如今NLP可以说是预训练模型的时代,希望借此抛砖引玉,能多多交流探讨当前预训练模型在文本分类上的应用。
1. 任务介绍与实际应用
文本分类任务是自然语言处理(NLP)中最常见、最基础的任务之一,顾名思义,就是对给定的一个句子或一段文本使用文本分类器进行分类。根据文本分类的类别定义,可以分为二分类/多分类、多标签、层次分类,以下面的新闻分类为例:
- 二分类/多分类也即标签集中有两个或以上的标签类别,每个样本有且只有一个标签
- 多标签也即样本可能有一个或多个标签
- 层次分类是特殊的多分类或多标签任务,数据集的标签之间具有层次关系。比如下图样本的一级标签是体育,二级标签是足球,体育为足球的父标签。

文本分类广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等日常或专业领域中。
- 情感分析:情感分析是针对数据的情感倾向进行分类,可以是二分类(正向或负向)或者是多分类(按照不同的细粒度划分情感),情感分析在影音评论、商品评价、舆情分析、股民基金情感分析等都有重要的应用。
- 主题分类:主题分类也是常见的文本分类应用场景,根据内容或标题进行分类,即可以是多分类、多标签也可以是层次分类,根据实际场景需要进行标签体系构造和划分。
- 金融数据分类:金融数据繁多复杂,文本分类可以应用于金融新闻分类、股民评论情感分析、基金类型分类、金融问答分类、金融情绪分析等多种任务,有助于从大量数据挖掘有效信息。
- 医疗数据分类:目前,文本分类已有许多医疗领域的成功应用,如药物反应分类、症状和患者问题分类,健康问答分类、电子病历分类、药品文本分类等等。
- 法律数据分类:文本分类在法律领域也有许多成果的探索,如罪名分类、案情要素分类、刑期预测、法律条文分类、法律情感分析、判决预测、法律文本挖掘、合规审查等等,帮助我们从海量的法律数据抽取有效信息。
2. 文本分类中文数据集
2.1 多分类数据集
- THUCNews新闻分类数据集: THUCTC: 一个高效的中文文本分类工具
- 百科问答分类数据集: GitHub - brightmart/nlp_chinese_corpus: 大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
- 头条新闻标题数据集(tnews):https://github.com/aceimnorst...
- 复旦新闻文本数据集:工作台 - Heywhale.com
- IFLYTEK app应用描述分类数据集:https://storage.googleapis.co...
- CAIL2018 刑期预测、法条预测、罪名预测 https://cail.oss-cn-qingdao.a...
- CAIL 2022事件检测: LEVEN
2.2 情感分类数据集
- 亚马逊商品评论情感数据集:https://github.com/SophonPlus...
- 财经新闻情感分类数据集: https://github.com/wwwxmu/Dat...
- ChnSentiCorp 酒店评论情感分类数据集:ChineseNlpCorpus/datasets/ChnSentiCorp_htl_all at master · SophonPlus/ChineseNlpCorpus
- 外卖评论情感分类数据集:https://github.com/SophonPlus...
- weibo情感二分类数据集:https://github.com/SophonPlus...
- weibo情感四分类数据集:https://github.com/SophonPlus...
- 商品评论情感分类数据集:https://github.com/SophonPlus...
- 电影评论情感分类数据集:https://github.com/SophonPlus...
- 大众点评分类数据集:https://github.com/SophonPlus...
2.3 多标签数据集
- 学生评语分类数据集:https://github.com/FBI1314/te...
- CAIL2019婚姻要素识别 【快速上手ERNIE 3.0】法律文本多标签分类实战 - 飞桨AI Studio
2.4 层次分类数据集
- 头条新闻标题分类(tnews的升级版):https://github.com/aceimnorst...
- 网页层次分类数据集: 网页层次分类数据集CSRI_CONTAM_PAGE-网络空间安全研究院-国家网络空间安全人才培养基地
- Chinese Medical Intent Dataset(CMID): https://github.com/liutongyan...
- 2020语言与智能技术竞赛事件分类:keras_bert_multi_label_cls/data at master · percent4/keras_bert_multi_label_cls
3. 预训练模型简介
随着Transformer 和 Bert 的出现,NLP模型大步跨向了预训练模型的时代,刚入门的NLP的同学可能会疑惑什么是预训练模型?预训练模型和文本分类模型是什么关系?我该使用什么预训练模型?只有CPU能训练吗?怎么开源加载预训练模型?
