目标检测:AugFPN(CVPR2020)
AugFPN: Improving Multi-scale Feature Learning for Object Detection
- 1. 摘要
-
- 1.1 现存问题
- 1.2 解决方法
- 1.3 性能表现
- 2. FPN缺陷分析
-
- 2.1 不同层特征的语义差距
- 2.2 最高层特征图信息丢失
- 2.3 RoI启发式分配策略问题
- 3. 算法详解
-
- 3.1 Consistent Supervision
- 3.2 Residual Feature Augmentation
- 3.3 Soft RoI Selection
CVPR2020,论文中提出了AugFPN,用于解决FPN中存在的一些缺陷
1. 摘要
1.1 现存问题
目前大多数的目标检测器都使用了特征金字塔模式,去检测多种尺度的目标,其中,FPN就是一个代表性的结构。但是,FPN中存在很多的一些缺陷,限制了多尺度特征的充分利用。
1.2 解决方法
这篇paper中,提出了一个新的特征金字塔结构,命名为AugFPN,用来解决FPN存在的问题,AugFPN主要由三部分组成:
- Consistent Supervision:在特征融合之前用来缩小不同尺度特征之间的语义差距
- Residual Feature Augmentation:在特征融合时,提取比例不变的上下文信息,以减少最高层金字塔中特征图的信息损失
- Soft RoI Selection:在特征融合之后,自适应地学习更好的RoI特征
1.3 性能表现
- 替换Faster-RCNN上的FPN为AugFPN后,分别使用ResNet50和MobileNetv2作为backbone,AP分别提高了2.3和1.6.
- 使用AugFPN的RetinaNet和FCOS,AP分别提高了1.6和0.9个点
代码地址
2. FPN缺陷分析
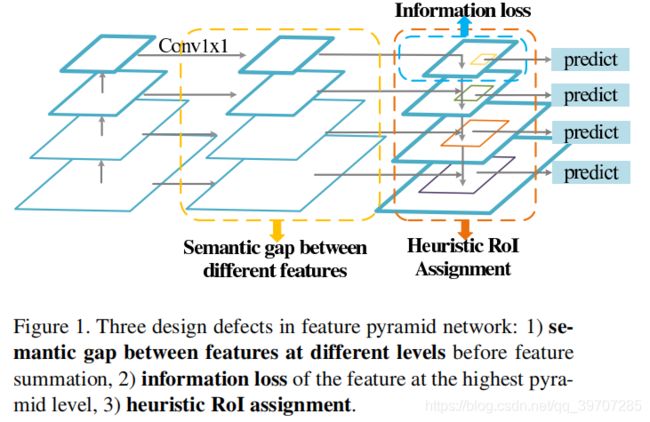
FPN可能分解为3个部分,如图1所示,分别是:
- 特征融合之前
- 自上而下的特征融合
- 特征融合之后
这三个部分都存在一定的缺点,下面逐一分析。
2.1 不同层特征的语义差距
在特征融合之前,每一层都要单独的执行1×1的卷积操作,用来减少通道数,这并没有考虑不同层之间的语义信息的差异,由于语义信息不一致,直接融合这些特征会降低多尺度特征表示的能力。
2.2 最高层特征图信息丢失
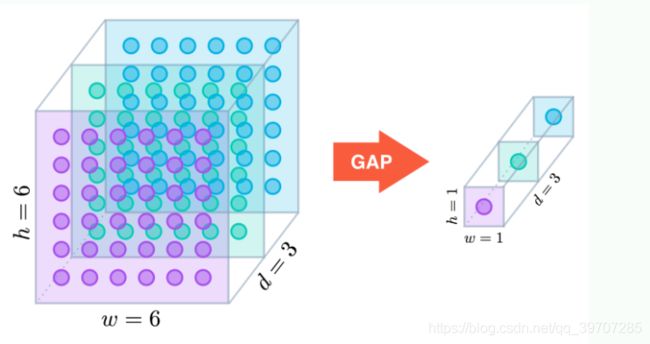
在各层之间进行特征融合时,特征以自上而下的方式传播,低层特征可以通过更高层次特征的更强语义信息进行改进,但是,由于通道数的减少,最高金字塔层的特征反而丢失了信息。有的论文中采取全局池化(Global Average Pooling,GAP),提取全局上下文特征可以减轻信息丢失,但是这种将特征融合为一个向量的策略可能会丢失空间关系和细节,因为在一幅图像中可能会出现多个对象。
2.3 RoI启发式分配策略问题
FPN在特征融合之后,每个特征层单独的对每个对象方案进行细化,不同层对应不同尺度的目标检测,例如底层用来检测小目标,高层用来检测大目标。但不同层对不同尺度的目标都会有一定的语义表达,这显然被忽略了。
在PANet中对于这个问题处理方法是,如上图所示,汇集所有金字塔层的RoI特征,不同层之间进行max-fusion,但这样做会忽略响应较小的特征,这些特征可能也有帮助,这样仍不能充分利用其他级别的特征,而且额外的全连通层显著增加了模型参数。
3. 算法详解

