化需要在原有的数据上加上描述字段,以反序列化解析之用,如果序列化过程引入的额外开销过高,可能会导致过大的网络,磁盘等各方面的压力,对于海量分布式存储系统,数据量往往以TB为单位,巨大的额外空间开销意味着高昂的成本
时间开销,复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。
3.数据结构,对象与二进制串
不同的计算机语言中,数据结构,对象以及二进制串的表示方式并不相同
数据结构和对象:对于类似Java这种完全面向对象的语言,工程师所操作的一切都是对象
4.广义上的序列化和反序列化
XML&SOAP
XML是一种常用的序列化和反序列化协议,具有跨机器,跨语言等有点,SOAP(SimpleObjectAccess protocol)是一种被广泛应用的,基于XML为序列化和反序列化协议的结构化消息传递协议。
JSON起源于弱类型语言javascript,它的产生来自于一种称之为“Associative array”的概念,其本质就是采用“Attribute-value”的方式来描述对象,实际上在JavaScript和PHP等弱语言中,类的描述方式就是Associative array。JSON的如下优点使得它快速成为最广泛使用的序列化协议之一,这种Associative array格式非常符合工程师对对象的理解。它保持了XML的人眼可读的优点,相对于XML而言,序列化后的数据更加简洁。是Ajax的事实标准协议,与XML相比,其协议比较简单,解析速度比较快,松散的Associative array使得其具有很良好的可扩展性和兼容性。
Protobuf
Protobuf具备了优秀的序列化协议的所需的众多典型特征
标准的IDL和IDL编译器,这使得其对工程师非常友好
序列化数据非常简洁,紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10
解析速度非常快,比对应的XML约快20-100倍
提供了非常友好的动态库,使用非常简洁,反序列化只需要一行代码。
5.Android人员如何去选择序列化方案
Serializable接口
Serializable用来标识当前类可以被ObjectOutputStream序列化,以及被ObjectOutputStream反序列化
Parcelable接口
Parcelable是Android为我们提供的序列化的接口,Parcelable相对于Serializable的使用相对复杂一些,但Parcelable的效率相对Serializable也高很多,这一直是Google工程师引以为傲的,Parcelable号称比Serializable号称快10倍的效率
6.ObjectOutputStream序列化工具实现了序列化逻辑,这是把一个对象给拆开
类信息
方法信息
字段信息
数据信息
转换成字节给我们使用
ObjectInputStream是将上面拆完的数据重新来进行恢复,重新构建一个对象出来
7.序列化和持久化的区别
序列化是为了拆数据和拼数据的实现,持久化是为了数据的保存的操作
8.序列化常见问题
什么是seriaIVersionUID,如果不定义这个,会发生什么?
假设你有一个类,他序列化并存储在持久化中,然后修改了该类以添加新字段,如果对已序列化的对象进行反序列化会发生什么情况?
seriaIVersionUID:是用来做版本管理的
JDK官方在考虑拆解拼装(序列化和反序列化)数据的时候考虑到有数据变动问题,所以要用一个变量作为标识,如果我们自己不写,会随机分配一个,自己写代表控制版本
9.seriaIVersionUID兼容性问题
为了在反序列化时,确保类版本的兼容性,最好在每个要序列化的类中加入private static final long seriaIVersionUID这个属性,具体数值自己定义,这样,即使某个类在与之对应的对象已经序列化出后做了修改,改对象依然可以被正确的反序列化,否则,如果不做显式定义该属性,这个属性值将由JVM根据类的相关信息计算,而修改后的类计算如果与修改之前的类计算结果往往不同,从而造成对象的反序列化因为类版本不兼容而导致失败,不显式定义这个属性值的另一个坏处是,不利于程序在不同JVM之间的移植,因为不同的编译器实现的该属性值的计算策略可能不同,从而造成虽然类没有改变,但是因为JVM不同,出现因类版本不兼容而无法正确反序列化的现象出现。
因此JVM规范强烈建议我们手动生成一个版本号,这个数字可以是随机的,只要固定不变就行,同事最好是private和final的
10.序列化时,你希望某些成员不要序列化,你要如何实现它?或者问什么是瞬态transient变量?瞬态变量和静态变量会不会得到序列化等?
transient瞬态变量的关键字
本是上是和序列化有关的,他是一个用来标记当前变量是否参与序列化的过程
11.如果类中的一个成员未实现可序列化接口,会发生什么情况?
