数据结构与算法6-队列
目录
队列的定义
队列的特点
队列的分类
队列的操作分类
队列的实现方式
循环队列
优先队列
阻塞队列
队列的定义
队列是一种特殊的线性表,它的特殊之处在于,只允许在前端进行删除操作,只允许在后端进行插入操作,和栈一样,队列是一种存在限制的线性表,进行插入操作的那一端称为队尾,进行删除操作的那一端称为队首,当队列中没有任何元素时,称为空队列
在队列中插入一个元素,叫做入队,在队列中删除一个元素,称为出队,因为队列只允许一端删除一端插入,所以最早入队的,也是最早出队的,先进先出,FIFO,first in first out,和栈是相反的
如果很难理解,就想像一下排队买饭,早来的早买饭,晚来的排队等着晚买饭(别犟,给我搞什么插队,这不是过家家)
另外,既然是线性表,意味着可以用数组和链表实现,所以说,数组和链表这俩是真的挺重要的
队列的特点
线性表
先进先出
队列的分类
顺序队列:只能在一端插入数据,另一端删除数据
循环队列:每一端都可以插入数据和删除数据
队列的操作分类
队列像栈一样,只有入队和出队
队列和栈很相似,都受限,当然,也都有存在的必要性,限制也是为了某种程度上安全
队列的实现方式
/**
* @author create by YanXi on 2022/9/9 15:34
* @email [email protected]
* @Description: 数组实现队列
*/
public class MyArrayQueue {
// 数据
private int data[];
// 头参数位置
private int head = 0;
// 尾参数位置
private int tail = 0;
// 大小
private int dataSize = 0;
public MyArrayQueue(int initSize) {
data = new int[initSize];
dataSize = initSize;
}
/**
* @Description: 入队列
* @Author: create by YanXi on 2022/9/9 22:09
* @Email: [email protected]
*
* @param pam 要插入的元素
* @exception
* @Return: void
*/
public void push(int pam) {
// 当尾结点等于队列长度,说明队列满了
if (tail == dataSize) {
return;
}
data[tail] = pam;
tail++;
}
/**
* @Description: 出队
* @Author: create by YanXi on 2022/9/9 22:16
* @Email: [email protected]
*
* @param
* @exception
* @Return: int 返回的值,如果是-1说明队列为空
*/
public int pop() {
if (isEmpty()) {
return -1;
}
int result = data[head];
head++;
return result;
}
/**
* @Description: 判断队列是否为空
* @Author: create by YanXi on 2022/9/9 22:17
* @Email: [email protected]
*
* @param
* @exception
* @Return: boolean
*/
public boolean isEmpty() {
return head == tail;
}
}
代码写出来就是这样的,是不是比较明白?
如果不明白的话,想一下这个道理,入队的时候,从尾部入,出队从头部出,结合代码,入队的时候尾部增加,tail增加,出队的时候,head出,head增加,不就是先入先出么
当然,细心的,会发现这段代码有个问题,那就是空间只能用一次,头往后,尾往后,总会到底的,到最后队列没存东西,但是位点已经到头了
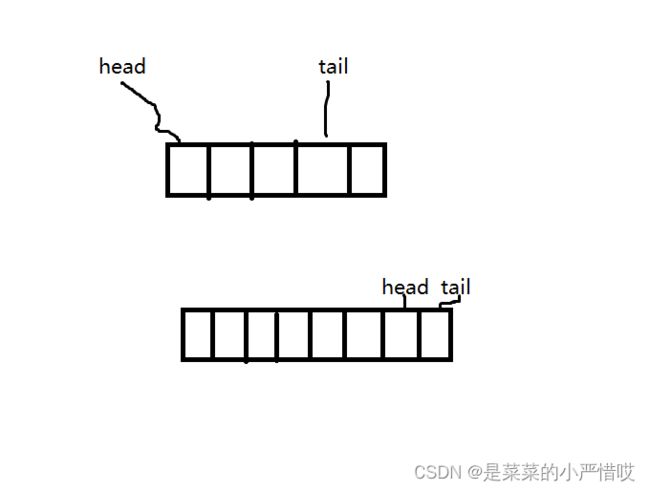
有想法的,可能会第一时间想到,每次出队列,那就往前移动,不过这样的话,时间复杂度就从O(1) 变成了O(n)
换一个实现当然可以,但是不能每次都换方案实现,可以想想怎么解决
提供一个思路,我们在入队的时候,因为需要判断空间,所以,我们可以在判断空间的时候,如果没空间了,我们再整体前移
当然,这样的话,出队不受影响,但是入队的时候,最好的情况下,时间复杂度是O(1),最坏的情况下是O(n)
不过,没空间意味着n-1都是O(1)的复杂度,所以,只有一次时间复杂度是O(n),算下来性能也是很高的
当然,我们这是用数组实现的,用链表实现也是差不多的,只不过链表在内存中的访问不如数组快
循环队列
循环队列先第一个问题,怎么判断队列满了?