AugFPN整体的网络结构如图2所示,和FPN一直,特征金字塔各层分别选自 { C 2 , C 3 , C 4 , C 5 } \{C_2,C_3,C_4,C_5\} {C2,C3,C4,C5},特征映射相当于输入图片的 { 4 , 8 , 16 , 32 } \{4,8,16,32\} {4,8,16,32}。 { M 2 , M 3 , M 4 , M 5 } \{M_2,M_3,M_4,M_5\} {M2,M3,M4,M5}是使用1×1卷积后,特征通道减少的特征。 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5}是由特征金字塔产生的特征,以下小节将讨论AugFPN的三个组成部分。
3.1 Consistent Supervision
先回顾一下FPN,FPN利用网络中的特征层次结构来生成具有不同分辨率的特征映射来构建特征金字塔,为了融合不同尺度的的特征,使用了上采样后叠加的方式,但是,不同尺度的特征包含着不同抽象层次的信息,它们之间存在着较大的语义差距,虽然FPN所采用的方法简单有效,但融合多个具有较大语义差距的特征会导致一个次优的特征金字塔。
本文提出的 Consistent Supervision在融合前对多尺度特征施加相同的监督信号,以缩小它们之间的语义差距,首先在backbone多个特征层 { C 2 , C 3 , C 4 , C 5 } \{C_2,C_3,C_4,C_5\} {C2,C3,C4,C5}中建立特征金字塔,然后在特征金字塔层 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5}使用 Region Proposal Network (RPN) 生成RoIs,每一个RoI映射到所有的特征层中,并通过RoI-Align得到 { M 2 , M 3 , M 4 , M 5 } \{M_2,M_3,M_4,M_5\} {M2,M3,M4,M5}每个层的RoI特征,然后在这些特征图上添加多个分类、回归head,得到loss。这些分类和回归head共享在不同的层次上的参数,可以进一步迫使不同的特征映射在相同的监督信号之外学习相似的语义信息。为了获得更稳定的优化结果,使用一个权重来平衡一致监督产生的辅助损失和初始损失,具体公式如下:
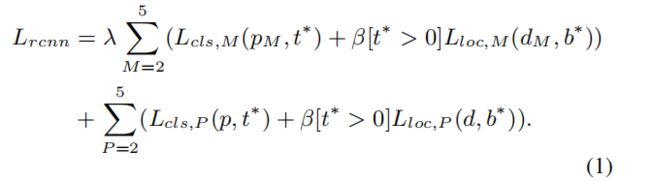
L c l s , M L_{cls,M} Lcls,M和 L l o c , M L_{loc,M} Lloc,M是在特征图 { M 2 , M 3 , M 4 , M 5 } \{M_2,M_3,M_4,M_5\} {M2,M3,M4,M5}上的loss, L c l s , P L_{cls,P} Lcls,P和 L l o c , P L_{loc,P} Lloc,P是在金字塔特征层 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5}上的loss, P M P_M PM, d M d_M dM和 p p p, d d d分贝是特征图和金字塔层的预测结果, t ∗ t^* t∗和 b ∗ b^* b∗分别是分类和回归的GT, λ \lambda λ用来平衡辅助loss和原始loss的权重, β \beta β是用来平衡分类和回归loss的权重, [ t ∗ > 0 ] [t^* >0] [t∗>0]定义如下:
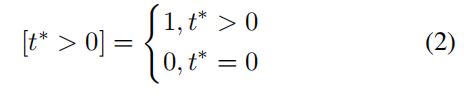
在预测阶段,会吧辅助分支去掉,只使用特征金字塔上的分支去预测,因此 Consostent Supervision没有增加额外的参数和计算量在推理阶段。
3.2 Residual Feature Augmentation