什么是预训练模型?
通常来说模型复杂度越高参数越多,模型越能拟合复杂的问题,模型的预测精度越高。随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合,而构建大规模的标注数据集非常困难(成本过高,标数据的苦ಥ_ಥ)。所以目前的做法是先在超大规模的语料采用无监督或者弱监督的方式训练模型,模型能够获得语言语义、语法相关的知识,然后再用具体的任务数据训练,这样的模型称为预训练模型。
预训练模型首先会将输入的句子使用分成多个token,英文句子通常是subword-level的分词策略,中文句子由于最小的单位就是字,所以通常是一个字符即为一个token,例如句子 "今天是个好天气!" 切分为8个token ['今', '天', '是', '个', '好', '天', '气', '!'];在多语言模型中也有将词作为token的情况,还是上面的例子,句子切分为5个token ['今天', '是个', '好', '天气', '!']。(分词细节可以参见 tokenizers小结)
此外,模型会在每个输入的开头加入一个[CLS]的token,在句子对间加入一个[SEP]的token。如下图所示,每个输入token会映射为一个对应的特征表示,经过预训练模型得到每个token的输出特征表示,token输出的特征表示会用于不同的任务,[CLS]的输出特征通常被认为是整个句子的语义表示。

接下来就是预训练,不同预训练模型的预训练方式略有不同,常用的无监督任务包括MLM和NSP任务:
- Mask Language Model(MLM):掩码预测任务,也即将一个句子中某一个token用掩码[MASK]替换,然后让模型预测出这个token。例如:"今天出太阳了,是个[MASK]天气",希望模型预测[MASK] -> 好。具体来说就是用[MASK]的模型输出特征,后接一个分类器进行分类。
- Next sentence Prediction(NSP):从文章中摘取两个句子A和B,50%是上下文关系,50%不是,训练模型预测句子A和句子B是否为上下文关系,也即在[CLS]的模型输出特征后接一个分类器进行二分类。
关于预训练模型结构和训练细节就不在这里赘述了,现在已经有许多写的很好文章讲解。
预训练模型和文本分类模型关系?
预训练模型学习到的文本语义表示能够避免从零开始训练模型,他们之间的关系可以直观地理解为,预训练模型已经懂得了相关句法、语义的语言知识,用具体任务数据训练使得预训练模型”更懂”这个任务,在预训练过程中学到的知识基础使学习文本分类任务事半功倍。

我该使用什么预训练模型?
目前已经有许多开源的预训练集模型,虽然英文预训练模型有GLUE 榜单,中文预训练模型有CLUE榜单,多语言模型有XTREME榜单,但选择模型还是要根据具体的任务和硬件条件进行选择。我中文分类任务做的比较多,我常用的预模型包括 ERNIE (多尺寸模型选择真的香)、Roformer-v2、Mengzi、RoBERTa-wwm-ext。
只有CPU能训练吗?
能,但耗时比较长。CPU开发者推荐使用层数比较少的小模型,或选择白嫖一些在线AI平台免费算力比如AI Studio(每天白嫖8小时V100,Paddle)、Google Colab(要,Pytorch Tensorflow都支持)。
怎么加载开源的预训练模型?
