【Pytorch深度学习实战】(9)神经语言模型(RNN-LM)
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
神经网络语言模型(RNN-LM)
传统语言模型的上述几个内在缺陷使得人们开始把目光转向神经网络模型,期望深度学习技术能够自动化地学习代表语法和语义的特征,解决稀疏性问题,并提高泛化能力。我们这里主要介绍两类神经网络模型:前馈神经网络模型(FFLM)和循环神经网络模型(RNNLM)。前者主要设计来解决稀疏性问题,而后者主要设计来解决泛化能力,尤其是对长上下文信息的处理。在实际工作中,基于循环神经网络及其变种的模型已经实现了非常好的效果。
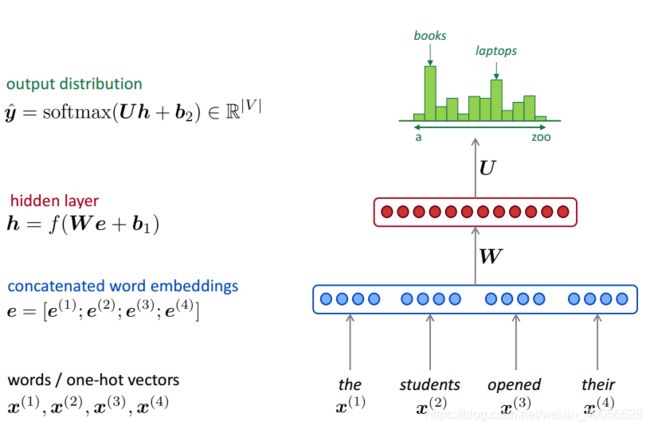
我们前面提到,语言模型的一个主要任务就是要解决给定到当前的上下文的文字信息,如何估计现在每一个单词出现的概率。Bengio等人提出的第一个前馈神经网络模型利用一个三层,包含一个嵌入层、一个全连接层、一个输出层,的全连接神经网络模型来估计给定n-1个上文的情况下,第n个单词出现的概率。其架构如下图所示:
RNN语言模型训练过程
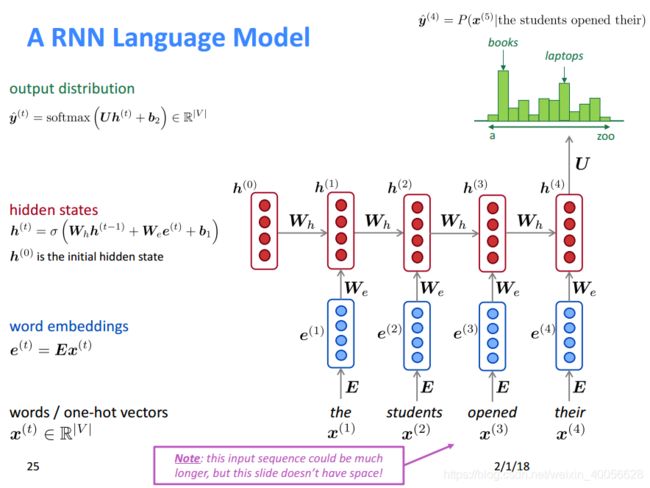
另一类循环神经网络模型不要求固定窗口的数据训练。FFLM假设每个输入都是独立的,但是这个假设并不合理。经常一起出现的单词以后也经常出现的概率会更高,并且当前应该出现的词通常是由前面一段文字决定的,利用这个相关性能提高模型的预测能力。循环神经网络的结构能利用文字的这种上下文序列关系,从而有利于对文字建模。这一点相比FFLM模型更接近人脑对文字的处理模型。比如一个人说:"我是中国人,我的母语是___ "。 对于在“__”中需要填写的内容,通过前文的“母语”知道需要是一种语言,通过“中国”知道这个语言需要是“中文”。通过RNNLM能回溯到前两个分句的内容,形成对“母语”,“中国”等上下文的记忆。一个典型的RNNLM模型结构如下图所示。
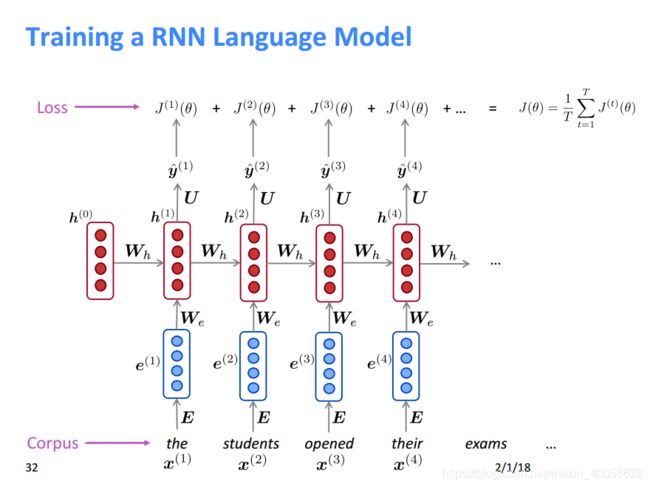
RNN语言模型训练过程
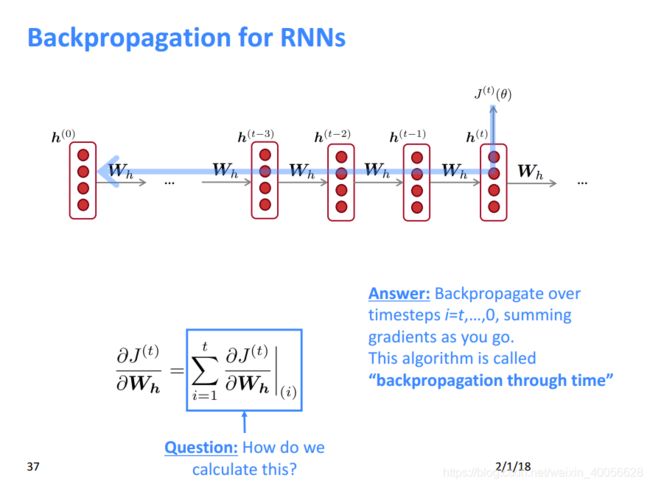
RNN语言模型反向传播
语言模型评估
迷惑度/困惑度/混乱度(perplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好。迷惑度越小,句子概率越大,语言模型越好。

神经网络语言模型Pytorch的实现
import torch
import torch.nn as nn
import numpy as np
from torch.nn.utils import clip_grad_norm_
from data_utils import Dictionary, Corpus
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 超参数
embed_size = 128
hidden_size = 1024
num_layers = 1
num_epochs = 5
num_samples = 1000 # number of words to be sampled
batch_size = 20
seq_length = 30
learning_rate = 0.002
# 加载“Penn Treebank”数据集
corpus = Corpus()
ids = corpus.get_data('data/train.txt', batch_size)
vocab_size = len(corpus.dictionary)
num_batches = ids.size(1) // seq_length
# 基于RNN的语言模型
class RNNLM(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers):
super(RNNLM, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
def forward(self, x, h):
# 将单词 id 嵌入到向量中
x = self.embed(x)
# 前向传播 LSTM
out, (h, c) = self.lstm(x, h)
