Pytorch实现MNIST手写数字识别(全连接神经网络及卷积神经网络)
目录
- 项目简介
- 数据集获取
-
- 1、读取数据
- 2、训练集和测试集划分
- 3、搭建全连接网络
- 4、搭建卷积神经网络
大家好,这是我第一次在CSDN上写文章,如果下面内容有错误或者不合适的地方,恳请大家批评指正。
项目简介
MNIST手写数字识别数据集是入门卷积神经网络(CNN)的一个常见数据集,它总共包含70000张图片,每张图片表示的是一个手写数字,共0~9这10个数字,也就是10个类别,每张图片均为灰度图片,即通道数为1,它的大小为28*28。本次项目主要是基于该数据集,通过Pytorch提供的库函数,运用全连接神经网络以及卷积神经网络实现这些图片的分类,并尝试调整了学习率这一参数。
数据集获取
数据集获取:
1、链接: https://pan.baidu.com/s/1fF__bqOZccDxVgm94ySF_g,提取码: bs9v
2、直接通过代码下载:
import torchvision
from torchvision.datasets import mnist
# 下载数据集,其中'./data/'表示你要保存的文件路径
train_data = mnist.MNIST('./data/', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))]))
test_data = mnist.MNIST('./data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))]))
1、读取数据
(1)导入基本的数据包
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from sklearn.model_selection import train_test_split
(2)设置主要参数
n_epochs = 10
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.1
(3)读取数据
#其中values表示的是去掉表头和索引,只取数据
minst_data = pd.read_csv("./mnist.csv", header=None).values
data = minst_data[:, 1:].reshape((-1, 28, 28))
label = minst_data[:, 0]
(4)展示部分图片
size = 4
plt.figure(figsize=(size, size))
for i in range(size*size):
plt.subplot(size, size, i+1)
plt.imshow(data[i], cmap='gray')

2、训练集和测试集划分
(1)训练集和测试集的划分
#使用线性模型
linear_data = data.reshape((-1, 28*28)) / 256
data_train, data_test, label_train, label_test = train_test_split(linear_data, label, test_size=0.2, random_state=2020)
print(data_train.shape, data_test.shape)
print(label_train.shape, label_test.shape)
训练集和测试集数据及标签的维度:
![]()
(2)将numpy转换为Tensor,调用DataLoader方法划分batch
import torch
from torch.utils.data import TensorDataset,DataLoader
random_seed = 1
torch.cuda.manual_seed(random_seed)
data_train = torch.from_numpy(data_train).float()
label_train = torch.from_numpy(label_train).long()
#TensorDataset相当于zip功能,将data和label按照第一个维度打包成两个tensor,DataLoader主要用来进行batch_size的划分,drop表示是否去除最后不满足一个batch_size大小的数据
data_train = DataLoader(TensorDataset(data_train, label_train), batch_size=batch_size_train, shuffle=True, drop_last=True)
data_test = torch.from_numpy(data_test).float()
label_test = torch.from_numpy(label_test).long()
data_test = DataLoader(TensorDataset(data_test, label_test), batch_size=batch_size_test, shuffle=True, drop_last=True)
3、搭建全连接网络
首先,构造了一个简单的全连接神经网络,输入为28*28的一维向量,隐藏层节点数为256,经过一个PReLU激活函数,最后输出图片属于某一类别的可能性。
