联邦学习在腾讯微视广告投放中的实践

分享人:宋凯 博士
整理者:林宜蓁
导读:
本文从广告主的角度,分享联邦学习实践的经验跟思考。
先介绍业务与技术选型背景:团队项目为用户增长及成本控制,方式为广告渠道投放,投放目标分为拉新、拉活两类。
-
拉新时,微视侧端内用户特征稀疏,而广告平台积累大量信息,但仅有有限性的oCPX标准化数据回传。
-
拉活时,微视侧具备用户行为序列等宝贵画像数据,与广告平台特征有互补性,但又无法直接粗暴的与广告平台共享数据。
所以,希望微视侧能与广告平台侧利用双方数据,实现收益共赢,但保证数据的安全不出域。在这种背景下我们团队选择了“联邦学习”,其为多方安全合作提供了一种解决方案。
文章围绕下面五点展开:
-
联邦学习
-
腾讯联邦学习平台 PowerFL
-
微视广告投放整体业务
-
广告投放联邦学习架构
-
建模实践和细节介绍
一、联邦学习
首先,简介联邦学习(Federated Learning,FL)的先导知识。
1. 联邦学习背景
机器学习模型都是 data-driven,但现实里数据皆为孤岛:公司与公司之间、甚至部门与部门之间无法共享数据;直接的共享会侵犯用户的隐私,也损伤公司的利益。2016年 Google 的文章以输入法 NLP 为背景,提出用安卓手机终端在本地更新模型,这篇文章一般被认为是联邦学习的开端。随即,我国微众银行、腾讯等公司也做了许多开创性的工作。
联邦学习的基本定义为:在进行机器学习的过程中,各参与方可借助其他方数据进行联合建模。各方无需直接触达他方数据资源,即数据不出本地的情况下,安全进行数据联合训练,建立共享的机器学习模型。
2. 联邦学习的两种架构
-
中心化联邦架构:早期发展包括 Google、微众银行,皆是此类架构。由可信赖的第三方(中央服务器)负责加密策略、模型分发、梯度聚合等。
-
去中心化联邦架构:有时双方合作,找不到可信赖的第三方,各方需参与对等计算。此架构需要更多的加解密和参数传输操作,比如:n方参与时,需进行2n(n-1)次传输。这里可以认为加解密算法实际上扮演了第三方的角色。
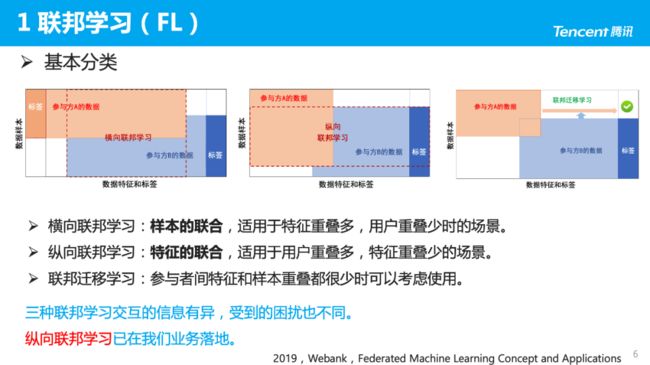
3. 联邦学习的三种分类
-
横向联邦学习:样本的联合,适用于特征重叠多,用户重叠少时的场景。比如:两个业务相似的公司,用户正交多但画像相似,可进行横向联邦学习,更像是一种数据变形的分布式机器学习。
-
纵向联邦学习:特征的联合,适用于用户重叠多,特征重叠少时的场景。比如:广告主与广告平台,希望结合两方的特征进行训练。
-
联邦迁移学习:参与者间的特征和样本重叠都很少时,可以考虑使用,但难度较高。
三种联邦学习交互的信息有异,受到的困扰也不同;比如:横向联邦学习时,各参与方数据异构,因此数据非独立同分布,也是联邦学习的研究热点。
目前纵向联邦学习已在我们业务中落地,也在探索联邦迁移学习、横向纵向的结合。
4. 联邦学习与分布式机器学习比较
精度上界:联邦学习不像优化其他具体的排序、召回模型,更像是在数据安全限制下,去推动整个建模。所以,理论上把共享数据下分布式机器学习(Distributed Machine Learning,DML)的结果作为上限。
联邦学习(FL)与分布式机器学习(DML)比较
虽然有人把联邦学习作为一种分布式机器学习的特殊情况,但是与一般的DML相比,联邦学习仍存在如下区别:
-
存在数据不共享的限制;
-
各server节点对worker节点控制弱;
-
通讯频率和成本较高。
二、腾讯联邦学习平台Angel PowerFL
