Learning to Compare: Relation Network for Few-Shot Learning
Learning to Compare: Relation Network for Few-Shot Learning
作者解读
一、Abstract
提出构建一个 关系网络(Relation Network)来让其学习如何比较(Learning to Compare),从而实现 少样本学习(Few-Shot Learning)。
元学习阶段,在每一个episode,针对少量的图片学习一个深度距离度量,此设计方式在模仿小样本学习。
所提网络,通过计算query图片和每一个新的类别图片的关系得分,此过程无需进一步更新网络就可以对新的类别图片进行分类。
二、Introduction
这个框架可以在每类给定少量样本的情况下学习识别出新的类别(训练集没有出现的类)。
适用于 Few-shot 和 Zero-shot 学习。
三、Related Work
1.Learning to Fine-Tune 学习微调
MAML 旨在元学习初始条件(神经网络权重集),该初始条件有利于微调 few-shot 问题。策略:给定神经网络的权重配置,在几个梯度下降更新步骤内完成对少样本问题的微调,每个目标问题的成功微调都会驱动基础模型的更新优化。
few-shot优化 更近一步,在良好初始条件基础上,还有一个基于 LSTM 的优化器。
本文:以完 完全前馈 的方式解决目标问题,不需要模型更新,
2.RNN Memory Based 基于RNN内存
RNN 迭代给定问题的示例,在外部内存中积累解决问题所需的知识。
本文:避免循环网络的复杂性,确保内存充足性。由简单快速的前馈神经网络定义。
3.Embedding and Metric Learning Approaches 嵌入和度量学习方法
方法一: 学习一组投影函数,该函数从目标问题中获取query图像和sample图像,用前馈方式进行分类。
方法二: 根据sample set 参数化前馈分类器的权值。
基于度量的学习:学习一组投影函数,在嵌入表示时,可以使用简单最近邻或线性分类器识别。元学习的可迁移知识是 投影函数 ,目标问题是一个简单前馈计算。
学习一个 embedding 函数,将输入空间(例如图片)映射到一个新的嵌入空间,在嵌入空间中有一个相似性度量来区分不同类。我们的先验知识就是这个 embedding 函数,在遇到新的 task 的时候,只将需要分类的样本点用这个 embedding 函数映射到嵌入空间里面,使用相似性度量比较进行分类。
知乎链接
三、Methodology
1.Problem Definition
三个数据集:training set / support set / testing set 。 support set 和 testing set 共享标签空间,training set 有独立标签空间,不相交。
在 training set 元学习提取可迁移知识,使能够在 support set 上进行 few-shot learning , 在test set 上更好的进行分类。
每次迭代,在 training set随机从 C C C 个类中抽取 K K K 个带标签的样本作为 sample set S S S,再取 C C C 个类中剩余样本的一部分作为 query set Q Q Q,sample/query set 类比 support/test set 。
本文:one-shot five-shot
2.Model
-
One-shot
RN 由两个模块:embedding 模块 f φ f_\varphi fφ ,relation 模块 g ϕ g_\phi gϕ
Q Q Q 中样本 x j x_j xj , S S S 中样本 x i x_i xi ,通过embedding 产生 f φ ( x i ) f_\varphi(x_i) fφ(xi) 和 f φ ( x j ) f_\varphi(x_j) fφ(xj) ,通过深度特征图串联得到 C ( f φ ( x i ) , f φ ( x j ) ) \mathcal C (f_\varphi(x_i),f_\varphi(x_j)) C(fφ(xi),fφ(xj))。
将sample和query的组合特征映射输入 g ϕ g_\phi gϕ, 得到一个0-1的标量,表示 x i , x j x_i,x_j xi,xj 之间相似性(关系评分)。

-
K-shot
对训练输入进行元素求和,形成该类的特征映射,将池级类特征映射与query特征映射结合。 -
Objective function
使用 mean square error (MSE) 作为损失函数。
0-不相似,1-相似

3.Zero-shot Learning
zero-shot 就是把输入从 one-shot 一个图片变成一个向量。
4.Network Architecture
Figure 2: Relation Network architecture for few-shot learning (b)
which is composed of elements including convolutional block (a).
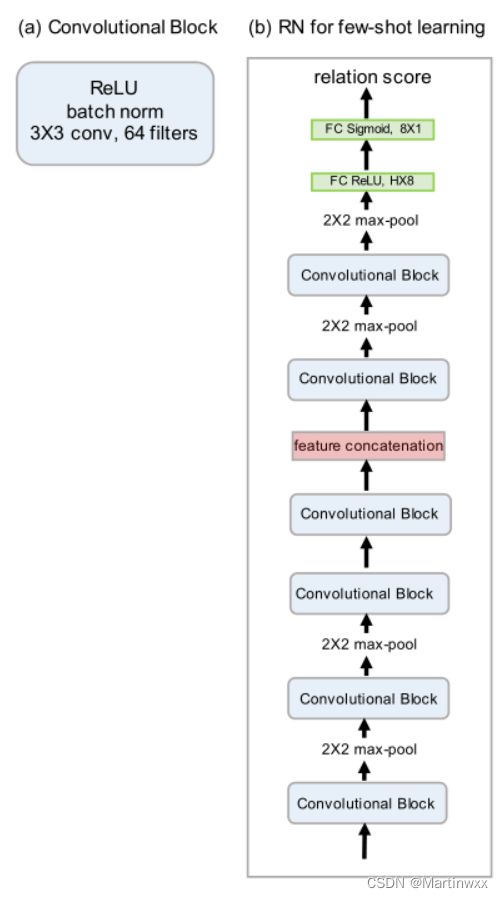
Figure 3: Relation Network architecture for zero-shot learning