(1)定义含一个隐藏层的全连接网络
#全连接网络
from torch import nn,optim
class linear_model(nn.Module):
def __init__(self):
super(linear_model, self).__init__()
self.dense = nn.Sequential(nn.Linear(28*28, 256), nn.PReLU(),nn.Linear(256, 10)) #PReLU效果比ReLU好
def forward(self, x):
return self.dense(x)
(2)模型的训练与测试(学习率为0.1,优化器为SGD)
#learning_rate=0.1,optim=SGD
from tqdm.notebook import tqdm
from torch.autograd import Variable
model = linear_model().cuda()
loss = nn.CrossEntropyLoss()
opt = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(n_epochs):
running_loss = []
#data_train是一个划分了batch的数据加载器,每一个batch看作一个训练集进行训练
for x, y in tqdm(data_train):
x = Variable(x).cuda()
y = Variable(y).cuda()
model.train() #启用BatchNormalization和Dropout进行训练模式
y_prediction = model(x)
l = loss(y_prediction, y)
opt.zero_grad() #将梯度设为0,因为每次训练把一个batch当作一个训练集进行训练
l.backward() #反向传播计算梯度
opt.step() #通过梯度下降进行一次参数更新,比如w=w-a*(grad(w))
running_loss.append(float(l))
running_acc = []
for x, y in data_test:
x = Variable(x).cuda()
y = Variable(y).cuda()
model.eval() #不启用BatchNormalization和Dropout进行测试模式
y_prediction = model(x)
y_prediction = torch.argmax(y_prediction, dim=1) #dim=1表示取每一行最大值的索引
acc = float(torch.sum(y_prediction == y)) / batch_size_test
running_acc.append(acc)
print("#summary:% 4d %.4f %.2f%%" % (epoch, np.mean(running_loss), np.mean(running_acc)*100))
实验结果:
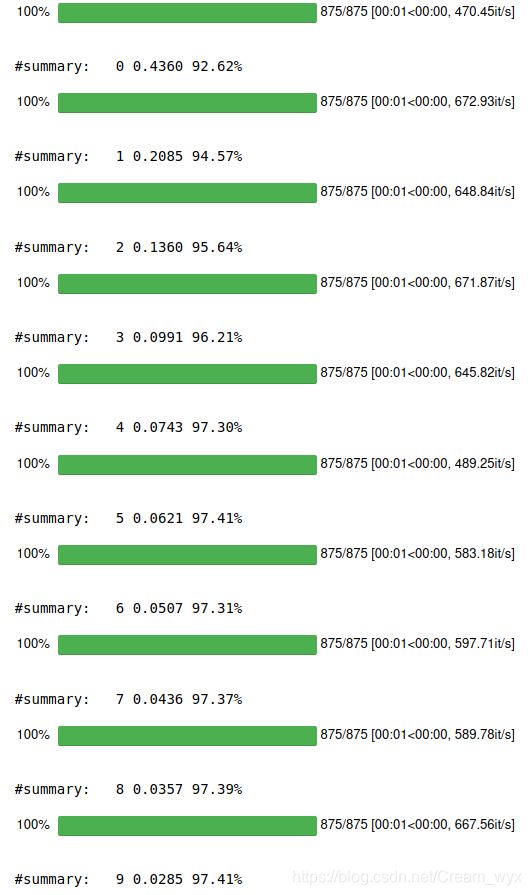 (3)模型的训练与测试(学习率为0.1,优化器为Adam)
(3)模型的训练与测试(学习率为0.1,优化器为Adam)
#learning_rate=0.1,optim=Adam
model = linear_model().cuda()
loss = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(n_epochs):
running_loss = []
#data_train是一个划分了batch的数据加载器,每一个batch看作一个训练集进行训练
for x, y in tqdm(data_train):
x = Variable(x).cuda()
y = Variable(y).cuda()
model.train() #启用BatchNormalization和Dropout进行训练模式
y_prediction = model(x)
l = loss(y_prediction, y)
opt.zero_grad() #将梯度设为0,因为每次训练把一个batch当作一个训练集进行训练
l.backward() #反向传播计算梯度
opt.step() #通过梯度下降进行一次参数更新,比如w=w-a*(grad(w))
running_loss.append(float(l))
running_acc = []
for x, y in data_test:
x = Variable(x).cuda()
y = Variable(y).cuda()
model.eval() #不启用BatchNormalization和Dropout进行测试模式
y_prediction = model(x)
y_prediction = torch.argmax(y_prediction, dim=1) #dim=1表示取每一行最大值的索引
acc = float(torch.sum(y_prediction == y)) / batch_size_test
running_acc.append(acc)