从联邦学习发展开始,腾讯参与度就非常高。包括:制定发布《联邦学习白皮书2.0》、《腾讯安全联邦学习应用服务白皮书》等;基建方面,基于腾讯开源的智能学习平台Angel(https://github.com/Angel-ML/angel),构建PowerFL,目前内部开源;实践方面,在金融、广告、推荐场景,有多次尝试和落地。
1. 工程特色
腾讯联邦学习平台PowerFL除了易部署、兼容性好等机器学习平台基本要求,还有以下五个工程特色:
-
学习架构:使用去中心化联邦架构,不依赖第三方;
-
加密算法:实现并改进了各种常见的同态加密、对称和非对称加密算法;
-
分布式计算:基于 Spark on Angel 的分布式机器学习框架;
-
跨网络通信:利用 Pulsar 对跨网通信优化,增强稳定性,提供多方跨网络传输接口;
-
可信赖执行环境:TEE(SGX等)的探索和支持。
2. 算法优化
另外,针对算法侧也做了许多优化:
-
密文运算重写:基于 C++ GMP 重写密文运算库;
-
数据求交优化:分别就双方和多方优化,特别是多方侧进行了理论上的改造(改进的 FNP 协议);
-
GPU支持:密文运算部分可用GPU并行;
-
模型扩展支持:支持模型灵活扩展,可使用Tensorflow、Pytorch开发DNN模型嵌入。
值得提到的是,除了基于同态加密方案,PowerFL还支持秘密分享和差分隐私(噪声扰动)等联邦神经网络隐私保护方案。
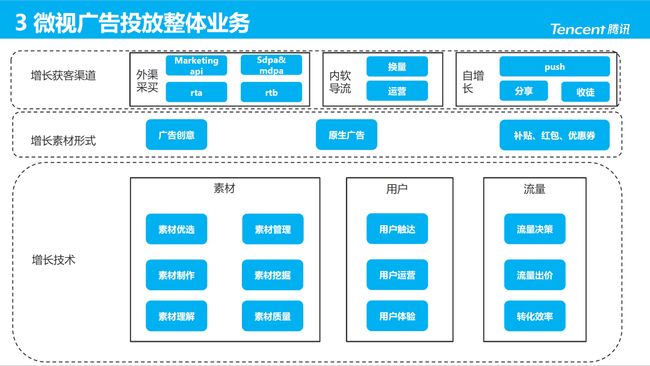
三、微视广告投放整体业务
我们团队的一个整体目的是迭代优化智能投放系统,我们从以下三点进行了发力:
1. 增长获客渠道
包含外渠采买、内软导流、自增长;其中,外渠采买实现形式上又可细分为 Marketing API 批量创建广告、RTA 人群定向、sDPA/mDPA 商品库、RTB 实时竞价等。
2. 增长素材形式
为了承接 Marketing API、RTA,持续优化广告创意;为了承接 RTB、sDPA/mDPA,优化原生广告内容;为了与自增长中的分享/收徒呼应,优化了补贴、红包、优惠券等策略或模型。
3. 增长技术
无论 RTA、RTB,核心都是优化用户与素材的精准匹配。我们针对素材、用户、两者的交互持续探索:
-
素材方面:包含制作、挖掘、理解、质量控制,比如:易出现负反馈内容的甄选、清晰度的识别与增强、素材的自动上下线与出价。#
-
用户方面:画像侧持续建设用户画像,如人群扩展(lookalike)、用户标签;运营侧借助 uplift、LTV 模型推进;体验侧追求拉承一体。
-
流量方面:广告投放决策核心即针对流量和成本的管理,于此发展一系列的策略;目前已尝试使用强化学习,来解决流量与成本的两难。
四、广告投放联邦学习架构
以下介绍联邦学习在微视广告投放框架中的角色:对 RTA 人群包的圈选。
1. 广告系统概览
首先,下图即为一个简单普适的广告系统:来自用户设备ID的广告请求,到达广告系统;通过广告召回、广告定向过滤 RTA、广告粗排、广告细排、广告下发,最后达成广告曝光。

2. RTA广告投放架构
然后,我们把其中 RTA 侧的框架放大。RTA 的目的为前置判断用户价值,执行人群定向、辅助分质出价。
-
RTA 广告请求发起,用户设备ID到达实验平台;
-
通过渠道的分配策略与 ID Mapping 识别,把历史用户使用拉活策略承接、非历史用户使用拉新策略承接;
-
联邦学习决定的即是 RTA-DMP 侧,以人群包的方式导入DMP,进行人群定向与分层。
3. 联邦学习粗粒度框架
这里,我们介绍下联邦学习粗粒度框架:
-