四、Experiments
few-shot数据集: Omniglot and miniImagenet
zero-shot数据集:Animals with Attributes (AwA) and Caltech-UCSD Birds-200-2011 (CUB).
1.Few-shot Recognition
Setting :
使用 Adam ,初始学习率 1 0 − 3 10^{-3} 10−3 , 每100,000 episodes 退火一半,端到端训练。
学习率退火 :在训练神经网络时,学习率都是随着训练而变化,这主要是由于在神将网络训练后期,如果学习率过高,会造成loss的震荡,但是如果学习率减小的过快,又会造成收敛变慢的情况。
Baseline :
对比: 神经网络,微调/不微调的 匹配网络,MANN,带记忆存储的孪生网络,卷积孪生网络,MAML, Meta Nets,原型网络,基于LSTM的元学习
①Omniglot
Dateset:
来自50个不同字母,1623个类,每类有20个样本,通过旋转90°,180°,270°,来得到新类。1200原始数据+旋转 作为 training,余下423原始数据+旋转 作为 testing
Training:
每个 training episode:
K K K 样本图 , C C C 类
5-way 1-shot :19 个query
5-way 5-shot:15个query
20-way 1-shot:10个query
20-way 5-shot:5个query
相当于:一个 training episode/mini-batch ,有 19 × 5 + 1 × 5 = 100 19 \times 5 + 1 \times 5 =100 19×5+1×5=100 个图片样本。
②miniImageNet
Dateset:
有60,000 张彩色图片,100个类,每个类有600样例,按照[29]进行分类,用64类,16类,20类 分别用于 训练 验证 测试。16验证类仅用于检测泛化性能。
Training:
每个 training episode:
K K K 样本图 , C C C 类
5-way 1-shot :15 个query
5-way 5-shot:10个query
相当于:一个 training episode/mini-batch ,有 15 × 5 + 1 × 5 = 80 15 \times 5 + 1 \times 5 =80 15×5+1×5=80 个图片样本。
输入图像大小调为 84 × 84 84 \times 84 84×84
[29] S. Ravi and H. Larochelle. Optimization as a model for few-shot learning. In ICLR, 2017. 1, 2, 4, 5, 6
2.Zero-shot Recognition
Datasets and settings:
两种 ZSL 设置进行training/test 分割:old setting / new GBU setting[42]
[42] Y. Xian, C. H. Lampert, B. Schiele, and Z. Akata. Zero-shot learning-a comprehensive evaluation of the good, thebad and the ugly. arXiv preprint arXiv:1707.00600, 2017. 5,6, 7
old setting 使用两个广泛使用的ZSL基准:
①AwA:50个种类动物,30745张图像。有固定的划分:40个 training 类,10个test 类。
②CUB :200个种类的鸟,11788张图像,有150个可见类,50个不相交的不可见类。
设置了三个数据集:AwA1、AwA2和CUB 。
新发布的AwA2由50个类的37322张图像组成。
Semantic representation:
AwA :使用连续85维类级属性向量。
CUB:使用连续312维类级属性向量。
Implementation details:
使用两种 embedding模块用于两种输入:
old setting 中使用Inception-V2将query embedding进DNN
GBU中使用ResNet101进行embedding
取顶层池化单元作为图像嵌入,维度分别是1024 和 2048。
用MLP网络嵌入语义属性向量。
对于AwA 和 CUB 隐藏层 FC1 大小为 1024 和1200,输出大小 FC2 设置与 图像嵌入 的维度一致。
关系模块:将图像和语义嵌入 级联,分别输入AwA 和 CUB,隐藏层FC3 大小为 400 和 1200的MLPs。
在FC1&2 加入 L 2 L2 L2 正则化权重衰减。用 正则化 将 语义特征向量 映射到 视觉特征空间 来解决 ZSL中跨模态映射中存在的枢纽问题 。
使用 FC3&4 计算 语义表示(在视觉特征空间中) 与 视觉表示之间的关系 。
所有ZSL模型都使用 1 0 − 5 10^{-5} 10−5 的权值衰减训练。
学习率用 Adam 初始化为 1 0 − 5 10^{-5} 10−5,每20w退火一次。
Results under the old setting
使用属性向量作为样本类嵌入,模型在AwA上取得有竞争力的结果,在CUB上取得最优性能。

Results under the GBU setting
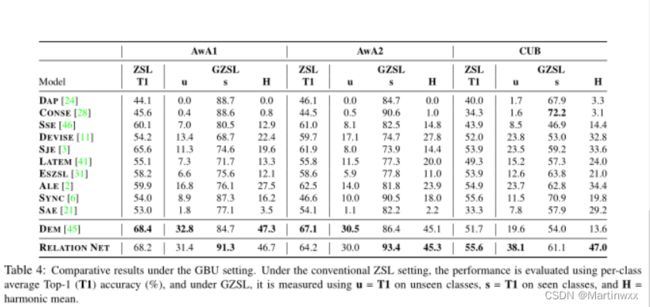
五、Why does Relation Network Work?
1. Relationship to existing models
传统 Few-shot 工作使用预先设定的距离度量,欧氏距离、余弦距离等。可视为远程度量学习,学习过程发生在特征嵌入,且使用固定度量。浅层学习 马氏度。
相比于 固定度量、浅层学习的度量, 关系网络 可视为 学习深度嵌入和深度非线性度量(相似函数)。
通过灵活的函数逼近器学习相似性,以数据驱动方式学习一个良好的度量。
2.Visualisation
每个样本输入(像素)根据它是否匹配固定的查询被着色。