一次序列化的过程本质上讲是一次深克隆
浅克隆,内存地址进行复制
深克隆,重新创建一个
需要将数据复制一份,不让我弄,我序列化本身就是要保存数据,连带内部的数据进行一个序列化,如果没有就会异常
12.如果类是可序列化的,但是其超类不是,则反序列化后从超类继承的实例变量状态如何?
如果是静态的,是可以序列化的
想要序列化需要提供两个条件:
(1)给版本号
(2)给无参构造
正常来说进行反序列化的时候,父类的数据会丢失,因此需要加上如下两个方法,这块不是重写,因为本身父类就没有这接口,所以不是重写,这块是一个反射。
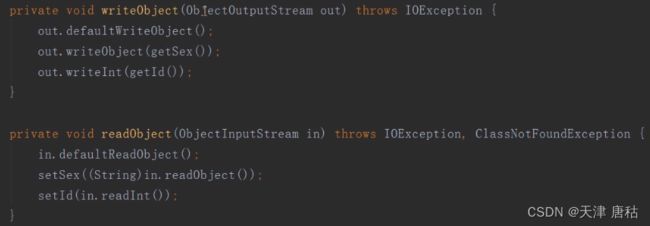
如果父类是可以序列化的,子类没有序列化是否可以运行?
是可以的,因为子类继承了父类,那么就会产生一个场景,就是不想让我们的子类继承这个序列化,那么只需要重写下面的几个方法
13.为什么序列化一定需要一个无参构造?
在反序列化过程中,Java并没有考虑什么给你多样化的玩法,他只管使用无参构造进行对象创建,所以必须有无参构造。
在序列化的过程中,他将构造函数的信息数据存储在ObjectStreamClass的类中,反序列化是提取到当前数据,拿到cons中的构造属性进行反射调用无参构造。
14.序列化的保存和直接保存json字符串取出再序列化有什么关系?
序列化时Java操作,内部多个Java程序之间的信息通信应用方便
json是固定格式固定解析,可以跨语言,跨平台
15.是否可以自定义序列化过程,或者覆盖java中默认的序列化过程?
可以,可以通过writeObject和readObject控制序列化过程
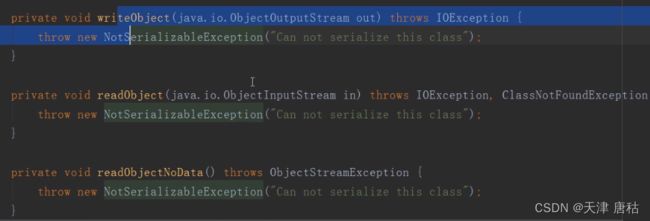
16.假设子类的超类实现可序列化接口,子类如何避免序列化?
直接在writeObject和readObject中抛异常,反正会调
17.在java中的序列化和反序列化过程中使用哪些方法?
序列化参考下面序列化过程
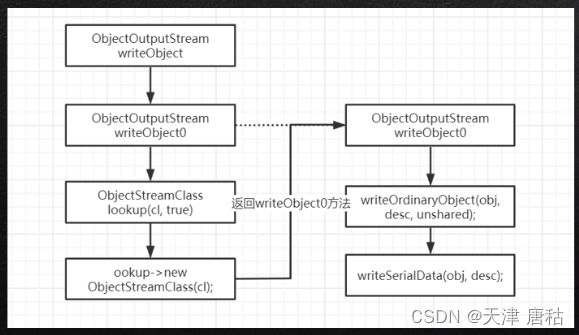
18.序列化原理
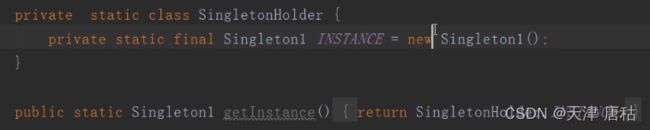
19.序列化会对单例进行一个破坏
解决方案:加final
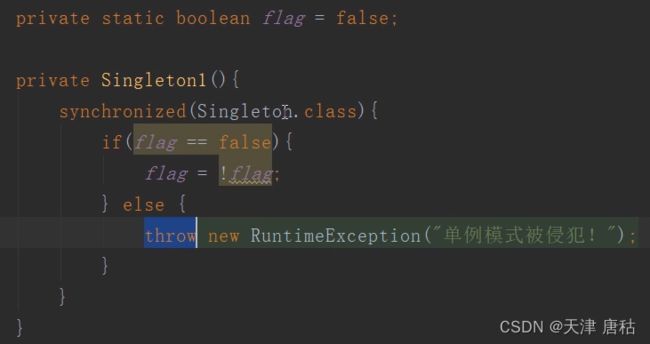
20.打断序列化过程,如何做到?