微视侧提供用户ID、画像、Label,广告平台侧提供用户ID、画像;
-
安全样本对齐(Private Set Intersection,PSI)得到用户交集,开始联邦学习协作训练;
-
模型评估后,双方合作抽取全量用户特征导出,并对全量用户打分;
-
最后将结果返回 RTA-DMP。
第五部分我们将详细拆解。
五、建模实践和细节介绍
1. 先导工作
相比于拉活,拉新更迫切使用联邦学习,因为端内特征更加稀疏,许多用户仅有用户设备ID;所以,优先切入拉新,先导工作包含:
1.1 拟合目标:四任务模型
-
主任务:主启次留率,即T日拉新,T+1日主动打开微视APP留存的用户占比。
-
副任务:主启次留成本、有效新增成本、有效新增占比;其中,用户新增有效性已模型化,根据停留时间等行为,给出概率打分。
1.2 微视单侧数据探索与特征工程
-
样本与采样:样本量摸底,确定采样策略。
-
特征与模型:ID 类特征、行为序列特征;使用 DNN 模型。
-
制定与线上表现一致的离线指标:经探索,Group-AUC 是良好的离线指标,Group 即为用户分层。Group-AUC 与线上表现正相关,且较 AUC 更敏感。
2. 模型训练
做完准备工作,微视侧开始与广告平台侧进行联合联邦学习建模。
2.1 联邦模型训练迭代流程
(1)数据对齐:确定用于协作训练的公共样本集合{id},有以下两种方式
-
明文:速度快,十亿与亿级别求交,仅需几分钟~十几分钟,但此种方法不安全,因两方只想确认公共集合部分,并不想泄露自己的补集;可使用信赖环境(TEE),在明文下保证安全。
-
密文:速度慢,较明文花费10倍以上时间,因涉及大量的加解密操作和碰撞;我们目前选用此策略,借助 自研PowerFL 平台实现。
(2)多方特征工程
-
纵向联邦学习:两侧特征独立,分而治之即可,比如:特征的标准化、补全。
-
横向联邦学习:部分统计量的获取,需要获得整个特征的全量分布,依然要使用联邦学习的通讯来解决数据同步。
(3)协同训练
-
确定计算环境、存储资源。
-
通讯信息(何种物理量承载,如梯度、embedding)。
(4)离线评估
(5)在线评估
2.2 基于 DNN 的联邦模型(FL-DNN)
微视侧与广告平台AMS侧共同训练多任务 DNN 模型,多任务结构从样本策略、修改损失函数等简单实现方式,演进到 MMoE ;工程上基于 Horovod 并行。
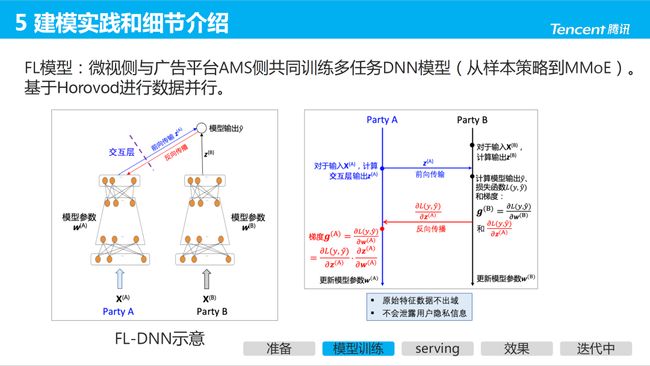
2.3 FL-DNN 模型参数的迭代过程
(1)初始化:A(host,AMS侧)、B(guest,微视侧)分别初始化各自网络(记为![]() 和
和![]() )的参数
)的参数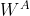 、
、![]() ,交互层参数
,交互层参数 ,记学习率为
,记学习率为 ,记噪声为
,记噪声为![]() 、
、![]() 、
、![]() ;
;
(2)前向传播:(![]() 表示同态加密)
表示同态加密)
-
A侧计算:计算
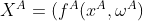 ;加密得到
;加密得到![[[X^A]]](http://img.e-com-net.com/image/info8/bb25b8a2d7274130b3b7f9bda14f6226.gif) (即为A侧输出的 embedding),将其发给B。
(即为A侧输出的 embedding),将其发给B。 -
B侧计算:同样进行 embedding 计算生成