print("#summary:% 4d %.4f %.2f%%" % (epoch, np.mean(running_loss), np.mean(running_acc)*100))
实验结果:
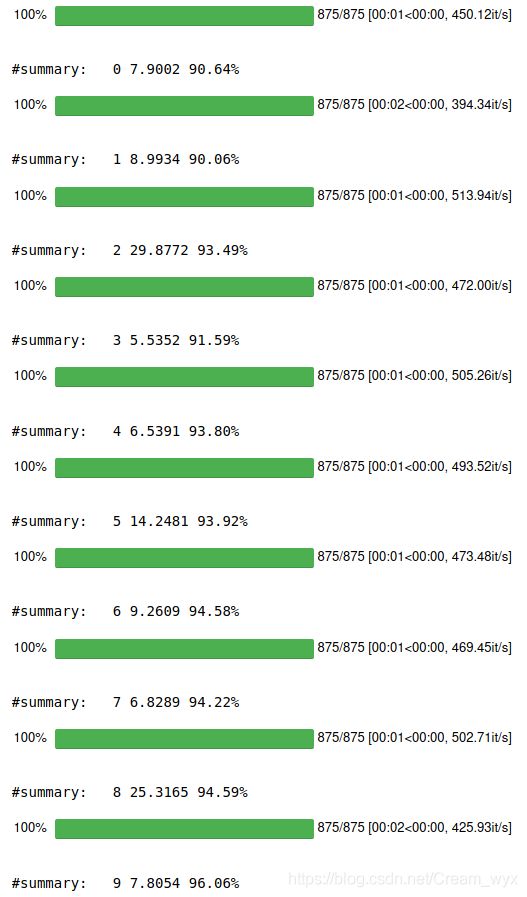 (4)模型的训练与测试(学习率为0.01,优化器为SGD)
(4)模型的训练与测试(学习率为0.01,优化器为SGD)
#learning_rate=0.01,optim=SGD
learning_rate = 0.01
model = linear_model().cuda()
loss = nn.CrossEntropyLoss()
opt = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(n_epochs):
running_loss = []
#data_train是一个划分了batch的数据加载器,每一个batch看作一个训练集进行训练
for x, y in tqdm(data_train):
x = Variable(x).cuda()
y = Variable(y).cuda()
model.train() #启用BatchNormalization和Dropout进行训练模式
y_prediction = model(x)
l = loss(y_prediction, y)
opt.zero_grad() #将梯度设为0,因为每次训练把一个batch当作一个训练集进行训练
l.backward() #反向传播计算梯度
opt.step() #通过梯度下降进行一次参数更新,比如w=w-a*(grad(w))
running_loss.append(float(l))
running_acc = []
for x, y in data_test:
x = Variable(x).cuda()
y = Variable(y).cuda()
model.eval() #不启用BatchNormalization和Dropout进行测试模式
y_prediction = model(x)
y_prediction = torch.argmax(y_prediction, dim=1) #dim=1表示取每一行最大值的索引
acc = float(torch.sum(y_prediction == y)) / batch_size_test
running_acc.append(acc)
print("#summary:% 4d %.4f %.2f%%" % (epoch, np.mean(running_loss), np.mean(running_acc)*100))
实验结果:
 (5)模型的训练与测试(学习率为0.001,优化器为Adam)
(5)模型的训练与测试(学习率为0.001,优化器为Adam)
#learning_rate=0.001,optim=Adam
learning_rate = 0.001
model = linear_model().cuda()
loss = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(n_epochs):
running_loss = []
#data_train是一个划分了batch的数据加载器,每一个batch看作一个训练集进行训练
for x, y in tqdm(data_train):
x = Variable(x).cuda()
y = Variable(y).cuda()
model.train() #启用BatchNormalization和Dropout进行训练模式
y_prediction = model(x)
l = loss(y_prediction, y)
opt.zero_grad() #将梯度设为0,因为每次训练把一个batch当作一个训练集进行训练
l.backward() #反向传播计算梯度
opt.step() #通过梯度下降进行一次参数更新,比如w=w-a*(grad(w))
running_loss.append(float(l))
running_acc = []
for x, y in data_test:
x = Variable(x).cuda()
y = Variable(y).cuda()
model.eval() #不启用BatchNormalization和Dropout进行测试模式
y_prediction = model(x)
y_prediction = torch.argmax(y_prediction, dim=1) #dim=1表示取每一行最大值的索引
acc = float(torch.sum(y_prediction == y)) / batch_size_test
running_acc.append(acc)
print("#summary:% 4d %.4f %.2f%%" % (epoch, np.mean(running_loss), np.mean(running_acc)*100))
实验结果:
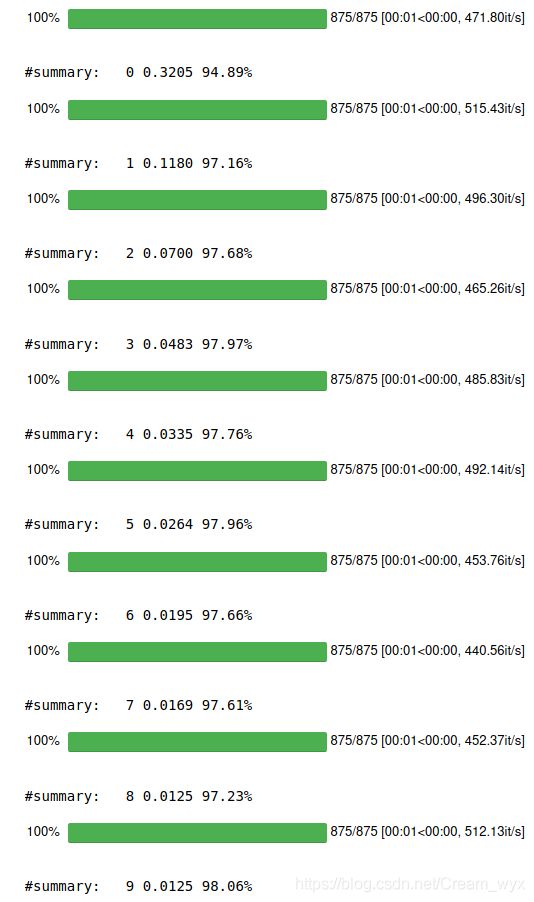
4、搭建卷积神经网络
(1)定义卷积神经网络(参考:https://blog.csdn.net/qq_34714751/article/details/85610966)
