ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
【写在前面】
视频识别一直以端到端学习范式为主——首先使用预训练图像模型的权重初始化视频识别模型,然后对视频进行端到端训练。这使视频网络能够从预训练的图像模型中受益。然而,这需要大量的计算和内存资源来微调视频,并且直接使用预训练的图像特征而不微调图像主干的替代方法会导致结果不佳。幸运的是,Contrastive VisionLanguage Pre-training (CLIP) 的最新进展为视觉识别任务的新路径铺平了道路。这些模型在大型开放词汇图像-文本对数据上进行了预训练,学习了具有丰富语义的强大视觉表示。在本文中,作者提出了高效视频学习 (EVL)——一种用于直接训练具有冻结 CLIP 特征的高质量视频识别模型的有效框架。具体来说,作者采用了一个轻量级的 Transformer 解码器并学习了一个查询token,以从 CLIP 图像编码器动态收集帧级空间特征。此外,作者在每个解码器层中采用局部时间模块来发现来自相邻帧及其注意力图的时间线索。作者表明,尽管使用冻结的主干进行训练很有效,但本文的模型在各种视频识别数据集上学习了高质量的视频表示。
1. 论文和代码地址

Frozen CLIP Models are Efficient Video Learners
论文地址:https://arxiv.org/abs/2208.03550
代码地址:https://github.com/opengvlab/efficient-video-recognition
2. Motivation
作为视频理解的基本组成部分,学习时空表示近年来仍然是一个活跃的研究领域。自深度学习时代开始以来,已经提出了许多架构来学习时空语义,例如传统的双流网络,3D 卷积神经网络和时空Transformer。由于视频是高维的并且表现出大量的时空冗余,因此从头训练视频识别模型效率非常低,可能会导致性能下降。直观地说,视频片段的语义意义与其每个单独的帧高度相关。先前的研究表明,图像识别的数据集和方法也可以使视频识别受益。由于图像和视频识别之间的密切关系,作为常规实践,大多数现有的视频识别模型都利用预训练的图像模型进行初始化,然后以端到端的方式重新训练所有参数以进行视频理解。
然而,端到端微调机制有两个主要缺点。首先是效率。视频识别模型需要同时处理多个帧,并且在模型大小方面比其图像对应物大几倍。微调整个图像主干不可避免地会产生巨大的计算和内存消耗成本。因此,这个问题限制了在有限计算资源下用于视频识别的一些最大图像架构的采用和可扩展性。第二个问题在迁移学习的背景下被称为灾难性遗忘。在对下游视频任务进行端到端微调时,如果下游视频信息量不足,可能会破坏从图像预训练中学习到的强大视觉特征并获得低于标准的结果。这两个问题都表明,从预训练的图像模型进行端到端微调并不总是一个理想的选择,这需要一种更有效的学习策略来将知识从图像转移到视频。
通过对比学习 、mask视觉建模和传统的监督学习,在学习高质量和通用的视觉表示方面已经做出了相当大的努力。MAE 等mask视觉建模方法训练编码器-解码器架构以重建来自潜在表示和mask token的原始图像。基于监督学习的方法使用一组固定的预定义类别标签训练图像主干。由于它们通常是单模训练的,因此它们都缺乏表示丰富语义的能力。相比之下,诸如 CLIP之类的对比视觉语言模型是使用大规模开放词汇图像-文本对进行预训练的。他们可以学习与更丰富的语言语义相一致的更强大的视觉表示。 CLIP 的另一个优势是其有前途的特征可迁移性,这为各种下游任务的一系列迁移学习方法奠定了坚实的基础。

上述原因启发作者重新思考图像和视频特征之间的关系,并设计有效的迁移学习方法来利用冻结的 CLIP 图像特征进行视频识别。为此,作者提出了一种基于轻量级 Transformer 解码器的高效视频学习 (EVL) 框架 。 EVL 与其他视频识别模型的区别如上图左所示。具体来说,EVL 学习一个查询token,以从 CLIP 图像编码器的每一层动态收集帧级空间特征。最重要的是,作者引入了一个局部时间模块,在时间卷积、时间位置嵌入和跨帧注意力的帮助下收集时间线索。最后,使用全连接层来预测视频类别的分数。作者进行了广泛的实验来证明本文方法的有效性,并发现 EVL 是一种简单有效的pipeline,具有更高的准确性,但训练和推理成本更低,如上图右所示。本文的贡献如下:
- 指出了当前端到端视频理解学习范式的缺点,并提出利用冻结的 CLIP 图像特征来促进视频识别任务
- 开发了 EVL——一种从图像到视频识别的高效迁移学习pipeline,其中作者在固定的可迁移图像特征之上训练了一个轻量级的 Transformer 解码器模块,以执行时空融合。
- 大量实验证明了 EVL 的有效性和效率。与端到端微调相比,它产生的训练时间要短得多,但性能却具有竞争力。这使得具有平均计算资源的更广泛社区可以访问视频识别这个任务。
3. 方法
本文的图像到视频迁移学习pipeline的三个主要目标是(1)总结多帧特征和推断视频级预测的能力; (2) 跨多个帧捕获运动信息的能力; (3) 效率。因此,作者提出了高效视频学习 (EVL) 框架,将在下面详细介绍。
3.1 Overall Structure