如果你想到了头或者尾加减判断,那么恭喜,不得行,因为存在队列容量没满的情况
有一种比较简单高效的办法,那就是再给队列增加一个属性,当前队列已经存了多少个元素,当队列已经存储的元素等于队列容量的时候,说明已经满了
还有一个办法,那就是 (tail位置+1)%长度=head位置
我画一幅草图来表示,蓝色代表位点,绿色代表存储的元素
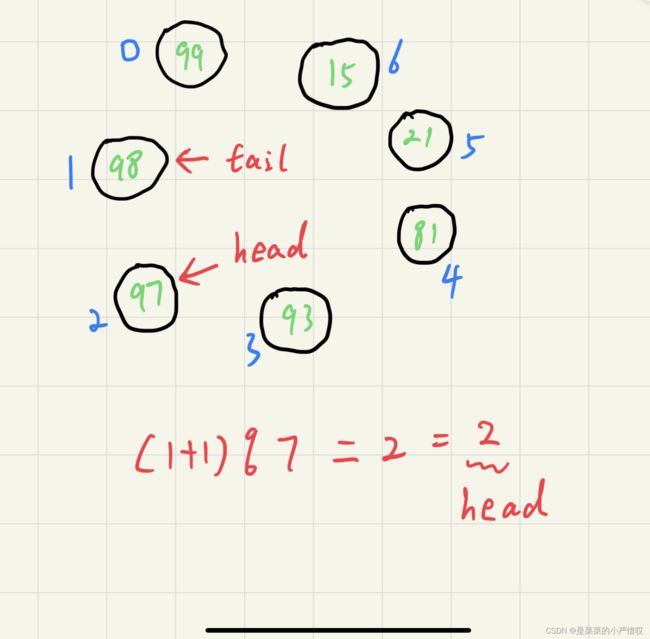
是不是能证明这个公式是对的
注意,循环链表这样的话,入队操作需要改一下
public void push(int pam) {
// 判断队列是否满了
if ((tail + 1)% dataSize == head) {
return;
}
data[tail] = pam;
// 这儿tail的下标不能采用++的方式,而应该采用取模的方式,这样可以保证不会越界,并且到头了,前面如果为空,可以再放回前面位置
tail = (tail + 1) % dataSize;
}将tail的下标计算改成这样之后,就不用再考虑扩容的问题
优先队列
优先级队列,最明显的就是会员优先级大于普通用户
实现的话,我们只要入队的时候做一个判断,做一个排序就好
阻塞队列
所谓阻塞队列,也很好理解,如果消费的时候,没有数组,那就阻塞,等着,直到有了数据,如果入队满了,也一直阻塞,等着,等着队列里有空间为止
要实现阻塞队列其实也简单,入队出队做个判断就好了,结合我们线程的知识
队列是一个很重要的数据结构,这种生产消费方式,在实际使用中十分广泛,并且为各个场景提供了解决方案
在实际使用中,一定要合理利用队列的特点和形式