通过readObject核writeObject
21.发现的问题
序列化过程中,存在可以打断现场,不给构造直接报错现场,莫名奇妙的调用一个readObject,writeObject
序列化过程
ObjectOutputStream(序列化,拆数据,怎么拆成二进制):序列化最终是变成字节数组
反序列化过程
ObjectInputStream(拼数据,从二进制变成数据)
(1)ObjectStreamClass desc:这个东西好像在构造里面拿着我的Class信息给我当前类里面的所有信息都提了一遍
(2)在进行构建的时候,默认他在里面尝试着提三个方法:writeObject readObject readObjectNoDate
结论:当前ObjectStreamClass new完,这个类的全部信息收集完成,包括SUID,构造,方法,字段,特殊的几个方法
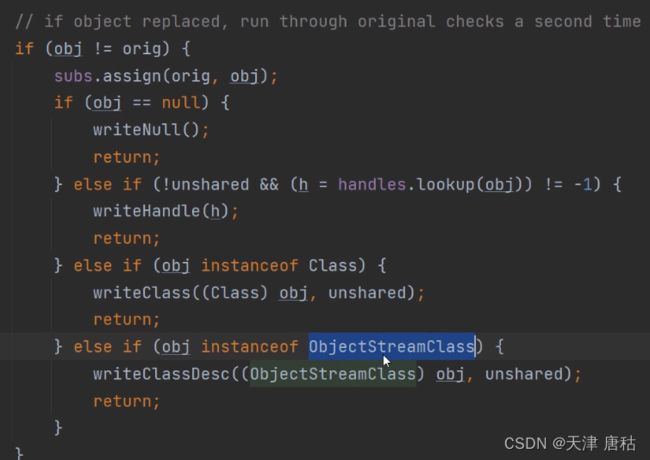
writeOrdinaryObject----->writeNoProxyDesc(转换之前取得的类信息,将其转换成字节)
1.ObjectOutputStream.writeObject
2.writeObject.writeObject0
3.writeObject0
----->ObjectStreamClass desc //用来拆解当前对象的Class信息,获取的数据包括字段信息,类名,版本号,获取特定三个方法writeObject,readObject,readObjectNoData
----->ObjectStreamClass.lookup(cl, true) //对ObjectStreamClass进行实例创建new
----->writeOrdinaryObject(obj, desc, unshared) //就是开始真正去写数据了,将拆完之后的类信息与对象数据给入
4.writeOrdinaryObject()
----->writeClassDesc(desc, false); //将类信息转换成字节数据
----->writeExternalData((Externalizable) obj);
----->writeSerialData(obj, desc); //将对象具体的数据转换成字节数据
5.writeSerialData
----->slotDesc.invokeWriteObject(obj, this); //调用一手writeObject
----->defaultWriteFields(obj, slotDesc); //将字段的具体数据转成字节数据
反序列化过程
defaultWriteFields已经将字段数据转换成为二进制字节了
原理总结:
ObjectInput/OutputStream作用就是去将对象拆车字节数据和将字节数恢复成对象
序列化过程
1.根据对象的Class进行拆分提取数据,将所有的类信息全部拿到,然后再提供自己需要的特殊数据(ObjectStreamClass)
2.将类信息转换成字节数组
3.调用自己提供的writeObject方法
4.字段数据转换成字节
反序列化过程
1.读取字节数组
2.还原类信息
3.构建对象
4.将字节中对应字段数据复制
Serializable是oracle写的 ObjectInput/OutputStream
网络数据传输,java,net,反射会很多,基于流
JVM垃圾回收,内存碎片
IO对造成额外的CPU开销
对于WEB应用程序,因为是服务器的问题,8核
手机:设备性能有限,在安卓系统内部,应用了跨进程方案对各个组件进行管理,进程间也需要通信
进程通信:socket,写到固定的地方,socket会产生大量的连接
android Binder 基于共享内存
json解析会带来大量字符串产生
Parcelable是google写的 Pracel–>read,write
我可以用C去写,东西自己控制
22.Paarcelable与Serizlizable对比