如上图所示,EVL 的整体结构是固定 CLIP 主干之上的多层时空 Transformer 解码器。 CLIP 主干从每个帧中独立提取特征。然后将帧特征堆叠以形成时空特征量,用时间信息调制,并馈入 Transformer 解码器。 Transformer 解码器执行多层特征的全局聚合:学习视频级分类token [CLS] 作为查询,并将来自不同骨干块的多个特征量作为键和值馈送到解码器块。线性层将最后一个解码器块的输出投影到类预测。形式上,Transformer 解码器的操作可以表示如下:
$$ \begin{aligned} \mathbf{Y}_{i} &=\operatorname{Temp}_{i}\left(\left[\mathbf{X}_{N-M+i, 1}, \mathbf{X}_{N-M+i, 2}, \ldots, \mathbf{X}_{N-M+i, T}\right]\right) \\ \tilde{\mathbf{q}}_{i} &=\mathbf{q}_{i-1}+\operatorname{MHA}_{i}\left(\mathbf{q}_{i-1}, \mathbf{Y}_{i}, \mathbf{Y}_{i}\right) \\ \mathbf{q}_{i} &=\tilde{\mathbf{q}}_{i}+\operatorname{MLP}_{i}\left(\tilde{\mathbf{q}}_{i}\right) \\ \mathbf{p} &=\operatorname{FC}\left(\mathbf{q}_{M}\right) \end{aligned} $$
其中$\mathbf{X}_{n, t}$表示从 CLIP 主干的第 n 层提取的第 t 帧的帧特征,$\mathbf{Y}_{i}$表示输入到 Transformer 解码器的第 i 层的时间调制特征量。$\mathbf{q}_{i}$是逐步细化的查询token,$\mathbf{q}_{0}$ 作为可学习参数,$\mathbf{p}$ 是最终预测。N、M 分别表示主干图像编码器和时空解码器中的块数。 MHA代表multi-head attention,三个参数分别是query、key和value。 Temp 是时间建模,它产生由更细粒度的时间信息调制的特征token。
3.2 Learning Temporal Cues from Spatial Features
虽然 CLIP 模型生成强大的空间特征,但它们完全缺乏时间信息。尽管 Transformer 解码器能够进行加权特征聚合,这是一种全局时间信息的形式,但细粒度和局部时间信号也可能对视频识别有价值。因此,作者引入了以下时间模块来对这些信息进行编码,然后再将特征输入到 Transformer 解码器中。
Temporal Convolution
时间深度卷积能够捕获沿时间维度的局部特征变化,并且已知是高效和有效的。形式上,这个卷积编码的特征写成 $\mathbf{Y}_{\text {conv }}$,并且
$$ \mathbf{Y}_{\mathrm{conv}}(t, h, w, c)=\sum_{\Delta t \in\{-1,0,1\}} \mathbf{W}_{\mathrm{conv}}(\Delta t, c) \mathbf{X}(t+\Delta t, h, w, c)+\mathbf{b}_{\text {conv }}(c) $$
Temporal Positional Embeddings
作者学习了一组维度为 C 的 T 个向量,表示为$\mathbf{P} \in \mathbb{R}^{T \times C}$,作为时间位置嵌入。图像特征根据它们的时间位置 t 与向量之一相加,表示为:
$$ \mathbf{Y}_{\operatorname{pos}}(t, h, w, c)=\mathbf{P}(t, c) $$
虽然时间卷积也可以隐式捕获时间位置信息,但通过使不同时间的相似特征可区分,位置嵌入更加明确。位置嵌入对于远程时间建模也更强大,为此必须堆叠多个卷积块以实现大的感受野。
Temporal Cross Attention.
另一个有趣但经常被忽视的时间信息来源是注意力图。由于注意力图反映了特征对应关系,计算两帧之间的注意力图自然会揭示对象运动信息。更具体地说,作者首先使用 CLIP 中的原始查询和关键投影构建相邻帧之间的注意力图:
$$ \mathbf{A}_{\text {prev }}(t)=\operatorname{Softmax}\left((\mathbf{Q X}(t))^{T}(\mathbf{K X}(t-1))\right)\\\mathbf{A}_{\text {next }}(t)=\operatorname{Softmax}\left((\mathbf{Q X}(t))^{T}(\mathbf{K X}(t+1))\right) $$
为简单起见,作者省略了注意力头,并在本文的实现中对所有头进行了平均。然后将其线性投影到特征维度:
$$ \mathbf{Y}_{\operatorname{attn}}(t, h, w, c)=\sum_{h^{\prime}=1}^{H} \sum_{w^{\prime}=1}^{W} \mathbf{W}_{\text {prev }}\left(h-h^{\prime}, w-w^{\prime}, c\right) \mathbf{A}_{\text {prev }}\left(t, h^{\prime}, w^{\prime}\right)+\\\mathbf{W}_{\text {next }}\left(h-h^{\prime}, w-w^{\prime}, c\right) \mathbf{A}_{\text {next }}\left(t, h^{\prime}, w^{\prime}\right) . $$
实验表明,尽管查询、关键和输入特征都是从纯 2D 图像数据中学习的,但这种注意力图仍然提供有用的信号。
最终的调制特征是通过将时间特征与原始空间特征以残差方式混合得到的,即$\mathbf{Y}=\mathbf{X}+\mathbf{Y}_{\mathrm{conv}}+\mathbf{Y}_{\text {pos }}+\mathbf{Y}_{\mathrm{attn}}$。
3.3 Complexity Analysis
Inference
考虑到只使用一个查询token,额外的 Transformer 解码器只引入了可忽略的计算开销。为了证明这一点,作者将 ViT-B/16 视为本文的图像主干,并为 Transformer 块写出 FLOPS,如下所示:
$$ \mathrm{FLOPS}=2 q C^{2}+2 k C^{2}+2 q k C+2 \alpha q C^{2} $$
这里,q、k、C、α 代表查询token的数量、键(值)token的数量、嵌入维度的数量和 MLP 扩展因子。通过这个公式,可以粗略地比较一个编码器块和解码器块的 FLOPS(h,w,t 是沿高度、宽度、时间维度的特征大小,采用常见的选择 α = 4,h = w = 14,C = 768 用于估计):
$$ \frac{\text { FLOPS }_{\mathrm{dec}}}{\mathrm{FLOPS}_{\mathrm{enc}}} \approx \frac{2 h w t C^{2}}{t\left(12 h w C^{2}+2 h^{2} w^{2} C\right)} \approx \frac{1}{6} $$
由此,可以看到,与编码器块相比,解码器块更轻量级。即使使用完整配置(每个编码器输出上都有一个解码器块,不减少通道并且启用所有时间模块),FLOPS 的增加也在主干的 20% 以内。
Training
由于使用固定骨干网和非侵入式 Transformer 解码器头(即,插入的模块不会改变任何骨干网层的输入),可以完全避免通过骨干网进行反向传播。这大大减少了内存消耗和每次训练迭代的时间。
4.实验