目前最方便的方法就是在PaddleNLP(Paddle)或 HuggingFace(Pytorch)直接根据模型名称使用AutoModel的方式调用,也可以在github上找开源模型参数下载链接。
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME)4. 基于预训练模型的文本分类算法
讲了这么多,终于到文本分类算法介绍了。文本分类算法最最常用的就是模型微调,当然也还包括在最近讨论度很高的预训练新范式提示学习(Prompt Tuning),之前看到基于检索的方法做文本分类也还蛮有意思的。
4.1 常用方法——预训练模型微调
基于预训练模型微调的想法非常简单直接,也即将[CLS]的模型输出特征表示作为输入句子的特征表示,通常为768维或1024维的向量,然后接入一个线性分类器(通常为单层全连接层)进行文本分类任务训练。

4.2 小样本——提示学习(Prompt Tuning)
近来,提示学习的火热,主要还是在小样本场景的优秀表现。
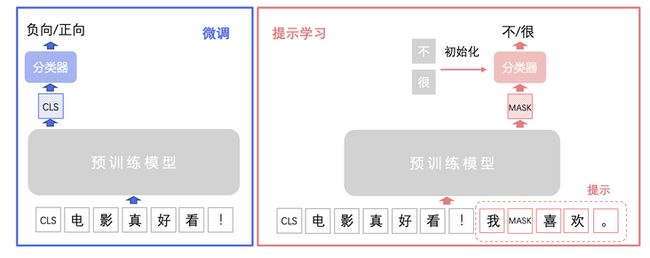
提示学习的主要思想是将文本分类任务转换为构造提示(Prompt)中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]模型输出特征后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。
我们以下图情感二分类任务为例来具体介绍提示学习流程。在输入文本后加入构造提示"我[MASK]喜欢。",将"负向"或"正向"的情感二分类任务转化为掩码[MASK]"不"或"很"的二分类任务,构造提示[MASK]分类器预测分类与原始标签的对应关系为"不"->"负向" 、"很"->"正向" 。具体实现方法是在掩码[MASK]的输出向量后接入线性分类器(二分类),然后用"不"和"很"的预训练向量来初始化分类器进行训练。
4.3 创新方法——检索
除了以上两种方法,还试过用检索的方式做文本分类。检索的方法适合标签类别较多或者是标签类别不固定(有时候会新增标签)。
基于检索的方法做文本分类有两种思路,一种是把标签集作为召回库,一种是把训练数据作为召回库。这两种思路在训练阶段的方法是一致的,可以用双塔模型(也就是两个预训练模型),一个模型输入句子,另一个模型输入标签,进行训练拉近句子和标签的[CLS]输出特征表示之间距离。在预测阶段,召回集有所不同:
思路一把标签作为召回集,每个标签的向量表示(也即[CLS]输出特征表示)是固定的,我们构建一个标签向量库。我们用待预测的句子的向量在标签向量库进行检索,找到特征相似度最大的标签,也即为待预测句子的标签。
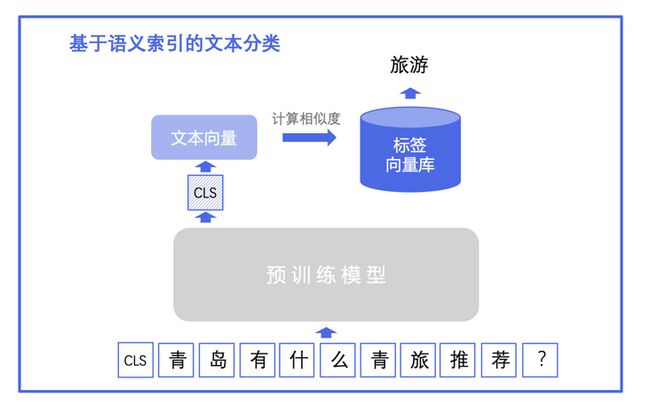
思路二则是把训练数据作为召回集,构建一个训练集文本的向量库,我们用待预测的句子的向量表示(也即[CLS]输出特征表示)在文本向量库进行检索,找到特征相似度最大的训练集文本,待预测句子的标签也即召回文本的标签。
5. 文本分类实战
接下来将带你快速使用PaddleNLP完成实现多分类、多标签、层次分类任务。你可以仿照数据集格式,替换数据集目录,直接训练你自己的数据:
- 多分类实践代码notebook(只有一个标签)https://aistudio.baidu.com/ai...
- 多标签实践代码notebook(有一个或多个标签):
https://aistudio.baidu.com/ai... - 层次分类实践代码notebook(标签间存在层次关系):
https://aistudio.baidu.com/ai...