# 将输出重塑为 (batch_size*sequence_length, hidden_size)
out = out.reshape(out.size(0)*out.size(1), out.size(2))
# 解码所有时间步的隐藏状态
out = self.linear(out)
return out, (h, c)
model = RNNLM(vocab_size, embed_size, hidden_size, num_layers).to(device)
# 损失和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 截断反向传播
def detach(states):
return [state.detach() for state in states]
# 训练模型
for epoch in range(num_epochs):
# 设置初始隐藏和单元格状态
states = (torch.zeros(num_layers, batch_size, hidden_size).to(device),
torch.zeros(num_layers, batch_size, hidden_size).to(device))
for i in range(0, ids.size(1) - seq_length, seq_length):
# 获取小批量输入和目标
inputs = ids[:, i:i+seq_length].to(device)
targets = ids[:, (i+1):(i+1)+seq_length].to(device)
# 前传
states = detach(states)
outputs, states = model(inputs, states)
loss = criterion(outputs, targets.reshape(-1))
# 向后优化
optimizer.zero_grad()
loss.backward()
clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
step = (i+1) // seq_length
if step % 100 == 0:
print ('Epoch [{}/{}], Step[{}/{}], Loss: {:.4f}, Perplexity: {:5.2f}'
.format(epoch+1, num_epochs, step, num_batches, loss.item(), np.exp(loss.item())))
# 测试模型
with torch.no_grad():
with open('sample.txt', 'w') as f:
# 设置初始隐藏单元状态
state = (torch.zeros(num_layers, 1, hidden_size).to(device),
torch.zeros(num_layers, 1, hidden_size).to(device))
# 随机选择一个单词id
prob = torch.ones(vocab_size)
input = torch.multinomial(prob, num_samples=1).unsqueeze(1).to(device)
for i in range(num_samples):
# 前向传播 RNN
output, state = model(input, state)
# 采样一个单词id
prob = output.exp()
word_id = torch.multinomial(prob, num_samples=1).item()
# 用采样的单词 id 填充输入以用于下一个时间步
input.fill_(word_id)
# 文件写入
word = corpus.dictionary.idx2word[word_id]
word = '\n' if word == '' else word + ' '
f.write(word)
if (i+1) % 100 == 0:
print('Sampled [{}/{}] words and save to {}'.format(i+1, num_samples, 'sample.txt'))
# 保存模型checkpoints
torch.save(model.state_dict(), 'model.ckpt')