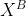 ,为符号对称,记
,为符号对称,记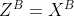 ;接收,并计算
;接收,并计算![[[Z^A]] = [[X^A]]I](http://img.e-com-net.com/image/info8/ec642ba543ef4489ace4901240553d9e.gif) ,然后计算
,然后计算![[[]Z^A+\epsilon^B]]](http://img.e-com-net.com/image/info8/c9df577de36946fe8c1406fae7d02bc1.gif) 并发送给A。
并发送给A。 -
A侧接收
![[[Z^A+\epsilon^A]]](http://img.e-com-net.com/image/info8/20e8dc1e1a5c4cf4a9eea22e861e7b97.gif) ,解密得到
,解密得到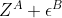 ;计算
;计算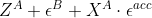 并发送给B
并发送给B -
B侧接收
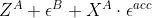 ,减去
,减去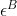 ,得到
,得到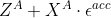 。在交互网络
。在交互网络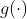 下传播,得到
下传播,得到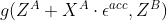 ,计算损失函数
,计算损失函数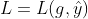 。
。
(3)反向传播
-
B侧计算:损失函数对参数
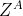 、
、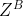 求导,得到梯度
求导,得到梯度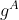 、
、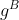 ;计算
;计算![[[g^A\cdot X^A+\epsilon^B]]](http://img.e-com-net.com/image/info8/02839f4398ea4ce697e4e0c37cbd596a.gif) ,并发送给A。
,并发送给A。 -
A侧接收
![[[g^A\cdot X^A+\epsilon^B ]]](http://img.e-com-net.com/image/info8/ce0d8c091db44aac84612c6d758fb4b4.gif) 并解密;计算
并解密;计算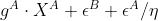 ,加密
,加密![[[\epsilon^{acc}]]](http://img.e-com-net.com/image/info8/b07d3b960517461da26ea96161b8430e.gif) ,将次两个量发送给B。
,将次两个量发送给B。 -
B侧接收
和;计算损失函数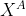 相对的梯度