最好用GPU跑,比较快
代码详解 施工ing
6. 实践经验总结
6.1 数据为王时代
在实践代码开始之前更想讨论一下数据,我个人的实践经验来说,提高文本分类精度最快、最有效的方法是既不是模型,也不是算法调参,而是数据质量。文本分类总的来说不是个复杂的自然语言处理任务(甚至可以说是最基本的任务),如何更好地进行数据标签地划分减少混淆重合情况和高质量的数据标注(正确标注,标准统一,且训练集与预测数据分布一致)是得到高精度的文本分类模型的关键。
- 标签体系划分。文本分类任务的标签体系依具体的任务而定,没有固定标准,一个清晰分界明确的标签体系有利于数据标注和分类。如果是多分类任务的话尽量减少标签之间范围重合,这样有助于标注标准的统一,减少出现在标注的时候相似的样本有的被标记为A,有的标记为B,降低准确率。
- 标注正确。"Garbage in, garbage out(垃圾进,垃圾出)",如果训练数据包含很多错误,可想而知模型不会有很好的预测结果。人工检查所有数据标注是否准确,成本不低,因此可以通过一些算法计算训练数据对模型的扰动,来筛选出脏数据进行重新标注。(这点之后会写新的文章细讲)
- 训练数据和预测数据分布一致。深度学习模型可以理解为拟合训练数据的分布,虽然大规模语料预训练,能够有效帮助模型有更好的泛化能力,但只有模型学习与预测场景相似的训练样本,才能在预测数据有更好的表现。在实践场景中遇到许多效果不好的基本是这个问题,比如遇到多标签分类训练集的数据只有一个标签,模型理所应当倾向于只预测一个标签,而测试集有多个标签,效果可想而知不太好。
- 文本数据精选有效信息。目前预训练模型通常支持的max_length最大为512,有些模型可能会应用一些策略使模型能够接受输入长度最长2048,当然还有一些支持长文本的模型例如Longformer,ERNIE-Doc。但输入文本过长,容易爆显存,训练速度过慢,并且由于文本包含过多无用的信息干扰使模型效果变差。因为文本数据十分多样,如何精选文本数据需要按实际数据而定,常见方法按句号对句子截断、利用一些正则式匹配的方法筛选有效文本内容等。
- 充足的数据。虽然文本分类在零样本和小样本领域有许多探索,但效果暂时还是很难超越在充足训练数据进行微调。充足的数据优先的方法当然是选择数据标注的方式,数据增强策略也是常见扩充数据的方法。
总而言之,高质量的训练数据是高精度文本分类模型的关键。
6.2 实践经验记录
现实场景中的数据并不总是那么理想,需要根据一些实际情况进行灵活变化。使用的也许不一定是最好的解法,欢迎各位大佬们讨论。
- 文本分类的类别非常多,几百上千甚至万级别。这时候用预训练模型微调的方法,效果表现可能非常一般甚至可能难以收敛。如果还要使用预训练模型微调的话,建议是使用多个分类模型,先训练一个文本分类模型(大类分类器)把数据分为具体的大类,每个大类再训练一个文本分类模型(子类分类器)对样本类别进行预测(缺点就是要训练多个分类器);另一个方法就是用检索的方法去做,不再是分类,而是召回与文本最相似的标签。
- 多分类任务预测可能会出现训练集没有出现的类别,希望可以预测成"其他"。前面也提到训练数据最好与预测数据一致,否则效果可能有限,但现实场景还是很难避免。最直接的想法是在多分类中构建一个"其他"的类别,但这种方法也有缺点,比如就是训练的时候一点其他类别的数据没有,另外也可能由于"其他"类别的数据分布差异很大,导致这个类别预测效果较差。最终选择的实践方法是使用多标签的方式进行训练,然后预测时候选择置信度最高的类别作为标签类别,如果置信度低于阈值(比如0.5),则这个类别为"其他"。训练的时候,如果有"其他"类别的数据,则该数据的标签为[0,0,0...,0]。
- 关于调参。超参数设置我自己常用的是learning rate [1e-5,3e-5,5e-5],batch size[16, 24, 32],使用早停策略,选择开发集精度最高的模型参数。如果要进一步提高精度的话,会选定epoch数(不使用早停策略)应用warmup策略。个人感觉,超参设置对模型效果影响不大(除非把batch size设为1,learning rate设的超大或超小这种),warmup策略也是小幅度的提高,在文本分类任务通过调参实现精度10%幅度这种大提高的可能性非常小。(参考:CLUE超参搜参结果)
7.参考
BERT 论文: https://arxiv.org/pdf/1810.04...
PaddleNLP文本分类应用:PaddleNLP/applications/text_classification at develop · PaddlePaddle/PaddleNLP