Kinetics-400数据集上本文方法和其他SOTA方法的对比。

上表展示了本文方法的基于CLIP方法的对比结果。

在实际硬件上测量的推理延迟和吞吐量。

训练时间比较。

作者在上表中比较了理想设置中的训练时间。
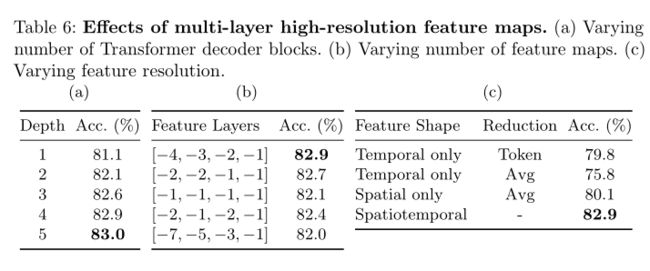
多层高分辨率特征图的效果。

不同预训练图像特征的结果。

上图展示了训练时间与冻结或微调主干的准确性。

时间信息对视频识别的影响。

Something-Something-v2 的主要结果。
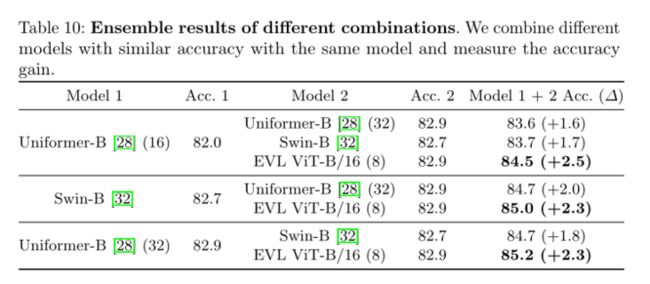
不同组合的集成结果。

在Something-Something-v2 上集成结果。
5. 总结
作者提出了一种新的视频动作识别pipeline形式:在固定的可迁移图像特征之上学习一个有效的迁移学习头。通过冻结图像主干,训练时间大大减少。此外,通过利用来自主干的多层高分辨率中间特征图,可以在很大程度上补偿由于冻结主干造成的精度损失。因此,本文的方法有效地利用了强大的图像特征进行视频识别,同时避免了对非常大的图像模型进行繁重或令人望而却步的全面微调。作者进一步表明,在开放世界环境中学习的可转移图像特征包含与标记数据集高度互补的知识,这可能会激发更有效的方法来构建最先进的视频模型。作者认为本文的观察有可能使更广泛的社区可以访问视频识别,并以更有效的方式将视频模型推向新的最先进水平。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
请关注FightingCV公众号,并后台回复ECCV2022即可获得ECCV中稿论文汇总列表。
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称

本文由mdnice多平台发布