定义了卷积神经网络结构各层的情况如下:
| 卷积层 | 输入维度 | 输出维度 |
|---|---|---|
| conv1 | [128,1,28,28] | [128, 16, 14, 14] |
| conv2 | [128, 16, 14, 14] | [128, 32, 7, 7] |
| conv3 | [128, 32, 7, 7] | [128, 64, 4, 4] |
| conv4 | [128, 64, 4, 4] | [128, 64, 2, 2] |
#卷积神经网络
from torch import nn,optim
class cnn_model(nn.Module):
def __init__(self):
super(cnn_model, self).__init__()
#卷积层
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1,
out_channels=16,
kernel_size=3,
stride=2,
padding=1), #200,1,28,28-----200,16,14,14
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
) #200,16,14,14-----200,32,7,7
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
) #200,32,7,7-----200,64,4,4
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
) #200,64,4,4-----200,64,2,2
#全连接层
self.dense = nn.Sequential(nn.Linear(2*2*64,256), nn.PReLU(), nn.Linear(256, 10)) #PReLU效果比ReLU好
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
x = self.dense(x)
return x
(2)CNN模型的训练与测试(学习率为0.001,优化器为Adam)
#learning_rate=0.001,optim=Adam
learning_rate = 0.001
model = cnn_model().cuda()
loss = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=learning_rate)
cost, accuracy = [], []
for epoch in range(n_epochs):
running_loss = []
#data_train是一个划分了batch的数据加载器,每一个batch看作一个训练集进行训练
for x, y in tqdm(data_train):
x = x.reshape((-1,1,28,28))
x = Variable(x).cuda()
y = Variable(y).cuda()
model.train() #启用BatchNormalization和Dropout进行训练模式
y_prediction = model(x)
l = loss(y_prediction, y)
opt.zero_grad() #将梯度设为0,因为每次训练把一个batch当作一个训练集进行训练
l.backward() #反向传播计算梯度
opt.step() #通过梯度下降进行一次参数更新,比如w=w-a*(grad(w))
running_loss.append(float(l))
running_acc = []
for x, y in data_test:
x = x.reshape((-1,1,28,28))
x = Variable(x).cuda()
y = Variable(y).cuda()
model.eval() #不启用BatchNormalization和Dropout进行测试模式
y_prediction = model(x)
y_prediction = torch.argmax(y_prediction, dim=1) #dim=1表示取每一行最大值的索引
acc = float(torch.sum(y_prediction == y)) / batch_size_test
running_acc.append(acc)
cost.append(np.mean(running_loss))
accuracy.append(np.mean(running_acc))
print("#summary:% 4d %.4f %.2f%%" % (epoch, np.mean(running_loss), np.mean(running_acc)*100))
实验结果:
 (3)绘制损失函数变化曲线
(3)绘制损失函数变化曲线
plt.plot(cost)

(4)绘制准确率变化曲线
plt.plot(accuracy)
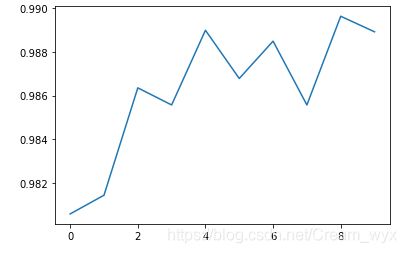 如有不恰当之处请在下面评论或者私信我。
如有不恰当之处请在下面评论或者私信我。