在FPN中,最高层M5的特征图采用自顶向下的方式传播,并与低层的特征图{M4,M3,M2}逐步融合。一方面,利用高层语义信息对低层特征映射进行增强,从而使特征自然地被赋予不同的上下文信息,另一方面,M5层由于减少了特征通道而导致信息丢失,并且只包含与其他级别的特征不兼容的单尺度上下文信息。
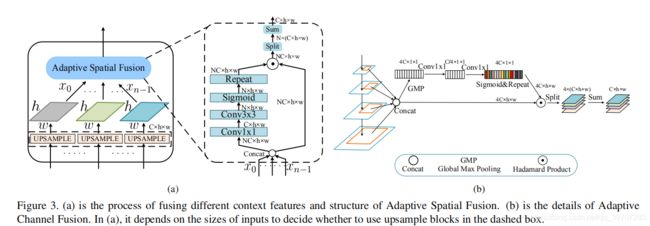
基于这个特点,提出了 Residual Feature Augmentation,利用残差分支向原始分支注入不同的空间上下文信息,改进M5的特征表示。期望空间上下文信息能够减少M5信道中的信息损失,同时提高特征金字塔的性能。
在C5层使用比例不变自适应池化,生成多个尺度的特征图( α 1 × S , α 2 × S , . . . , α n × S \alpha_1 ×S,\alpha_2 ×S,...,\alpha_n ×S α1×S,α2×S,...,αn×S),然后各自使用1×1的卷积核生成256通道的输出,最后,通过双线性插值将它们上采样到S的尺度,以便进行后续融合。考虑到插值会引起的混叠效应,设计了一个模块 Adaptive Spatial Fusion (ASF) 去自适应地组合这些上下文特征,而不是简单的相加,ASF的细节如图3a所示。ASF将上采样的特征作为输入,并为每个特征生成一个空间权重图,利用权值将上下文特征聚合为M6,并赋予其多尺度的上下文信息。
由ASF生成M6后,通过求和与M5相结合,传播到与其他低层特征融合,最后,在每个特征映射上附加一个3×3的卷积层来构造一个特征金字塔 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5}。
比例不变自适应池化与PSP的不同之处在于,PSP池化具有固定大小的多个特征,而比率不变性自适应池化则考虑了图像的比率,这对于目标检测来说效果更好。
3.3 Soft RoI Selection
在FPN中,每个RoI的特征都是通过集中在一个特定的特征层上获得的,该特征是根据感兴趣区域的尺度来选择的。通常来说,较小的RoI分配给较低层,而较大的RoI分配给较高层。在这种策略下,可能会将两个大小相似的RoI分配到不同的级别。这可能会产生次优结果,因为不清楚哪个特征层包含RoI的最重要信息。 如何设计一个完美的策略来分配RoI是一个挑战。
PANet通过汇集来自各个层次的RoI特征,使用RoI特征中的最大值,并使用全连接层来优化候选框。它提高了实例分割的性能,但额外的全连接成显著增加了参数量。另外,使用最大值操作只选择响应最高的特征点,而忽略其他可能有利于识别的低响应特征点,这可能会阻碍不同层次的特征得到充分利用。
因此,提出了 Soft RoI Selection,它通过参数化RoI池化的过程,从各个金字塔级别的特征中学习生成更好的RoI特征。Soft RoI Selection引入了自适应权重来更好地度量ROI区域内不同层次特征的重要性,最终的RoI特征是基于自适应权重的,而不是启发式的RoI分配或最大值操作。
具体来说,我们首先为每个RoI汇集所有金字塔级别的特性,然后,我们开发了一个自适应空间融合模块 Adaptive Spatial Fusion module (ASF) 来自适应地融合这些特征,而不是像PANet那样使用全连接层来调整RoI特征。它从不同层为RoI特征生成不同的空间权重图,并将RoI特征与加权聚合相融合,ASF仅由两个卷积层组成,与PANet中使用的额外全连接层相比,ASF消耗的参数要少得多,这样, Soft RoI Selection参数化了RoI池化的过程。它可以通过与网络中其他组件的反向传播来学习,而不依赖于启发式设计的策略。