相对的梯度![[[\delta W^A]] = [[g^A\cdot (I+\epsilon^{acc})]]](http://img.e-com-net.com/image/info8/0fbfcfbbca694a00ac77dd1200d16ae7.gif) ,并将
,并将![[[\delta W^A]]](http://img.e-com-net.com/image/info8/f148e167b316480baf32bee462224f4d.gif) 发送给A。
发送给A。 -
A侧接收
并解密。
(4)梯度更新:A、B、I分别对梯度更新,完成一轮迭代:
![]()
![]()
![]()
此结构与召回、粗排常用的双塔看似相似,但实际上设计原则并不同。双塔结构常被诟病 embedding 交互时机过晚,所以有了许多改进版,比如 MVKE模型(腾讯),把 embedding 的交互时机提早。纵向联邦学习中,A侧的![]() 可以在第一层,甚至没有变化(即仅做特征加密)就交给B侧,如此原则上没有交互时机问题。
可以在第一层,甚至没有变化(即仅做特征加密)就交给B侧,如此原则上没有交互时机问题。
2.4 FL-DNN 模型参数迭代特殊情况:单侧特征
B(guest侧)在没有或特征太弱下,只能提供用户设备ID、label,上述参数迭代过程退化为没有![]() 的情况,读者可尝试写下参数更新过程。
的情况,读者可尝试写下参数更新过程。
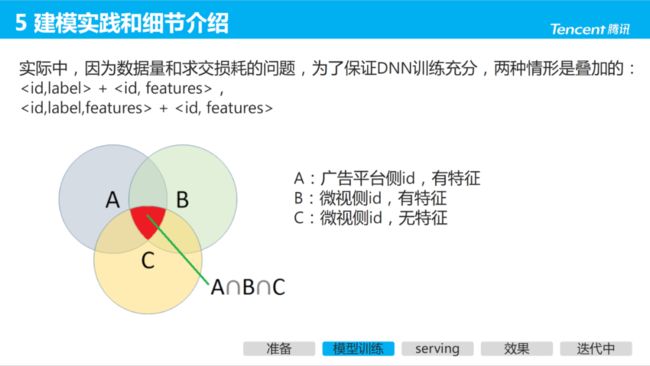
实际中,因为数据量、特征覆盖度、求交损耗等问题,为保证 DNN 训练充分,以下两种情况叠加:
-
B侧无特征:
-
B侧有特征:
3. 在线服务
各参与方只能得到与自己相关的模型参数,预测时需要各方协作完成:
(1)发送请求:用户设备ID,分别触达A、B;
(2)embedding 计算
-
A侧计算
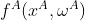 ,加密
,加密![[[f^A(x^A,\omega^A)]]](http://img.e-com-net.com/image/info8/c927089d87614afa95786d19dffda283.gif) ;
; -
B侧计算
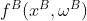 ;
;
(3)label 计算
-
A侧将
发给B侧; -
B侧计算label
![[[y]]=g([[f^A(x^A,w^A)]],f^B(x^A,w^B))](http://img.e-com-net.com/image/info8/00af3fa9c7dd4e8692c889709673db8a.gif) ;
; -
B侧解密得到y。
4. 效果展示
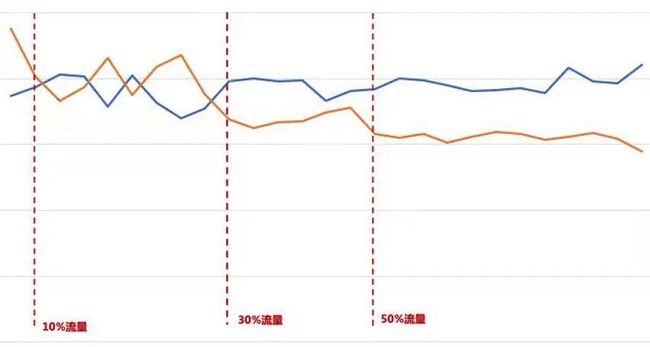
在与腾讯广点通AMS的合作中,相对微视单独训练,联邦学习使得 Group-AUC +0.025;主目标与3个次目标都呈正相关且有提升。主要目标主启次留率(覆盖率折算后)提升 +4.7PP。初版上线后各项指标均有显著提升,已发布全量。在迭代的第二版也取得了GAUC的显著提升,正在小流量实验。

下图则展示了主启次留成本的有效降低(橙色):
5. 迭代中
5.1 拉新模型
推进与其他渠道的联邦协作,但团队无力在每个投放平台都维护一个联邦模型。初步尝试将与AMS平台联合训练的模型,放到在其他平台拉新。但因数据异构(样本分布偏差)等原因,此模型不如 base 模型(微视单侧)好;另各投放平台存在利益冲突,都希望广告主重点投放自家流量,因此,我们在尝试横向与纵向的结合:微视与广告平台是纵向,广告平台之间是横向,期望从三方联邦协作切入,目前正在迭代联邦迁移思路。
5.2 拉活模型
与AMS平台合作,联邦模型打通后,我们想复用到拉活模型上。因用户拉活是多目标、多兴趣、异行为序列的情形,我们将重心放在时效性与模型的创新上,进行了基于 MMoE-Mind-transformer 模型的探索。
5.3 迭代困难
(1)效率和稳定性
-
提升数据对齐速度:为提升密文求交速度,以哈希分桶做到简单的并行而加速。
-
压缩训练时间:增量训练做 finetune;与全量训练得到相似结果,时间少一半。
(2)可解释性和 debug 困难:联邦的双方都看不到对方原始数据,甚至有时双方还会隐藏各自的神经网络结构。这样的确保证数据的安全;但从迭代角度看,问题定位更难。
(3)多方联邦建模的困难
-
与多个合作广告平台联合建模,彼此有利益冲突,与 Google FedAvg 场景不同。
-
与其他事业部联合建模,如微信、搜索具强而有力的特征,但对方没有动机。
-
存在技术/网络稳定性/沟通成本。
六、Q&A
Q1. TEE(可信赖执行环境)在联邦学习任务中是必备的吗?什么场景下会基于TEE完成任务?当前介绍的项目是基于TEE计算的吗?
A1. 当前并无使用 TEE 环境,若使用 TEE 就可直接明文操作,无需大量加密操作;因 TEE 环境下保证即使明文操作,数据也是安全且对对方不可见;目前无论数据求交、模型训练(梯度、embedding)都是密文操作。
Q2. 联邦学习的第一步数据对齐,需要做映射表维护吗?
A2:无需维护映射表,因数十亿用户量加上特征,映射表数据量达到数百G级别,其实是一种资源的浪费;实际操作样本对齐时是按顺序操作,广告平台侧给的ID,是按约定从上往下的顺序,即无需再维护kv的映射关系。
Q3. Serving(在线服务)时,需要拿对方(广告平台)的特征,这块延时如何?
A3. Serving 的延时还是通讯带来的,广告平台在自己的机器上训练广告平台侧的模型,微视侧在自己的机器上训练微视侧的模型,最终交互时也是交互 embedding。
Q4. 所有情况下,B侧(guest侧)提供 label 都是必须的吗?
A4. B侧(guest侧,微视侧),因数据不出域不会提供 label 给对方,见“FL-DNN 模型参数的迭代过程”章节公式可知,梯度是在 B 侧计算完成,对方无法得知 label。
Q5. 使用联邦学习后 Group-AUC 增加 +0.025,未使用联邦学习前的 Group-AUC 是多少?
A5. 数值没有太直接指导意义,不同场景下的样本定义、拟合目标改变即改变;原先从 0.70 级别,提到 0.72-0.73 级别。
Q6. 腾讯前段时间发的 MKVE 论文全名是?
A6. 2021-tencent-Mixture of Virtual-Kernel Experts for Multi-Objective User Profile Modeling。
Q7. FL-DNN 建模中需要第三方,如何信任第三方?
A7. 其实按去中心化的架构无需第三方,可由一系列的加解密操作的算法来承担。
Q8. 如果双方都是 TEE 的执行环境,网络中交换的数据都是明文的吗?
A8. 对,明文即可。
Q9. 联邦框架和RTA结合,是离线产出人群包,还是在线实时预估?
A9. 经探索,拉新侧的实时重要度并不高,是把离线人群包导入DMP,再给RTA对接;拉活侧因为想抓住用户短时间内的兴趣变化,有实时性的要求,目前正在研究。